用MySQL对数据进行分析
分析目标:
根据某电商近期的销售记录,对每月的购买人数、复购率、回购率、消费时间、消费群体等进行分析。
数据来源
orderinfo表:
create table orderinfo(
orderid varchar(10) primary key,
userid varchar(10),
ispaid varchar(10),
prince varchar(20),
paidtime varchar(50));
userinfo表:
create table userinfo(
userid varchar(10) primary key,
sex char(2),
brith varchar(50));
导入数据:
本处用到MySQL自带的LOAD DATA INFILE的函数。对比了python的execute/executemany,LOAD DATA INFILE的速度真是非常快,谁用谁知道!
ps:如果用LOAD DATA INFILE,提示禁止加载本地数据;这必须在客户端和服务器端都启用。
那可能是加载本地文件没有开启,输入查看命令:show variables like 'local_infile';
然后开启:set global local_infile=on;
OK!
LOAD DATA LOCAL INFILE 'order_info.csv' into table orderinfo fields terminated by ',';
LOAD DATA LOCAL INFILE 'user_info.csv' into table orderinfo fields terminated by ',';
处理数据
由于orderinfo表中的paidtime与userinfo表中的brith是字符串类型,需要转换成日期类型,分别用了两种方法实现。
ALTER TABLE orderinfo CHANGE paidtime paidtime datetime;
UPDATE userinfo SET brith = CAST( brith AS date );
分析问题
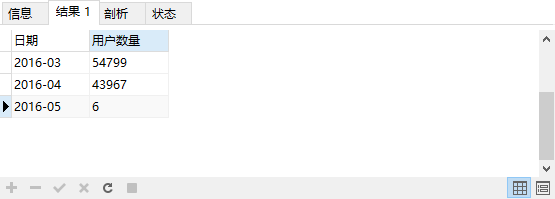
统计各个月份的下单人数
SELECT DATE_FORMAT(paidtime,'%Y-%m') as '日期',
count( DISTINCT userid ) as '用户数量'
FROM
orderinfo
WHERE
ispaid = '已支付'
GROUP BY
MONTH ( paidtime );
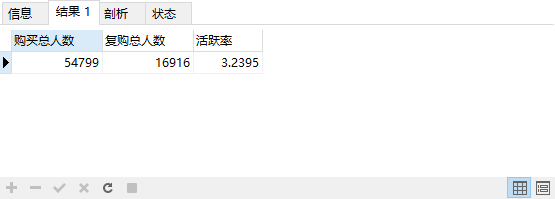
统计用户三月份的复购率和回购率
#复购率是在本月消费中多少人消费一次以上的占比
SELECT
COUNT( userid ) AS '购买总人数',
SUM( a ) AS '复购总人数',
COUNT( userid )/ SUM( a ) AS '活跃率'
FROM
( SELECT userid, IF ( count(*)> 1, 1, 0 ) AS a FROM orderinfo WHERE MONTH ( paidtime )= 3 GROUP BY userid ) AS t;
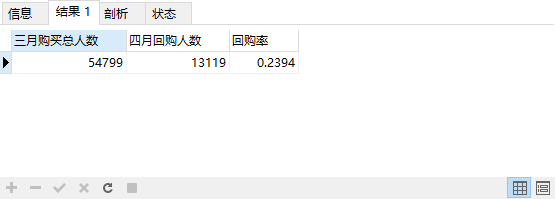
#回购率是三月份购买的人数在四月份依旧购买的占比
SELECT
COUNT( DISTINCT t1.userid ) AS '三月购买总人数',
COUNT( DISTINCT t2.userid ) AS '四月回购人数',
COUNT( DISTINCT t2.userid )/ COUNT( DISTINCT t1.userid ) AS '回购率'
FROM
( SELECT DISTINCT userid FROM orderinfo WHERE MONTH ( paidtime )= 3 ) AS t1
LEFT JOIN ( SELECT DISTINCT userid FROM orderinfo WHERE MONTH ( paidtime )= 4 ) AS t2
ON t1.userid = t2.userid;
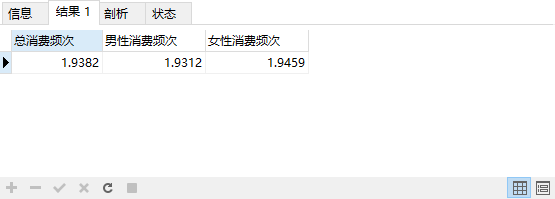
统计男女的消费频次是否有差异
SELECT
COUNT( userid )/ COUNT( DISTINCT userid ) AS '总消费频次',
COUNT( M )/ COUNT( DISTINCT M ) AS '男性消费频次',
COUNT( F )/ COUNT( DISTINCT F ) AS '女性消费频次'
FROM
(
SELECT
t1.orderid,
t1.userid,
IF
( sex = '男', t1.userid, NULL ) AS M,
IF
( sex = '女', t1.userid, NULL ) AS F
FROM
orderinfo AS t1
INNER JOIN userinfo AS t2 ON t1.userid = t2.userid
WHERE
t2.sex IS NOT NULL
) t3;
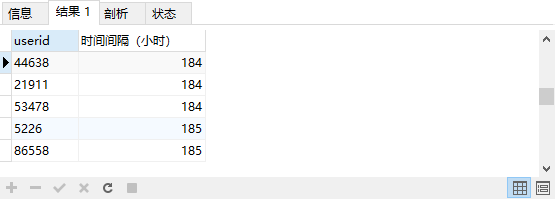
统计多次消费的用户,第一次和最后一次消费时间的间隔
SELECT
userid,
TIMESTAMPDIFF(
HOUR,
min( paidtime ),
max( paidtime )) '时间间隔(小时)'
FROM
orderinfo
WHERE
paidtime IS NOT NULL
GROUP BY
userid
HAVING
COUNT( orderid )> 1
ORDER BY
时间间隔(小时);
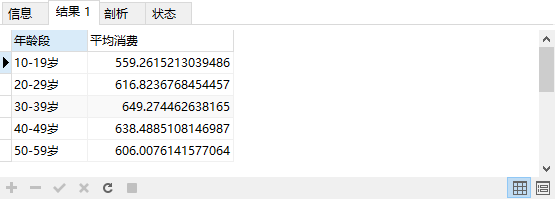
统计不同年龄段的用户消费金额是否有差异
SELECT
t2.age as '年龄段',
AVG( t1.prince ) as '平均消费'
FROM
orderinfo AS t1
INNER JOIN (
SELECT
userid,
CASE
WHEN TIMESTAMPDIFF( YEAR, brith, '2016-01-01' ) BETWEEN 10 and 19 THEN
'10-19岁'
WHEN TIMESTAMPDIFF( YEAR, brith, '2016-01-01' ) BETWEEN 20 and 29 THEN
'20-29岁'
WHEN TIMESTAMPDIFF( YEAR, brith, '2016-01-01' ) BETWEEN 30 and 39 THEN
'30-39岁'
WHEN TIMESTAMPDIFF( YEAR, brith, '2016-01-01' ) BETWEEN 40 and 49 THEN
'40-49岁'
WHEN TIMESTAMPDIFF( YEAR, brith, '2016-01-01' ) BETWEEN 50 and 59 THEN
'50-59岁'
WHEN TIMESTAMPDIFF( YEAR, brith, '2016-01-01' ) BETWEEN 60 and 69 THEN
'60-69岁'
WHEN TIMESTAMPDIFF( YEAR, brith, '2016-01-01' ) BETWEEN 70 and 79 THEN
'70-79岁'
ELSE NULL
END
AS age FROM userinfo WHERE brith IS NOT NULL ) AS t2
ON t1.userid = t2.userid
WHERE t1.ispaid = '已支付' AND t2.age IS NOT NULL
GROUP BY age ORDER BY age;
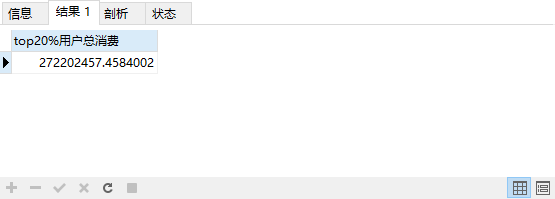
统计消费的二八法则,消费的top20%用户,贡献了多少额度
SELECT
sum( t1.user_prince ) as 'top20%用户总消费'
FROM
(
SELECT
userid,
SUM( prince ) AS user_prince,
row_number() over ( ORDER BY sum( prince ) DESC ) AS num
FROM
orderinfo
WHERE
ispaid = '已支付'
GROUP BY
userid
) AS t1
WHERE
num <(
SELECT
count( DISTINCT userid )* 0.2
FROM
orderinfo
WHERE
ispaid = '已支付'
);