当文章的内容过的时候,需要给文章建立目录,可以实现点击目录随意的跳转到对应的内容。此时是使用markdown的锚点的功能。
基本的格式为:
- [标题名](#给标题取得一个id,一般与标题同名即可) ### <a id="给标题取得一个id,一般与标题同名即可">标题名</a> 实例如下:
测试1测试2测试3 测试1 dsd
fad
fadfadf
fadfafa
fafda
fa
fa
fafafafa
fafa
fa
af
测试2 fa
fa
fa
fa
fa
fa
fa
fa
f
af
af
a
fa
fa
fa
f
测试3 fafafa
faf
a
f
题目描述:
编写一个算法来判断一个数是不是“快乐数”。
一个“快乐数”定义为:对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和,然后重复这个过程直到这个数变为 1,也可能是无限循环但始终变不到 1。如果可以变为 1,那么这个数就是快乐数。
示例:
输入: 19
输出: true
解释:
1^2 + 9^2 = 82
8^2 + 2^2 = 68
6^2 + 8^2 = 100
1^2 + 0^2 + 02 = 1
int Num(int x) { int ret=0; while(x){ ret+=(x%10)*(x%10); x/=10; } return ret; } bool isHappy(int n) { if(n<=0) return false; while(n!=1){ n=Num(n); if(n==4) return false; } return true; }
转发自博客:
https://blog.csdn.net/teacher_lee_zzsxt/article/details/79230501
Windows7环境下使用Anaconda配置tensorflow—cpu版本和pycharm进行python开发 软件配置:Anaconda安装包和pycharm社区版安装包+Windows7系统
1:安装Anaconda
(1)从下述网址下载Anaconda安装包,注意看好需要的版本。
https://www.anaconda.com/distribution/
Anaconda官网下载,下载界面如下
若上述网址打不开或下载不下来时候可使用下述网址
https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
(2)双击下载好的“exe文件”,进行安装,点击“next”
(2)点击“I Agree”
(3)点击“next”
(4)点击“Browse”选择自己的安装路径,点击”Next”
(5)第一个对勾是是否将Anaconda加入环境变量,涉及是否能在cmd中使用conda操作,建议打钩。第二个对勾是是否设置Anaconda所带的python3.6为系统的默认版本,建议均如下图操作。
(6)系统自己安装,静候等待
(7)安装完成,点击“next”
(8)点击“skip”
(9)点击“Finish”完成安装。
2:配置tensorflow环境
(1)打开Anaconda Prompt,目前是root环境,我们需要配置tensorflow则在Anaconda Prompt中输入以下命令(指定相应的python版本)
conda create -n tensorflow python=3.6 (2)出现以下界面时,会安装一些包,输入‘y’即可
(3)如图,‘tensorflow’环境已经成功创建,
(4)由于平时使用tensorflow时候,会安装一下常用的的库和组件,所以我们在此设置下镜像网站,提高下载速度。
镜像网站:http://mirrors.neusoft.edu.cn/
在此,我们设置清华镜像,在Anaconda下输入以下命令
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --set show_channel_urls yes (5)安装tensorflow
激活刚才创建的“tensorflow”环境,在Anaconda Prompt中运行
activate tensorflow 接着输入命令安装tensorflow的cpu版本
pip install --upgrade --ignore-installed tensorflow 扩展
在这里我们使用“activate XX”XX为环境名字来切换环境
如果忘记了环境名称,可以输入“conda env list”查询,可以列出conda管理下的所有环境
activate //切换到base环境
activate XX //切换到XX环境
(6)测试下安装后的tensorflow环境是否可以成功调用
在Anaconda Prompt下输入 ”activate tensorflow”激活环境,输入“python”出现python界面时,输入“import tensorflow as tf”查看,如出现下图情况,则配置成功。
有几点需要注意的:
要先安装VS,如果先安装的cuda,可以重新运行cuda安装程序,将VS相关的组件(比如NSIGHT)重新安装
要运行cuda的例程,需要特点版本的Windows SDK
每个工程只能有一个main函数。
在java开发中除了上文经常用的对字符串的操作外,还有使用居多的当属集合了。在基础的java学习时,相信很多同学都学习了List、Set、Map这些,他们之间的区别和基本的使用方法也是很了解了,本文是详细的去分析List中Vector、ArrayList、LinkedList之间的区别和底层实现原理以及使用场景
首先说下这三者的区别:
1.基本区别:三个类都实现了List接口,都是有序集合,数据是允许重复的;ArrayList 和Vector都是基于数组实现存储的,集合中的元素的位置都是有顺序即连续的;LinkedList是基于双向链表实现存储的,集合中的元素的位置是不连续的
2.性能区别:Vector和ArrayList底层实现原理一致,但是Vector是线程安全的,因此性能比ArrayList差很多;LinkedList相比于集合Vector和ArrayList在插入,修改,删除等操作上速度较快,但是随机访问的性能较差
3.安全区别:Vector是使用了synchronized同步锁是线程安全的,ArrayList和LinkedList都是线程不安全的
4.原理区别:ArrayList与Vector都有初始的容量大小,当存储的元素的个数超过了容量时,就需要增加存储空间,Vector默认增长为原来两倍,而ArrayList的增长为原来的1.5倍;ArrayList与Vector都可以设置初始空间大小,Vector还可以设置增长的空间大小,而ArrayList没有提供设置增长空间的方法
然后详细分析每一个的原理:
1.Vector
从源码可以看出Vector的初始默认空间大小为10,底层使用protected Object[] elementData;存储数据,使用protected int elementCount;存储元素数量,Vector的方法都被synchronized关键字修饰,因此是线程安全的。
接下来我们从源码上看下Vector的添加元素时以及初始容量不足时的扩容机制:
当创建一个Vector容器,向其中添加一个元素是,首先会调用ensureCapacityHelper函数判断容器存储容量,如果容量不足则会调用grow函数扩容,上面我们说的扩展为原来的两倍,其实不是非常准确,因为当设置了扩容参数值,则就不是扩展为两倍了,而是原来的长度加上扩容参数值,默认情况下还是扩展为原来的两倍。
2.ArrayList
ArrayList的初始容量大小也是10,和Vector的原理是完全一样的,只是不是线程安全的,我们这里主要看下ArrayList的扩容原理:
ArrayList也是会先判断容器的容量大小,如果容量不足,则调用扩容方法grow函数,将容量扩展原来加原来一半也就是1.5倍
3.LinkedList
LinkedList是一个继承于AbstractSequentialList的双向链表,它也可以被当作堆栈、队列或双向队列进行操作。LinkedList实现 List 接口,能对它进行队列操作。LinkedList 实现 Deque 接口,即能将LinkedList当作双端队列使用。LinkedList 是非同步的(线程不安全的)。因为是双向链表,所以它的顺序访问会非常高效,而随机访问效率比较低。
下面我们先看下LinkedList的添加元素的原理:
我们从源码可以看到其实add添加元素的操作就是在容器的最后新增一个数据节点,具体分析:先把当前最后一个节点存档到l数据节点中,然后新增一个数据节点,这里有一个判断,如果l为空那就是说改链表是空的,这样这个新增元素即是第一个也是最后一个节点;如果l不为空,将当前最后一个节点变成新增的前一个节点,然后last存放新增节点使其变成最后一个元素节点,这样一个新增的操作就完成了。
我们再来看看向制定位置添加数据节点的原理,看下面源码:
首先是位置是否存在,添加元素的位置必须是大于等于0小于等于链表的大小;然后判断如果要添加元素的位置等于链表的大小,则该元素插入最有一个即可,否则在指点的位置前插入节点,先将该位置前的阶段存起来到pred,然后判断如果pred为空说明该链表是空的,则将新增数据节点写入第一个节点中,如果pred不为空,将原来的前一个节点的下一个节点指向新添加的节点,将新添加节点的下一个节点指向原来位置的下一个节点即可
接下来我们看下删除第一个节点元素:
删除时是先把原来的第一个节点的下一个节点存到first中,然后将第一个节点的指向都设置为null(删除),然后将first指向next就可以了,然后判断如果next为空则last设置为空,这时候整个链表也就是空的;反之释放next内存;然后将链表大小减小一个,将此列表已被结构修改的次数减一
接下来我们看下删除最后一个节点元素:
删除最后一个元素是相对简单一些,删除最后一个节点,然后释放该节点指向前一个节点的指针空间和释放前一个节点指向下一个节点的指针空间,然后将链表大小减小一个,将此列表已被结构修改的次数减一
感兴趣的小伙伴可以关注我的公众号【IT技术之旅】,每天更新干货内容。
一、实际问题:
1、开机出现原子上下文调度的bug:
[ 6.290494] <1>.(1)[285:init]BUG: scheduling while atomic: init/285/0x00000000 [ 6.290528] <1>-(1)[285:init][<c010e61c>] (dump_backtrace) from [<c010e954>] (show_stack+0x18/0x1c) [ 6.290533] <1>-(1)[285:init] r6:600b0013 r5:c14556d0 r4:00000000 r3:00040975 [ 6.290543] <1>-(1)[285:init][<c010e93c>] (show_stack) from [<c04b5e88>] (dump_stack+0x94/0xa8) [ 6.290551] <1>-(1)[285:init][<c04b5df4>] (dump_stack) from [<c0159a14>] (__schedule_bug+0x58/0x6c) [ 6.290555] <1>-(1)[285:init] r6:c1404a54 r5:c13a4b00 r4:00000000 r3:600b0013 [ 6.290561] <1>-(1)[285:init][<c01599bc>] (__schedule_bug) from [<c0ddf568>] (__schedule+0x660/0xa68) [ 6.290564] <1>-(1)[285:init] r4:df68bb00 r3:c13a4b00 [ 6.290568] <1>-(1)[285:init][<c0ddef08>] (__schedule) from [<c0ddf9c4>] (schedule+0x54/0xb8) [ 6.290572] <1>-(1)[285:init] r10:00000000 r9:00000000 r8:00000000 r7:00000000 r6:00000000 r5:00000000 [ 6.
C++ Primer知识点整理
C++必须有一个main函数,return0 返回0表示程序执行完毕。定义函数必须指定4个元素:返回类型、函数名、圆括号内形参表和函数体。cin(读see-in)输入,cout(读see-out)输出,预处理命令会告诉编译器要做一些事情。endl称为操纵符,具有输出换行的效果。C++中通过定义类来定义自己的数据结构。
第一部分 基本语言
类型是所有程序的基础。C++的几种基本类型:整形、浮点型、字符型等。void没有对应的值,以0开头,八进制,以0x开头,16进制。变量提供了程序可以操作的有名字的存储区。变量是左值(可在等号左边或右边),数字是右值(只能在右边)。C++大多数作用域用花括号来界定。定义const对象,它把一个对象转换成一个常量,因为常量的值在定义后不能修改,所以定义的时候必须初始化。const对象默认为文件的局部变量,只存在那个文件中,不能被其他文件访问。引用,就是对象的另一个名字,const引用是指向const对象的引用。typedef名字,可以用来定义类型的同义词。枚举,不但定义了整数常量集,而且把他们汇聚成组。关键字是enum,枚举成员是常量,每个枚举都定义一种唯一的类型。类类型,每个类都定义了一个接口和一个实现。类以关键字class开始,其后是该类的名字标识符。类体位于花括号里面,花括号后面必须跟个分号。 类的数据成员、访问标号等。struct关键字,它也可以定义类类型,但成员都是public的。
标准库类型一旦用了using声明,我们就可以直接引用名字,而不需要再引用该名字的命名空间。string类型支持长度可变的字符串。Vector是一个类模板,用于管理同一类型的对象集合,迭代器实现了对存储与容器中对象的间接访问。迭代器可用于访问和遍历string类型和vector类型的元素。
数组和指针与vector类似,数组也能保存某种类型的一组对象;而他们的区别在与数组的长度是固定的。数组一经创建,就不能添加新的元素。指针像迭代器一样,用于遍历和检查数组中的元素。指针用于指向对象,具体来说指针保存着另一对象的地址。多维数组,如果数组的元素又是数组称为多维数组。
表达式
语句C++提供了一组控制流,允许有条件的或者重复执行某部分功能。if和switch提供条件分支结构。for、while、do while则支持重复执行的功能。continue终止当次循环,break退出一个循环或switch语句;goto将控制跳到某个标号语句;default标号,相当于else字句的功能。while语句,每次循环都将该变量的初始值转换为bool类型。
函数函数由函数名以及一组操作数类型唯一的表示。函数的操作数也叫形参。return语句用于结束当前正在执行的函数。递归函数,直接或间接的调用自己的函数,举例:数n的阶乘,递归必须要有一个终止条件。内联函数,(编译器在调用点直接把函数代码展开)避免函数调用的开销,把内联函数放入头文件。类的成员函数,每个成员函数都有一个额外的、隐含的形参this。this指针的作用,当你进入一个房子后,你可以看见桌子、椅子、地板等,但是房子你是看不到全貌了。对于一个类的实例来说,你可以看到它的成员函数、成员变量,但是实例本身呢?this是一个指针,它时时刻刻指向你这个实例本身。构造函数,通过构造函数来初始化类的数据成员,构造函数是特殊的成员函,它和类同名没有返回类型。
标准IO库 istream,提供输入操作;ostream,提供输出操作;cin,读入标准输入的istream对象;cout,写到标准输出的ostream对象。cerr,输出标准错误的ostream对象。
第二部分 容器和算法
顺序容器,顺序容器的元素按其位置存储和访问。vector、list(高效的插入和删除不支持随机访问)、和deque(双端队列),还提供了三种容器适配器,动过定义新的操作接口,来适应基础的容器类型。顺序容器适配器包括stack、queue、priority-queue(有优先级管理的队列)。选择容器的提示,若程序要求随机访问,则应使用vector和deque容器。 如果程序必须在容器中间位置插入或删除元素,应采用list。 如果程序不是在元素中间位置插入或删除,而是在容器首部或尾部插入和删除则用deque。string类型;容器适配器,优先级队列允许用户为队列中存储的元素设置优先级。
关联容器关联容器和顺序容器的本质差别,关联容器通过键(key)存储和读取元素,而顺序容器则通过元素在容器中的位置顺序存储和访问元素。两个基本的关联容器map和set map是键-值对的集合,可以理解为关联数组:可使用键作为下标来获取一个值。 map 是键-值对的集合,好比以人名为键的地址和电话号码。相反的,set容器是单纯的键的集合。multimap和multiset允许一个键对应多个实例。
泛型算法
第三部分 类和数据抽象
类定义了数据成员和函数成员。数据成员用于存储与该类类型 的对象相关联的状态,而函数成员则负责执行赋予数据意义的操作。简单来说类就是定义了一个新的类型和一个新的作用域。构造函数是特殊的成员函数,只要创建类类型的新对象,都要执行构造函数。
复制控制 重载操作符与转换
第四部分 面向对象编程和泛函编程
继承,子类继承父类。
根据数据的不同情况及处理数据的不同需求,通常会分为两种情况,一种是去除完全重复的行数据,另一种是去除某几列重复的行数据,就这两种情况可用下面的代码进行处理。
1. 去除完全重复的行数据
data.drop_duplicates(inplace=True) 2. 去除某几列重复的行数据
data.drop_duplicates(subset=['A','B'],keep='first',inplace=True) subset: 列名,可选,默认为None
keep: {‘first’, ‘last’, False}, 默认值 ‘first’
first: 保留第一次出现的重复行,删除后面的重复行。last: 删除重复项,除了最后一次出现。False: 删除所有重复项。 inplace:布尔值,默认为False,是否直接在原数据上删除重复项或删除重复项后返回副本。(inplace=True表示直接在原来的DataFrame上删除重复项,而默认值False表示生成一个副本。)
参考:
https://blog.csdn.net/qq_28811329/article/details/79962511
https://blog.csdn.net/Disany/article/details/82689948
概览: 学习创建时间预测序列的步骤额外关注 Dickey-Fuller test & ARIMA(自回归移动平均) 模型从理论上学习这些概念,以及它们在python中的实现 介绍 时间序列(从现在开始称为TS)被认为是数据科学领域中不太为人所知的技能之一(就连我几天前也对它知之甚少)。我开始了一段新的学习旅程,学习解决时间序列问题的基本步骤,现在我和大家分享一下。这些绝对会帮助你在未来的项目中得到一个不错的模型!
在阅读本文之前,我强烈建议阅读关于R中的时间序列建模的完整教程,并学习自由时间序列预测课程。它侧重于基本概念,我将重点介绍如何使用这些概念来解决端到端问题,以及Python中的代码。R中有很多时间序列的资源,但是很少有Python的资源,所以我将在本文中使用Python。
我们的旅程将经过以下步骤:
是什么让时间序列如此特别?用 Pandas 记载并处理时间序列如何检验时间序列的平稳性?如何使时间序列平稳?预测时间序列 1. 是什么让时间序列如此特别? 顾名思义,TS是按固定的时间间隔收集的数据点的集合。这些分析是为了确定长期趋势,以便预测未来或进行其他形式的分析。但是TS和常规回归问题有什么不同呢?有两件事:
它与 时间 有关。所以线性回归模型的基本假设即观测值是独立的在这种情况下并不成立。随着增加或减少的趋势,大多数 TS 具有某种形式的 季节性(seasonality trends) 趋势,即特定于特定时间段的变化。例如,如果你看到一件羊毛夹克的销量随着时间的推移,你一定会发现冬季的销量更高。 由于 TS 的固有性质,分析它涉及到很多步骤。下面将详细讨论这些问题。让我们从用Python加载一个TS对象开始。我们将使用流行的航空乘客数据集,可以在这里下载。
2. 用 Pandas 加载并处理时间序列 Pandas有专门的库来处理TS对象,特别是 datatime64[ns] 类,它存储时间信息并允许我们快速执行某些操作。让我们从引入所需的库开始:
import pandas as pd import numpy as np import matplotlib.pylab as plt %matplotlib inline from matplotlib.pylab import rcParams rcParams['figure.figsize'] = 15, 6 现在,我们可以加载数据集,看看列的一些初始行和数据类型:
data = pd.read_csv('AirPassengers.csv') print data.head(n = 10) # 默认 n为5 print '\n Data Types:' print data.
点击下载来源:vc运行库合集 官方正式版 v2019.07.20
vc运行库是一款应用于系统底层支持软件运行加载的动态链接库,一般我们常用的安装程序会集成打包vc运行库进行安装使用,单纯从字面上了解,运行库是支持程序在运行时所需要的库文件,而我们通常使用的运行库是以dll文件的形式提供的,dll本意为动态链接库文件,又称为应用程序扩展,用于程序执行时进行相应的调用,当然一个dll文件可以被不同的程序进行交替使用,达到底层支持共享的作用。
vc运行库合集是将现今市面上常用的vc++版本运行库集成在一起,避免分开安装不同的版本库文件,该vc运行库合集内置了多个版本全部的dll扩展程序文件,帮助用户解决缺少各种dll文件以及丢失的难题。本站支持vc运行库合集下载,有需要的用户可以在本站下载!注:下载包中有vc运行库合集32位以及64位安装包,安装包在未使用时请不要轻易删除以及更改文件类型。
vc运行库合集
安装教程
1、在本站下载好安装包,双击运行“MSVBCRT_AIO_2017.10.25_X86 X64.exe”程序;小提示:由于小编电脑系统版本是X64版本,所以安装教程以X64安装包为例,X32安装过程相同;
2、弹出的软件窗口中查看vc运行库合集安装的版本库,单击“下一步”开始安装;
3、自定义选择需要安装的组件类型,默认推荐安装,也可以选择自定义安装需要的vc运行库版本,完成后点击“下一步”按钮;
4、当还有需要更新设置的程序运行时,安装程序自动提示关机,默认关闭即可,点击“下一步”完成安装;
5、等待安装进度完成,点击“完成”结束安装;
软件集合包含下列组件:
Visual Basic Virtual Machine(5.1)
Visual Basic Virtual Machine (6.0)
Microsoft C Runtime Library(7.0)
Microsoft C Runtime Library(7.10)
Microsoft Visual C++ 2005 SP1(8.0.61187)
Microsoft Visual C++ 2008 SP1(9.0.30729.7523)
Microsoft Visual C++ 2010 SP1(10.0.40219)
Microsoft Visual C++ 2012 update4(11.0.61030)
Microsoft Visual C++ 2013 (12.0.21005)
Microsoft Visual C++ 2017(14.11.25325)
Microsoft Universal C Runtime (10.0.10586.9)
VS 2010 Tools For Office Runtime(10.
前言 相比于前面三种垃圾收集算法,引用计数算法算是实现最简单的了,它只需要一个简单的递归即可实现。现代编程语言比如Lisp,Python,Ruby等的垃圾收集算法采用的就是引用计数算法。现在就让我们来看下引用计数算法(reference counting)是如何工作的。
算法原理 引用计数算法很简单,它实际上是通过在对象头中分配一个空间来保存该对象被引用的次数。如果该对象被其它对象引用,则它的引用计数加一,如果删除对该对象的引用,那么它的引用计数就减一,当该对象的引用计数为0时,那么该对象就会被回收。
比如说,当我们编写以下代码时,
String p = new String("abc") abc这个字符串对象的引用计数值为1.
而当我们去除abc字符串对象的引用时,则abc字符串对象的引用计数减1
p = null 由此可见,当对象的引用计数为0时,垃圾回收就发生了。这跟前面三种垃圾收集算法不同,前面三种垃圾收集都是在为新对象分配内存空间时由于内存空间不足而触发的,而且垃圾收集是针对整个堆中的所有对象进行的。而引用计数垃圾收集机制不一样,它只是在引用计数变化为0时即刻发生,而且只针对某一个对象以及它所依赖的其它对象。所以,我们一般也称呼引用计数垃圾收集为直接的垃圾收集机制,而前面三种都属于间接的垃圾收集机制。
而采用引用计数的垃圾收集机制跟前面三种垃圾收集机制最大的不同在于,垃圾收集的开销被分摊到整个应用程序的运行当中了,而不是在进行垃圾收集时,要挂起整个应用的运行,直到对堆中所有对象的处理都结束。因此,采用引用计数的垃圾收集不属于严格意义上的"Stop-The-World"的垃圾收集机制。这个也可以从它的伪代码实现中看出:
New(): //分配内存 ref <- allocate() if ref == null error "Out of memory" rc(ref) <- 0 //将ref的引用计数(reference counting)设置为0 return ref atomic Write(dest, ref) //更新对象的引用 addReference(ref) deleteReference(dest) dest <- ref addReference(ref): if ref != null rc(ref) <- rc(ref)+1 deleteReference(ref): if ref != null rc(ref) <- rc(ref) -1 if rc(ref) == 0 //如果当前ref的引用计数为0,则表明其将要被回收 for each fld in Pointers(ref) deleteReference(*fld) free(ref) //释放ref指向的内存空间 对于上面的伪代码,重点在于理解两点,第一个是当对象的引用发生变化时,比如说将对象重新赋值给新的变量等,对象的引用计数如何变化。假设我们有两个变量p和q,它们分别指向不同的对象,当我们将他们指向同一个对象时,下面的图展示了p和q变量指向的两个对象的引用计数的变化。
一.明确一些基本概念 屏幕尺寸:屏幕的对角线的长度,以inch为单位。1英寸=2.54cm
屏幕分辨率:横纵向方向像素的大小,纵向像素横向像素,如1920px1080px,单位像素(px)
像素密度DPI( dot per inch):每英寸的像素点数 简称像素密度。
三者关系
像素密度=Sqrt(横向像素横向像素+纵向像素纵向像素)/屏幕尺寸
拿1920X1080,屏幕尺寸为6英寸的手机举例:
1920x1920+1080x1080=4852800,
4852800在开方后约等于2202,
2202/6=367
这个手机的像素密度就是367
屏幕密度(density),density和dpi的关系为 density = dpi/160
名称 代表的分辨率(px)像素密度范围应用图标icon(2:3:4:6:8)ldpi 240x320?dpi-120dpi48*48dp(36*36px)mdpi 320x480120dpi-160dpi48*48dp(48*48px)假设切的图标大小为48dphdpi 480x800160dpi-240dpi48*48dp(72*72px)xhdpi 720x1280240dpi-320dpi48*48dp(96*96px)xxhdpi 1080x1920320dpi-480dpi48*48dp(144*144px)xxxhdpi 1440x2560 480dpi-640dpi48*48dp(192*192px) PPI 全称为 Pixel Per Inch,译为每英寸像素取值,更确切的说法应该是像素密度,也就是衡量单位物理面积内拥有像素值的情况。 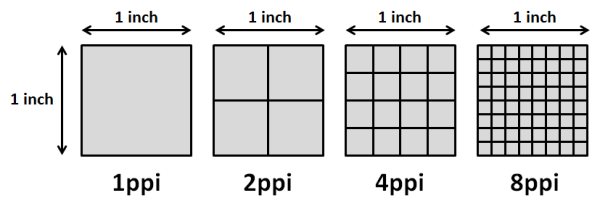 密度无关像素:density-independent pixel,叫dp或dip,与终端上的实际物理像素点无关 可以保证在不同屏幕像素密度的设备上显示相同的效果 在Android中,规定以160dpi(即屏幕分辨率为320x480)为基准:1dp=1px
dip和px之间的转换关系 1dip= (手机的像素密度/160dpi)px
当手机的像素密度是160dpi时 1dip = (160/160)*1px 即1dip = 1px
例如:800480 240dpi的手机
1dip = (240dpi/160dpi)px=1.5px
所以如果要在480320 像素密度为160dpi的手机表示320px就需要320dip来表示
如果也在800480,像素密度为240dpi的手机上也用320dip,则320dip代表320(240/160)px=480px
这就说明在像素密度为160dpi手机上如果用160dip表示屏幕的宽度,则将这个160dip
放到像素密度为240dpi的手机上也是一个屏幕的宽度。这样就达到了同样的效果。
如果涉及到dip和sp相互转换时,描述手机时,仅仅用分辨率是不够的,主要是要用到像素密度,因为
这两个单位的转换,涉及到的其实是手机的像素密度。
sp的使用google推荐使用12sp以上的字体大小,设置的比12小,用户可能看到。
不要使用小数,奇数,否则可能造成精度的丢失。
获取屏幕分辨率信息的方法
DisplayMetrics metrics = new DisplayMetrics();
Display display = activity.
unique “去除相邻的相同元素” 实际并未去除 只是把不重复的依次移动到了前面 实现方法如下:
iterator My_Unique (iterator first, iterator last) { if (first==last) return last; iterator result = first; while (++first != last) { if (!(*result == *first)) *(++result)=*first; } return ++result; } 但是unique 返回了++result 因此可以配合erase删除区间
a.erase(unique(a.begin(), a.end()), a.end());
点击下载来源:rufus(u盘引导盘制作工具) v3.5.1497
rufus是一款小巧实用、开源免费的系统u盘制作软件,当你需要安装系统又没有带装有系统的U盘或者刻录光盘的时候,这款软件就该上场了,可以帮你安装Windows系统和linux系统哦。该软件体积虽然很小,才900k,但是他的功能却很全面,正所谓浓缩就是精华。本站提供rufus(u盘引导盘制作工具)中文绿色版下载端口,没错,不仅支持中文版,而且软件是免安装去广告的,当然软件的稳定性、安全性、成功率也是有很大保障的,欢迎有需要的朋友免费下载体验。
rufus
功能介绍
1、支持把一些可引导的ISO格式的镜像(Windows,Linux,UEFI等)创建成USB安装盘。
2、麻雀虽小,五脏俱全,体积虽小,功能全面。
3、Rufus 还 非常快,比如,在从ISO镜像创建 Windows 7 USB安装盘的时候,他比 UNetbootin,Universal USB Installer 或者 Windows 7 USB download tool 大约快2倍。
4、可以帮助格式化和创建可引导USB闪存盘的工具,比如 USB 随身碟,记忆棒等等。
软件特色
1、完全免费。
2、界面简单,上手容易。
3、功能全面,同时支持windows和linux系统。
4、速度快,这个软件制作自启动U盘时需要的速度比其他软件快得多。
5、这个软件还有带free dos版本。个人认为这个应该是毫无用处的,随便制作一个linux启动盘都比dos好用几百倍。
6、最后还要说明的是,使用rufus后的u盘还是可以用来存储文件,你可以在xp、vista、windows 7、win 8等系统上运行这个软件。
使用方法
1、下载操作系统的 ISO 镜像文件。
2、将准备制作的U盘插到电脑上,并备份好 U 盘的资料,下面的操作将会完全清除掉U盘全部内容。
3、运行 Rufus USB 启动盘制作软件。
4、在「设备」的下拉选项里选中该 U 盘对应的盘符。
5、引导类型选择「镜像文件」并点击右边的「选择」按钮找到你下载好的系统镜像文件。
6、根据不同操作系统的需求,选择分区类型和目标系统类型。
7、点击「开始」按钮即会开始进行启动盘的制作。
常见问题
如何格式化U盘?
1、插入U盘后启动制作工具。
2、在【创建可使用的启动磁盘】选项里下拉菜单后面选择“iso image”模式,点击后面的图标选择iso镜像文件。
3、点击【开始】按钮,确认格式化U盘即可进行制作。
1
格式说明
1、对DOS支持的说明
如果你创建了一个DOS启动盘,但是没有使用美式键盘,Rufus 会尝试根据设备选择一个键盘布局,在那种情况下推荐使用 FreeDOS(默认选项)而不是 MS-DOS,因为前者支持更多的键盘布局。
2、对ISO支持的说明
Rufus v1.10 及其以后的所有版本都支持从 ISO 镜像 (.
叉乘的应用 叉积的几何意义
|c|=|a×b|=|a| |b|sinα (α为a,b向量之间的夹角)
已知向量A和B,A × B的到如图红色的向量,根据右手螺旋定则,手指指向A,向B方向合拢,大拇指向上为正,向下为负。
向量p=(a,b), q=(c,d)
p × q = ad - bc
应用 1、计算面积 向量p=(a,b), q=(c,d)
p × q = ad - bc = - q × p
叉乘的大小等于于2倍三角形面积(叉乘结果取绝对值)
2、判断点与直线的关系 设向量P=(x1,y1),Q=(x2,y2)
P × Q
①若结果为正,则P在Q的顺时针方向;
②若结果为负,则P在Q的逆时针方向;
③若结果为零,则P与Q共线,也就是平行,可能同向可能反向
3、求直线交点 设直线1经过两点(x1,y1)、(x2,y2),直线2过两点(x3,y3)、(x4,y4).
先用叉乘判断两直线是否相交:
int a=x2-x1,b=y2-y1; int c=x4-x3,d=y4-y3; int cha=a*d-b*c; 如果叉积cha不等于0则相交,若为0则平行或者重合。
求交点:
int a1=y1-y2; int b1=x2-x1; int c1=x1*y2-x2*y1; int a2=y3-y4; int b2=x4-x3; int c2=x3*y4-x4*y3; int D1=a2*b1-a1*b2; int D2=a1*b2-a2*b1; double X=1.
0、引言
Z3 是微软研究领域最先进的定理证明器。它可以用来检查逻辑公式在一个或多个理论上的可满足性。Z3为软件分析及验证工具提供了一个引人注目的匹配, 因为几个常见的软件构造直接映射到支持的理论中
1、Z3的基本架构:
在深入研究Z3的体系结构细节之前,让我们看一下Z3的体系结构,以了解它是如何执行的。Z3集成了一个SAT求解器、一个核心理论求解器(同余闭合核)、4个辅助求解计算器以及一个e匹配抽象机(e-match)。它的体系结构如图1所示。
图 1 架构图
Z3的简化器(simplifier )采用了一种不完整但有效的简化方案。例如,它将p^true简化为p,将x=4^f(x)简化为f(4)(在这两个例子中,运算符^用作逻辑运算符And。Z3的编译器被认为是一个节点,它将简化的输入转换成由一组子句和同余闭包节点组成的不同的数据结构。同余闭包核心处理等式和未解的函数。它接收来自SAT求解器的赋值,并使用E-matching方法对其进行处理。SAT求解器对公式进行求解,并将结果传递回同余闭合核。然后同余闭合核对结果进行处理。有四种主要类型的理论求解器,用于算术,数组和其他。它们是线性算术、位向量、数组和元组。理论求解基于同余闭包算法,这是大多数SMT求解器使用的算法。因此,同余闭包可以作为核心解算器,其他理论解算器可以作为外围辅助解算器。
2、程序源码组织结构
Z3最初并不是一个开源软件,而是在公司内部和研究团队中使用的。因此,Z3的源代码一开始组织并不太好。在Z3对开源候,为了更好地为其他用户提供使用,开发人员开始重写代码的某些部分并清理了Z3存储库。他们将所有代码都放到z3/src目录中,并使在z3/src的子目录中更容易找到某个模块。现在Z3的源代码可读性很好,而且组织结构比较清晰。
图 2 源码组织图
Z3项目库有以下四个子目录:
1)、z3/doc,用于生成API doc文件和代码doc文件。
2)、z3/examples,它提供了一组示例或基准测试,帮助用户理解如何用不同的API语言表示问题。
3)、z3/scripts,包含用了于更新外部z3 API的文件
4)、z3/src,它包含了z3的所有核心模块。
3、模块分析
通过对代码组织的了解,我们可以继续将Z3划分如下几个模块。(如图3中的文件夹模块所示)
1)、Make和Built模块:为使用Z3做准备。
2)、RiSE4fun模块:在线工具其他项目模块:集成Z3到其他项目。
3)、scripts模块:支持make和build模块,文档更新功能模块:包含解析器、测试器、求解器、sat、model等一系列子模块的核心模块。
4)、API、sat和math模块:支持不同输入格式的源代码Doc模块:生成API和代码文档。
此外,位于另一个存储库中的测试模块是整个项目的单独部分,它提供了测试基础设施和基准测试。
4、层次分析
一个软件应用程序,在开发软件体系结构时要考虑三个方面的问题,即描述/工具层、业务/领域层和数据/代码访问层。这种分层结构为我们分析Z3项目提供了参考。在这里我们使用支持层而不是数据访问层,因为我们认为这样更合适。
1)、工具层(utility):这一层用于用户和Z3之间的交互。我们可以在不同的平台上使用Z3和命令行。此外,我们也可以在RiSE4fun网站上测试Z3,或者将Z3插入到其他项目中。Make和build模块是使用命令行Z3的重要部分。它们是用于使用前的编译等工作。这两个模块依赖于核心层中的脚本模块,因为脚本模块中的python文件对于执行make和build是必需的。
2)核心层(core):这一层主要是Z3核心功能的实现。在核心层,大部分模块用于实现Z3的功能的源码实现。作为一个定理证明者,给出一个定理的正确结果的必要步骤包括解析(看看语法和语义是否正确)、测试(结果)、解决(问题)、判断(它是否是一个可满足的sat定理)和生成模型(如果这个定理是一个可满足的)。这些模块及其依赖关系如图3所示。此外,脚本也是整个项目的核心模块,没有脚本Z3是无法安装和使用的。
3)、支持层(support):这一层提供了支持核心层操作的基本功能、理论和公式。这一层中的API、math和smt模块都是用于此目的的。此外,doc模块也在这一层,因为它提供API和代码文档,并且支持Z3的实现和使用。
图 3 Z3层次图
此外,还有一个名为test的文件夹,它包含用于测试Z3的测试基础设施和基准。
5、特征分析
特性被定义为软件项目的一个区别特征(例如,性能、可移植性或功能)。当一个系统有许多可供用户选择的选项和功能时,它就被称为功能丰富的系统。Z3的典型特征见下表。
特征
描述
编译
如何构建Z3
API
提供那些编程语言可供用户构建应用
OS
Z3支持的操作系统
用户界面
在哪里可以使用Z3
输入格式
如何输入逻辑公式
求解
当公式满足时,用户如何获取模型及相关变量的解
理论
可用Z3求解的相关理论领域
编译器: Windows用户可以使用Visual Studio编译Z3源代码,而其他平台可以使用Makefile(基于g++和clang++)编译Z3作为替代。
API: Z3是一个低级工具。在需要解决逻辑公式的其他工具的上下文中,最好将其作为组件使用。因此,Z3公开了许多API工具,以方便工具映射到Z3。这些编程api由. net、c++、C、Java、Ocmal和Python组成。操作系统:Z3支持所有主要的操作系统,包括Windows、MacOS X、Linux和FreeBSD,从而促进了Z3的普及。
用户界面:有一个在线工具rise4fun,使用基于SMT 2语言的文本界面显示Z3的主要功能。然而,大多数应用程序使用Z3编程API来访问这些特性。可以通过构建Z3的源代码或通过外部IDE访问这些Z3编程api。
输入格式:与上述用户界面对应,需要满足性检查和求解的逻辑公式可以用SMT 2.0语言或Z3 API输入(参见示例)。此外,还可以将本机文本输入Z3。
线段覆盖
给定x轴上的N(0<N<100)条线段,每个线段由它的二个端点a_I和b_I确定,I=1,2,……N.这些坐标都是区间(-999,999)的整数。有些线段之间会相互交叠或覆盖。请你编写一个程序,从给出的线段中去掉尽量少的线段,使得剩下的线段两两之间没有内部公共点。所谓的内部公共点是指一个点同时属于两条线段且至少在其中一条线段的内部(即除去端点的部分)。
输入描述 Input Description
输入第一行是一个整数N。接下来有N行,每行有二个空格隔开的整数,表示一条线段的二个端点的坐标。
输出描述 Output Description
输出第一行是一个整数表示最多剩下的线段数。
样例输入 Sample Input
3
6 3
1 3
2 5
样例输出 Sample Output
2
数据范围及提示 Data Size & Hint
0<N<100
基础线段覆盖模型 -> 贪心
直接按照右端点从小到大排序。优先选排在前面的。
证明:排序后显然当你选了一个线段后,再要从后面选一个线段,其左断点必须>=你的右端点。右端点当然越小越好。
代码如下:
public class Test { private static void quickSort(int[][] arr, int low, int high){ if (low >= high || arr.length == 0) return; int i = low; int j = high; int x = arr[low][1]; while (i < j){ //从右向左查找第一个小于x的坐标 while (i < j && arr[j][1] > x) j--; //从左向右查找第一个大于x的坐标 while (i < j && arr[i][1] <= x) i++; if (i < j){ int p1 = arr[i][1]; int p2 = arr[i][0]; arr[i][1] = arr[j][1]; arr[i][0] = arr[j][0]; arr[j][1] = p1; arr[j][0] = p2; } } int tmp1 = arr[i][1]; int tmp2 = arr[i][0]; arr[i][1] = arr[low][1]; arr[i][0] = arr[low][0]; arr[low][1] = tmp1; arr[low][0] = tmp2; //左排 quickSort(arr, low, i-1); //右排 quickSort(arr, i+1, high); } public static void main(String[] args) { Scanner scan = new Scanner(System.
昨晚看了一篇公众号的文章:https://mp.weixin.qq.com/s/idzZVuncx3XPcQwEZ4C3cg
上面有介绍数字黑洞“6174”,论坛上也有很多,大概的历史由来不在赘述,随便找一个数如“1314”,看下图足矣:
其中,流程分两步,一步是自己输入一个数字不全相同的四位数(1111,2222等等的不要),由程序计算出数字黑洞;然后由程序随机出100个四位数,分别算数数字黑洞,最后如果这些数的数字黑洞都是同一个数,说明这样的数字黑洞是存在的!
如果要更严谨的话,应该遍历所有的四位数,要实现起来也很简单,只是我想练习使用随机数的代码而已~
po上自己写的代码,跟大家交流!
#include <iostream> #include <cmath> #include <random> using namespace std; int new_quard_diff(int quard) { int a[4]; int new_quard_max; int new_quard_min; a[0] = quard / 1000 % 10; a[1] = quard / 100 % 10; a[2] = quard / 10 % 10; a[3] = quard / 1 % 10; sort(a, a + 4, greater<int>());//由大到小排列 new_quard_max = a[0] * 1000 + a[1] * 100 + a[2] * 10 + a[3]; new_quard_min = a[3] * 1000 + a[2] * 100 + a[1] * 10 + a[0]; return new_quard_max - new_quard_min; } int main() { int a,b,i; cout << "
矩阵中要求每个向量的长度一致,因此,在循环语句下,若结果长度不一致,利用矩阵,则无法满足循环要求。故而采用元胞数组。cell语句的简单运用说明如下。
1. 元胞数组的建立 例1 创立元胞数组
2. 元胞数组的赋值 例2, 将向量 [1,2,3]放入元胞数组第一cell
例3,将向量 [1,2,3]放入元胞数组第一cell,将向量 [4,5,6]放入元胞数组第二cell
3. 元胞数组的索引 例4,索引元胞数组A的第一行第二列的元宝数组,索引出来的结果仍然是元胞数组
例5,索引元胞数组A的第一行第二列的元宝数组,索引出来的结果是元素,即,向量或者文本。
代码:
clc clear A=cell(1,3); % 例1 A(1,1)={[1,2,3]}; % 例2 A(1,1:2)={[1,2,3],[4,5,6]}; % 例3 B=A(1,2); % 例4 C=A{1,2}; % 例5 注:注意 “{}”、“[]”、“()” 在cell语句中的使用区别!!!