淘宝购物数据分析(桑吉图制作)
import pandas as pd
import numpy as np
import pandas as pd
import matplotlib as mpl
from matplotlib import pyplot as plt
import seaborn as sns
import warnings
import matplotlib.dates as mdates
from pyecharts import options as opts
from pyecharts.charts import Funnel
from pyecharts.faker import Faker
from datetime import timedelta
from pyecharts.globals import CurrentConfig, OnlineHostType
from pyecharts import options as opts # 图形设置
from pyecharts.charts import Sankey # 导入桑基图型的类
from pyecharts.globals import ThemeType
from IPython.display import display, IFrame
# 去除warning提醒
warnings.filterwarnings('ignore')
# 用来显示中文标签
mpl.rcParams["font.family"] = "SimHei"
# 用来显示负号
mpl.rcParams["axes.unicode_minus"] = False#读取数据集
data=pd.read_csv('D: ')
# 使用shape属性获取行数
num_rows = data.shape[0]
print(num_rows)# 查看是否存在重复的行数据
(data.duplicated()).sum()
#删除重复行
data_del_chongfu=data.drop_duplicates()#查看列中是否存在缺失值数据
data.isnull().any(axis=0)#返回true证明有缺失数据,false:没有缺失数据re_buy1=data[data.behavior_type==4].groupby('user_id')['time'].apply(lambda x:len(x.unique()))
re_buy2=re_buy1[re_buy1>=2].count()/re_buy1.count()
re_buy2漏斗图:
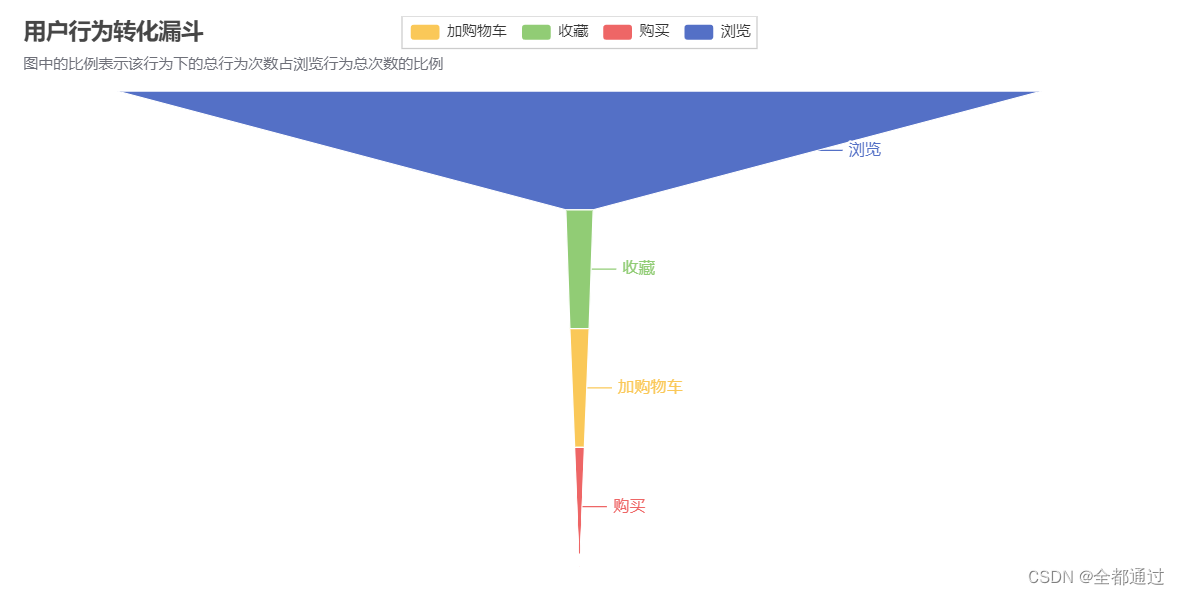
#漏斗分析:用户“浏览-收藏-加购-购买”的转化率是怎样的?哪一步的折损比例最大?
#用户行为转化漏斗图
pv_users = data[data.behavior_type == 1]['user_id'].count()
fav_users = data[data.behavior_type== 2]['user_id'].count()
cart_users = data[data.behavior_type== 3]['user_id'].count()
buy_users = data[data.behavior_type == 4]['user_id'].count()
attr = ['浏览', '收藏', '加购物车', '购买']
#####1:浏览pv 2:收藏fav 3:加购物车cart 4:购买buy
values = [np.around((pv_users / pv_users * 100), 2),
np.around((cart_users / pv_users * 100), 2),
np.around((fav_users / pv_users * 100), 2),
np.around((buy_users / pv_users * 100), 2)]
c = (
Funnel()
.add(
series_name="环节",
data_pair=[list(z) for z in zip(attr,values)],
sort_="descending", # 数据排序显示顺序为降序
label_opts=opts.LabelOpts(font_size=13,position="right",formatter="{b}"),
)
.set_global_opts(title_opts=opts.TitleOpts(title="用户行为转化漏斗",subtitle="图中的比例表示该行为下的总行为次数占浏览行为总次数的比例"))
)
c.render_notebook()
c.render("chart.html")
display(IFrame(src="./chart.html", width="100%", height="500px"))
# 使用空格分隔一列数据为两列
data[['time_1', 'time_2']] = data['time'].str.split(' ', 1, expand=True)
data.head(1)折线图:
# 绘制折线图
# 14年11月与12月的购买量变化趋势
data_buy=data[data.behavior_type==4]
value_counts = data_buy['time_1'].value_counts()
df = pd.DataFrame({'time': value_counts.index, 'count': value_counts.values})
df = df.sort_values('time', ascending=True)
x=df['time']
y=df['count']
fig, ax = plt.subplots(figsize=(20,8),dpi=100)
ax.plot(x,y)
# 添加标题和标签
ax.set_title("14年11月与12月的购买量变化趋势",fontsize=22)
ax.set_xlabel("时间",fontsize=18)
ax.set_ylabel("购买量",fontsize=18)
ax.xaxis.set_tick_params(rotation=90)
# 添加网格线
plt.grid(True)
# 显示图表
plt.show()
# 绘制折线图
# 一天中的购买量变化趋势
data_buy=data[data.behavior_type==4]
value_counts = data_buy['time_2'].value_counts()
value_counts
df = pd.DataFrame({'time': value_counts.index, 'count': value_counts.values})
df = df.sort_values('time', ascending=True)
x=df['time']
y=df['count']
fig, ax = plt.subplots(figsize=(20,8),dpi=100)
ax.plot(x,y)
# 添加标题和标签
ax.set_title("一天中的购买量变化趋势",fontsize=22)
ax.set_xlabel("时间",fontsize=18)
ax.set_ylabel("购买量",fontsize=18)
ax.xaxis.set_tick_params(rotation=90)
# 添加网格线
plt.grid(True)
# 显示图表
plt.show()
桑基图:
# 浏览总数:
data_1=data[data.behavior_type==1]
value_counts = data_1['item_id'].value_counts()
df_1 = pd.DataFrame({'item_id': value_counts.index, 'count': value_counts.values})
pv = df_1['count'].shape[0]
pv
#收藏总数
data_2=data[data.behavior_type==2]
value_counts = data_2['item_id'].value_counts()
df_2 = pd.DataFrame({'item_id': value_counts.index, 'count': value_counts.values})
fav = df_2['count'].sum()
fav
# 浏览+收藏总数
merged = pd.merge(df_1['item_id'], df_2['item_id'], how='inner')
pv_fav = merged.shape[0]
pv_fav
# 浏览+非收藏总数
pv_unfav=pv-pv_fav
pv_unfav
# 加购总数
data_3=data[data.behavior_type==3]
value_counts = data_3['item_id'].value_counts()
df_3 = pd.DataFrame({'item_id': value_counts.index, 'count': value_counts.values})
cart = df_3['count'].shape[0]#加购总数
cart
merged = pd.merge(df_1['item_id'], df_2['item_id'], how='inner')
merged1= pd.merge(merged, df_3['item_id'], how='inner')
pv_fav_cart = merged1.shape[0]
pv_fav_cart#收藏后进行加购的总数
# 浏览+收藏+非加购
pv_fav_uncart=pv_fav-pv_fav_cart
pv_fav_uncart
# 购买总数
data_4=data[data.behavior_type==4]
value_counts = data_4['item_id'].value_counts()
df_4 = pd.DataFrame({'item_id': value_counts.index, 'count': value_counts.values})
buy = df_4['count'].shape[0]#购买总数
buy
# 浏览+收藏+加购+购买
merged = pd.merge(df_1['item_id'], df_2['item_id'], how='inner')
merged1= pd.merge(merged, df_3['item_id'], how='inner')
merged2= pd.merge(merged1, df_4['item_id'], how='inner')
pv_fav_cart_buy = merged1.shape[0]
pv_fav_cart_buy
# 浏览+收藏+加购+非购买
pv_fav_cart_unbuy=pv_fav_cart-pv_fav_cart_buy
pv_fav_cart_unbuy
# 浏览+收藏
merged = pd.merge(df_1['item_id'], df_2['item_id'], how='inner')
# 浏览+收藏+非加购
# 使用 merge() 函数合并两个 DataFrame,并根据两列进行比较
merged = pd.merge(merged, df_3, left_on='item_id', right_on='item_id', how='outer')
count_nan = merged['count'].isna().sum()
count_nan
merged2= pd.merge(merged['item_id'], df_4['item_id'], how='inner')
pv_fav_uncart_buy = merged2.shape[0]
pv_fav_uncart_buy
# 浏览+收藏+非加购+非购买
pv_fav_uncart_unbuy=pv_fav_uncart-pv_fav_uncart_buy
pv_fav_uncart_unbuy
# 浏览+非收藏
merged=df_1[~df_1['item_id'].isin(df_2['item_id'])]
pv_unfav = merged.shape[0]
pv_unfav
# 浏览+非收藏+加购
merged2= pd.merge(merged['item_id'], df_3['item_id'], how='inner')
pv_unfav_cart = merged2.shape[0]
pv_unfav_cart
# 浏览+非收藏+非加购
pv_unfav_uncart=pv_unfav-pv_unfav_cart
pv_unfav_uncart
# 浏览+非收藏+加购+购买
merged3= pd.merge(merged2['item_id'], df_4['item_id'], how='inner')
pv_unfav_cart_buy = merged3.shape[0]
pv_unfav_cart_buy
# 浏览+非收藏+加购+非购买
pv_unfav_cart_unbuy=pv_unfav_cart-pv_unfav_cart_buy
pv_unfav_cart_unbuy
# 浏览+非收藏
merged=df_1[~df_1['item_id'].isin(df_2['item_id'])]
# 浏览+非收藏+非加购
merged2=merged[~merged['item_id'].isin(df_3['item_id'])]
pv_unfav_uncart = merged2.shape[0]
pv_unfav_uncart
# 浏览+非收藏+非加购+购买
merged3 = pd.merge(merged2, df_4['item_id'], how='inner')
pv_unfav_cart_buy = merged3.shape[0]
pv_unfav_cart_buy
pv_unfav_uncart_unbuy=pv_unfav_uncart-pv_unfav_cart_buy
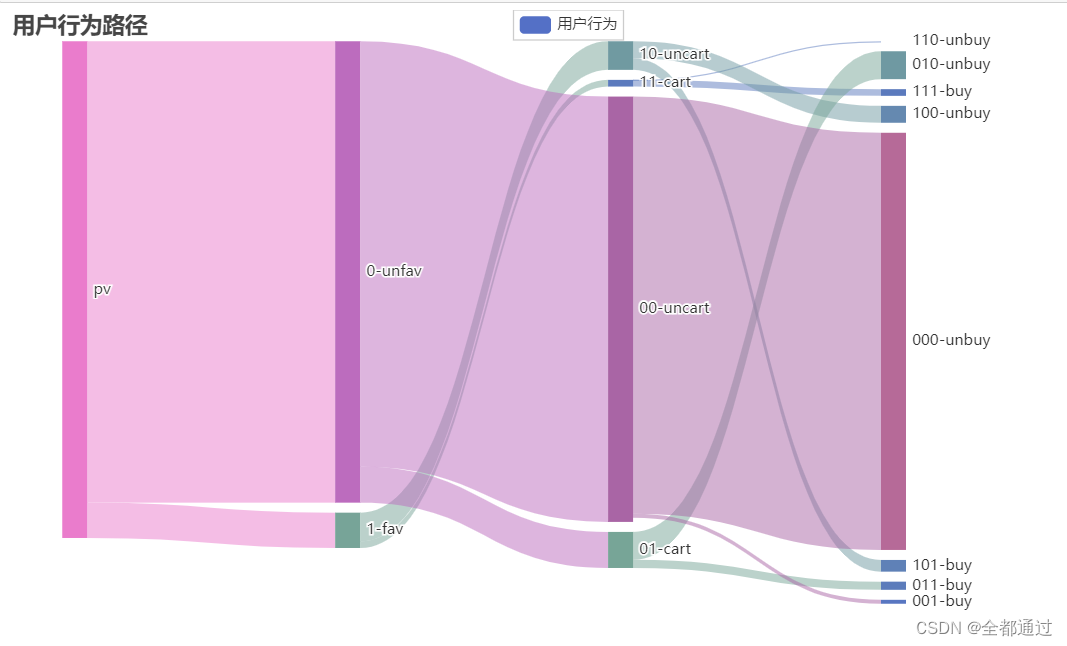
pv_unfav_uncart_unbuysangji_data=pd.DataFrame({'父类': ['pv', 'pv', '1-fav','1-fav','0-unfav','0-unfav','11-cart','11-cart','10-uncart','10-uncart','01-cart','01-cart','00-uncart','00-uncart'],
'子类': ['1-fav','0-unfav','11-cart' ,'10-uncart','01-cart','00-uncart','111-buy','110-unbuy','101-buy','100-unbuy','011-buy','010-unbuy','001-buy','000-unbuy'],
'数量': [204117, 2666487, 38710,165407,208467,2458020,38710,0,67623, 97784,47210,161257,22707,2410810]})
sangji_data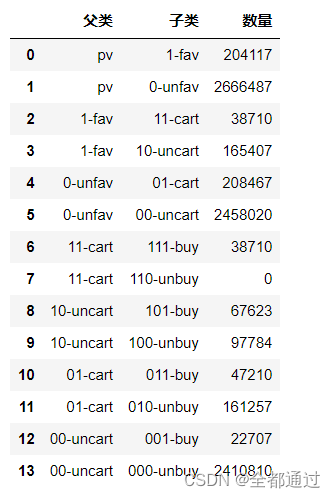
确定全部节点nodes
1、先找出全部的节点
所有的节点数据就是上面的父类和子类中去重后的元素,我们使用集合set进行去重,再转成列表
# 父类+子类中的数据,需要去重
sangji_data['父类'].tolist()
sangji_data['子类'].tolist()
# 将上面的数据相加并且去重:
nodes=list(set(sangji_data['父类'].tolist()+sangji_data['子类'].tolist()))
nodes
2、生成节点数据
# 节点列表数据: nodes_list
nodes_list=[]
for i in nodes:
dic={}
dic["name"]=i
nodes_list.append(dic)
nodes_list
生成链路数据
我们将导入的数据生成链路数据:每一行记录都是一个链路数据:
links_list=[]
for i in range(len(sangji_data)):
dic={}
dic['source']=sangji_data.iloc[i,0]#父类
dic['target']=sangji_data.iloc[i,1]#子类
dic['value']=int(sangji_data.iloc[i,2])#数据值:使用int函数直接强制转换
links_list.append(dic)
links_list
完成了桑葚图中节点数据和链路数据的生成,下面开始绘图
c = (
Sankey()
.add(
"用户行为",
nodes_list,
links_list,
linestyle_opt=opts.LineStyleOpts(opacity=0.5,curve=0.5, color="source"),
label_opts=opts.LabelOpts(position="right"),
)
.set_global_opts(title_opts=opts.TitleOpts(title="用户行为路径"))
)
c.render_notebook()
c.render("chart2.html")
display(IFrame(src="./chart2.html", width="100%", height="500px"))