Pandas学习笔记(三)处理丢失数据&导入导出数据
文章目录
前言
这一节主要介绍如何处理丢失数据以及导入导出数据的方法
一、处理丢失数据
1.导入库&建含有NaN数据表
import numpy as np
import pandas as pd
dates = pd.date_range("20210124", periods=6)
df = pd.DataFrame(np.arange(24).reshape((6, 4)), index=dates, columns=["A", "B", "C", "D"])
df.iloc[0, 1] = np.nan
df.iloc[1, 2] = np.nan
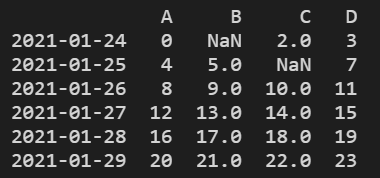
print(df)
结果显示:
2.删除有NaN数据的行&列
1)存在NaN就删除行
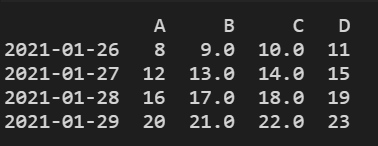
print(df.dropna(
axis=0, # 0对行进行操作 1对列进行操作
how='any' # 'any':只要存在NaN就丢掉(默认方法);'all':必须全部是NaN才drop
))
结果显示:
2)存在NaN就删除列
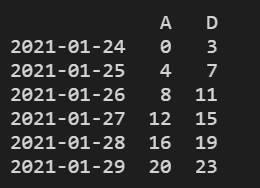
print(df.dropna(axis=1, how="any"))
结果显示:
3)全为NaN才删除
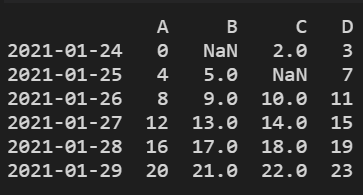
print(df.dropna(axis=0, how="all"))
结果显示:
3.替换NaN的值
print(df.fillna(value=0))
# 替换NaN值为0
结果显示:

4.判断NaN数据
1)判断表中各值
print(df.isnull()) # 缺失数据返回True
# print(df.isna()) 在pandas中这两个方法等价
结果显示:
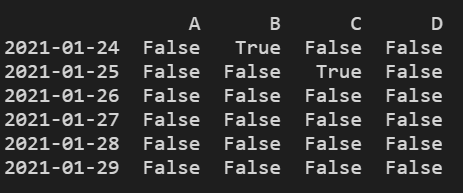
2)判断某列存在NaN
# 检测某列是否有缺失数据NaN
print(df.isnull().any())
结果显示:

3)判断整个表的情况
print(np.any(df.isnull()) == True)
# 至少有个数据等于null返回True
结果显示:

二、使用步骤
1.引入库
import pandas as pd
2.导入数据
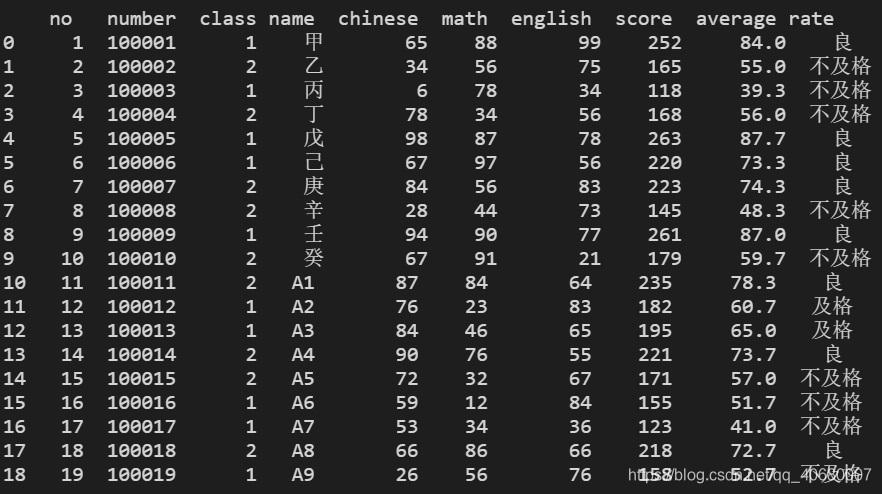
data = pd.read_csv('student.csv') # 文件目录
# 当前文件夹下student.csv文件
print(data) # 会自动增加从0开始的索引
结果显示:
类似的导入方法如:
EXCEL:read_excel()
SQL:read_sql()
PICKLE:read_pickle()
5.查看数据
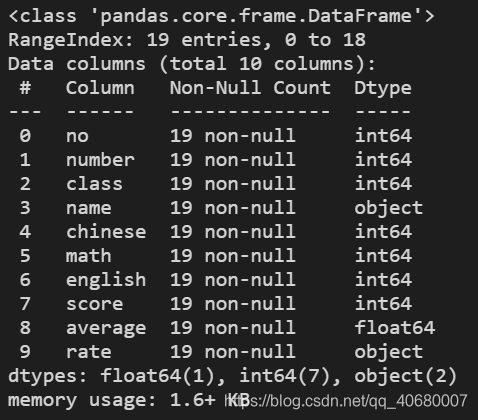
1)info()方法 查看详细信息
data.info()
结果显示:
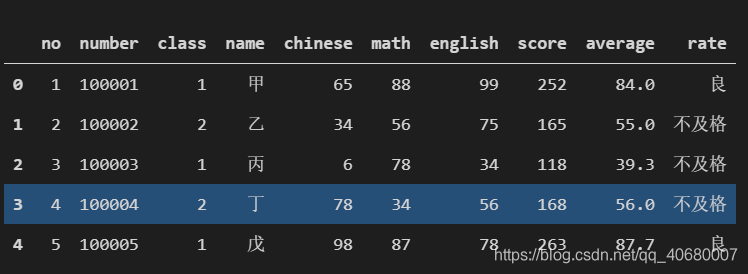
2)head()方法 前几个数据
data.head() # 默认前五个数据
结果显示:
data.head(2)
结果显示:

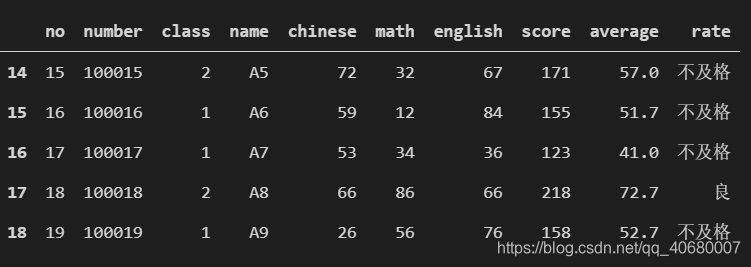
3)tail()方法 后几个数据
data.tail() # 默认后5个数据
结果显示:
4.导出数据
data.to_pickle("student.pickle") # 导出存储成student.pickle
类似的导入方法如:
EXCEL:to_excel()
SQL:to_sql()
CSV:to_csv()
下一节介绍concat&append&merge三种合并方法