背景 由于服务器带宽优先,很多时候上传文件,尤其是视频文件,稍微大一点上传速度有很慢,加上一些安全方面的原因,我还是喜欢将文件直接上传到阿里云OSS上,但是在uniapp中配置上传相对有点繁琐,这里记录一下,也方便大家直接拷贝使用。
流程 1.阿里云后台获取相关key
这里用需要三个数据
分别是:
1.accessid:
2.accesskey:
3.Bucket域名:
前两个大家都知道,最后一个由于阿里云后台都写在一起,比较容易搞混,这里截图给大家参考下
2.小程序端配置js文件
小程序主要配置4个文件和一个调用文件:crypto.js,hmac.js,sha1.js,base64.js
这四个文件我把代码放在下面,大家也可以直接网上下载。
最后一个aliyun.js是配置和调用的。
由于我习惯了网站的文件管理习惯,所以都放在了"/static/js"文件夹下,文件夹也是新建的,大家可以根据自己的习惯去修改路劲,不过修改路径的话记得前面的几个文件中的调用也要修改下。想偷懒就按的路劲来也可以的。
3.前端调用
代码调用就直接抄我的吧
代码 crypto.js
var base64map = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"; let Crypto = {}; var util = Crypto.util = { rotl: function (n, b) { return (n << b) | (n >>> (32 - b)); }, rotr: function (n, b) { return (n << (32 - b)) | (n >>> b); }, endian: function (n) { if (n.
问题描述:内网一台服务器安装Centos 7操作系统,可ping通,但无法ssh
排查方向:
1、查看防火墙状态
[root@localhost ~]# systemctl status firewalld
Unit firewalld.service could not be found.
未安装防火墙
2、查看ssh进程是否正常启动
[root@localhost ~]#systemctl restart sshd.service
sshd.service - OpenSSH server daemon
Loaded: loaded(/usr/lib/systemd/system/sshd.service;enabled:;vendor preset: enabled)
Active: active (running) since Thu 2822-85-12 13:01:12CST:1min 11s ago
ssh正常启动
3、查看selinux状态
[root@localhost ~]#sestatus
SELinux status: disabled
selinux关闭状态
因此怀疑是否存在地址冲突或者网络中存在安全设备拦截
4、将服务器网线拔出,在内网再次ping服务器地址,发现可ping通
故障原因:
与内网其他设备地址冲突
解决方案:
修改内网其他设备地址或服务器地址
定义 极大似然估计方法(Maximum Likelihood Estimate,MLE)也称最大概似估计或最大似然估计: 利用已知的样本结果,反推最有可能(最大概率)导致这样的结果的参数值。
思想:已经拿到很多个样本,这些样本值已实现,最大似然估计就是找参数估计值,使得前面已经实现的样本值发生概率最大。
本质:其是一种概率论在统计学的应用,是参数估计的方法之一;其是一种粗略的数学期望,要知道它的误差大小还要做区间估计。
#针对情况
针对一些情况:样本太多,无法得出分布的参数值,可以通过采样小样本后,利用极大似然估计方法获取假设中分布的参数值。
步骤 (1)写出似然函数:
总体为离散型时:
总体为连续型时: (2)对似然函数两边取对数
总体为离散型时:
总体为连续型时: (3)对lnL(θ)求导数并令之为0,求出未知参数的最大似然估计值(极值):
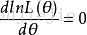 此方程为对数似然方程。解对数似然方程所得,即为未知参数 的最大似然估计值。 注:一阶的微分和可导可近似;取ln是因为对数比较方便求导。
#例子
例一
一个麻袋里面有白球和黑球,不知道它们之间的数量比例,有放回的抽取10次,结果为:8次黑球和2次白球,我需求最有可能的黑白球之间的比例,这时候可采取最大似然估计法。
很多人马上有了答案:80%,其背后的理论支撑是什么?
设:抽到黑球的概率为p,则白球的概率为1-p。因为每次抽出求的颜色都服从独立分布。
我们把每次抽出来球的颜色为一次抽样,则黑球事件的概率为P(样本结果|Model)。
记第一次抽样的结果为x1,则第n次为xn.
得出8次黑球和2次白球的结果概率:
P(样本结果|Model ) = P(x1,x2,...x10 | Model)= P(x1 | 黑) * P(x2 | 白)*... =p^8 * (1-p)^2. 以上就为概率表达式,而我们要求的模型的参数,就是求p。
有无数的p供我们选择,极大似然估计采取的选择原则是让这个样本结果出现的可能性最大,就是使上述概率表达式最大。将p看成方程求极值即可,即求导的过程就是求极值的过程.
最后求得P=80%.
例二
假如噪声服从正态分布,但该分布的均值与方差未知。选取大量的噪声作为我们观察样本结果,然后通过最大似然估计来获取上述假设的正太分布的参数,即可知道正态分布的期望和方差。
也就是说通过小样本的采样就知道一系列重要的数学指标量。
报错 /root/.go/pkg/mod/github.com/coreos/go-systemd/v22@v22.3.2/sdjournal/journal.go:27:11: fatal error: systemd/sd-journal.h: No such file or directory 27 | // #include <systemd/sd-journal.h> | ^~~~~~~~~~~~~~~~~~~~~~ compilation terminated. 解决:yum搜索安装其开发包即可 # yum search systemd 已加载插件:fastestmirror Loading mirror speeds from cached hostfile * base: mirrors.bfsu.edu.cn * extras: mirrors.bfsu.edu.cn * updates: mirrors.bfsu.edu.cn =============================================================================================== N/S matched: systemd ================================================================================================ clevis-systemd.x86_64 : systemd integration for clevis oci-systemd-hook.x86_64 : OCI systemd hook for docker pcp-pmda-systemd.x86_64 : Performance Co-Pilot (PCP) metrics from the Systemd journal rpm-plugin-systemd-inhibit.x86_64 : Rpm plugin for systemd inhibit functionality systemd-devel.
文章目录 目录结构文件类型文件路径 目录结构 Windows: 以多根的方式组织文件 C:\ D:\ E:
Linux: 以单根的方式组织文件 /
目录级别: / --> 一级目录 --> 二级目录 --> 类推
在Linux系统下,获取系统目录结构:
ls / 如图:
下图为Centos7的目录结构:
/bin:
bin 是 Binaries (二进制文件) 的缩写, 这个目录存放着最经常使用的命令。
普通用户使用的命令 /bin/ls, /bin/date。
/boot:
启动目录,这里存放的是启动 Linux 时使用的一些核心文件,包括一些连接文件以及镜像文件。
/dev:
dev 是 Device(设备) 的缩写, 该目录下存放的是 Linux 的外部设备,在 Linux 中访问设备的方式和访问文件的方式是相同的。
设备文件 /dev/sda,/dev/sda1,/dev/tty1,/dev/tty2,/dev/pts/1。
/etc:
配置文件,控制台文件。etc 是 Etcetera(等等) 的缩写,这个目录用来存放所有的系统管理所需要的配置文件和子目录。
/home:
普通用户家 Base 目录,家目录 存储用户的目录。
用户的主目录,在 Linux 中,每个用户都有一个自己的目录,一般该目录名是以用户的账号命名的,如上图中的 alice、bob 和 eve。
/lib:
库文件 Glibc,lib 是 Library(库) 的缩写这个目录里存放着系统最基本的动态连接共享库,其作用类似于 Windows 里的 DLL 文件。几乎所有的应用程序都需要用到这些共享库。
2022年是新冠疫情的第三个年头,各行各业都不太景气赚钱越来越难了。为了让自己别太消沉,我开始找些有兴趣的事情来搞一下。于是在笔记本上部署了YoloV5,训练了几个模型,本意就是做着玩,没想到其中有些功能被朋友看上了,要部署一套试用。这对我来说就有点麻烦了,直接给他放个工控机成本有点高而且不太专业,从网上查了一下,发现原来还有jetson-nano这个东西,价格不贵体积还小,感觉正适合我,就打算入手一个。结果一打听,Nvidia原厂的主板没货而且挺贵。国产jetson-nano套件有货,价格也相对便宜一些。我抱着尝试的想法买了一块,折腾两周后终于练成神功,成功部署、运行了YoloV5。这期间遇到不少困难,跟卖家有过多次沟通,人家很配合,但因为没有客户在他们这个板子上部署过YoloV5,所以无法提供详细的教程。为了感谢卖家的帮助,同时也为了让自己以后再搭建部署的时候能有个依据,本人以注册CSDN后最为认真的态度制作了以下教程,希望能帮助到有相同需求的朋友。
首先是准备工作,我的主板如下图:
产品名称:Jetson NX国产套件
型号/规格:P3668
买主板的时候只是一个裸板,风扇、电源适配器、Wifi模块都是单买的,卖家就有,建议一次采购好,要不后面很麻烦(跟老板套套磁也没准能他送给你,别说是我说的哟^_^)。我就忘记了电源适配器的事,结果老板很仗义,直接送个我了一个。电源适配器是12V,48W的,输入100V~240V 5A 50/60Hz,输出12V-4A,可能在市面上很常见,我不懂硬件所以没有自己去找,直接跟老板要的,老板很痛快直接送给我一个,但是快递进北京之前要统一消杀,结果耽误了好几天时间。
下图就是完整的jetson-nano套件三大件,有了这些就能开机、联网了。当然Wifi模块不是必须的,主要看你的网络环境。
这里我再补充个重要的事情,咱们这个主板的镜像是ubuntu18.4,不能装其他操作系统,主板自带的存储空间是16G,但是ubuntu系统镜像上去之后就已经占用14G+了,留给咱们部署的空间只有1G+。搭建YoloV5环境还要安装、更新很多包,1G+空间肯定是不够的,所以建议大家提前采购个固态硬盘,一定要买M.2接口的,买错了用不了。我买的是金士顿250G SSD固态硬盘 M.2结口(NVMe协议),大概200元出头。咱们搭建环境之前得先把操作系统从主板自带的存储空间迁移到自己的固态硬盘上,这样才有足够的空间部署和运行YoloV5,我后面的教程里会详细的教你怎么迁移。另外这个Jetson NX国产套件还能插tf卡,但是tf卡不能用来迁移操作系统,只能作为扩展空间使用。由于我250G的固态硬盘已经够用了,所以就没有再插tf卡。下图就是我买的固态硬盘:
好了,书归正传,下面就要正式开始搭建环境了。拿到Jetson NX国产套件之后,老板给我发了一个《Jetson-Nano 国产套件使用手册》的PDF文档,里面介绍了怎么刷机和安装常用软件,介绍的挺详细,但是没有说怎么部署YoloV5,而且里面提供的刷机包还有问题,刷了之后进不去ubuntu系统,所以如果你只是想部署YoloV5,果断放弃这个文档吧,按照我的教程向下进行就可以了。我发现文档里面的刷机包有问题之后找老板反应,老板给我了一个新的刷机包,经过测试是正常的。我把百度网盘的地址放出来,如果下载不了啦,请大家给我留言。
链接:https://pan.baidu.com/s/1Yz7U7gr7yUSXSa4yGjj0vQ
提取码:59ks
现在要开始刷机了,Jetson-Nano 国产套件的快递盒子里除了主板之外,还有一个小塑料袋,装着一根杜邦线、一个跳线帽和一根刷机线。杜邦线我不知道是干嘛用的,跳线帽会用到,千万别弄丢了。下图就是随主板一起快递来的杜邦线和跳线帽:
刷机前,主板先不要通电,用跳线帽把主板上的FC REC和GND短接起来,如下图:
然后找一台安装了Ubuntu18.04系统的电脑(如果你没有ubuntu系统的电脑可以自己安装一下,非常方便,没弄做过的朋友参考这两篇文章https://blog.csdn.net/fu6543210/article/details/79722615,https://blog.csdn.net/syp_net/article/details/108738198,我就是第一次装ubuntu,很顺利就弄好了。除了直接安装外,还可以做虚拟机安装,我找了个旧电脑直接装上了就没做虚拟机,有兴趣的朋友可以研究一下怎么用虚机安装)。然后用刷机线把Jetson-Nano 国产套件和电脑连接起来,如下图:
现在用这台ubuntu系统的电脑去下载前面百度网盘的镜像包,我是在windows上下载完,用U盘传到ubuntu电脑上面的。下载地址这里再发一遍:
链接:https://pan.baidu.com/s/1Yz7U7gr7yUSXSa4yGjj0vQ
提取码:59ks
下载后会看到下面6个文件:
打开readme.txt参考,先将文件合并:
cat JetPack_4.6_Linux_JETSON_NANO_TARGETS.tar.gz* > JetPack4.6_Linux_JETSON_NANO_TARGETS.tar.gz
文件合并后会多出来一个叫做JetPack4.6_Linux_JETSON_NANO_TARGETS.tar.gz的文件。如下图:
然后解压这个文件:
sudo tar -zxvf JetPack4.6_Linux_JETSON_NANO_TARGETS.tar.gz
执行完成后,会出现一个新的目录,如下图:
现在给Jetson-Nano 国产套件插上电源适配器,插上之后主板上会亮起绿的的小灯。如下图:
在Ubuntu18.04的电脑上打开一个终端,测试Jetson-Nano 国产套件与电脑的连接情况。
输入lsusb命令,如果出现Nvidia Corp.就说明已经连接成功,可以开始下一步了。如下图:
从终端进入前面创建的JetPack4.6_Linux_JETSON_NANO_TARGETS/ Linux_for_Tegra这个目录下面,执行脚本刷机:
sudo ./flash.sh -r jetson-nano-devkit-emmc mmcblk0p1
刷机的时间比较长,但是和后面要进行的操作比起来,就算是挺快的了。当终端显示
*** The target t210ref has been flashed successfully. ***
Reset the board to boot from internal eMMC.
记录一下关于 python 操作 excel表
简单复制excel表 这个复制不了颜色之类的格式,但是边边框框可以带上
import copy import openpyxl class SplitMultiSheet: """复制带格式""" def split_sheet(self, wb: openpyxl.Workbook, sn: str): """ :param wb: excel表格 :param sn: sheet_name :return: """ # _sn: sheet_name, ws: Worksheet for _sn, ws in zip(wb.sheetnames, wb): if _sn != sn: wb.remove(ws) # 保存文件、关闭文件 wb.save(f'{sn}.xlsx') wb.close() def main(self, file_path: str): wb = openpyxl.load_workbook(filename=file_path) for sn in wb.sheetnames: # 深拷贝 new_wb = copy.deepcopy(wb) self.split_sheet(wb=new_wb, sn=sn) if __name__ == '__main__': path = 'xxx.
问题描述 一个 N × M 的方格矩阵,每一个方格中包含一个字符 O 或者字符 X。
要求矩阵中不存在连续一行 3 个 X 或者连续一列 3 个 X。
问这样的矩阵一共有多少种?
【输入格式】
输入一行包含两个整数 N 和 M。
【输出格式】
输出一个整数代表答案。
【样例输入】
2 3
1
【样例输出】
49
1
【数据规模与约定】
对于所有评测用例,1 ≤ N, M ≤ 5。
Java import java.util.Scanner; public class 矩阵计数 { static int n; static int m; static int[][] map; static int ans = 0; public static void main(String[] args) { Scanner scanner = new Scanner(System.
呼吸灯的效果采用PWM调波的形式,即快速的改变每个周期的占空比(一个周期内高电平时间占一个周期时间的比值)来实现点亮到熄灭的效果。示意如下图
而关于整个波形图,用50MHz的晶振,从0开始计数到49则为1us。
而1ms是1us的1000倍,以1us为基准,从0开始计数到999则为1ms。
同理,以1ms为基准,从0开始计数到999则为1s。
cnt_en为使能信号,当其为0的时候,实现【完全熄灭】——【完全点亮】过程
当cen_en为1的时候,实现【完全点亮】——【完全熄灭】过程
下图实现的是以2s为周期,前1s实现【完全熄灭】——【完全点亮】,后1s实现【完全点亮】——【完全熄灭】。
Verilog代码为
module breath_led #( parameter CNT_1US_MAX=6'd49, parameter CNT_1MS_MAX=10'd999, parameter CNT_1S_MAX=10'd999 ) ( input wire sys_clk, input wire sys_rst_n, output reg led_out ); reg [5:0]cnt_1us; reg [9:0]cnt_1ms; reg [9:0]cnt_1s; reg cnt_en; always@(posedge sys_clk or negedge sys_rst_n)//1us计数器的波形变化过程 if(sys_rst_n==1'b0) cnt_1us<=6'd0; else if(cnt_1us==CNT_1US_MAX) cnt_1us<=6'd0; else cnt_1us<=cnt_1us+6'd1; always@(posedge sys_clk or negedge sys_rst_n)//1ms计数器的波形变化过程 if(sys_rst_n==1'b0) cnt_1ms<=10'd0; else if((cnt_1ms==CNT_1MS_MAX)&&(cnt_1us==CNT_1US_MAX)) cnt_1ms<=10'd0; else if((cnt_1us==CNT_1US_MAX)) cnt_1ms<=cnt_1ms+10'd1; else cnt_1ms<=cnt_1ms; always@(posedge sys_clk or negedge sys_rst_n)//1s计数器的波形变化过程 if(sys_rst_n==1'b0) cnt_1s<=10'd0; else if((cnt_1ms==CNT_1MS_MAX)&&(cnt_1us==CNT_1US_MAX)&&(cnt_1s==CNT_1S_MAX)) cnt_1s<=10'd0; else if((cnt_1ms==CNT_1MS_MAX)&&(cnt_1us==CNT_1US_MAX)) cnt_1s<=cnt_1s+10'd1; else cnt_1s<=cnt_1s; always@(posedge sys_clk or negedge sys_rst_n)//呼吸灯的两个状态 if(sys_rst_n==1'b0) cnt_en<=1'b0; else if((cnt_1ms==CNT_1MS_MAX)&&(cnt_1us==CNT_1US_MAX)&&(cnt_1s==CNT_1S_MAX)) cnt_en<=~cnt_en; else cnt_en<=cnt_en; always@(posedge sys_clk or negedge sys_rst_n)//LED灯的效果 if(sys_rst_n==1'b0) led_out<=1'b1; else if((cnt_en==0)&&(cnt_1ms<=cnt_1s)||(cnt_en==1)&&(cnt_1ms>cnt_1s)) led_out<=1'b0; else led_out<=1'b1; endmodule 仿真测试代码如下
背景: 使用mybatis中的聚合函数(max()、avg())查询SQL语句,返回结果装入List集合
使用了以下方法判断空值:
if (CollectionUtils.isNotEmpty(list)) { return xxx; } 结果是,无论是否数据库中是否有值, 返回都不为空。
进一步debug发现, list.size() = 1,但List中值为空, 显示All elements are null
问题原因: 使用了MySQL中的聚合函数,分别是求和函数SUM()、求平均函数AVG()、最大值函数MAX()、最小值函数MIN()和计数函数COUNT, 进而导致出现size = 1,但结果为空的情况, 具体原因不明, 后续更新。。
解决办法: 使用如下方法判空
if (CollectionUtils.isNotEmpty(list) && list.get(0) != null) { return xxx; }
文章目录 1 乘法器2 部分积的产生2.1 波兹(Booth)编码2.2 改进的波兹编码 3 部分积的累加3.1 阵列乘法器3.2 进位保留乘法器3.3 Wallace 树形乘法器 4 Verilog 实现4.1 普通阵列乘法器4.2 Booth 乘法器4.3 Wallace 乘法器 5 总结参考 1 乘法器 M和N位宽输入的乘法,采用一个N加法器需要M个周期。
利用移位和相加将M个部分积(partial product)加在一起。部分积的计算位相乘本质上是与逻辑。
101010 被乘数 × 1011 乘数 ——————————— 101010 \ 101010 | 部分积 000000 | + 101010 / ————————————— 111001110 2 部分积的产生 2.1 波兹(Booth)编码 乘数 8’b0111_1110 可以转换成 8’b1000_0000 - 8’b0000_0010 。这里用8’b1000_00I0 表示(I表示 -1 )。
这可以减少非0行的数量,使得部分积的数目至少可以减少原来的一半。部分积数目的减少意味着相加次数的减少,从而加快了运算速度并减少了面积。
保证了在每两个连续位中最多只有一个是 1 或者 -1 。形式上相当于把乘数变换成一个四进制形式。8’b1000_00I0 = (2,0,0,-2)(四进制)
问题:与{0,1}相乘等效于AND,但是与{-2,-1,0,1,2}相乘还需要反向逻辑和移位逻辑,大小不同的部分积阵列对乘法器设计不合理。
2.2 改进的波兹编码 改进的波兹编码(modified Booth’s recoding)乘数由最高有效位(msb)到最低有效位(lsb)进行,按3位一组进行划分,相互重叠一位,编码表:
转自:详解 慢查询 之 mysqldumpslow - 知乎 (zhihu.com) 查询mysql的操作信息 show status -- 显示全部mysql操作信息 show status like "com_insert%"; -- 获得mysql的插入次数; show status like "com_delete%"; -- 获得mysql的删除次数; show status like "com_select%"; -- 获得mysql的查询次数; show status like "uptime"; -- 获得mysql服务器运行时间 show status like 'connections'; -- 获得mysql连接次数 show [session|global] status like .... 如果你不写 [session|global] 默认是session 会话,只取出当前窗口的执行,如果你想看所有(从mysql 启动到现在,则应该 global)
通过查询mysql的读写比例,可以做相应的配置优化; 慢查询 当Mysql性能下降时,通过开启慢查询来获得哪条SQL语句造成的响应过慢,进行分析处理。当然开启慢查询会带来CPU损耗与日志记录的IO开销,所以我们要间断性的打开慢查询日志来查看Mysql运行状态。
慢查询能记录下所有执行超过long_query_time时间的SQL语句, 用于找到执行慢的SQL, 方便我们对这些SQL进行优化.
show variables like "%slow%";-- 是否开启慢查询; show status like "%slow%"; -- 查询慢查询SQL状况; show variables like "
一、二叉树的创建 1.树结构定义 二叉树是树结构的一种特殊结构,每一个节点最多有左孩子和右孩子两个子节点。所以在定义树结构的时候可以定义根节点ID、左右子节点的ID、以及指向左右子节点的指针。定义如下:
class TreeNode { public: TreeNode* m_pLeftChild, * m_pRightChild; int m_nRootId; //根节点ID int m_nLeftId; //子孩子节点ID int m_nRightId; //右孩子节点ID int m_nChildCount; //子孩子个数 }; 2. 二叉树的创建 给定一组数据,在创建的二叉树的时候按照左节点小于根节点,右节点大于根节点的原则进行创建,下面一组数据创建的二叉树结构应如图所示。
int data[9] = { 6, 7, 2, 9, 3, 1, 8, 2, 4 };
创建逻辑如下:
TreeNode *BinaryTree::CreateNode(int data) { TreeNode* node = new TreeNode; node->m_nRootId = data; node->m_pLeftChild = NULL; node->m_pRightChild = NULL; node->m_nChildCount = 0; node->m_nLeftId = NULL; node->m_nRightId = NULL; return node; } void BinaryTree::InsertNode(int data) { TreeNode* node = CreateNode(data); if (m_pTreeNode == NULL) { m_pTreeNode = node; } else { TreeNode* pChild = m_pTreeNode; while (pChild !
1.背景 回顾下maven的构建流程,如果没有私服,我们所需的所有jar包都需要通过maven的中央仓库或者第三方的maven仓库下载到本地,当一个公司或者一个团队所有人都重复的从maven仓库下载jar包,这样就加大了中央仓库的负载和浪费了外网的带宽,如果网速慢的话还会影响项目的进程
2.简介 私服是在局域网的一种特殊的远程仓库,目的是代理远程仓库及部署第三方构件。有了私服之后,当 Maven 需要下载jar包时,先请求私服,私服上如果存在则下载到本地仓库。否则,私服直接请求外部的远程仓库,将jar包下载到私服,再提供给本地仓库下载。
3.安装 3.1 下载 Maven 仓库管理软件(我们这里使用的是2.x的版本)
https://help.sonatype.com/repomanager2/download
3.2 本地解压
3.3 启动
3.3.1 以管理员身份打开cmd,进入到bin目录,先执行nexus install命令,再执行nexus start。
3.3.2 打开浏览器,访问http://localhost:8081/nexus3.3.3 点击右上角Log in,使用用户名:admin,密码:admin123登录
4.介绍nexus服务器预置的仓库 hosted:是本地仓库,用户可以把自己的一些jar包,发布到hosted中,比如公司的第二方库
proxy,代理仓库,它们被用来代理远程的公共仓库,如maven中央仓库。不允许用户自己上传jar包,只能从中央仓库下载
group,仓库组,用来合并多个hosted/proxy仓库,当你的项目希望在多个repository使用资源时就不需要多次引用了,只需要引用一个group即可
virtual,虚拟仓库基本废弃了。
预置仓库
Central:该仓库代理Maven中央仓库,其策略为Release,因此只会下载和缓存中央仓库中的发布版本构件。
Releases:这是一个策略为Release的宿主类型仓库,用来部署正式发布版本构件
Snapshots:这是一个策略为Snapshot的宿主类型仓库,用来部署开发版本构件。
3rd party:这是一个策略为Release的宿主类型仓库,用来部署无法从maven中央仓库获得的第三方发布版本构件,比如IBM或者oracle的一些jar包(比如classe12.jar),由于受到商业版权的限制,不允许在中央仓库出现,如果想让这些包在私服上进行管理,就需要第三方的仓库。
Public Repositories:一个组合仓库
5.创建仓库 5.1点击add ------>hosted repository
5.2填写仓库信息
5.3自己创建的仓库添加到group
5.3.1然后选择Public Repositories,打开configuration选项卡,将自己创建的仓库添加到group 5.4将项目发布到maven私服
5.4.1 首先配置maven的setting文件 //配置的是授权信息 id为仓库的id <server> <id>xiaoqiid</id> <username>admin</username> <password>admin123</password> </server> //配置maven公共仓库的地址 <mirror> <id>nexus</id> <mirrorOf>*</mirrorOf> <url>http://localhost:8081/nexus/content/groups/public/</url> </mirror> //配置profile <profile> <id>xiaoqiid</id> // id随便写 和下面的activeProfile 对应 <repositories> <repository> <id>nexus</id> //id随便写 <name>nexus private server</name> <layout>default</layout> <url>http://localhost:8081/nexus/content/groups/public/</url> <releases> <enabled>true</enabled> </releases> <snapshots> <enabled>false</enabled> </snapshots> <!
如何修改CSV文件里的日期格式 前几天做时序预测,数据是 m/d/yyyy 格式的,但是pandas不认这种日期格式。于是就想用python写个脚本一起改了。
方法一: 略微冲了一下浪,找到了Dataframe的增删改查的方法。‘date’ 是列名。
import pandas as pd data = pd.read_csv("Dataset_Finished.csv",header=0) import datetime data.loc[:,'date'] = pd.to_datetime(data.loc[:,'date'], format='%m/%d/%Y', errors='coerce') data.to_csv('change.csv') 修改成功,但是我想打开excel修改个别数据的时候发现日期格式又变回原来的%m/%d/%Y。一阵冲浪后发现,excel自动会把日期的变量转换为windows默认日期格式,就是windows右下角的日期格式。
所以,即使数据只有 ‘10:00 AM’,windows也会自动补齐年月日,变成1/0/1900 10:00:00 AM。
我心想excel这么智能,都能给我自己改回来。那肯定有办法直接改日期格式。
方法二: 在excel或wps里选中所需数据,我这里是ob_time一整列。
右键 ‘设置单元格格式’ 或 ‘Format cells‘
数字里有日期选项,但是格式都不伦不类,与我无用。点击自定义。
输入自己想要的数据格式,比如我用的是 yyyy/mm/dd hh:mm,点击确定。
可以看到日期格式修改了,虽然格子里原来的数据还在。
保存后在编辑器里读取是修改后的数据。
至此,问题解决。
唯一问题就是,如果你再次在excel里打开csv文件,日期格式又会回到windows默认格式。
IDEA 报错:无效的源发行版 问题描述 从SVN拉项目代码到本地后用idea运行,发现几个报错,关键的一个是:无效的源发行版,考虑是JDK版本问题
解决方案: 1、检查本地JDK与项目的JDK版本是否一致
(1)WIN+R打开cmd窗口,输入java -version查看当前本地的JDK版本。
(2)查看项目JDK版本:File > Project Structure > Project。如果与本地JDK版本有差异,改成本地JDK版本。
每个项目都要改成与本地SDK版本一致,然后点击应用(apply)
(3)依赖也需要检查一下
2、检查 pom.xml文件的java版本,如果有差异,改成本地SDK版本。
3、重新加载maven,如果不更新的话,有可能依旧报错。
4、重新启动项目
至此,报错解决,项目启动成功!
人物交互(Human Object Interaction,HOI)也即是人-物体交互检测,主要目的是定位人体、物体、并识别他们之间的交互关系,就是检测图像中的<人体,动词,物体>三元组。HOI检测旨在利用人体、物体以及人物对的特征将人与物体之间的交互进行关联,从而实现对图像或视频中的动作分类。
https://github.com/s-gupta/v-coco
git clone --recursive https://github.com/s-gupta/v-coco.git
文章目录 HOI检测的方法数据集评价指标挑战与展望 HOI检测的方法 1.传统方法
手工提取局部特征,如颜色,HOG,SIFT、使用贝叶斯模型进行HOI分类。
2.深度学习
2.1 两阶段方法
就是把HOI检测任务分为目标检测和交互推理两个子任务。目标检测阶段使用预训练的目标检测模型检测图像中的人和物体,然后将其逐一匹配为成对的建议,而交互推理阶段则是根据人-物体对的特征来推断交互。
2018年提出的基于人-物体区域的卷积神经网络(HO-RCNN)对HOI检测的研究具有十分重要的意义。它是一个多流网络结构,包含三个流:一个人流、一个物体流以及一个成对流。其中人流和物体流分别编码人和物体的外观特征,而成对流的目的则是编码人和物体之间的空间关系。 2.1.1融入注意力的HOI检测方法
ICAN:在HO-RCNN的基础上提出,采用以实例为中心的注意力模块来提取与局部区域(人/物框)的外观特征互补的上下文特征,以提高HOI检测效果,ICAN的注意力图是自动学习的,并与网络的其余部分联合训练。
注意力机制的加入有效提高了HOI检测模型提取上下文特征的能力,
由于其分支结构与HO-RCNN相比并没有明显变化,仍然只是利用人与物体的视觉特征以及空间特征来进行推理判断。
2.1.2融入图模型的HOI检测方法
图模型的基本思想是用节点表示人和物体,用边表示人和物体之间的交互,人与物体之间的交互性越大,则边的强度就越高,如:GPNN(图解析神经网络)引入连接函数解决图结构的学习问题,能够以端到端的方式推断邻接矩阵,其中人与物是使用的相同的节点,后来有人提出将人与物用不同的节点表示。
图注意力模型:引入注意力机制的特征处理网络图像上下文信息融入到图节点的特征表示中,如GAT、VS-GATS、如VSGNet(视觉空间网络)、SAG(时空注意力图神经网络)、DRG(双重关系图)
2.1.3融入身体部分和姿态的HOI检测方法
提出了身体部位注意模型,通过学习关注关键部位以及他们之间的相关性,进行HOI识别,使用ROI,提出了TIN:利用交互网络从多个HOI数据集学习一般交互知识,并在推理过程中的HOI分类之前进行非交互抑制。PMFNet(姿态感知多级特征网络)、RPNN(关系解析神经网络)、PFNet(多级成对特征网络)MLCNet(多层次条件网络)、PMN(基于姿态的模块化网络)
2.2 一阶段方法
由于两阶段检测方法需要将检测到的人与物体先配对再进行交互预测,会产生昂贵的计算代价一阶段检测器能够直接从图像中检测HOI三元组,采用一步到位的方法。
PPDM:第一个实时的一阶段HOI检测方法,这一方法使用检测框的中心点表示人和物体点,用人点和物体点间的中点表示交互点。该模型使用两个并行分支分别进行点检测和匹配,其中点检测分支预测人、物体以及交互点,点匹配分支预测从交互点到其对应的人点和物体点的两个位移。源自同一交互点的人点和物体点被视为匹配对
IP-Net:首个将HOI检测作为关键点检测和分组问题,通过将人和物体之间的相互作用定义为相互作用点,将HOI检测视为相互作用点估计问题。
UnionDet:面向实时人机交互检测的联合检测器,使用联合检测框架直接检测相互作用的人类对象对。
AS-Net:将HOI检测表述为一个集合预测问题,具有并行的实例分支和交互分支。
2.3 其他新技术
数据集 1.传统数据集
sports event:博涵8种体育赛事,使用大量语义级标签描述场景和对象。TUHOI:人物交互数据集,由于动词的语法师太以及一词多义现象带来映射偏差,导致验证时难以区分语言理解错误和HOI检测错误。HICO:收录来自80个对象的117种常见行为,该数据集以物体为中心。
2.实例数据集V-COCO数据集:V-COCO针对每一类别的单目标进行实例分割,并为每张图提供了5种文字描述,由Microsoft COCO派生而来,由2533副图像训练集、2867副图像验证集和4946副图像测试集,总共10346副图像,包含16199个人的实例,每个带注释的人含有26个动作标签,80个对象类别。HICO-DET:使用无向边作为交互类标签,将人与物体的实例框相连接,专门用于HOI研究任务的基准数据集,来自于HICO的扩种,共有47776副图像,其中38118用于训练,9658用于测试,该数据集与V-COCO 是人物交互检测领域中公认的两大基准数据集。HAKE:是人物交互领域最新发布的数据集,HOI-A:来自真实场景,包含不同的外观类型,低分辨率,具有严重遮挡的图像,识别难度较大,由38668个带注释的图像 组成,包含11中交互物体和10中交互动作,HOI-A数据集中每种类型的交互分为室内、室外和车内三种场景,包括了黑暗、自然和强烈的三种照明条件,以及各种不同的角度。 评价指标 预测的人类边框与其真实边框(ground truth)之间的IoU大于或等于0.5;预测的物体边框与真实的物体边框之间的IoU大于或等于0.5;预测出的人与物体之间的交互动作与标签标注的真实发生的交互动作一致。
被判断为真阳性TP(true positive)表示模型的预测结果与样本的真实类别一致均是正例。FN:模型预测是反例,样本真实是正例FP:预测是正例,样本 真实是反例TN:预测是反例,样本真实是反例使用平均精度mAP来评估HOI检测,是AP的平均值,计算AP需要用到混淆矩阵。
准确率表示真正样本占人-物体交互检测模型预测出的全部正样本比例:
召回率真实的正样本中,人-物体交互检测模型为正确的正样本所占有的比例 AP:所有准确率和占该类别的图像数量的比例,评价的是在单个类别上模型判断结果的好坏(p表示准确率,r表示召回率)
mAP指的是平均精确率(AP)的平均值,它衡量的是在所有类别上模型判断结果的好坏。(c表示HOI类的总数) 挑战与展望 目前HOI检测网络主要从以下两方面进行改进提升:
替换主干网络。主干网络用于提取图像特征,融入额外的信息。例如加入人体姿态与身体部分信息可以提升模型的理解能力
挑战:数据集中不同类别间的实例样本数量不平衡,并且交互类别欠全面,目前的HOI检测模型主要基于V-COCO和HICO-DET等少数几个公共基准数据集进行训练和测试,无法训练出特定场景的模型
数据集还有待进一步完善。由于一张图像中往往含有多个人和物体,若是将所有人和物体的组合穷举出来再逐对进行推理判断,则会给计算资源带来巨大的负担两阶段模型不能用于实时性要求较高的场景视觉干扰,如光照变化,拍摄距离,阴影、局部动态背景物体等。运动视角下的人物交互检测。基于图片场景建模的检测方法只适用于固
定拍摄的场景,视频中的交互动作识别对于应用至关重要,如何处理整个时序信息中多个物体产
生的交互,目前还没有很好的方案。
趋势在两阶段方法中,图网络的强大的推理能力非常适用于解决HOI检测任务,但大多数以前的工作未能利用图形中的空间关系信息。因此,如何引入其他信息来完善图模型的构建还有较大的研究空间。一阶段方法更快、更高效,不需要在不同阶段之间切换模型,也不需要保存或加载中间结果,更容易在实际应用中部署,使用它扩展处理一些相关问题,如视觉关系检测和多目标跟踪等也是值得研究的方向。如何简化后期处理以及怎样处理好与交互区域相关的语义歧义是未来研究中亟需解决的问题。由于少样本的HOI检测是为直接解决HOI检测中最重要的两个问题而设计的,是解决HOI检测问题必要深入研究的重要方向。只通过现有的数据进行训练就能够推广到其他未见场景
中,这样才能减少HOI模型对于标记数据的依赖。迫切需要更多像HOI-A这样包含更具针对性动作的或更具实际意义动作的数据集来进一步推动这项技术的发展与应用。 参考文献
[1]阮晨钊,张祥森,刘科,赵增顺.深度学习的人-物体交互检测研究进展[J].计算机科学与探索,2022,16(02):323-336.
[2]龚勋,张志莹,刘璐,马冰,吴昆伦.人物交互关系HOI检测研究进展综述[J/OL].西南交通大学学报:1-13[2022-04-13].
Flutter Web 稳定版本发布至今也有一年多了,经过这一年多的发展,今天就让我们来看看作为大前端时代的乱流,Flutter Web 究竟有什么不同之处,本篇分享主要内容是目前 Flutter 下少有较为全面的 Web 内容。
本篇来自本人在《T技术沙龙-大前端时代的挑战与机遇(深圳场)》的线下技术分享。
一、起源与实现 说起 Flutter 的起源就很有意思,大家都知道早期 Flutter 最先支持的平台是 Android 和 iOS ,至今最核心的维护平台依然是 Android 和 iOS ,但是事实上 Flutter 其实起源于前端团队。
Flutter 来源于前端 Chrome 团队,起初 Flutter 的创始人和整个团队几乎都是来自 Web,在 Flutter 负责人 Eric 的相关访谈中, Eric 表示 Flutter 来自 Chrome 内部的一个实验,他们把一些乱七八糟的 Web 规范去掉后,在一些内部基准测试的性能居然能提升 20 倍,因此 Google 内部就开始立项,所以 Flutter 出现了。
另外前端的同学应该知道, Dart 起初也是为了 Web 而生,事实上在 Dart 诞生至今也有 10 年了,所以可以说 Flutter 其实充满了 Web 的基因。
但是作为从 Web 里诞生的框架,和 React Native/ Weex 不同的是,前者是先有了 Web 下的 React 和 Vue 实现之后才有的客户端支持,而对于 Flutter 则是反过来,先有客户端实现之后才支持 Web 平台,这里其实可以和 Weex 做个简单对照。
任意数字的指定位上的数值如何求?
目录
一、提取各个位数的方法?
二、方法解读
1.详细解释方法
结果输出为:
2.举例子(水仙花数)
总结
一、提取各个位数的方法? 先进行整除操作,将要求的数字移动到个位上,在使用取余操作,取出最后一位上的值。
二、方法解读 1.详细解释方法 方法中第一部分(将要求的数字移动到个位上)的意思是:用这个整数先整除将要提取的数字所在位的10^(n-1),
第二部分(在使用取余操作,取出最后一位上的值):将第一部分计算的结果对10取余,即可获得最后一位上的值。
既:
个位获取: XXX % 10;
十位获取: XXX /10 % 10;
百位获取: XXX / 100 % 10;
千位获取: XXXX / 1000 % 10; .............
public class Demo08 { public static void main(String[] args) { int num = 789456; //操作数 int gewei = num % 10; //个位:从右往左数第1个数字,用操作数整除10^(1-1)在对10取余 int shiwei = num / 10 % 10; //十位:从右往左数第2个数字,用操作数整除10^(2-1)在对10取余 int baiwei = num / 100 % 10; //百位:从右往左数第3个数字,用操作数整除10^(3-1)在对10取余 int qianwei = num / 1000 % 10; //千位:从右往左数第4个数字,用操作数整除10^(4-1)在对10取余 int wanwei = num / 10000 % 10; //万位:从右往左数第5个数字,用操作数整除10^(5-1)在对10取余 int shiwanwei = num / 100000 % 10; //十万位:从右往左数第6个数字,用操作数整除10^(6-1)在对10取余 System.
复杂网络研究中的传播模型SIR的Python实现 SIR应用 SIR import random ''' 程序主要功能 输入:网络图邻接矩阵,需要被设置为感染源的节点序列,感染率,免疫率,迭代次数step 输出:被设置为感染源的节点序列的SIR感染情况---每次的迭代结果(I+R)/n ''' def update_node_status(graph, node, beta, gamma): """ 更新节点状态 :param graph: 网络图 :param node: 节点序数 :param beta: 感染率 :param gamma: 免疫率 """ # 如果当前节点状态为 感染者(I) 有概率gamma变为 免疫者(R) if graph.nodes[node]['status'] == 'I': p = random.random() if p < gamma: graph.nodes[node]['status'] = 'R' # 如果当前节点状态为 易感染者(S) 有概率beta变为 感染者(I) if graph.nodes[node]['status'] == 'S': # 获取当前节点的邻居节点 # 无向图:G.neighbors(node) # 有向图:G.predecessors(node),前驱邻居节点,即指向该节点的节点;G.successors(node),后继邻居节点,即该节点指向的节点。 neighbors = list(graph.predecessors(node)) # 对当前节点的邻居节点进行遍历 for neighbor in neighbors: # 邻居节点中存在 感染者(I),则该节点有概率被感染为 感染者(I) if graph.