语义分割入门系列之 FCN(全卷积神经网络)
FCN论文解读及代码分析
Fully Convolutional Networks for Semantic Segmentation
FCN是卷积神经网络用于语义分割的开山之作,文章的出发点在于如何将普通的分类卷积神经网络用于语义分割网络。卷积神经网络在分类任务上取得了重大突破,因为随着卷积网络的层数加深,网络从图像中提取出越来越抽象的语义信息特征图的通道数越来越多,并且为了控制计算量,特征图的分辨率越来越小,并且最后还有全连接层做softmax预测,将整个图片的空间位置信息全部破坏。
FCN便从这方面入手,提出方案将普通分类卷积神经网络改造成能够进行语义分割的网络。下面来介绍FCN到底是如何做的。
1.修改分类器,使网络能够密集预测
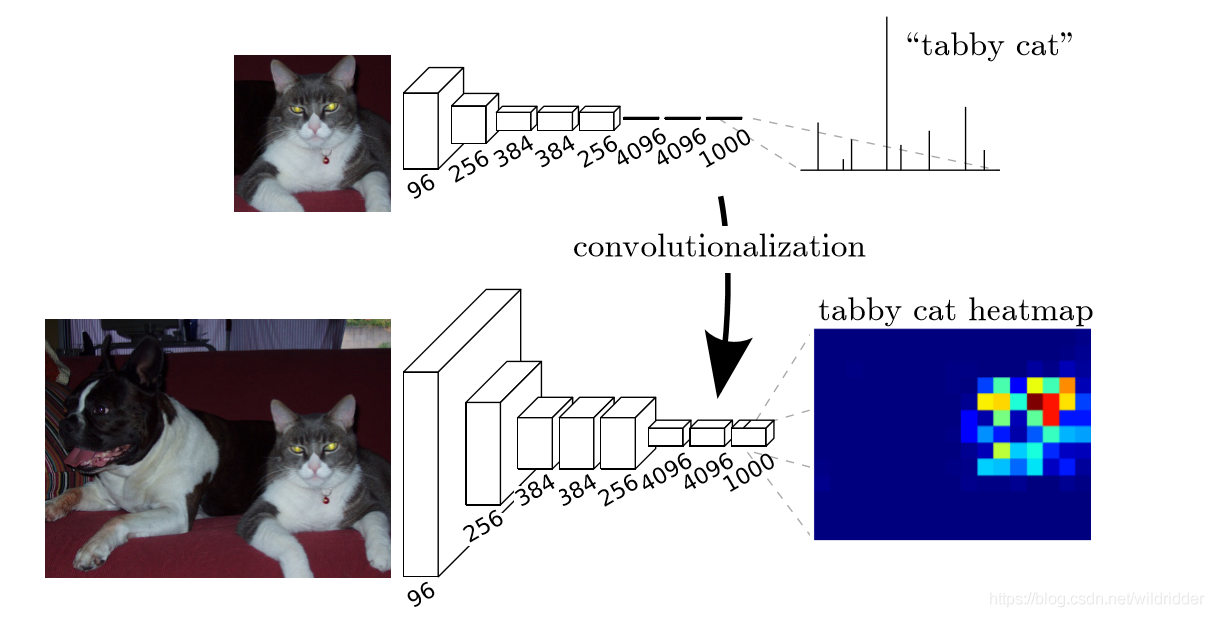
如图所示,普通的分类神经网络最后的全连接层,输出的是该图片对应于每个分类的概率。将最后的全连接层全部替换成1x1的卷积卷积核,这样既实现全连接层的计算功能,又保持了特征图的空间分辨率,可以生成一个分类网络的热力图,热力图的分辨率很低,但是依然可以表示出让网络做出该判断的响应位置,这样就有了位置信息(很粗糙的位置信息)。并且,替换掉全连接层后带来的好处是,输入图片的尺寸可以是任意size的。
2. 深层与浅层的融合
上一步将全连接层替换成卷积层之后,特征响应的位置得以保留,但是网络最后特征图的尺寸已将很小(VGG经过5次下采样,resnet也经过5次下采样,最后一个特征图的分辨率是原图的2^5=32倍,虽然有特征响应的位置,但是无法对应到原图的精确位置),所以,FCN提出将深层的、分辨率粗糙的语义信息,与浅层的高分辨率的精细特征结合,以此来修复热力图的分辨率,使其不断上采样到原图尺寸,这样就得到了原图分辨率的结果。具体操作如下图:
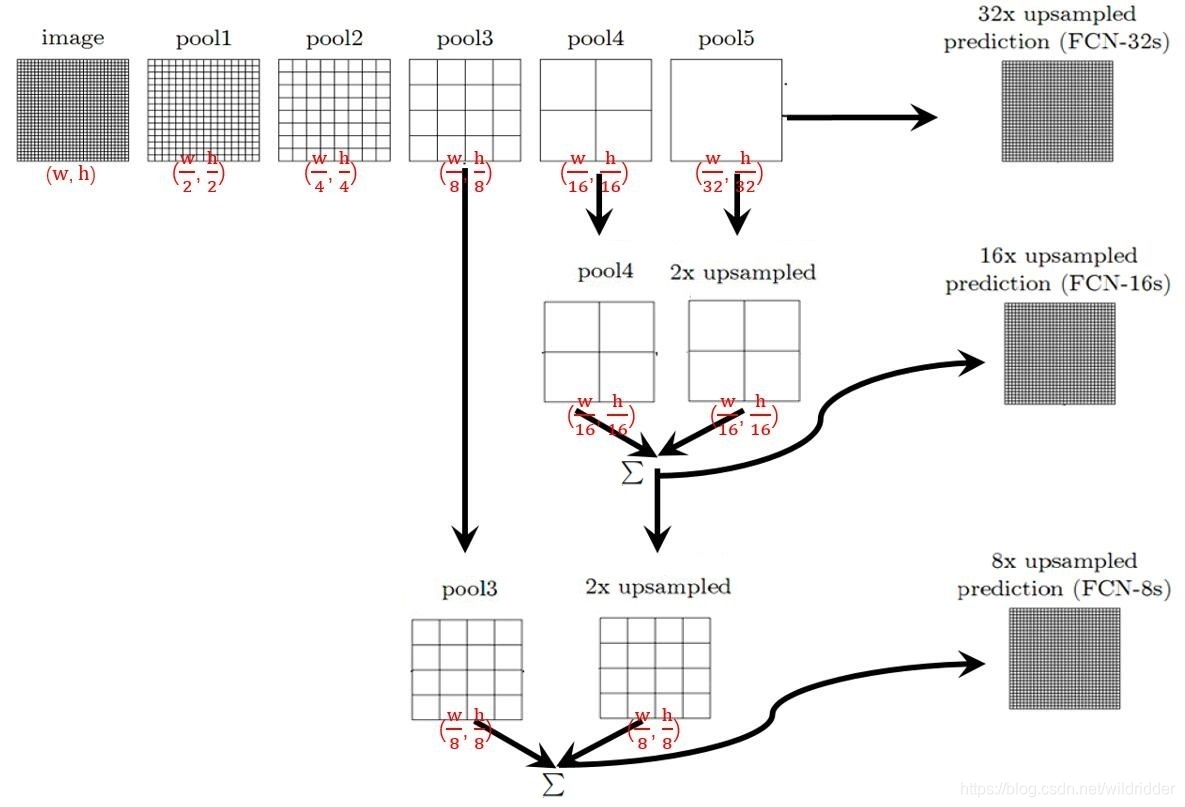
图片来自:https://zhuanlan.zhihu.com/p/31428783,比论文原图更好理解
FCN32s是将最后一个特征图,直接上采样32倍(5次步长为2的3x3的反卷积操作),得到最后的分割结果。代码如下(pytorch实现):其中pretrained_net表示的是backbone网络
class FCN32s(nn.Module):
def __init__(self, pretrained_net, n_class):
super().__init__()
self.n_class = n_class
self.pretrained_net = pretrained_net
self.relu = nn.ReLU(inplace=True)
self.deconv1 = nn.ConvTranspose2d(512, 512, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn1 = nn.BatchNorm2d(512)
self.deconv2 = nn.ConvTranspose2d(512, 256, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn2 = nn.BatchNorm2d(256)
self.deconv3 = nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.deconv4 = nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn4 = nn.BatchNorm2d(64)
self.deconv5 = nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn5 = nn.BatchNorm2d(32)
self.classifier = nn.Conv2d(32, n_class, kernel_size=1)
def forward(self, x):
output = self.pretrained_net(x)
x5 = output['x5']
score = self.bn1(self.relu(self.deconv1(x5)))
score = self.bn2(self.relu(self.deconv2(score)))
score = self.bn3(self.relu(self.deconv3(score)))
score = self.bn4(self.relu(self.deconv4(score)))
score = self.bn5(self.relu(self.deconv5(score)))
score = self.classifier(score)
return score
FCN16s则是将最后一个特征图(pool5的结果)用步长为2的3x3反卷积(参数可学)上采样一倍,得到的结果与pool4的结果相加,它们俩的分辨率相同,都是原图的1/16。这样得到的结果在通过16倍上采样得到与原图相同的分辨率。
class FCN16s(nn.Module):
def __init__(self, pretrained_net, n_class):
super().__init__()
self.n_class = n_class
self.pretrained_net = pretrained_net
self.relu = nn.ReLU(inplace=True)
self.deconv1 = nn.ConvTranspose2d(512, 512, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn1 = nn.BatchNorm2d(512)
self.deconv2 = nn.ConvTranspose2d(512, 256, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn2 = nn.BatchNorm2d(256)
self.deconv3 = nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.deconv4 = nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn4 = nn.BatchNorm2d(64)
self.deconv5 = nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn5 = nn.BatchNorm2d(32)
self.classifier = nn.Conv2d(32, n_class, kernel_size=1)
def forward(self, x):
output = self.pretrained_net(x)
x5 = output['x5']
x4 = output['x4']
score = self.relu(self.deconv1(x5))
score = self.bn1(score + x4)
score = self.bn2(self.relu(self.deconv2(score)))
score = self.bn3(self.relu(self.deconv3(score)))
score = self.bn4(self.relu(self.deconv4(score)))
score = self.bn5(self.relu(self.deconv5(score)))
score = self.classifier(score)
return score
FCN8s 则是将FCN16s中1/16的特征图,再次通过一个2倍的上采样,与pool3的结果相加,得到原图分辨率1/8的特征图,再通过8倍的上采样得到原图相同分辨率分割结果。
class FCN8s(nn.Module):
def __init__(self, pretrained_net, n_class):
super().__init__()
self.n_class = n_class
self.pretrained_net = pretrained_net
self.relu = nn.ReLU(inplace=True)
self.deconv1 = nn.ConvTranspose2d(512, 512, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn1 = nn.BatchNorm2d(512)
self.deconv2 = nn.ConvTranspose2d(512, 256, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn2 = nn.BatchNorm2d(256)
self.deconv3 = nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.deconv4 = nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn4 = nn.BatchNorm2d(64)
self.deconv5 = nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn5 = nn.BatchNorm2d(32)
self.classifier = nn.Conv2d(32, n_class, kernel_size=1)
def forward(self, x):
output = self.pretrained_net(x)
x5 = output['x5']
x4 = output['x4']
x3 = output['x3']
score = self.relu(self.deconv1(x5))
score = self.bn1(score + x4)
score = self.relu(self.deconv2(score))
score = self.bn2(score + x3)
score = self.bn3(self.relu(self.deconv3(score)))
score = self.bn4(self.relu(self.deconv4(score)))
score = self.bn5(self.relu(self.deconv5(score)))
score = self.classifier(score)
return score
注意,以上步骤中的上采样全部都由3x3的反卷积操作完成,参数可学。
三者效果如下:

可见,直接上采样32倍的FCN32s效果最差,因为直接上采样太多倍导致结果粗糙,而后面逐步结合了浅层特征的网络结果效果则越来越好。
后续很多工作延续了这个思想,从分类网络的结果开始逐步结合前面的浅层特征,以实现精细的分割。
参考文献:Long J , Shelhamer E , Darrell T . Fully Convolutional Networks for Semantic Segmentation[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2014, 39(4):640-651.