进入小车测试前非常需要吐槽几句,由于我使用的Autolabor小车底盘非常矮,调车过程需要在点云地图中定位完成才可以进行接下来的规划等步骤,所以不得不在室外蹲在地上抱着键鼠特别别扭的测试,所以建议各位提前准备好马扎还有穿的厚实点(冬天)或者多带点花露水(夏天)。
言归正传,由于是实车测试,需要在搞清楚自己的硬件设备的情况下进行,由于我前期进行了许多杂七杂八的测试导致每个硬件驱动都在独立的工作空间下,每次实车测试前都要开多个终端独立启动四五个launch文件。在这里简单介绍下我所需要在测试前启动的部分:
1、小车底盘的launch,启动后可以通过/cmd_vel话题给小车下发控制指令,同时随launch启动的还有一个键盘控制节点,该节点将键盘消息转化为小车控制指令发送给底盘,是小车自带的程序部分。
2、激光雷达的launch文件,在这里我使用过VLP16以及RS-Helios-16P两款雷达。在测试前均需要对其进行修改,至于如何修改后文详谈。
3、启动Autoware主程序。
4、启动话题信息格式转换节点。
上面的操作流程每个人每种硬件平台各不相同,总而言之流程是相似的:
按照上述的流程来记录我的测试流程,首先需要将小车移动到指定位置,Autolabor小车底盘因为是一个比较完整的底盘,工控机中包含了直接启动底盘的launch文件,该文件可以完成小车状态发布、数据接收以及按键盘控制和rviz显示小车状况的四个节点。由于不需要rviz的显示功能,故在launch中注释掉了这段代码。运行小车launch后就可以用键盘遥控小车到处走了。(成品底盘的优点也就是这方面省心)。 到达测试地点后,首先需要将传感器全部启动,这里主要指的是激光雷达,雷达部分是需要提前设置的,首先是VLP-16雷达,雷达默认的话题名为/velodyne_points,但是Autoware默认接收的激光雷达传感器话题为/points_raw。在这里需要修改velodyne雷达的驱动来将发布话题进行修改。或许有人发现Autoware内置了VLP16的启动launch,但是我测试的时候发现从Autoware中内置的启动方法会报错,无论添不添加yaml文件都会报错。所以,考虑到不确定排错时间成本上不如多开一个终端来的简单方便。
此外当时寻找velodyne的话题发布程序位置花了一段时间,在这里把代码位置放出来,使用同款雷达的可以参考修改话题。位置在velodyne功能包下面的velodyne_pointcloud/src/conversions/transform.cc文件内,程序内有一行:
output_=node.advertise<sensor_msgs::PointCloud2>(“velodyne_points”,10); 可以在这里修改雷达的话题名。
同时还测试了一款RS-Helios-16P雷达,这款雷达设置起来稍微麻烦一些,因为前期建图使用的Lio-sam,算法要求激光雷达要用ring等信息,所以为了程序都可以适配起来,干脆直接将雷达的信息完全改成VLP16的雷达信息格式,同时修改雷达发布的话题名。
rs2velodyne转换功能包从网上下载,具体出处忘记了,这里放一个百度网盘的链接吧。
链接: https://pan.baidu.com/s/1D-TnyMDwOf7AU9D2S9wq-w?pwd=9bjn 提取码: 9bjn。
具体使用方法可以参考功能包中的README,至于输出话题名可以直接在该功能包最后面几行的代码处修改。
pubRobosensePC=node.advertise<sensor_msgs::PointCloud2>(“velodyne_points”,1); 雷达设置完毕后可以简单测试一下定位功能了。将车行驶到测试位置,启动好雷达,然后进入Autoware程序界面,实车测试并不需要像之前一样加载rosbag,可以直接进入setup界面启动tf,按照实际的tf设置即可,设置好后点击左边tf按钮,按钮变蓝表示启动成功。至于下方的vehicle model车辆模型可启动也可以不启动,加载空模型会直接载入默认模型(一辆车)。
接下来进入map选项卡,这里需要加载point cloud、vector map、tf三个部分。首先选择右侧ref按钮,在弹出菜单选中提前准备好的pcd点云图。注意这里需要注意使用Lio-sam建立的点云地图时,只需要加载GlobalMap.pcd一个文件,不要加载CornerMap.pcd,这两个地图在ndt定位环节表现GlobalMap表现要好一些。如果是其他形式的点云地图请根据情况自行选择加载。矢量地图便是将之前使用Unity插件生成的一系列文件全部载入。然后载入tf,tf位置在autoware.ai/src/autoware/documentation/autoware_quickstart_examples/launch/tf_local.launch
接下来进入sensing选项卡,由于雷达已经通过launch启动了,所以这个选项卡只启动两个滤波相关功能。
voxel_grid_filter是体素网格滤波,点击右侧app后打开的窗口有三个参数设置,分别是设置点云话题(points topic)、体素滤波尺寸(voxel Leaf size)以及测量范围(measurement range),在这里三个参数默认即可无需修改。
ring_ground_filter也是一个滤波功能,主要是与上面的滤波结合起来滤去地面的雷达点云数据,同样最上面也是输入的点云话题。Sensor Model表示激光雷达的线数,根据自己的雷达选择对应线数。Sensor Height为雷达相对于地面的安装高度,Max Slope为最大坡度,Vertical Thres为障碍物与地面的差异度阈值。这两个选项共同决定了地面滤波效果。除非路面环境比较特殊,这里的参数默认即可。 地图载入和传感器滤波操作完成后,这个时候就可以打开Autoware人机交互界面右下角的rviz按钮启动rviz了,这里如果之前没有跑过历程,还没加载过rviz的配置文件的话,需要加载autoware.ai/src/autoware/documentation/autoware_quickstart_examples/launch/rosbag_demo/default.rviz
加载完成后的rviz应该是显示有点云地图和矢量地图,如果不显示的话,回到map选项卡重新载入点云地图和矢量地图,如果发现rviz中没有点云地图而且重新加载后也没有点云地图,可以修改rviz左侧的Global Options-fixed frame的参数,将默认的world修改为velodyne和map查看下是否有画面。因为在前期测试历程时发现Autoware给定的world2map的tf中设置了非常大的值,导致world坐标系和map坐标系相去甚远,可以检查下之前加载的tf文件有没有这样的情况,有的话可以将x、y值改为0让两个坐标重合。
接下来进入Computing选项卡,打开lidar_localizar下ndt_matching的参数设置,由于没有GPS,所以不选择GNSS,选择Initial Pos参数默认000即可。下方Method Type根据自己的设备,没有GPU选择pcl_generic。反之选择pcl_anh_gpu。
参数设置完毕后勾选ndt_matching,顺带勾选autoware_connector下的vel_pose_connect,勾选前打开看一下参数里面只要没有勾选Simulation Mode即可。
正常情况下传感器传来的点云数据(红黄色)会马上出现在rviz中的初始位置。同时左上角会实时显示NDT匹配的毫秒数。此时选中 rviz上面的2D Pose Estimate,然后在地图中给定一个带方向的初始值以用于定位(箭头指向方向代表车辆前进方向)。
到这里没有问题的话应该是可以定位成功,如果定位失败可以再尝试给新的初值。
1.引言 最近又来了几个面试机会,心情复杂,本来都开始准备二战了,加上老妈给我说了句你放心二战,不希望自己边工作边二战,二战的钱还是有的,搞得我确实心情复杂。既然有厂给机会了还是得准备准备,毕竟每次都是多个厂一起来,也不亏的。这次本来以为是小公司但是没想到确实腾讯的来面试,整体感觉有点友好。
2.没答好的题目 这里直接也不怕丢人,没答好的题目直接放下来:
(1)ISO7层网络模型(当时考研选的是除了计网的408):
物理层:实现相邻计算机节点之间比特流的透明传送,尽可能屏蔽掉具体传输介质和物理设备的差异(可以理解成很多厂家的接口不一样,可能会导致兼容问题);
数据链路层:通过差错控制、流量控制方法,使有差错的物理线路变为无差错的数据链路,即提供可靠的通过物理介质传输数据的方法;
网络层:包含有常用的网络层协议,数据链路层的数据在这一层被转换为数据包,然后通过路径选择、分段组合、顺序、进/出路由等控制,将信息从一个网络设备传送到另一个网络设备;
传输层:向用户提供可靠的端到端的差错和流量控制,保证报文的正确传输;
会话层:组织和协调两个会话进程之间的通信,并对数据交换进行管理。用户可以按照半双工、单工和全双工的方式建立会话,单工指的是数据的传输是单向的,双工是指数据的传输可以双向同时进行,半双工指的是数据的传输可以双向不同时进行;
表示层:处理用户信息的表示问题,如编码、数据格式转换和加密解密;
应用层:计算机用户、各种应用程序和网络之间的接口,其功能是直接向用户提供服务,完成用户希望在网络上完成的各种工作。
(2)3次握手和四次挥手:
三次握手:第一次客户端向服务端发送一个带有SYN标志的数据包,具体内容为SYN=1,seq=x,x为随机生成数值;第二次握手服务端接受一个带有SYN/ACK标志的数据包确认信息,具体内容为SYN=1,ACK=x+1,seq=y,y为随机生成数值;第三次客户端回传一个ACK标志的数据包,具体内容为SYN=1,ACK=y+1,seq=x+1。
四次挥手:第一次挥手客户端发送一个带FIN标志位的数据包(内容为FIN=1,seq=x),用来关闭从客户端到服务端的数据传送,并进入FIN_WAIT_1状态;第二次挥手服务端接受到客户端的FIN数据包之后给客户端发送一个带ACK标志位的数据包(内容为FIN=1,ack=x+1,seq=y),同时服务端进入CLOSE_WAIT状态;第三次挥手服务端发送一个FIN用来关闭服务端到客户端的数据传送(内容为FIN=1,ack=x+1,seq=z),服务端进入LAST_ACK状态;第四次挥手客户端接受到FIN数据包之后,进入TIME_WAIT状态,接着向服务端发送一个ACK数据包(内容为FIN=1,ack=z+1,seq=h),服务端接受之后进入CLOSED状态,完成断开连接。
(3)web缓存:
web缓存主要可以分成三大类:数据库缓存、服务器端缓存以及浏览器缓存,数据库缓存比如redis,服务器端缓存包括代理服务器缓存、CDN缓存等,浏览器缓存算是常考了:cookie、session、localstorage、sessionStorage、indexedDB,浏览器缓存还有http缓存(这里没有答上来),http缓存只针对于get请求,当客户端向服务器请求资源时,会先获取该资源缓存的header信息,结合expires有效期,如果命中强缓存返回200,如果命中协商缓存返回304,Expires是一个GMT格式的时间字符串,用来标识资源的失效时间,Cache-Control字段包含的值有:public(客户端和服务端都可以用来缓存数据)、private(只让客户端缓存数据)、immutable(即使用户刷新数据,在有效期内也不会刷新)、no-cache(跳过设置强缓存,但是依然可以设置协商缓存)、no-store(不缓存)。
协商缓存命中将会返回最新header同时提醒浏览器去调用缓存里面的内容,last-modified用于和请求头里面的last-modified-since对比,如果相等则表示协商缓存命中,但是last-modified只要编辑了就会标记为修改了,只能精确到秒级,因此出现了etag,基于内容生成一个标识字符串,请求头带有一个if-no-match(其值是上一次的etag),如果两次一致说明协商缓存命中。
(4)如何实现两个对象的实例相等:
//让两个对象的实例相等 function Single() {} const obj1 = new Single(); const obj2 = new Single(); console.log("第一次比较两个对象:", obj1 === obj2);//false //借鉴单例模式实现 let _instance = null; function singleTon() { if (!_instance) _instance = new Single(); return _instance; } const obj3 = new singleTon(); const obj4 = new singleTon(); console.log("第二次比较两个对象:", obj3 === obj4);//true (5)事件循环机制
排行榜: 在CMU-MOSE数据集排行榜
CMU-MOSEI Benchmark (Multimodal Sentiment Analysis) | Papers With Code
在MOSI数据集排行榜
MOSI Benchmark (Multimodal Sentiment Analysis) | Papers With Code
2022年 《M-SENA: An Integrated Platform for Multimodal Sentiment Analysis》
ACL;ACL ; star:317;2022
UniMSE: Towards Unified Multimodal Sentiment Analysis and Emotion Recognition
star:44; 2022; MOSI数据排行第1
MMLatch: Bottom-up Top-down Fusion for Multimodal Sentiment Analysis
star:14; 2022; CMU-MOSEI排行第3
The MuSe 2022 Multimodal Sentiment Analysis Challenge: Humor, Emotional Reactions, and Stressstar:19;2022;
Sentiment Word Aware Multimodal Refinement for Multimodal Sentiment Analysis with ASR Errors
import axios from "axios"; const timeout = 60000; // 请求超时时间和延迟请求超时时间统一设置 const config = { baseURL: '接口前缀', timeout, headers: { "Content-Type": "application/json", "Authorization": sessionStorage.getItem("token") } }; const instance = axios.create(config); instance.interceptors.request.use(async (config) => { if (!config.extraConfig?.tokenRetryCount) { config.extraConfig = { tokenRetryCount: 0, }; } (config.headers)["Authorization"] = sessionStorage.getItem("token"); return config; }); /** * http response 拦截器 */ instance.interceptors.response.use( (response) => { return response.data; }, async (err) => { if (axios.isCancel(err)) { // 取消的请求,不报错 return; } if (err.
解题 1.暴力循环
import java.util.*; public class Main { public static void main(String[] args) { Scanner scanner = new Scanner(System.in); long L = scanner.nextLong(); L /= 1000;//题目说毫秒不计 int a = 365*24*60*60;//非闰年一年秒数 int b = 366*24*60*60;//闰年一年秒数 int i = 1970;//起始 String s = ""; while(L/a!=0){//循环减去年份秒数直到只剩一年的秒数 if(i%400==0 || i%4==0&&i%100!=0){ L-=b; }else { L-=a; } i++; } L%=24*60*60;//取余表示最后一天的秒数 int x = (int)L/(60*60); int y = (int)L%(60*60)/60; int z = (int)L%(60*60)%60; if(x>9){ s+=x; }else { s+="
分布式事务 1.基础概念1.1.什么是事务1.2.本地事务1.3.分布式事务1.4 分布式事务产生的场景 2.分布式事务基础理论2.1.CAP理论2.1.1.理解CAP2.1.2.CAP组合方式2.1.3 总结 2.2.BASE理论 3.分布式事务解决方案之2PC(两阶段提交)3.1.什么是2PC3.2.解决方案3.2.1 XA方案3.2.2 Seata方案 3.3.seata实现2PC事务3.3.1.业务说明3.3.2.程序组成部分3.3.3.创建数据库3.3.4.启动TC(事务协调器)3.3.5 discover-server3.3.6 Seata执行流程3.3.7 导入案例工程dtx-seata-demo3.3.8 dtx-seata-demo-bank13.3.9 dtx-seata-demo-bank23.3.10 测试场景3.4.小结 4.分布式事务解决方案之TCC4.1.什么是TCC事务4.2.TCC 解决方案4.3.Hmily实现TCC事务4.3.1.业务说明4.3.2.程序组成部分4.3.3.创建数据库4.3.4 discover-server4.3.5 导入案例工程dtx-tcc-demo4.3.6 dtx-tcc-demo-bank14.3.7 dtx-tcc-demo-bank24.3.8 测试场景 4.4.小结 5.分布式事务解决方案之可靠消息最终一致性5.1.什么是可靠消息最终一致性事务5.2.解决方案5.2.1.本地消息表方案5.2.2.RocketMQ事务消息方案 5.3.RocketMQ实现可靠消息最终一致性事务5.3.1.业务说明5.3.2.程序组成部分5.3.3.创建数据库5.3.4.启动RocketMQ5.3.5 导入dtx-txmsg-demo5.3.6 消息发送发:dtx-txmsg-demo-bank15.3.7 消息消费者:dtx-txmsg-demo-bank25.3.8 测试场景 5.4.小结 6.分布式事务解决方案之最大努力通知6.1.什么是最大努力通知6.2.解决方案6.3.RocketMQ实现最大努力通知型事务6.3.1.业务说明6.3.2.程序组成部分6.3.3.创建数据库6.3.4.启动RocketMQ6.3.5 discover-server6.3.6 导入dtx-notifymsg-demo6.3.7 消息发送方:dtx-notifydemo-pay6.3.8 消息接收方:dtx-notifydemo-bank16.3.9 测试场景 6.4.小结 7.分布式事务综合案例分析7.1.系统介绍7.1.1.P2P介绍7.1.2.总体业务流程7.1.2.业务术语7.1.2.模块说明 7.2.注册账号案例分析7.2.1.业务流程7.2.2.解决方案分析 7.3.存管开户7.3.1.业务流程7.3.2.解决方案分析 7.4.满标审核7.4.1.业务流程7.4.2.解决方案分析 8.课程总结重点知识回顾:分布式事务对比分析:总结: 1.基础概念 1.1.什么是事务 什么是事务?举个生活中的例子:你去小卖铺买东西,“一手交钱,一手交货”就是一个事务的例子,交钱和交货必须全部成功,事务才算成功,任一个活动失败,事务将撤销所有已成功的活动。
明白上述例子,再来看事务的定义:
事务可以看做是一次大的活动,它由不同的小活动组成,这些活动要么全部成功,要么全部失败。
1.2.本地事务 在计算机系统中,更多的是通过关系型数据库来控制事务,这是利用数据库本身的事务特性来实现的,因此叫数据库事务,由于应用主要靠关系数据库来控制事务,而数据库通常和应用在同一个服务器,所以基于关系型数据库的事务又被称为本地事务。 回顾一下数据库事务的四大特性 ACID:
A(Atomic):原子性,构成事务的所有操作,要么都执行完成,要么全部不执行,不可能出现部分成功部分失败的情况。C(Consistency):一致性,在事务执行前后,数据库的一致性约束没有被破坏。比如:张三向李四转100元,转账前和转账后的数据是正确状态这叫一致性,如果出现张三转出100元,李四账户没有增加100元这就出现了数据错误,就没有达到一致性。I(Isolation):隔离性,数据库中的事务一般都是并发的,隔离性是指并发的两个事务的执行互不干扰,一个事务不能看到其他事务运行过程的中间状态。通过配置事务隔离级别可以避脏读、重复读等问题。D(Durability):持久性,事务完成之后,该事务对数据的更改会被持久化到数据库,且不会被回滚。 数据库事务在实现时会将一次事务涉及的所有操作全部纳入到一个不可分割的执行单元,该执行单元中的所有操作要么都成功,要么都失败,只要其中任一操作执行失败,都将导致整个事务的回滚
1.3.分布式事务 随着互联网的快速发展,软件系统由原来的单体应用转变为分布式应用,下图描述了单体应用向微服务的演变:
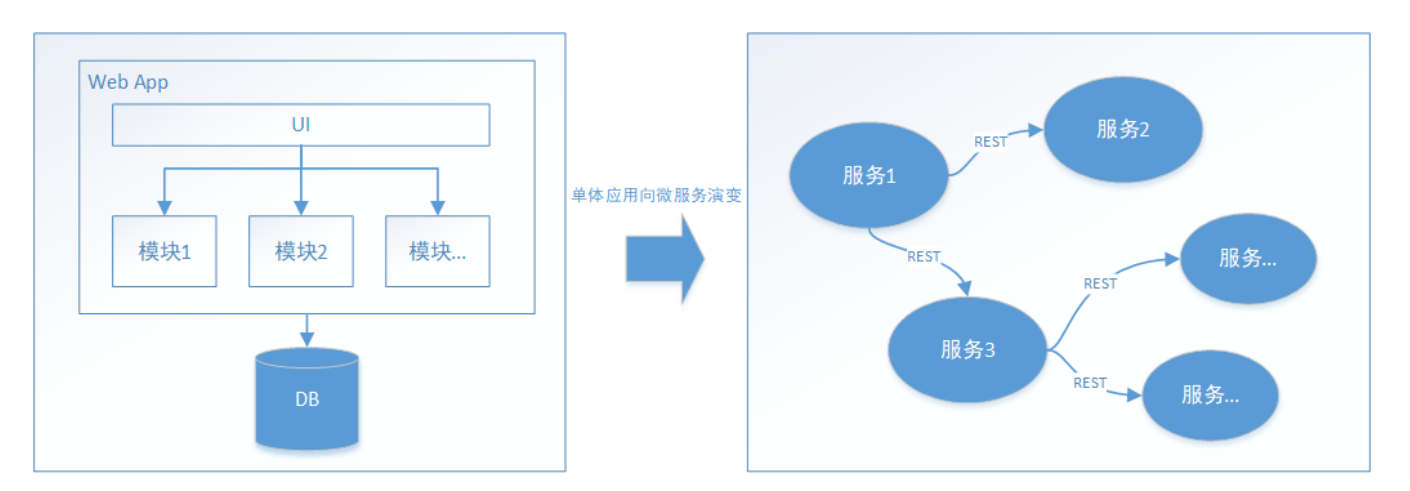
分布式系统会把一个应用系统拆分为可独立部署的多个服务,因此需要服务与服务之间远程协作才能完成事务操作,这种分布式系统环境下由不同的服务之间通过网络远程协作完成事务称之为分布式事务,例如用户注册送积分事务、创建订单减库存事务,银行转账事务等都是分布式事务。
我们知道本地事务依赖数据库本身提供的事务特性来实现,因此以下逻辑可以控制本地事务:
begin transaction; //1.本地数据库操作:张三减少金额 //2.本地数据库操作:李四增加金额 commit transation; 但是在分布式环境下,会变成下边这样:
begin transaction; //1.
分布式锁 1. 分布式锁1.1 为什么要用分布式锁1.2 分布式锁应该具备哪些条件1.3 三种实现分布式锁的方式1.4 三种方式对比1.5 基于数据库实现分布式锁1.6 基于Redis实现分布式锁1.6.1 setnx命令1.6.2 setnx expire1.6.3 Redisson1.6.4 RedLock 1.7 基于Zookeeper实现分布式锁 1. 分布式锁 1.1 为什么要用分布式锁 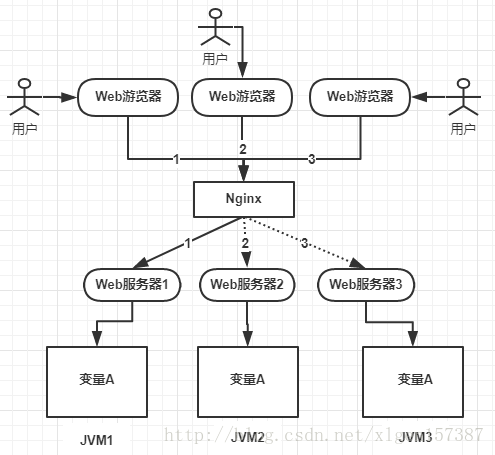
从上图可以看到,变量A存在JVM1、JVM2、JVM3三台服务器上。如果不加任何控制的话,变量A同时会被在每个JVM中分配一块内存,三个请求过来同时对这个变量操作,结果显然是不对的。
三个请求分别操作三个不同JVM内存区域中的数据,变量A之间不存在共享,也不具有可见性,处理的结果也是不对的。
为了保证一个方法或者属性在高并发的情况下,同一时间只能被同一个线程执行,在传统单体应用及其部署的情况下可以使用Java并发处理相关的API(如ReentranLock或Synchronized)进行控制。但是在分布式集群中,由于分布式多线程且分布在不同的机器上,单纯的java API并不能提供分布式锁的能力。所以需要用分布式锁来解决跨JVM的互斥机制来控制共享资源的访问。
1.2 分布式锁应该具备哪些条件 在分布式系统环境下,一个方法在同一时间只能内一个机器的一个线程执行高可用的获取锁和释放锁高性能的获取锁和释放锁具备可重入特性具备锁失效机制,防止死锁具备非阻塞锁特性,即没有获取到锁将直接返回获取锁失败 1.3 三种实现分布式锁的方式 基于数据库实现分布式锁基于Redis实现分布式锁基于Zookeeper实现分布式锁 1.4 三种方式对比 分类方案实现原理优点缺点基于数据库基于MySQL表唯一索引1)表增加唯一索引2)加锁:执行insert语句,若报错则表明加锁失败3)解锁:执行delete语句完全利用DB现有能力,实现简单1)锁无超时自动失效机制,有死锁风险2)不支持锁重入,不支持阻塞等待3)操作数据库开销大,性能不高基于分布式协调系统基于Zookeeper1)加锁:在/lock目录下创建临时有序节点,判断创建的节点序号是否最小。若是则表示获取到锁;否则watch /lock目录下序号比自身小的前一个节点2)解锁:删除节点1)有zk保障系统高可用2)Curator框架已原生支持系列分布式锁命令,使用简单需要单独维护一套zk集群,维保成本高基于缓存基于redis命令1)加锁:执行setnx命令,若成功再执行expire添加过期时间2)解锁:执行delete命令实现简单,相比数据库和Zookeeper的实现,该方案最轻,性能最好1)setnx和expire分两步执行,非原子操作,可能会出现死锁2)delete命令存在误删,除非当前线程保持有锁的可能3)不支持阻塞等待,不可重入基于redis Luau脚本1)加锁:实行 SET lock_nam random_value EX seconds NX命令2)解锁:执行Luau脚本,释放锁时验证random_value– ARGV[1]为random_value, KEYS[1]为lock_nameif redis.call(“get”, KEYS[1]) == ARGV[1] thenreturn redis.call(“del”,KEYS[1])elsereturn 0end同上;实现逻辑上也更严谨,除了单点问题,生产环境采用这种方案,问题也不大不支持锁重入,不支持阻塞等待 1.5 基于数据库实现分布式锁 乐观锁:
DROP TABLE IF EXISTS `method_lock`; CREATE TABLE `method_lock` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键', `method_name` varchar(64) NOT NULL COMMENT '锁定的方法名', `state` tinyint NOT NULL COMMENT '1:未分配;2:已分配', `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, `version` int NOT NULL COMMENT '版本号', `PRIMARY KEY (`id`), UNIQUE KEY `uidx_method_name` (`method_name`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8 COMMENT='锁定中的方法'; 1)先获取锁的信息
一,安装及配置 1.下载英特尔® Distribution of OpenVINO™ toolkit package 安装包
choice1:去官网下载
Download Intel® Distribution of OpenVINO™ Toolkit
版本选如下版本
2.解压安装包(以下皆以l_openvino_toolkit_p_2021.4.752为例)
tar -xvzf l_openvino_toolkit_p_2021.4.752.tgz 3.来到l_openvino_toolkit_p_2021.4.752目录
cd l_openvino_toolkit_p_2021.4.752 4.使用图形用户界面 (GUI) 安装向导
sudo ./install_GUI.sh ( 如果你已经有opencv,那么在勾选安装产品时可以选择不安装opencv,会造成高版本的opencv与低版本的opencv冲突)
5.安装外部依赖:
cd /opt /intel /openvino_ 2021 /install_dependencies sudo -E . /install_openvino_dependencies.sh 6.配置环境
gedit ~/.bashrc 将下述命令行添加至最后一行
source /opt/intel/openvino_2021/bin/setupvars.sh (验证):新打开一个终端,看见[setupvars.sh] OpenVINO environment initialized.证明成功。
7.
cd /opt /intel /openvino_ 2021 /deployment_tools /model_optimizer /install_prerequisites sudo . /install_prerequisites_onnx.sh 至此环境配置成功。
二,GPU选择性安装: 如果你是锐龙的显卡和集显,则不需要配置GPU环境,用CPU跑即可。
查看显卡信息
lspci -k | grep -A 2 -i "
目录 数据同步一.思路分析1.同步调用2.异步通知3.监听binlog4.选择 二.实现数据同步1.思路2.导入demo3.声明交换机、队列3.1引入依赖3.2 配置文件3.3 声明队列交换机名称3.4 声明队列交换机 4.发送MQ消息4.1 事务配置类4.2 service 代码 5.接收MQ消息 数据同步 elasticsearch中的酒店数据来自于mysql数据库,因此mysql数据发生改变时,elasticsearch也必须跟着改变,这个就是elasticsearch与mysql之间的数据同步。
一.思路分析 常见的数据同步方案有三种:
同步调用异步通知监听binlog 1.同步调用 方案一:同步调用
基本步骤如下:
hotel-demo对外提供接口,用来修改elasticsearch中的数据酒店管理服务在完成数据库操作后,直接调用hotel-demo提供的接口, 2.异步通知 方案二:异步通知
流程如下:
hotel-admin对mysql数据库数据完成增、删、改后,发送MQ消息hotel-demo监听MQ,接收到消息后完成elasticsearch数据修改 3.监听binlog 方案三:监听binlog
流程如下:
给mysql开启binlog功能mysql完成增、删、改操作都会记录在binlog中hotel-demo基于canal监听binlog变化,实时更新elasticsearch中的内容 4.选择 方式一:同步调用
优点:实现简单,粗暴缺点:业务耦合度高 方式二:异步通知
优点:低耦合,实现难度一般缺点:依赖mq的可靠性 方式三:监听binlog
优点:完全解除服务间耦合缺点:开启binlog增加数据库负担、实现复杂度高 二.实现数据同步 1.思路 利用课前资料提供的hotel-admin项目作为酒店管理的微服务。当酒店数据发生增、删、改时,要求对elasticsearch中数据也要完成相同操作。
步骤:
导入课前资料提供的hotel-admin项目,启动并测试酒店数据的CRUD
声明exchange、queue、RoutingKey
在hotel-admin中的增、删、改业务中完成消息发送
在hotel-demo中完成消息监听,并更新elasticsearch中数据
启动并测试数据同步功能
2.导入demo 资料:资料在这里
导入资料提供的hotel-admin项目:
运行后,访问 http://localhost:8099
其中包含了酒店的CRUD功能:
3.声明交换机、队列 MQ结构如图:
3.1引入依赖 在hotel-admin、hotel-demo中引入rabbitmq的依赖:
<!--amqp--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-amqp</artifactId> </dependency> 3.2 配置文件 spring: rabbitmq: host: 192.168.1.100 username: guest password: guest virtual-host: / 3.
日常开发中,大家经常使用缓存,但是你知道大型的互联网公司面对高并发流量,要注意缓存穿透问题吗!!! 本文会介绍布隆过滤器,空间换时间,以较低的内存空间、高效解决这个问题。
本篇文章的目录:
1、性能不够,缓存来凑 现在的年轻人都喜欢网购,没事就逛逛淘宝,剁剁手,买些自己喜欢的东西,释放下工作压力。
地址:
https://detail.tmall.com/item.htm?id=628993216729
上图是一个天猫 iphone12 的商品详情页,id表示商品的编号
我们都知道淘宝的访问量是非常高的,为了提升系统的吞吐量,做了很多性能优化,其中非常重要一点是将信息异构到缓存中。
有句话说的好:性能不够,缓存来凑。
但是,使用缓存时,我们要关注一个重要问题,如果缓存没有命中怎么办?
2、缓存没有命中,怎么办? ①我们先查询缓存,判断缓存中是否有数据
②如果有数据,直接返回
③如果缓存为空,我们需要再查一次数据库,并将数据格式异构化,然后预热到缓冲中,然后将结果返回
注意:
步骤 ③ 存在风险漏洞,如果缓存中数据不存在,压力会转嫁给数据库。假如被竞争对手利用,搞无效请求流量攻击,瞬间大量请求打到数据库中,对系统性能产生很大影响,很容易把数据库打挂,这种现象称为缓存穿透。
3、那么如何处理缓存穿透? 我们的思路是,缓存中能不能判断这个数据库值的存在性,如果真的不存在,直接返回,也避免一次数据库查询。
由于不存在是个无限边界,所以,我们采用反向策略,将存在的值建立一个高效的检索。每次缓存取值时,先走一次判空检索。
简单归纳下,这个框架的要求:
快速检索
内存空间要非常小
经调研,我们发现布隆过滤器具备以上两个条件。
4、什么是布隆过滤器? 布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。
优点:空间效率和查询时间都远远超过一般的算法。
缺点:有一定的误识别率,删除困难。
5、布隆过滤器如何构建? 布隆过滤器本质上是一个 n 位的二进制数组,用0和1表示。
假如我们以商品为例,有三件商品,商品编码分别为,id1、id2、id3
a)首先,对id1,进行三次哈希,并确定其在二进制数组中的位置。
三次哈希,对应的二进制数组下标分别是 2、5、8,将原始数据从 0 变为 1。
b)对id2,进行三次哈希,并确定其在二进制数组中的位置。
三次哈希,对应的二进制数组下标分别是 2、7、98,将原始数据从 0 变为 1。
下标 2,之前已经被操作设置成 1,则本次认为是哈希冲突,不需要改动。
Hash 规则:如果在 Hash 后,原始位它是 0 的话,将其从 0 变为 1;如果本身这一位就是 1 的话,则保持不变。
6、布隆过滤器如何使用? 跟初始化的过程有点类似,当查询一件商品的缓存信息时,我们首先要判断这件商品是否存在。
通过三个哈希函数对商品id计算哈希值然后,在布隆数组中查找访问对应的位值,0或1判断,三个值中,只要有一个不是1,那么我们认为数据是不存在的。 注意:布隆过滤器只能精确判断数据不存在情况,对于存在我们只能说是可能,因为存在Hash冲突情况,当然这个概率非常低。
7、如何减少布隆过滤器的误判? a)增加二进制位数组的长度。这样经过hash后数据会更加的离散化,出现冲突的概率会大大降低
一、前言 世纪九十年代,传统OPC通信技术的诞生为不同生产商的工业设备通讯建立一整套开放的接口、属性和方法标准集,进而实现了不同协议设备和上位机之间的通讯。随着工业4.0的快速推进,越来越多的用户希望将设备数据上传到物联网平台实现数据的统筹管理,MQTT作为物联网协议,常常用于物联网平台数据的采集。因此,本文主要介绍如何通过虹科OPC Client for MQTT软件实现OPC DA Server和MQTT Broker之间的数据交互。
二、工具 1. 软件:OPC DA Server 、虹科OPC Client for MQTT、虹科HiveMQ MQTT Broker、MQTT.fx
2. 硬件:1台Windows 10 PC
三、MQTT通信简介 MQTT协议是一种基于发布/订阅(Pub/Sub)模式的“轻量级”通讯协议,作为一种低开销、低带宽占用的即时通讯协议,广泛应用于物联网行业。MQTT协议通信主要由三部分组成,分别为发布端(Publisher)、订阅端(Subscriber)和MQTT Broker。其中,发布端和订阅端通过主题(Topic)来进行数据传输。而且,发布端和订阅端并不是直接相连,而是通过MQTT Broker进行连接,整体的通信架构如下图所示。
当发布端给MQTT Broker发布某个主题的消息后,MQTT Broker会把消息转发给订阅该主题的订阅端,从而实现发布端和订阅端的数据交互。
四、 操作步骤 本文使用虹科OPC Client for MQTT采集OPC DA Server数据并且作为MQTT发布端发布数据,使用虹科HiveMQ MQTT Broker作为MQTT Broker,使用MQTT.fx作为MQTT订阅端接收数据。
4.1 OPC DA Server数据添加
1. 打开虹科OPC Client for MQTT软件,点击菜单栏中“OPC Servers”添加OPC DA Server
2. 选择本地OPC DA Server
注:除了本地OPC DA Server,也支持连接远程OPC DA Server(通信前请配置DCOM),可以在上图中“Remote Connection”配置远程OPC DA Server连接参数。
3. 添加OPC组
(1)右键点击刚添加的OPC DA Server,选择菜单中中“Add Group”添加OPC组
Ubuntu 离线安装mariadb 10.4 准备工作联网电脑操作离线电脑操作mysql 初始化数据库使用 准备工作 需要一台能连互联网的ubuntu电脑操作系统版本与离线电脑版本一致,本文使用的是ubuntu18.04-server版本 联网电脑操作 安装dpkg-dev,后面要用到dpkg-scanpackages命令 apt-get install dpkg-dev 下载安装包,首先清空/var/cache/apt/archives目录,这里选择备份,防止文件丢失
2.1 安装基础组件
# 备份archives mv /var/cache/apt/archives /var/cache/apt/archives-bak # 新建一个archives目录 mkdir /var/cache/apt/archives # 新建一个文件夹,后面用于拷贝 mkdir /home/dorahou/mariadb/ # 安装mariadb,此处不是真的安装,而是下载所有用到的离线包,-d表示只下载,是必加的 # 如果是在线安装,则不需要加-d apt-get -d install software-properties-common apt-key adv --fetch-keys 'https://mariadb.org/mariadb_release_signing_key.asc' 2.2 安装指定版本数据库,mariadb10.4版本,所以要修改源
vi /etc/apt/sources.list 在sources.list第一行添加如下内容,注意保留其他在线链接
deb [arch=amd64] https://mirrors.ustc.edu.cn/mariadb/repo/10.4/ubuntu bionic main 2.3 下载安装包
apt-get update apt-get -d install mariadb-server mariadb-client 2.4 离线装包打包
# 复制archives文件夹,并用dpkg-scanpackages建Packages.gz索引 cp -r /var/cache/apt/archives /home/dorahou/mariadb/ cd /home/dorahou/mariadb/ dpkg-scanpackages archives /dev/null | gzip > archives/Packages.
第一步: brew upgrade git 第二步:
brew link git --overwrite
➜ ~ brew link git --overwrite Warning: Already linked: /usr/local/Cellar/git/2.36.0 To relink: brew unlink git && brew link git 出现提示时,第三步:
git version 查询版本
如果版本没更新,第四步:
brew unlink git && brew link git
brew link --overwrite git强制更新
DHCP DHCP简介DHCP的典型组网DHCP租期和地址池DHCP报文介绍DHCP报文格式DHCP原理描述有中继场景的DHCP客户端首次接入网络的工作原理 DHCP简介 DHCP(Dynamic Host Configration Protocol),动态主机配置协议是一种针对于IP地址进行动态管理和分配的技术。显而易见,DHCP可以动态为主机分配地址,但是也可以静态的分配地址给主机,也就是说给某个主机分配一个固定的地址。使用DHCP的好处在于:降低了维护成本,可以远程进行控制,并且可以集中对网络进行管理。
DHCP的典型组网 在DHCP中,主要包括三种角色:
DHCP服务器
DHCP服务器负责从地址池中选择IP地址分配到DHCP客户端,还可以为DHCP客户端提供其它网络参数,好比默认网关地址,DNS服务器或者WINS服务器地址等。DHCP服务器可以接收来自本网段或者是跨网段由DHCP中继转发的DHCP请求报文。DHCP客户端
客户端可以理解为请求IP地址的设备,好比:IP电话,手机,PC等。DHCP客户端发送DHCP请求报文进行IP地址的请求。DHCP中继
很多时候,DHCP服务器并不与DHCP客户端在同一网段,因此就需要一个代理,也就是这里的中继,及逆行帮助跨网段转发。过程具体如下:
DHCP客户端首先发送广播范围的请求的报文(目的地址为255.255.255.255),这样的话位于同一网段的DHCP服务器可以接收到广播的请求报文,但是如果不在一个网段,那就无法接收到DHCP客户端的请求报文,这个时候就需要DHCP中继进行转发DHCP报文。在DHCP中继这里,收到DHCP客户端发送的消息之后不会原样进行转发,而是会修改格式,然后生成一个新的DHCP报文再进行转发。 DHCP租期和地址池 租期:
DHCP服务器为每一个DHCP客户端分配的地址都定义了一个使用期限,这个期限就叫做租期。在租期到期之前,如果DHCP客户端仍然需要使用这个IP地址,那么可以请求进行延长租期;但是在租期到期之前,如果不需要这个地址了,那就可以主动释放掉这个IP地址。在没有其他空余可用的IP地址的情况下,DHCP服务器就会把这个被释放掉的IP地址分配给其它客户端。就是说,被用过的IP地址优先级不如没有使用过的IP地址,分配的话首先分配未使用过的IP地址,如果原来的用户重新向服务器请求,就可以使用原来自己使用的那个IP地址。其中静态分配的地址是没有租期限制的,也就是永久有效。地址池
地址池是指DHCP服务器可以为客户端分配的IP地址的集合。除了IP地址之外,地址池中还可以分配租期,子网掩码,默认网关等等,这些参数在地址进行分配的时候,一块分配给客户端。
根据创建的方式不同,地址池分为基于接口的地址池和基于全局的地址池:基于接口的地址池:在DHCP服务器与客户端相连的接口上进行配置,地址池跟接口地址是一个网段,并且地址池中的地址只能分配给这个接口下的客户端。这种方式见到那,但是只适用于DHCP服务器与客户端在同一个网段的场景。基于全局方式的地址池:在系统视图下创建指定网段的地址池,并且地址池中的地址可以分配给设备所有接口下的客户端,当DHCP服务器与客户端不在同一个网段的时候,需要部署DHCP中继。
地址池中的地址分为多种状态:已使用的(Used)、空闲的(Idle)、冲突的(Conflict)、不能使用的(Disable)和静态绑定的(Static-bind)等。 DHCP报文介绍 DHCP客户端与DHCP服务器之间通过DHCP报文进行通信。DHCP报文是基于UDP协议进行传输的。DHCP客户端向DHCP服务器发送报文的时候采用68端口,DHCP服务器端向DHCP客户端发送报文的时候采用67端口号。没以前有八种类型的报文。
DHCP DISCOVERY:DHCP客户端首次登录网络时进行DHCP交互发送的第一个报文,用来寻找DHCP服务器。DHCP OFFER:DHCP服务器用来相应DHCP DISCOVERY报文,这个报文用于响应DHCP DISCOVERY报文。DHCP REQUEST:此报文用于以下三种用途:
客户端初始化之后,发送广播的DHCP REQUEST报文来回应服务器的DHCP OFFER报文。
客户端重启之后,发送广播的DHCP REQUEST报文来确认先前被分配的IP地址等配置信息
当客户端已经和某个IP地址绑定之后,发送DHCP REQUEST单播或者是广播来绑定新的IP地址的租约DHCP ACK:服务器对客户端的DHCP REQUEST报文进行确认响应报文,客户端收到这个报文之后,才真正的获取了IP地址和相关的配置信息。DHCP NAK:服务器对客户端的DHCP Request报文的拒绝相应报文,例如DHCP服务器收到DHCP Request保温之后,没有找到相应的租约记录,那就发送DHCP NAK作为应答,告知DHCP客户端无法分配合适IP地址。DHCP DECLINE:客户端发现服务器分配给他的IP地址冲突时会通过发送此报文来通知服务器,并且重新向服务器申请地址。DHCP RELEASE:客户端发送这个报文主动释放服务器给他分配的IP地址,服务器收到这个保温之后,就可以将这个IP地址分配给其它客户端。DHCP INFORM:DHCP客户端获得IP地址后,如果需要向DHCP服务器获得更加详细的配置,那么客户端就向服务器发送DHCP INFORM请求报文。 DHCP报文格式 DHCP报文的格式是在BOOTP报文格式的基础之上发展而来的,因此,DHCP服务器支持与BOOTP客户端之间进行交互。
OP字段:1字节:标识报文类型,取值为1或2,1表示客户端,2表示服务器端。Htype:1字节:表示硬件类型。最常见的是1,表示以太网。hlen:1字节:表示硬件长度。hops:1字节:表示当前的DHCP报文经过的DHCP中继的数目。这个字段由客户端或者服务器设置为0,没经过一个DHCP中继,这个字段就会加一。DHCP中继数目不能超过16个,也就是HOP不能超过16,否则DHCP报文就会被丢弃。secs:2字节:表示客户端从开始获取地址或地址续租更新之后所用的时间,单位是s。flags:2字节:最高位才有意义,其余15位都被置为0,为0时,客户端请求服务器以单播的形式发送响应报文。为1时,客户端请求服务器以广播形式发送响应报文。ciaddr:4字节:表示客户端的IP地址。yiaddr:4字节:表示服务器分配给客户端的IP地址。siaddr:4字节:DHCP客户端获得启动配置信息的服务器的IP地址。giaddr:4字节:表示第一个DHCP中继的IP地址。chaddr:16字节:表示客户端的MAC地址。sname:64字节:表示客户端获取配置信息的服务器的名字。options:可变:DHCP通过这个字段包含了DHCP报文类型,服务器分配给中断的配置信息,网关IP地址,DNS服务器的IP地址,客户端可以使用的IP地址的有效租期等。 DHCP原理描述 只有跟DHCP客户端在同一个网段的DHCP服务器才能收到DHCP客户端广播的DHCP DISCOVER报文。如果客户端与服务器不在一个网段,那就必须部署中继来转发DHCP客户端和DHCP服务器之间的DHCP报文。
无中继场景的DHCP客户端首次接入网络的工作原理
第一步:发现阶段:
首次接入网络的DHCP客户端不知道DHCP服务器的IP地址,为了学习到DHCP服务器的IP地址,DHCP客户端以广播的方式发送DHCP DISCOVER报文,目的IP地址为255.255.255.255,发送给同一网段内设备,包括DHCP服务器或者中继等等。DHCP DISCOVER保温里面携带了客户端的MAC地址(chaddr字段)等信息。
第二步:提供阶段:
与DHCP客户端位于同一网段内的服务器都会接收到DHCP DISCOVER报文,DHCP服务器选择跟接收DHCP DISCOVER报文接口的IP地址处于同一网段的地址池,并且从中选择一个可以用的IP地址,然后通过DHCP OFFER报文发送给DHCP客户端。
通常,DHCP服务器的地址池中会指定IP地址的租期,如果DHCP客户端发送的DHCP DISCOVER报文中携带了期望租期,服务器会将客户端请求的期望租期与指定租期进行比较,选择其中时间较短的租期分配给客户端。
DHCP 服务器在地支持给客户分配IP地址的顺序如下:
DHCP服务器上已配置的与客户端MAC地址静态绑定IP地址。客户端发送DHCP DISCOVER报文中指定地址。DHCP服务器上记录的而曾经分配给客户端的IP地址。在地址池中随机查找一个idle状态的IP地址。如果没有找到可以分配的IP地址,那就以此查询超过租期处于冲突的IP地址,如果找到了可用的IP地址,那就进行分配;否则,DHCP客户端等待应答超时之后,重新发送DHCP DISCOVER报文进行申请IP地址。 为了防止分配出去的IP地址跟网络中的其它客户端的IP地址冲突,DHCP服务器在发送DHCP OFFER报文之前,通过发送源地址为DHCP服务器的IP地址,目的地址为预分配出去的IP地址的ICMP ECHO REQUEST报文对分配的IP地址进行地址冲突检测。如果在指定时间之内没有收到应答报文,说明网络中没有客户端使用这个IP地址,可以分配给客户端;如果在指定时间之内收到了应答报文,表示网络中已经存在了使用这个IP地址的客户端,则把这个地址列为冲突地址,然后重新等待再次收到DHCP DISCOVER报文之后按照前面的顺序再次重新进行分配。
概要:本期主要讲解Qt中的QStringList类的常用接口。 一、简介 头文件:#include<QStringList> 模块: QT += core 父类 : QList<QString> 功能:根据字面理解的话,QStringList是存储QString的QList.所以你可以认为QStringList是存储类型为QString的列表。学过QStringList,那么QList的使用你也学会了。 二、访问方式 1.数组方式访问 QStringList _strList = {"I","am","GUGUBO"}; for(int i = 0;i < _strList.size();i ++) { QString _str = _strList[i]; } 2.列表方式访问 //使用at()来访问QStringList的元素会比数组方式访问快,因为at()不会进行深拷贝。 QStringList _strList = {"I","am","GUGUBO"}; for(int i = 0;i < _strList.size();i ++) { QString _str = _strList.at(i); } 3.迭代器方式访问 //需要引入QStringListIterator头文件 QStringList _strList = {"I","am","GUGUBO"}; QStringListIterator _strListIterator(_strList); while (_strListIterator.hasNext()) { QString _str = strIterator.next(); } 三、常用接口 1.初始化、赋值 //初始化 QStringList _strList = {"
目录
ES6
let
const
解构赋值
模板字符串
字符串与数值的扩展
数组的扩展
对象的扩展
函数的扩展
Symbol 类型
iterator 迭代器
Set数据结构
Map数据结构
Proxy代理
Reflect反射
Promise对象
Generator生成器函数
class语法
class继承
ES7
求幂运算符
数组的includes方法
ES8
async和await
对象方法扩展
字符串填充
ES9
rest与扩展运算符
正则命名捕获分组
Promise.finally
异步迭代
ES10
Object.fromEntries
trimStart和trimEnd
flat()和flatMap() symbol.description ES11
Promise.allSettled
Module新增
字符串的matchAll方法
bigint (大整数)类型
globalThis 顶层对象
空值合并运算符 ??
可选链操作符 ?.
ES12
新增逻辑操作符
字符串的replaceAll 方法
Promise.any
WeakRef
ES13
类新增特性
顶层 await at函数
findLast 和 findLastIndex
catch捕获错误添加原因
ES6 let // 块级作用域 // 不允许重复声明 // 没有变量提升 // 暂存性死区 let name = "
在C语言中,指针可以进行增加或减少操作,从而指向不同的内存地址,方便地访问数组或其他数据结构中的元素。
指针的增减操作是通过指针算术运算实现的,指针可以进行加法、减法运算操作,如p++、p--、p+=n等。这些运算的结果取决于指针类型的大小,在内存中的步长会自动根据类型进行计算。
下面是一个例子,展示了指针的增减操作:
#include <stdio.h> int main() { int arr[5] = {1, 2, 3, 4, 5}; int *p = arr; printf("arr[0] = %d, *p = %d\n", arr[0], *p); p++; //指针向后移动一个位置,此时指向arr[1] printf("arr[1] = %d, *p = %d\n", arr[1], *p); p += 2; //指针向后移动两个位置,此时指向arr[3] printf("arr[3] = %d, *p = %d\n", arr[3], *p); p--; //指针向前移动一个位置,此时指向arr[2] printf("arr[2] = %d, *p = %d\n", arr[2], *p); p -= 2; //指针向前移动两个位置,此时指向arr[0] printf("arr[0] = %d, *p = %d\n"
在线学习网站:
1. 爱资源网
链接地址
2.CSDN
集技术博客、技术交流、资源下载为一体的学习与交流平台
链接地址
3.github
世界上最大的代码托管平台,提供代码管理,资源下载,和技术论坛
链接地址
4.w3cshool(编程狮)
W3Cschool是一个专业的编程入门学习及技术文档查询应用,提供包括HTML,CSS,Javascript,jQuery,C,PHP,Java,Python,Sql,Mysql等编程语言和开源技术的在线教程。
链接地址
4.菜鸟教程
菜鸟教程提供了编程的基础技术教程, 介绍了HTML、CSS、Javascript、Python,Java,Ruby,C,PHP , MySQL等各种编程语言的基础知识。
链接地址
5.OSCHINA 开源中国
提供了一个全面的、快捷更新的用来检索开源软件以及交流使用开源经验的平台
链接地址
6.C语言中文网
一个在线学习编程的网站。它始于C语言,但不终于C语言,除了C语言,您还可以学习 C++、Java、Python、Golang、PHP、Linux 等其它技能
链接地址
7.码农教程
为IT编程入门学员及码农们提供免费学习的平台,有大量IT编程入门教程(JAVA, PHP, JAVASCRIPT, C, C++, HTML, CSS等)及编程过程中遇到问题时的解决办法。
链接地址
8.uni-app
微信小程序开发学习平台
链接地址
9.易百教程
包含代码示例、面试题、教程的学习平台
链接地址
10.慕课网
慕课网(IMOOC)提供了丰富的移动端开发、php开发、web前端、android开发以及html5等视频教程资源公开课。
链接地址
11.表严肃
提供前端技术视频讲解
链接地址
12.51CTO学堂
51CTO学堂汇集各类IT精品视频课程,部分视频免费,部分需要钱滴
链接地址
面试准备网站:
1.牛客网
牛客网是互联网求职神器,C++、Java、前端、产品、运营技能学习/备考/求职题库
链接地址
2.力扣
提供海量技术面试资源,帮助你高效提升编程技能
链接地址
————————————————
版权声明:本文为CSDN博主「浅笑一斤」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/linyibin_123/article/details/124724768
future和promise C++11中std::future提供了一种访问异步操作结果的机制。异步操作不能马上就获取操作结果,只能在未来某个时候获取,但可以以同步等待的方式来获取结果,可以通过查询future的状态(future_status)来获取异步操作的结果。
std::promise 对象可以保存某一类型 T 的值,该值可被 future 对象读取(可能在另外一个线程中),因此 promise 也提供了一种线程同步的手段。在 promise 对象构造时可以和一个共享状态(通常是std::future)相关联,并可以在相关联的共享状态(std::future)上保存一个类型为 T 的值。可以通过 get_future 来获取与该 promise 对象相关联的 future 对象,调用该函数之后,两个对象共享相同的共享状态(shared state)。
deferred:异步操作还没开始ready:异步操作已经完成timeout:异步操作超时 future函数:
**get():**获取future所得到的结果,如果异步操作还没有结束,那么会在此等待异步操作的结束,并获取返回的结果。
**wait()😗*等待异步操作的结束状态变为ready,不能获得返回结果。
**wait_for(timeout)😗*等待timeout时间后返回结果,如果超时返回状态status=timeout。promise函数
set_value():设置共享状态的值,此后 promise 的共享状态标志变为 ready
get_future:获取与promise对象关联的对象
set_exception:为promise设置异常,此后promise的共享状态标识变为ready
set_value_at_thread_exit :在线程退出时该 promise 对象会自动设置为 ready(注意:该线程已设置promise的值,如果在线程结束之后有其他修改共享状态值的操作,会抛出future_error(promise_already_satisfied)异常)
swap:交换 promise 的共享状态
使用示例: ```cpp include <iostream> #include <future> #include <thread> #include <unistd.h> #include<chrono> void set_promise(std::promise<int>& p) { std::cout << "set_promise begin." << std::endl; sleep(5); p.set_value(100); std::cout << "set_promise end." << std::endl; } int main() { std::promise<int> p; // 将promise和future绑定,这一步就是允诺future,未来会有人对promise赋值 std::future<int> f = p.
安装相关依赖
sudo apt-get install build-essential
sudo apt-get install cmake libgtk2.0-dev pkg-config libswscale-dev
sudo apt-get install libjpeg-dev libpng-dev libtiff-dev
安装
在官网(Releases - OpenCV)下载opencv的压缩包,选择你需要的版本 我下载的是3.4.8
https://opencv.org/releases/page/3/点击进入
之后解压缩 ,进入opencv目录
新建build文件夹进行构建
mkdir build #新建一个build目录,一切操作均在build目录下
cd build #如果make失败了,可以删掉build目录,改正问题后重新编译
编译
cmake …
sudo make
sudo make install
sudo make这一步非常耗时间,你可以去处理手边其他的事
使用
新建一个文件夹
mkdir test
cd test
创建编写一小段demo test_opencv.cpp 读取摄像头视频
#include #include <opencv2/opencv.hpp>
#include <opencv2/imgproc/imgproc.hpp>
using namespace cv;
int main(int argc, const char * argv[]) {
Mat image;