VSCode下载与安装 点击这个链接VSCode官网进入VSCode官网
点击中间这个下载就行了,下载好后安装就行了(安装应该有手就行吧)
相关插件的下载 Chinese安装 打开VSCode后,点击左边这按钮,到搜索栏里面输入Chinese,安装那个简体的就行了,这里笔者已经装过了,搜索出来就没有安装按钮,安装好后需要重启一下,然后你的VSCode里面显示的就全是中文了
SSH安装 同样在搜索框中输入ssh,如下图,安装最上面这个就行了,
安装好后,设置一下拓展(右键点击拓展,然后点那个拓展设置)
弹出如下窗口,到第一栏里面写上你想保存的配置文件的路径就行了
接下来是对远程系统的配置,如果你已经配好了就可以跳过
Linux系统配置 此处以Ubuntu
安装SSH 先打开terminal,输入如下语句安装SSH服务
sudo apt-get install openssh-server 安装好后,输入如下语句启动SSH
sudo systemctl start ssh 然后看看有没有启动
ps -ef|grep sshd 连接设置 密码登录 打开VSCode里面的远程资源管理器,再点这个 + 号
到弹出的输入框里输入如下信息,这里读者按照自己的情况去填写
然后点刷新,就会出现你刚刚设置的连接,具体如下
再点右边的小箭头就可以远程连接了,此时需要输入密码
免密登录设置 首先生成公钥,然后传给远程服务器(已经开启ssh服务了)
使用git bash来生成
ssh-keygen -t rsa ssh-copy-id -i ~/.ssh/id_rsa.pub 远程服务器用户名@远程服务器的IP 然后到你的config文件下加上这一行就可以实现免密登录了
下次你连接远程服务器的时候,就不需要输入密码,终端会输入如下的内容,就代表你成功免密登录了。
一、Mybatis 整体执行流程 二、Mybatis 具体流程源码分析 三、源码分析
写一个测试类,来具体分析Mybatis 的执行流程:
public class MybatisTest { public static void main(String[] args) throws IOException { //1. 读取mybatis-config.xml 文件 InputStream inputStream = Resources.getResourceAsStream("mybatis-config.xml"); //2. 构建SqlSessionFactory(创建了DefaultSqlSessionFactory) SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream); //3. 打开SqlSession SqlSession sqlSession = sqlSessionFactory.openSession(); //4. 获取Mapper 接口对象 UserMapper mapper = sqlSession.getMapper(UserMapper.class); //5. 获取mapper 接口对象的方法操作数据库 List<SysUser> sysUsers = mapper.selectByIdList(Arrays.asList(1L)); System.out.println("查询结果为:" + sysUsers.size()); } } 1. 查看 XMLConfigBuilder.parse() : 跟踪 new SqlSessionFactoryBuilder().build(inputStream); 查看XMLConfigBuilder.parse() :
1.1 propertiesElement private void propertiesElement(XNode context) throws Exception { if (context !
文章目录 注意我这里写反了,应该是左0右1题目描述证明过程前八个斐波那契数规律发现规律的数学证明 分析与总结 注意我这里写反了,应该是左0右1 题目描述 字符a~h出现的频率恰好是前8个Fibonacci数,它们的哈夫曼编码是什么?将结果推广到n个字符的频率恰好是n个Fabonacci数的情形。
证明过程 前八个斐波那契数规律发现 规律的数学证明 如果要保证上面推论,得保证每一个项都是类似的树型结构,映射到数值之间的关系就是下图的结论
这里是对推论的样例举例和具体说明,比较好懂!
分析与总结 算法设计和分析真的是比较难,还需好好努力,加油!不过挺有意思的!
TS编译配置 编译 typescript官网- tsconfig-json
编译 编写完ts文件,通过tsc ts文件名,来编译指定文件,
tsc ts文件名 -w (watch:看,观察),监视指定文件,变化时自动编译
tsconfig.json (一次性编译而且同时监视) 编译项目中配置内的ts文件, 命令行输入 tsc ,就可以将全部文件编译, 输入tsc -w就是监视所有文件
配置项
include: 指定文件或目录下
exclude:不需要进行编译,默认值 [“node_modules”,“bower_components”,“jspm_packages”]
extends:多个json配置文件引入进来,相当于import引入外部文件
files:指定个别文件编译,只能写文件名
compilerOptions: 编译器基本选项
target:编译为何种版本,默认ES3, let 使用 var,ES6 let 不变,ESNext表示最新版本的ESmodule:模块化类型,‘none’, ‘commonjs’, ‘amd’, ‘system’, ‘umd’, ‘es6’, ‘es2015’, ‘es2020’, ‘es2022’, ‘esnext’, ‘node12’, ‘nodenext’. es6与es2015效果几乎等同lib:(libary库) 指定项目中要使用的库,一般情况下不需要去更改outDir:编译后文件目录outFile:编译后文件中全局作用域代码合并为一个文件,如果要使多个模块合并在一个文件当中,module使用 amd或system,一般不配置,而通过打包工具来实现这个功能allowJs:是否编译js文件,默认为false,如果我们模块使用js写的,那么我们需要将allowJs设置为truecheckJs:检查js是否符合js语法, 默认为false,checkJs与allowJs一般是一起用的removeComments:是否移除注释,默认falsenoEmit:编译是否需要产生编译后的代码,只使用它来检查一下代码是否有错,默认为 falsenoEmitOnError:指当有错误时是否生成文件,默认为falsealwaysStrict:编译后的文件是否使用严格模式(即在js文件开头添加“use strict”),默认为falsenoImplicitAny:(implicit:隐式)是否对any类型检查,改为true进行检查noImplicitThis:.检查不明确的this类型 function fn(this){ alert(this) // this指向window } function fn(this: window){ alert(this) // 明确 window 类型 } strictNullChecks :严格的检查空值,默认为falsestrict:所有严格检查的总开关,默认false,一般开发打开 // tsconfig.
安装mock.js 经测试发现vite-plugin-mock版本太新与vite@4版本不兼容,最好使用2.9.6版本
#npm npm install mockjs vite-plugin-mock -D npm install mockjs vite-plugin-mock@2.9.6-D #yarn yarn add mockjs vite-plugin-mock -D yarn add mockjs vite-plugin-mock@2.9.6 -D vite中mock引入 安装后,需要在vite.config.js文件中引入vite-plugin-mock插件
/* vite.config.js */ import { defineConfig } from "vite"; import vue from "@vitejs/plugin-vue"; import { viteMockServe } from "vite-plugin-mock"; // https://vitejs.dev/config/ export default defineConfig({ base: '/', plugins: [ vue(), viteMockServe({ mockPath: "src/mock",//设置mock文件存储目录 localEnabled: true,//设置是否启用本地mock文件 prodEnabled: true,//设置打包是否启用 mock 功能 watchFiles: true,//设置是否监视mockPath对应的文件夹内文件中的更改 injectCode: ` import { setupProdMockServer } from '.
分布式事务解决方案-Seata 1.分布式事务问题1.1.本地事务1.2.分布式事务1.3.演示分布式事务问题 2.理论基础2.1.CAP定理2.1.1.一致性2.1.2.可用性2.1.3.分区容错2.1.4.矛盾 2.2.BASE理论2.3.解决分布式事务的思路 3.初识Seata3.1.Seata的架构3.2.部署TC服务3.3.微服务集成Seata3.3.1.引入依赖3.3.2.配置TC地址3.3.3.其它服务 4.动手实践4.1.XA模式4.1.1.两阶段提交4.1.2.Seata的XA模型4.1.3.优缺点4.1.4.实现XA模式 4.2.AT模式4.2.1.Seata的AT模型4.2.2.流程梳理4.2.3.AT与XA的区别4.2.4.脏写问题4.2.5.优缺点4.2.6.实现AT模式 4.3.TCC模式4.3.1.流程分析4.3.2.Seata的TCC模型4.3.3.优缺点4.3.4.事务悬挂和空回滚1)空回滚2)业务悬挂 4.3.5.实现TCC模式1)思路分析2)声明TCC接口3)编写实现类 4.4.SAGA模式4.4.1.原理4.4.2.优缺点 4.5.四种模式对比 5.高可用5.1.高可用架构模型 1.分布式事务问题 1.1.本地事务 本地事务,也就是传统的单机事务。在传统数据库事务中,必须要满足四个原则:
1.2.分布式事务 分布式事务,就是指不是在单个服务或单个数据库架构下,产生的事务,例如:
跨数据源的分布式事务跨服务的分布式事务综合情况 在数据库水平拆分、服务垂直拆分之后,一个业务操作通常要跨多个数据库、服务才能完成。例如电商行业中比较常见的下单付款案例,包括下面几个行为:
创建新订单扣减商品库存从用户账户余额扣除金额 完成上面的操作需要访问三个不同的微服务和三个不同的数据库。
订单的创建、库存的扣减、账户扣款在每一个服务和数据库内是一个本地事务,可以保证ACID原则。
但是当我们把三件事情看做一个"业务",要满足保证“业务”的原子性,要么所有操作全部成功,要么全部失败,不允许出现部分成功部分失败的现象,这就是分布式系统下的事务了。
此时ACID难以满足,这是分布式事务要解决的问题
1.3.演示分布式事务问题 我们通过一个案例来演示分布式事务的问题:
1)微服务结构如下:
其中:
seata-demo:父工程,负责管理项目依赖
account-service:账户服务,负责管理用户的资金账户。提供扣减余额的接口storage-service:库存服务,负责管理商品库存。提供扣减库存的接口order-service:订单服务,负责管理订单。创建订单时,需要调用account-service和storage-service 2)启动nacos、所有微服务
3)测试下单功能,发出Post请求:
请求如下:
curl --location --request POST 'http://localhost:8082/order?userId=user202103032042012&commodityCode=100202003032041&count=20&money=200' 如图:
测试发现,当库存不足时,如果余额已经扣减,并不会回滚,出现了分布式事务问题。
2.理论基础 解决分布式事务问题,需要一些分布式系统的基础知识作为理论指导。
2.1.CAP定理 1998年,加州大学的计算机科学家 Eric Brewer 提出,分布式系统有三个指标。
Consistency(一致性)Availability(可用性)Partition tolerance (分区容错性) 它们的第一个字母分别是 C、A、P。
Eric Brewer 说,这三个指标不可能同时做到。这个结论就叫做 CAP 定理。
2.1.1.一致性 Consistency(一致性):用户访问分布式系统中的任意节点,得到的数据必须一致。
比如现在包含两个节点,其中的初始数据是一致的:
当我们修改其中一个节点的数据时,两者的数据产生了差异:
要想保住一致性,就必须实现node01 到 node02的数据 同步:
2.1.2.可用性 Availability (可用性):用户访问集群中的任意健康节点,必须能得到响应,而不是超时或拒绝。
如图,有三个节点的集群,访问任何一个都可以及时得到响应:
无论是在自动化测试实践,还是日常交流中,经常听到一个词:框架。之前学习自动化测试的过程中,一直对“框架”这个词知其然不知其所以然。
最近看了很多自动化相关的资料,加上自己的一些实践,算是对“框架”有了一些理解,这篇博客,就聊聊自动化框架的一些事吧。。。
一、什么是自动化测试框架 简单来说,自动化测试框架就是由一些标准,协议,规则组成,提供脚本运行的环境。自动化测试框架能够提供很多便利给用户高效完成一些事情,例如,结构清晰开发脚本,多种方式、平台执行脚本,良好的报告去跟踪脚本执行结果。
1.框架具有以下一些优点:
1)代码复用
2)最大覆盖率
3)很低成本维护
4)很少人工干预
5)简单报告输出
2.常见的测试框架分类
早期设计的框架大致可分为以下几类:
1)基于模块的测试框架
2)基于库(Library)结构测试框架
3)数据驱动测试框架,和QTP很像
4)关键字驱动测试框架,也是QTP过来的
5)混合测试框,3 4和综合
6)行为驱动开发测试框架
这里我们不一一介绍这些框架,字面意思可以想象一些这些框架的背景和组件,本文只是对框架有一个基本了解。
3.框架基本组件
我们来思考下框架组成部分:
1)需要配置文件管理
2)业务逻辑代码和测试脚本分离
3)报告和日志文件输出
4)自定义的库的封装
5)管理、执行脚本方式
6)第三方插件引入
7)持续集成
解释:
我们需要一个配置文件去控制一些,环境信息,开关,配置文件可以是txt/xml/yaml/properties/ini,一般.properties使用较多在JAVA里,本文是Python系列,我可能会选择ini文件。
业务逻辑代码和测试脚本分离,不像我们刚开始学习Selenium那样,代码和脚本在一个类文件里演示。我们根本没有用到代码重构,复用。代码和用例文件分离后,更加清晰,去多人开发脚本,方便调试。
报告和日志文件输出,你执行了多少case,case结果如何,这都需要报告来展示,一般采用第三方插件来实现这个功能,好多报告格式是html,简单,明了的风格。日志输出也很重要,如果发生报错,脚本执行失败,通过日志快速定位发生问题位置。
用户自定义库,这个很好理解,我们很多功能需要重复调用,这样我们就写成一个公用方法,放到工具包下,每次方便调用,例如浏览器引擎类和basepage.py的封装。
管理和执行脚本的方式,例如Python中单元测试框架unittest使用率非常高。
第三方插件,有时候,我们一些功能,需要借助第三方插件,能够更好实现,例如AutoIT,来实现文件上传和下载。还有利用第三方报告插件生成基于html格式的测试报告。
持续集成,git,svn,ant,maven,jenkins,我们会把这整合到jenkins,达到持续集成,一键执行测试脚本。
根据以上的特点介绍,我大致用以下图来描述一下,一个简单的自动化测试框架,可能包含哪些组成部分。
框架的简单介绍就到这里,有些人把框架想得太复杂了,框架无非就是一些软件的集合,达到特定的目的。这里我们上图画出来的框架,就是一个简单的自动化测试框架,别笑,这确实是一个简单但又包含必要的组件的自动化测试框架设计实例,如果你学会了这个设计思路和思想,那么,你已经达到了自动化测试第二个阶段的水平:能够简单设计自动化测试框架和维护框架的能力。
二、自动化测试
自动化测试定义
首先来说一下什么是软件测试?
软件测试简单来说就是在规定的条件下对程序进行操作以发现程序错误,衡量软件质量,并对其是否能满足设计要求进行评估的过程。
那么什么是自动化测试呢?
自动化测试是把以人为驱动的测试行为转化为机器执行的一种过程,即模拟手工测试步骤通过执行程序语言编制的测试脚本自动地测试软件,包括了所有测试阶段,它是跨平台兼容的,并且是进程无关的。
实际上严格的说自动化测试是分广义和狭义的。广义的就是测试自动化,它强调的是整个测试过程都由计算机系统完成,范围更广。狭义的就是我们通常所说的自动化测试,主要是说通过某个自动化工具自动执行某项测试任务,处理范围比较小。
使用自动化测试的前提条件及适用场合
前提条件
实施自动化测试之前需要对软件开发过程进行分析,以观察其是否适合使用自动化测试。通常需要同时满足以下条件:
1) 需求变动不频繁
测试脚本的稳定性决定了自动化测试的维护成本。如果软件需求变动过于频繁,测试人员需要根据变动的需求来更新测试用例以及相关的测试脚本,而脚本的维护本身就是一个代码开发的过程,需要修改、调试,必要的时候还要修改自动化测试的框架,如果所花费的成本不低于利用其节省的测试成本,那么自动化测试便是失败的。
项目中的某些模块相对稳定,而某些模块需求变动性很大。我们便可对相对稳定的模块进行自动化测试,而变动较大的仍是用手工测试。
2) 项目周期足够长
自动化测试需求的确定、自动化测试框架的设计、测试脚本的编写与调试均需要相当长的时间来完成,这样的过程本身就是一个测试软件的开发过程,需要较长的时间来完成。如果项目的周期比较短,没有足够的时间去支持这样一个过程,那么自动化测试便成为笑谈。
3) 自动化测试脚本可重复使用
如果费尽心思开发了一套近乎完美的自动化测试脚本,但是脚本的重复使用率很低,致使其间所耗费的成本大于所创造的经济价值,自动化测试便成为了测试人员的练手之作,而并非是真正可产生效益的测试手段了。
另外,在手工测试无法完成,需要投入大量时间与人力时也需要考虑引入自动化测试。
比如我们愚公坊项目这次SpringBoot升级后一些相对稳定的模块就可以采用自动化测试注册登录模块 购物车模块 订单模块等等。
适用场合
通常适合于软件测试自动化的场合:
(1)回归测试,重复单一的数据录入或是击键等测试操作造成了不必要的时间浪费和人力浪费;
(2)此外测试人员对程序的理解和对设计文档的验证通常也要借助于测试自动化工具;
(3)采用自动化测试工具有利于测试报告文档的生成和版本的连贯性;
(4)自动化工具能够确定测试用例的覆盖路径,确定测试用例集对程序逻辑流程和控制流程的覆盖。
1.win和mac同步git代码,比如cocoscreator中,win拉mac提交的代码,cocos编辑器把meta文件换行符改变了,要保持和mac同事提交的一直需要把git设置一下:
autoCrlf: false, safeCrlf:true
目录
1.ICMP协议简介
2.ICMP报文格式
2.1 ICMP报文以太网数据帧格式
2.2 ICMP首部格式
2.3 ICMP报文类型列表
3.ICMP故障排查工具
3.1 ping工具
3.2 traceroute工具
4.常见ICMP报文
4.1 ICMP请求和应答
4.2 ICMP差错报告报文
4.3 目标主机不可达
5.ICMP校验和计算
5.1 ICMP校验和计算
5.2 ICMP校验和验证
6.ICMP编程示例
6.1 发送回显请求
6.2 发送回显应答
1.ICMP协议简介 ICMP(Internet Control Message Protocol)是一种网络协议,它用于在IP网络中传递控制信息和错误消息。它通常与IP协议一起使用,IP协议负责发送和路由数据包,而ICMP协议负责检查网络是否可达、路由是否正确、主机是否可达等网络状态的反馈信息。
ICMP协议的主要功能如下:
发现网络错误:当一个数据包在传输过程中出现错误时,ICMP协议通过向发送方发送错误通知来发现网络错误。
检查网络是否可达:通过发送ICMP ECHO请求并接收ICMP ECHO回复消息,可以确定目标主机是否可达。
发现主机错误:当一个主机无法正常工作时,ICMP协议通过向发送方发送错误通知来发现主机错误。
发送路由信息:ICMP协议可以向其他主机发送路由信息,以帮助它们在网络中找到合适的路由。
2.ICMP报文格式 2.1 ICMP报文以太网数据帧格式 图 1 ICMP以太网数据帧
ICMP报文属于IP子协议,协议号为1。
2.2 ICMP首部格式 图 2 ICMP首部格式
其中各字段的含义如下:
类型(Type):指定 ICMP 报文的类型,占 1 个字节。常见类型有:回显应答(Echo Reply:0)、回显请求(Echo Request:8)等。
代码(Code):指定 ICMP 报文的代码,占 1 个字节。用于进一步描述 ICMP 报文,与 Type 字段组合使用。
目录
1.ARP协议简介
2.ARP工作原理
2.1 局域网通信
2.2 跨网段通信
3.ARP协议解析
3.1 ARP报文结构
3.2 ARP请求
3.3 ARP响应
4.ARP攻击
4.1 ARP欺骗
4.2 ARP投毒
4.3 如何预防ARP攻击?
5.ARP编程示例
5.1 ARP请求示例代码
5.2 ARP响应示例代码
6.Linux ARP调试
6.1 查看ARP表
6.2 手动添加ARP表项
6.3 删除ARP表项
1.ARP协议简介 ARP(Address Resolution Protocol)协议是一种在局域网中解析MAC地址的协议。
当主机要向局域网中的另一台主机发送数据时,需要知道目标主机的MAC地址。ARP协议就是用来解析目标主机的MAC地址的。主机会广播一个ARP请求包,请求目标主机回应自己的MAC地址。目标主机接收到请求后会返回一个ARP响应包,包括自己的MAC地址。这样,请求主机就可以通过MAC地址向目标主机发送数据了。
2.ARP工作原理 图 1 ARP工作原理
2.1 局域网通信 局域网主机A和主机B通信,如果双方原来没有通信过,主机A只知道主机B的IP地址,不知道主机B的MAC地址,此时主机A和主机B无法正常通信。
局域网通信的基础通信双方都得知道对方的MAC地址,MAC地址通常是存储在主机的ARP表中。
此时主机A会尝试去获取主机B的MAC地址,获取的MAC地址的方式是发送ARP请求(以广播形式发送),主机B如果收到ARP请求会回复ARP响应给主机A。
主机A收到响应后会把主机B的IP和MAC地址记录在ARP表中,此时主机A能够发送数据给主机B,主机B因为收到主机A的ARP请求,通过ARP请求知道主机A的MAC地址,把主机A的IP和MAC地址记录在ARP表中,主机B也能给主机A发送数据,正阳主机A和主机B就能正常通信。
2.2 跨网段通信 主机A要访问一个公网主机,由于主机A和公网主机IP地址不再同一网段,此时需要用到路由功能,路由功能后续章节会详细介绍。
我们只要记住一个核心点,路由功能核心作用就是找到去往目的IP的网关IP地址。
网关IP地址必须和主机A处于同一局域网。找到网关IP地址的目的是为了获取网关MAC地址,获取到网关MAC地址,可以通过网关MAC地址把数据包发送给网关,让网关转发数据包至公网。
如果通过网关IP获取到网关MAC地址可以参考局域网通信。
跨网段通信流程:
步骤1:通过路由查找到网关IP地址
步骤2:如果不知道网关MAC地址,需要通过ARP协议获取到网关MAC地址。
步骤3:把网关MAC地址填入以太网报文头部,将数据包发给网关。
步骤4:网关转发数据包至公网。
3.ARP协议解析 3.1 ARP报文结构 图 2 ARP报文结构 硬件类型:2字节,表示使用的网络类型,例如以太网、令牌环等。协议类型:2字节,表示使用的协议类型,例如IPv4、IPX等。硬件地址长度:1字节,表示硬件地址的长度,例如以太网地址长度为6字节。协议地址长度:1字节,表示协议地址的长度,例如IPv4地址长度为4字节。操作码:2字节,表示ARP请求(数值为1)或ARP响应(数值为2)。发送方硬件地址:6字节,表示发送方的硬件地址。发送方协议地址:4字节,表示发送方的协议地址。目标硬件地址:6字节,表示目标的硬件地址。目标协议地址:4字节,表示目标的协议地址。 3.2 ARP请求 图 3 ARP请求报文
前几天博主接到一个任务:5台HTCVIVEPro设备,其中一台设备进行演示,另外四台设备画面同步。 在设备没到之前,博主进行了一下前期准本工作:同一局域网 一台主机控制多台主机
PS:博主参考了其它博主大大的文章,感觉很有用!!!!!!
如果需要其它的一些TCP操作流程,请看这个博主大大的文章,很详细
【Unity】Socket网络通信(TCP) - 最基础的C#服务端通信流程_unity的tcp发送消息_IM雾凇的博客-CSDN博客
【Unity】Socket网络通信(TCP) - 实现简单的多人聊天功能_unity socket通信_IM雾凇的博客-CSDN博客
以下开始了博主操作的具体流程,希望对你有所帮助
一:5台设备同一局域网下,且所有主机的防火墙需要关闭,要保证每台电脑都能互相ping通
1.如何关闭防火墙:
2.ping他人电脑
win+R打开cmd, ping 192.168.2.5 按下enter键之后,出现数据即为ping通
二.创建服务器,我们需要一台主机作为服务器(消息发送方)
1.打开VS,创建控制台应用程序
2.封装服务端ServerSocket
using System; using System.Collections.Generic; using System.Net; using System.Net.Sockets; using System.Text; using System.Threading; namespace TCPServer { public class ServerSocket { private Socket socket; private bool isClose; private List<ClientSocket> clientList = new List<ClientSocket>(); public void Start(string ip, int port, int clientNum) { isClose = false; socket = new Socket(AddressFamily.
基类的指针指向它派生出来的子类实例时,可以用这个指针来操作这个子类实例。由于子类可以继承基类的成员函数和数据成员,因此这个指针可以访问基类和子类共有的成员函数和数据成员,但不能访问子类独有的成员函数和数据成员。
基类的指针的常见用法之一是在面向对象编程中实现多态。在多态中,基类的指针可用来访问派生类对象,使代码更灵活、通用、可扩展。通过使用指向基类的指针,可以让程序更具有可扩展性和维护性。
以下是一个简单的基类指针示例:
class Shape { public: virtual double area() const { return 0; } // 基类函数,可被子类覆盖 }; class Circle : public Shape { public: Circle(double r) : radius(r) {} virtual double area() const override { return 3.14*radius*radius; } // 子类覆盖了基类的area函数,实现了多态 private: double radius; }; class Rectangle : public Shape { public: Rectangle(double w, double h) : width(w), height(h) {} virtual double area() const override { return width*height; } // 子类覆盖了基类的area函数,实现了多态 private: double width; double height; }; int main() { Shape* shape1 = new Circle(5.
QEMU CAN总线 在我的博客《qemu常用参数选项说明》中我介绍的一些常用的qemu参数配置,而对于嵌入式开发往往还会涉及到更多形形色色的系统总线和硬件,本文来讲述下使用qemu can总线的用法。
qemu参数配置 qemu支持can模拟的硬件不多,如果是官网下载的qemu我这里推荐使用xlnx zynqmp这个board,但是本文这里直接选择我的系列博客《基于qemu-riscv从0开始构建嵌入式linux系统》中自制的quard-star板,目前开源在github和gitee上的代码均已支持CAN模拟。
qemu启动参数如下:
-M quard-star,canbus=canbus0 -object can-bus,id=canbus0 -object can-host-socketcan,id=socketcan0,if=vcan0,canbus=canbus0 这里参数设置是将host主机上的can设备与qemu模拟的can设备相连接,如果我们host上没有can设备,则需要创建虚拟的vcan,此处vcan0即为我们需要创建的vcan。
vcan0创建 创建config_vcan.sh脚本,内容如下:
#!/bin/bash set -e MODE=\ "config_vcan | \ release_vcan" USER_NAME=$(whoami) USAGE="usage $0 [$MODE] [<CAN_NAME>] " if [ $# == 2 ] ; then CAN_NAME=$1 else CAN_NAME=vcan0 fi config_vcan() { modprobe vcan ip link add dev $CAN_NAME type vcan ip link set up $CAN_NAME } release_vcan() { ip link set down $CAN_NAME ip link delete dev $CAN_NAME } case "
联邦学习的核心是模型聚合算法,常用的有FedAvg(Federated Averaging)算法和FedProx(Federated Proximal)算法。其中,FedAvg算法是一种简单的平均算法,其数学公式如下:
$$w_{t+1}=\sum_{k=1}^{K}\frac{n_k}{n}w_{k,t}$$
其中,
$w_{t+1}$
表示第$t+1$轮的全局模型,
$w_{k,t}$
表示第$t$轮参与方$k$上传的本地模型,
$n_k$
表示参与方$k$的样本数量,$n$表示所有参与方的样本数量之和。
另外,FedProx算法是在FedAvg算法的基础上增加了正则化项,其数学公式如下:
$$w_{t+1}=\sum_{k=1}^{K}\frac{n_k}{n}(w_{k,t}-\eta\nabla f_k(w_{k,t})+\mu(w_{k,t}-w_t))$$
其中,$\eta$表示学习率,$\mu$表示正则化参数,$w_t$表示第$t$轮的全局模型,$\nabla f_k(w_{k,t})$表示参与方$k$在本地数据上的梯度。
也称IIS系统时钟,一般是采样频率的256倍、512倍,384倍。假设采样率是48K,MCLK输出的时钟是采样的256倍,则MCLK会输出 48K*256 = 12.288MHz
在使用springer提供的Latex模板时,期刊参考文献格式为作者+年份的格式,使用\bibliographystyle{spbasic} 格式的参考文献格式,导致文章内参考文献不按顺序引用。解决办法如下:
在论文的latex目录内找到spbasic.bst将其复制并重命名为spbasic_unsort.bst 。打开spbasic_unsort.bst 在1572行和1625行找到SORT (注意为大写)使用%%将SORT注释。注释后为%%SORT。在论文的.tex文件中加入\bibliographystyle{spbasic_unsort} 并在在论文的latex目录内找到.bbl文件将其删除。重新构建即可。
一、SSH远程管理 SSH是一种安全通道协议,用来实现字符界面的远程登录,远程复制等,对通信双方的数据传输进行了加密处理,包括用户登录时输入的用户口令,因此SSH协议具有很好的安全性(系统默认安装,已配置好防火墙和安全控制)
两种配置文件:
1.ssh_config #针对客户端配置文件
2.sshd_config #针对服务端配置文件
1.SSH的组成结构 1.传输层协议(ssh-trans) 服务器认证,保密性、完整性的数据,数据的压缩功能(重要组件)一般运行在TCP/IP的连接上,也可能用于其他可靠的数据流上(主要提供加密技术,密码主机认证,数据完整性、数据压缩、基于主机认证,不能进行用户认证)
2.用户认证协议 向服务器提供客户端用户鉴别的功能,运行在ssh-trans之上,开始执行用户认证,从低层协议接收会话的标识符,认证私钥的所有权
root → 认证用户是否存在,在服务端中有没有这个用户 → 提示输入用户密码 → 认证密码是否和用户相符合 → 登录成功
3.连接协议(ssh-connect)多个加密隧道分成逻辑隧道 他运行在用户认证之上,提供了交互式的登录会话,远程命令的执行,转发TCP/IP的连接
连接协议 → 提供交互式登录 → 用户认证 → 认证用户存在,密码匹配 → 传输协议 → 建立连接
服务端配置文件位置/etc/ssh/sshd_config #ListenAddress 不变 (监听地址) #LoginGraceTime 2m (标识掉即可) #PermitRootLogin yes (允许root登录) #MaxAuthTires 6 (最大密码输入次数) 相关命令:
ssh [用户名]@[IP地址] #远程连接命令行格式
ssh -p [端口号] [用户名]@[IP地址] #指定端口号远程连接
二、远程复制功能 1.SCP命令 将远程主机的文件复制到本机(远程复制)从其他设备复制到本机
远程复制目录
命令:scp -r [用户名]@[IP地址]:[目录全路径] [要复制到本机的位置] ```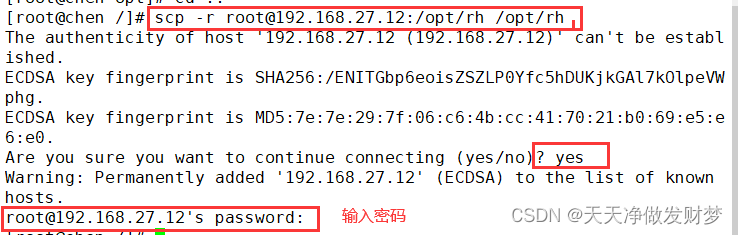 指定端口号并复制到指定主机的本地目录 ```bash 命令:scp -P [端口号] [用户名]@[IP地址]:[目录全路径] [要复制到本机的位置] 2.
一、介绍 1.1、Session、Cookie、Token区别 session:存储再服务端,无法引用与分布式场景,并且需要占用服务端的资源
cookie:存储再客户端,适用于分布式场景,但是存在安全问题,不支持垮域访问
token:存储在localstorage中,更加灵活
1.2、如何实现登录认证 用户使用账号密码登录成功通过JWT生成一串字符串作为Token,返回给前端前端每次请求的时候都在请求头中携带上这个Token后端每次都使用JWT对该Token进行校验,还原出一些用户信息,以此来判断用户是否登录 1.3、JWT组成 1.3.1、样例 eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJkYXRhIjpbXSwiaWF0IjoxNjg0ODIzNzIzLCJleHAiOjE2ODQ4NTc1OTksImF1ZCI6IiIsImlzcyI6ImFxaSIsInN1YiI6IiJ9.W306xll5X2lHWL_B0AUZs7nf9e7Zn5QvgoasnviBeaQ
1.3.2、组成 JWT生成的字符串由三个部分组成
第一部分(header:JWT头,该部分只用Base64编码,未加密)
头部由2个属性组成
1、typ:令牌类型,固定设置为JWT
2、alg:加密算法,默认为HS256
第二部分(Payload:有效载荷,该部分只用Base64编码,未加密,避免存放隐私信息)
就是JWT的主体部分
1、issuer:发行者
2、IssuedAt:发布时间
3、expiration:到期时间
4、subject:主题
5、Not Before:生效时间
6、JWT ID:用于标识该 JWT
7、audience:用户
第三部分(Signature:签名,该部分是安全的,无法被解密)
该部分可以设置secret(俗称:加盐)的方式增加该部分的破解难度
1.4、优缺点 1.4.1、优点 是json格式,跨语言的可以利用Payload存储一些非敏感的信息不需要存储在服务端,可以用于分布式场景一般存储在localStorage中,不存在于Cookie中,避免了一些安全性问题便于实现单点登录功能 1.4.2、缺点 一旦生成就无法修改过期时间,需要搭配缓存来实现过期或者退出效果同样Token过期无法进行续签不可以在JWT中存储敏感信息 二、使用 2.1、引入POM依赖 <dependency> <groupId>io.jsonwebtoken</groupId> <artifactId>jjwt</artifactId> <version>0.9.1</version> </dependency> 2.2、编写工具类 package com.xx.utils; import io.jsonwebtoken.Claims; import io.jsonwebtoken.Jws; import io.jsonwebtoken.Jwts; import io.jsonwebtoken.SignatureAlgorithm; import org.springframework.util.StringUtils; import javax.servlet.http.HttpServletRequest; import java.util.Date; /** * @author aqi * DateTime: 2020/11/9 3:27 下午 * Description: JWT工具类 */ public class JwtUtils { /** * 设置Token过期时间 */ public static final long EXPIRE = 1000 * 60 * 60 * 24; /** * 秘钥 */ public static final String APP_SECRET = "
算术单元构造 文章目录 算术单元构造前言一、半加器二、全加器二、减法器 前言 通过上一节的内容,我们已经了解了如何“创造”出我们最基本的模块——与、或、非门,并使用这些基本模块构建出了与非门、或非门、异或门等。
在这一节中我们将构建计算机最主要的功能模块——计算。众所周知,计算机干的工作就是计算功能,所以我们通过计算的原理来来构建算术单元。
一、半加器 加法器的构造解释有很多,大多都是从加法的一个实例来解释。有人会产生困惑,为什么自己手算很流畅的加法竖式,但是在转换成电路设计的时候还是理解不了为什么要这样设计?
这里我认为是我们的思维还没有从改变过来。在我们学习的开始,我们也是一步一步走过来的,我们需要先算两个数的相加,然后判断是否进位,最后是进位符号是否参与运算。或许是我们经过多年的计算已经把这样的流程自然而然一步到位,但是电路设计还是要一步一步来设计,分而治之。
加法计算过程:
0 + 0 -> 0 0
0 + 1 -> 0 1
1 + 0 -> 0 1
1 + 1 -> 1 0
异或门(XOR)的真值表
XYZ000011101110 与门(AND)的真值表 XYZ000010100111 观察上面加法计算的计算过程,计算结果分为两列,前面的一列为进位后得到的结果,得到的结果与与门的真值表输出的结果一致。后面一列为两个数相加的结果。相加的结果与异或门真值表输出的结果一致。所以,半加器的构造可以使用一个异或门和与门进行构造。 半加器构造图如下:
为了降低电路对我们理解上的困惑,我们会对电路进行封装,然而接口是对应的。如果对电路内部好奇,想知道它的全貌,那就把封装电路替换成真实电路即可。
二、全加器 半加器虽然可以解决两个数的相加,但距离真正的加法计算还有一步的距离。回想十进制的加法,两个整数相加,流程为:
个位计算:个位 + 个位 = 进位 数值十位计算:十位 + 十位 + 个位的进位 = 进位 数值百位计算:百位 + 百位 + 十位的进位 = 进位 数值 从上面的加法过程中可以看出,半加器的那一步距离就是进位,在个位的计算当中,可以写成 个位 + 个位 + 进位 0 = 进位 数值 的形式。
文章目录 前言数据结构`线性表``数组``链表``栈与队列`[串/字符串] 树并查集`二叉树`[二叉排序树/二叉搜索树]`红黑树`红黑树操作 霍夫曼树`堆`[大/小]根堆可并堆 多叉树B-树B+树 图最短路最小生成树网络流建模 复合型`[散列表/哈希表]`[散列树/哈希树][Trie树/字典树] 算法算法复杂度`时间复杂度`空间复杂度 基础算法问题全排列问题爬楼梯问题背包问题八皇后问题 基础算法思想枚举`递归`贪心算法滑动窗口算法深度优先搜索算法与广度优先搜索算法DFS例子BFS例子 分治算法回溯算法倍增算法 `动态规划`爬楼梯问题国王和金矿问题 `[查找/搜索]`[线性搜索/线性查找/遍历查找/顺序搜索]`[二分算法/二分查找/二分搜索/折半查找]`剪枝技巧插值查找法斐波那契查找法线性索引 `排序算法`冒泡排序选择排序`快速排序`归并排序计数排序桶排序插入排序希儿排序堆排序跳舞链 附录1:力扣刷题`刷题技巧`刷题套路高频算法模版`双指针`二分查找广度优先搜索深度优先搜索[二叉搜索树/二叉排序树/二叉查找树]模板动态规划模板 前言 数据结构 + 算法 = 程序。
无论从事前端还是后端,无论使用什么编程语言,
只要想进大厂,都绕不开考核数据结构与算法这道坎,
本文中的代码均用Java编写,当然,也可以使用其他语言来实现。
其实编程语言并不是最重要的,思想才是,逻辑思维才是。
本文大部分内容并不是作者原创,
只是记录作者在学习算法与数据结构过程中的点点滴滴,
如有侵权,请在评论中及时指出。
本文理论上是对[新手/小白]友好的,
如果有不明白的地方可以评论指出。
本文内容较多,
建议先纵览一下文章顶部的目录,
再结合左侧目录阅读。
先把基本的数据结构弄明白,例如:数组,链表,哈希表等等。
之后再去看一些基本的算法,例如:枚举,递归,二分查找等等。
再循序渐进。
注意事项:
[堆栈]作为计算机科学中的一个专有词语,操作系统中的[堆栈]和数据结构中的[堆栈]不是一个概念;算法中的[枚举]与Java中的[枚举]不是一个概念; 基本概念:
[遍历/迭代]:迭代通常指在数据结构中按顺序逐个访问元素的过程,例如使用循环语句逐个访问数组、列表或树中的元素。遍历通常指访问整个数据结构中的所有元素,无论是按照某种特定的顺序还是按照某种规则,例如深度优先搜索算法和广度优先搜索算法都是树的遍历算法; 数据结构 数据结构可以优化算法效率,同一个算法用不同的数据结构,
可能会带来完全不一样的时间和空间(时间与空间互换)。
例如:平衡二叉树与数组都能实现查找功能,
但两者的时间复杂度分别是:O(n),O(logn)。
涉及到时间复杂度的地方,如果读者不懂,
可以先跃迁至本文的“算法”部分,里面有个小章节有专门讲解。
不管是什么数据结构,在内存中的存储中方只有两种:
数组(顺序存储);链表(链式存储); [常用/常见]数据结构:
数组;链表;[散列表/哈希表];栈与队列;二叉树;堆;跳表;图;[Trie树/字典树];字符串; 以下是最简单的十个数据结构,按照难易程度排序:
数组:一组连续的内存单元,可以存储相同类型的数据。链表:一组通过指针连接在一起的节点,每个节点包含数据和指向下一个节点的指针。栈:一种后进先出(LIFO)的数据结构,可以在栈顶进行插入和删除操作。队列:一种先进先出(FIFO)的数据结构,可以在队尾插入和在队头删除元素。树:一组通过边连接在一起的节点,每个节点可以有多个子节点。图:一组通过边连接在一起的节点,每个节点可以有多个相邻节点。哈希表:通过哈希函数将键映射到值的数据结构。堆:一种可以快速找到最大或最小值的数据结构,可以用数组或树实现。并查集:一种用于维护集合的数据结构,可以高效地判断两个元素是否在同一集合中。字典树:一种用于高效地存储和搜索字符串的数据结构,可以支持前缀搜索和字符串匹配。 线性表 线性表是最容易理解的数据结构,这是一切开始的地方,
线性表是指存储了多个数据元素的数据结构,
其中的元素是按照线性顺序排列的,
元素具有相邻关系,每个元素最多只有一个前驱和一个后继,
可以按照一定顺序进行存储和访问。
常见的线性表有:数组、链表、队列和栈等。
数组适用于随机访问元素的场景;链表适用于插入和删除元素频繁的场景;栈适用于表达式求值和括号匹配等场景;队列适用于消息传递和任务调度等场景;双向链表适用于需要双向遍历的场景;循环链表适用于需要遍历整个列表的场景; 数组 数组在内存中是紧凑连续的存储,可以随机访问,
通过[索引/index]可以快速找到对应元素,
而且相对节约存储空间。
但正因为连续存储,所以内存空间必须一次性分配够,
如果数组要扩容,则需要重新分配一块更大的空间,
再把数据全部复制过去,时间复杂度为 O(N)。