ViT (Vision Transformer) ---- Text Generation(文本生成器)
- 使用RNN对文本预测
假如输入的文本是:the cat sat on the ma 那么下一个字符什么呢?
这里采用的是many to many模型,如下:
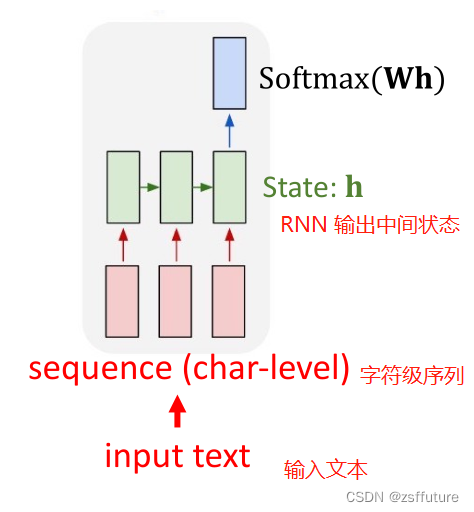
此时模型的输出字符概率为:
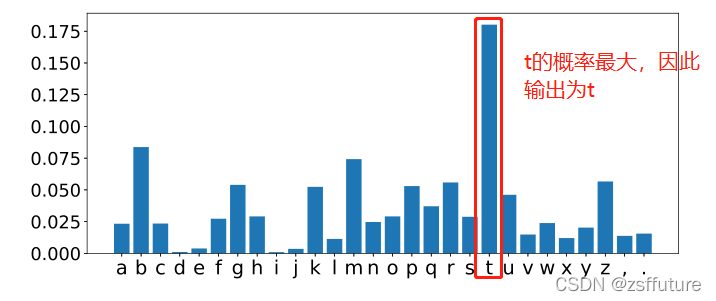
- 如何训练RNN模型?

如上一段英语文字,我们采用分割的方法,这里采用输入的长度为40,滑动距离为3,即从开始到第40个字符用作输入,
第41个字符用作标签数据label,如上:
输入为:Machine learning is a subset of artifici label为:a
上面是第一个训练数据对即pairs
第二个如下:

因为滑动为3,因此在第一个训练对的基础上,向后滑动三个字符在进行分割,分割距为40个字符,后面一个为对应的预测label,因此训练标签对为:
输入为:hine learning is a subset of artificial label为 :I
以此类推,直到把这个段落分割完,做成训练对
制作好的数据集,开始训练,输入数据,通过rnn的最后一个状态查找字符字典,然后和label进行比对,通过交叉熵进行计算loss,在通过优化机制和反向传播更新rnn的参数矩阵,然后迭代多次即可完成训练
- 制作数据集
下面就开始整个数据集的制作和训练
- 分割数据

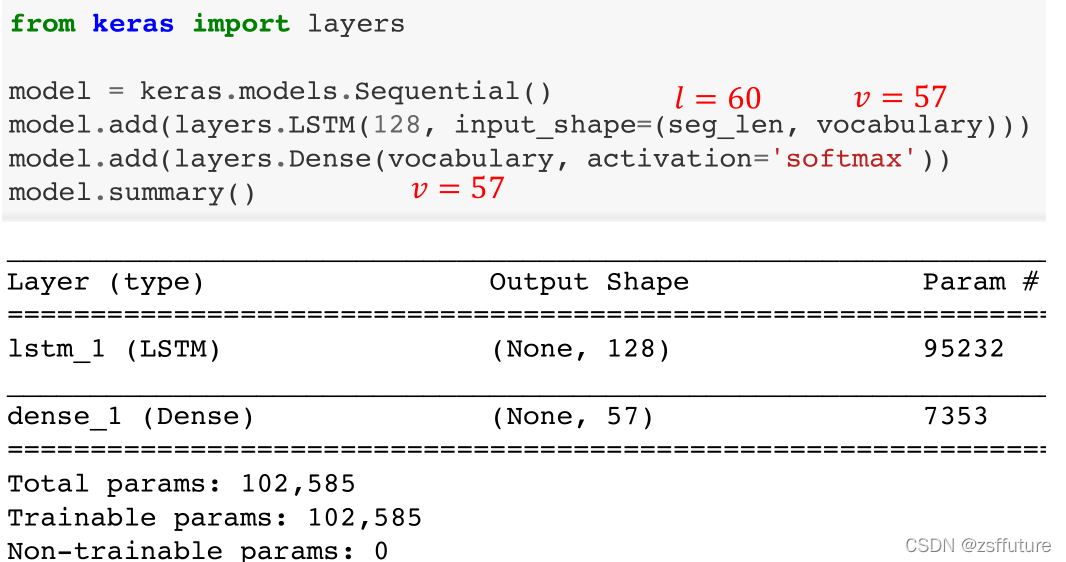
该步骤主要是把一段话或者一篇文章或者一本书进行字符分割,分割时有两个需要设置的参数,分割的长度,滑动长度,这里分割长度是60,滑动长度为3
- 字典制作
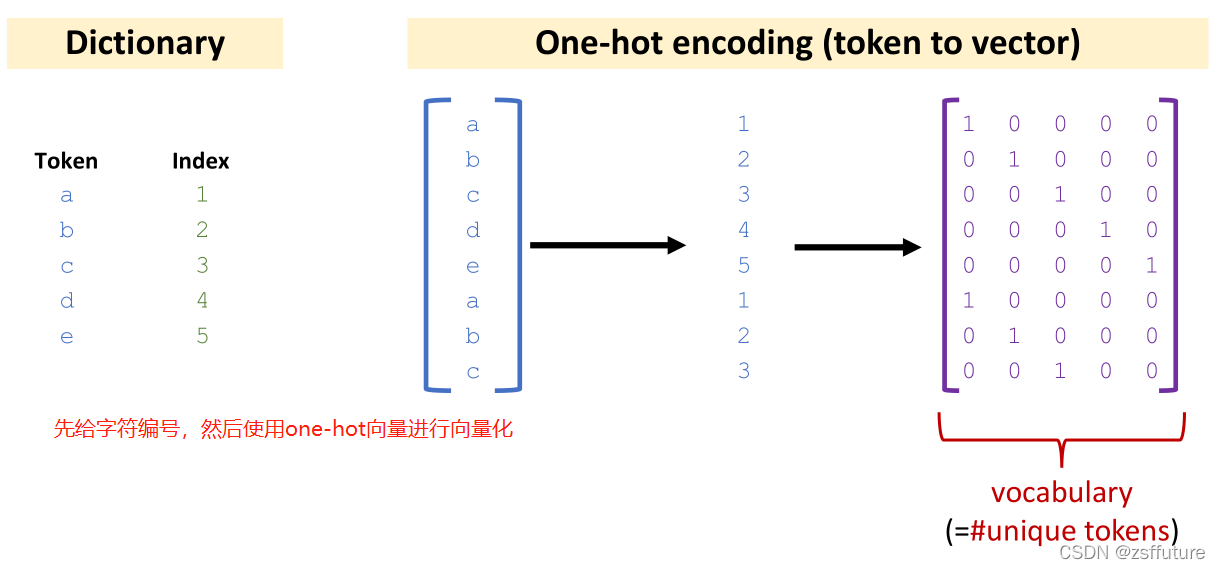
这里是制作字符的字典,英文有26个字符还要加上各种标点和空格总共有57个字符向量,现在按照顺序进行编号,然后给编号进行向量化,这样从字符到向量就完成了
第一步假设分割的段落长度为60,字符字典为57
那么每个段落对应的矩阵就表示为:

假如这里有200278这样的pair,都这样进行矩阵化,这样数据集就制作完成了
下面就是搭建模型训练了:
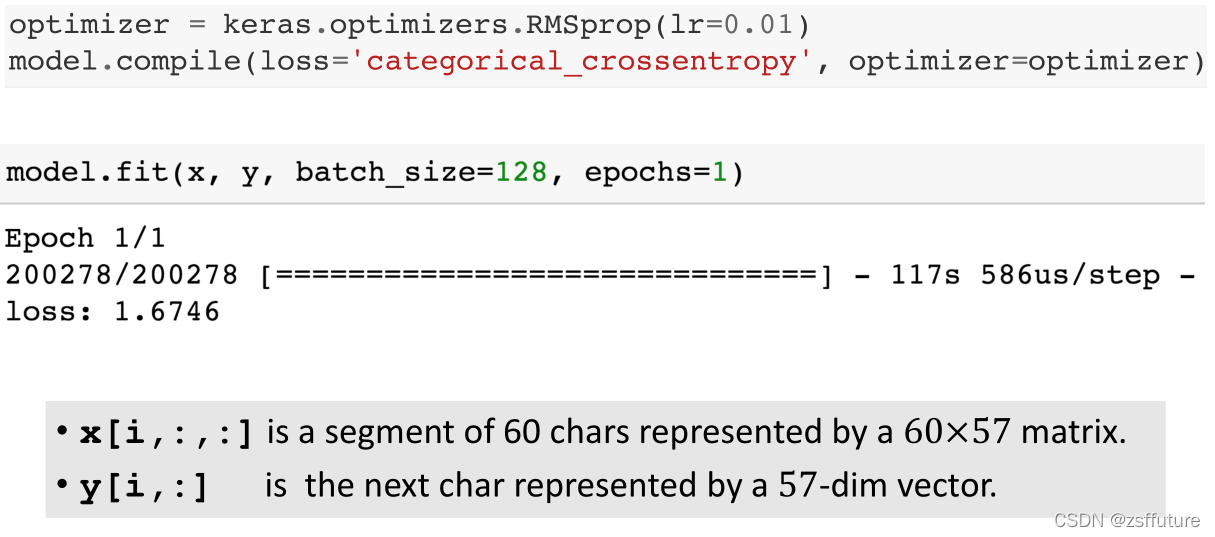
- 搭建模型并训练