es 查询案例分析
场景描述:
有这样一种场景,比如我们想搜索
title:Brown fox
body:Brown fox
文章索引中有两条数据,兔子和狐狸两条数据
PUT /blogs/_bulk
{"index": {"_id": 1}}
{"title": "Quick brown rabbits", "body": "Brown rabbits are commonly seen."}
{"index": {"_id": 2}}
{"title": "Keeping pets healthy", "body": "My quick brown fox eats rabbits on a regular basis."}结果肯定是想要数据二,狐狸优先展示
但是,然后搜索的时候,会对搜素词 Brown fox 进行分词,导致数据一优先级更高
可以看下结果:
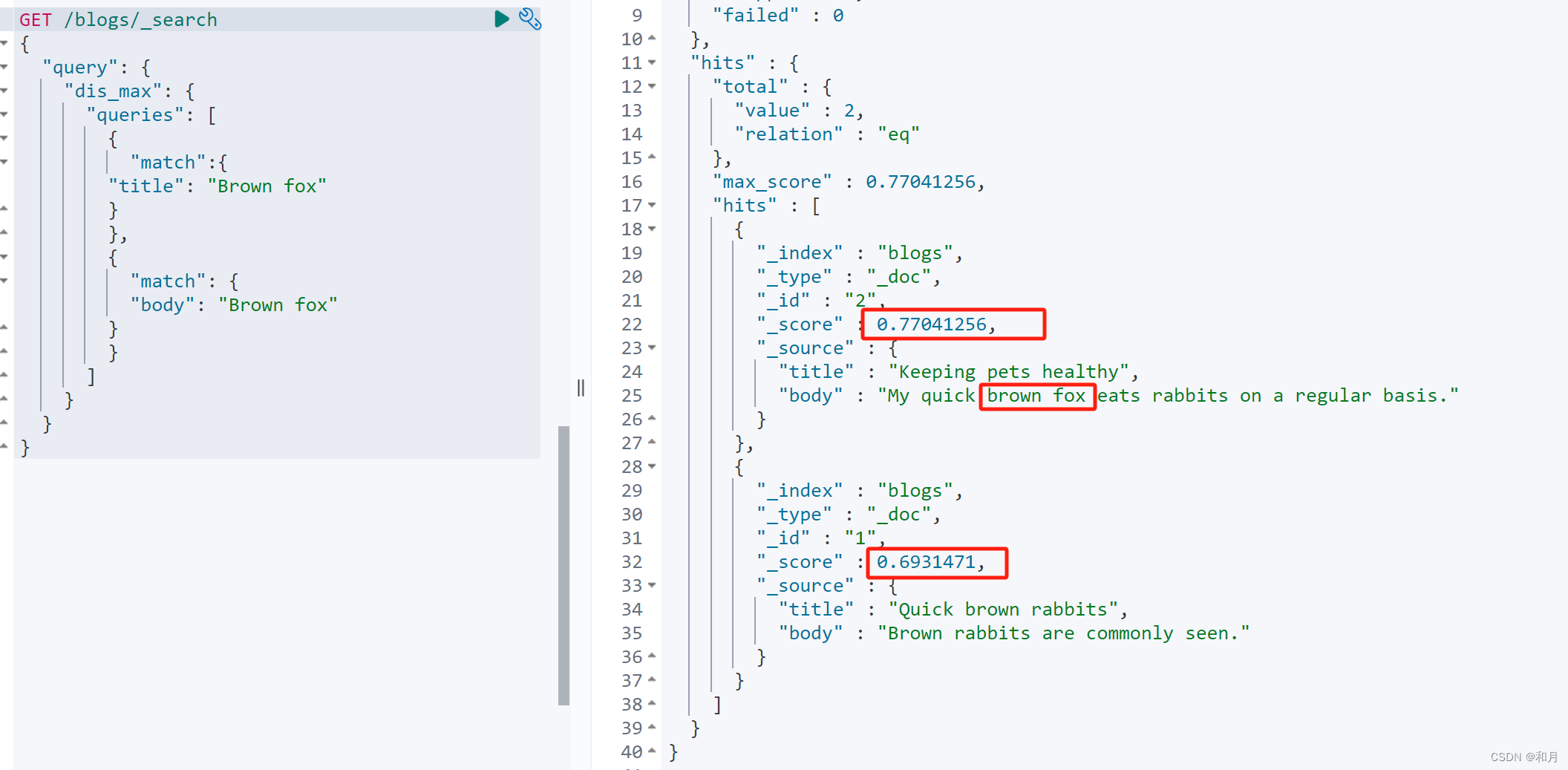
优先展示的是兔子,有 0.8 的算分,而狐狸只有 0.7 的算分

GET /blogs/_search
{
"query": {
"bool": {
"should": [
{"match": {
"title": "Brown fox"
}},
{"match": {
"body": "Brown fox"
}}
]
}
}
}原因分析:
bool should的算法过程:
- 查询should语句中的两个查询
- 加和两个查询的评分
- 乘以匹配语句的总数
- 除以所有语句的总数
上述例子中,title和body属于竞争关系,不应该将分数简单叠加,而是应该找到单个最佳匹配的字段的评分。
解决方案
方式一 dis_max:
可以采用 dis max query
实例如下:可以看到此时达到了我们想要的结果
GET /blogs/_search
{
"query": {
"dis_max": {
"queries": [
{
"match":{
"title": "Brown fox"
}
},
{
"match": {
"body": "Brown fox"
}
}
]
}
}
}这里简单解释一下这两种命令产生的原因:
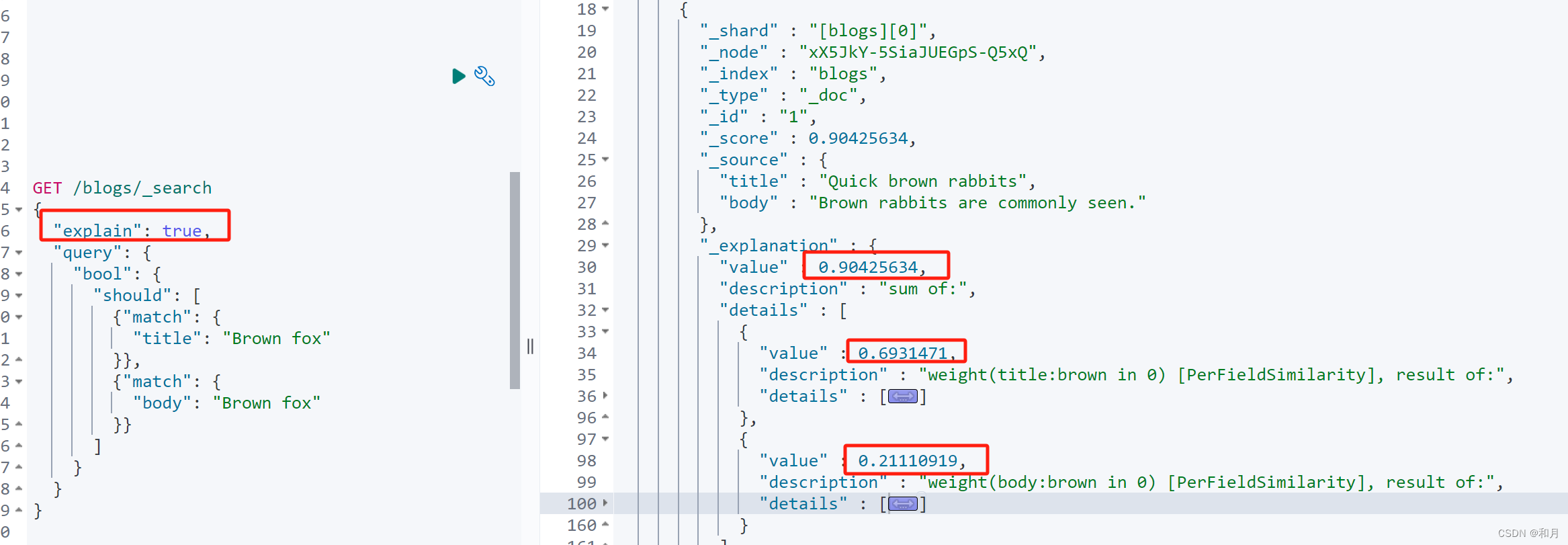
类似 MySQL 可以使用 explain 关键字分析指令
先分析 bool should
如下看兔子这条数据,总算分是两个字段的算分之和
GET /blogs/_search
{
"explain": true,
"query": {
"bool": {
"should": [
{"match": {
"title": "Brown fox"
}},
{"match": {
"body": "Brown fox"
}}
]
}
}
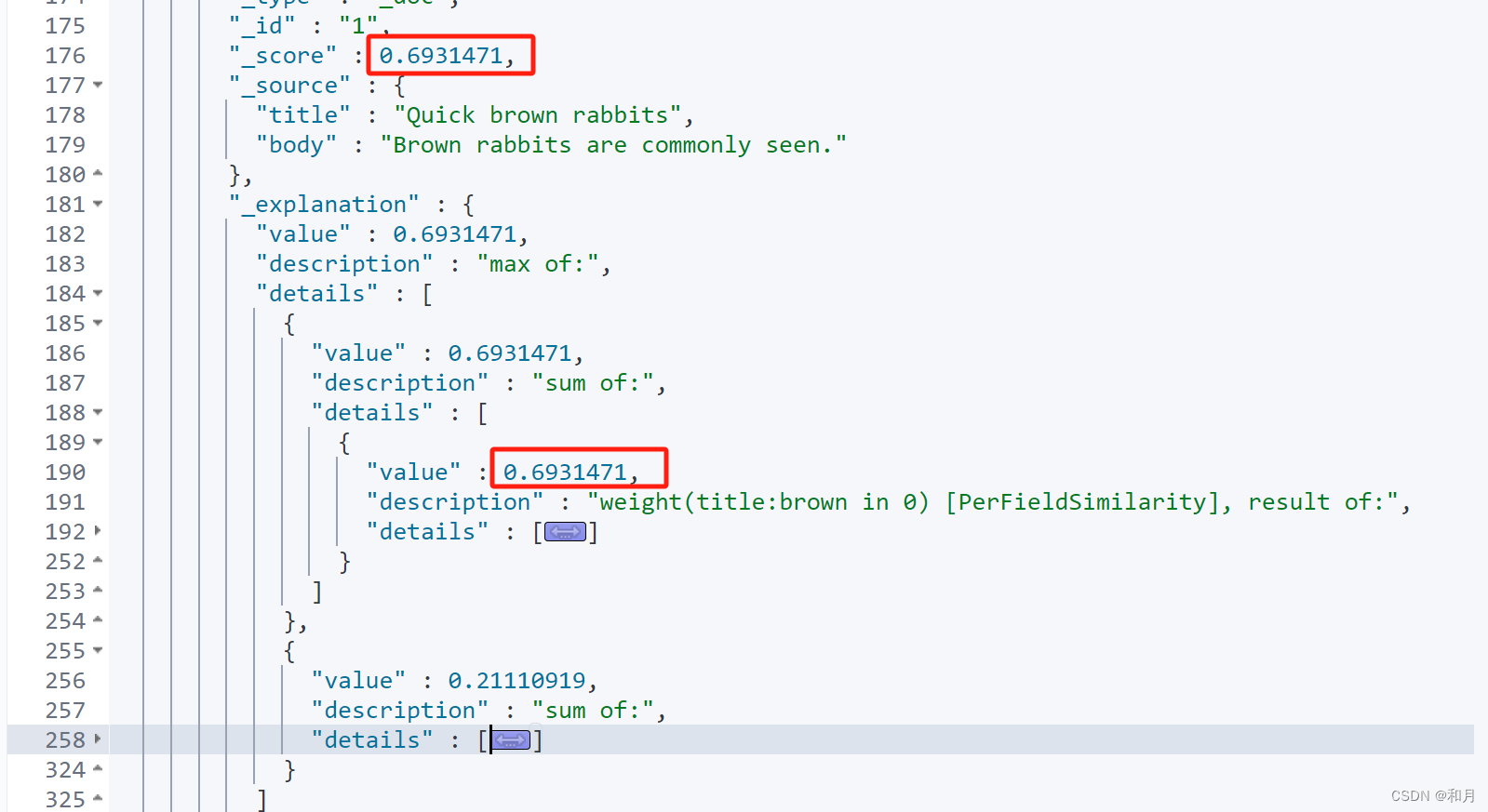
}再来看 dis_max
如下同样看兔子的这条数据,可以看到,此时这条数据的总算分是其中一个字段的最大值
GET /blogs/_search
{
"explain": true,
"query": {
"dis_max": {
"queries": [
{
"match":{
"title": "Brown fox"
}
},
{
"match": {
"body": "Brown fox"
}
}
]
}
}
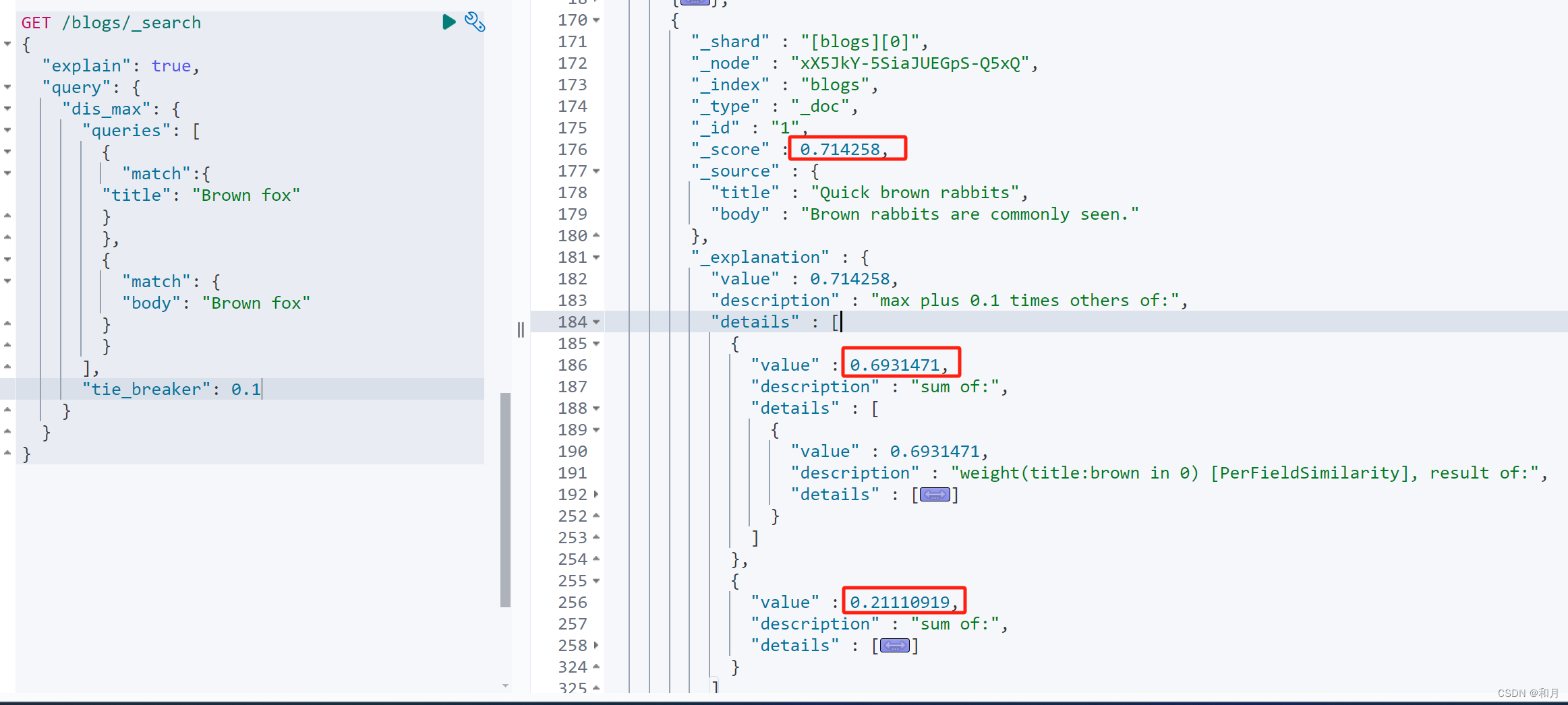
}dis_max 还可以使用 tie_breaker 控制非最大值字段的算分
tier breaker是一个介于0-1之间的浮点数。0代表使用最佳匹配;1代表所有语句同等重要。
- 获得最佳匹配语句的评分_score 。
- 将其他匹配语句的评分与tie_breaker相乘
- 对以上评分求和并规范化
最终得分=最佳匹配字段+其他匹配字段*tie_breaker
此时可以看到
兔子这条数据的算分 0.714258 = 0.6931471 + 0.21110919 * 0.1
0.1 就是 tier breaker 的数值
方式二 multi_mahch :
还记得之前篇章里面学到的 multi_match 多字段查询么
看到下面结果中的算分是不是有点似曾相识,
没错,multi_mahch 默认的查询方式就是两字段取最大值的方式
算分方式和上面一致,可以自行使用 explain 进行尝试
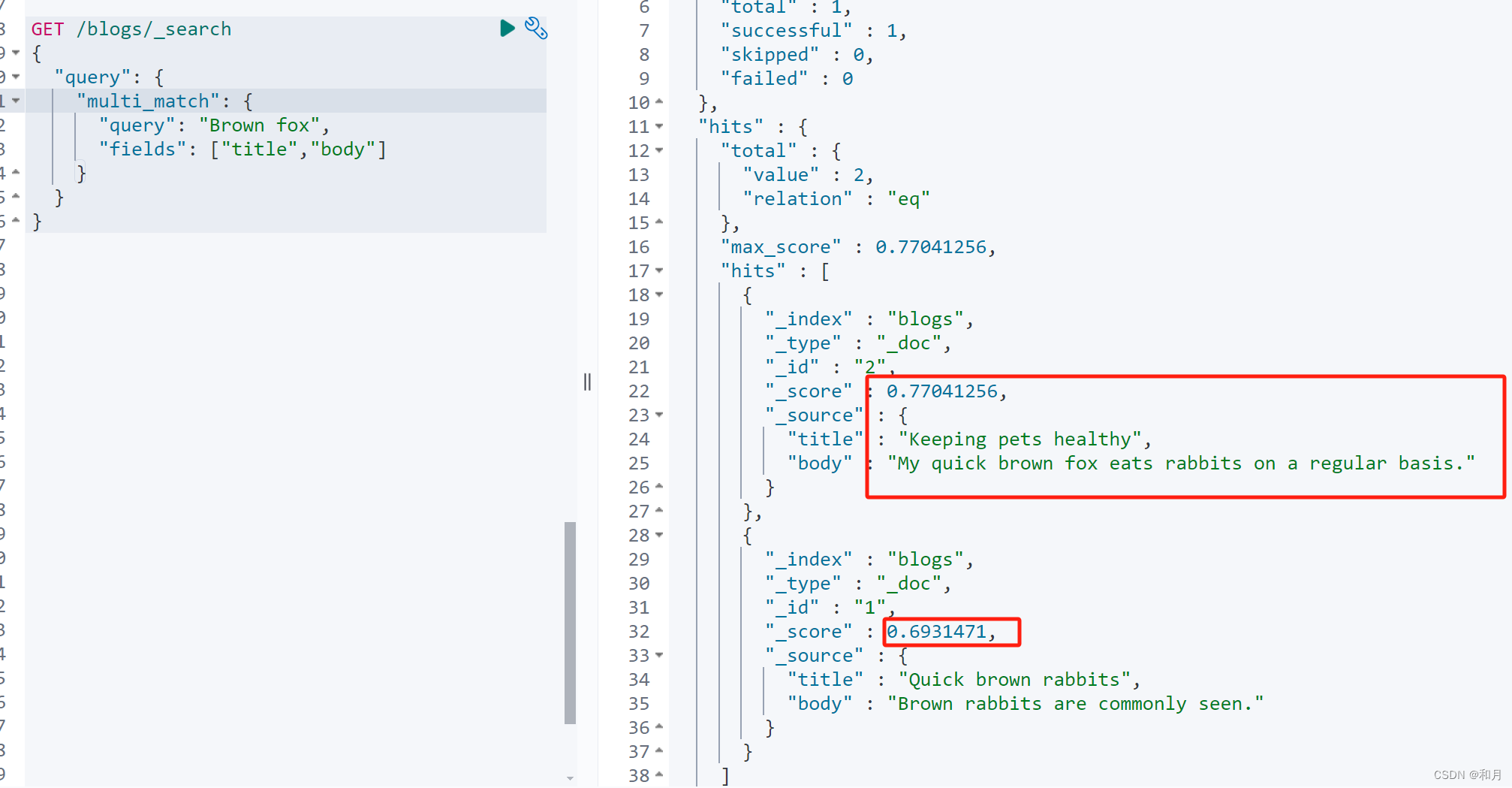
GET /blogs/_search
{
"query": {
"multi_match": {
"query": "Brown fox",
"fields": ["title","body"]
}
}
}同样的 multi_mahch 也可以使用 tie_breaker 控制最佳匹配之外字段的算分
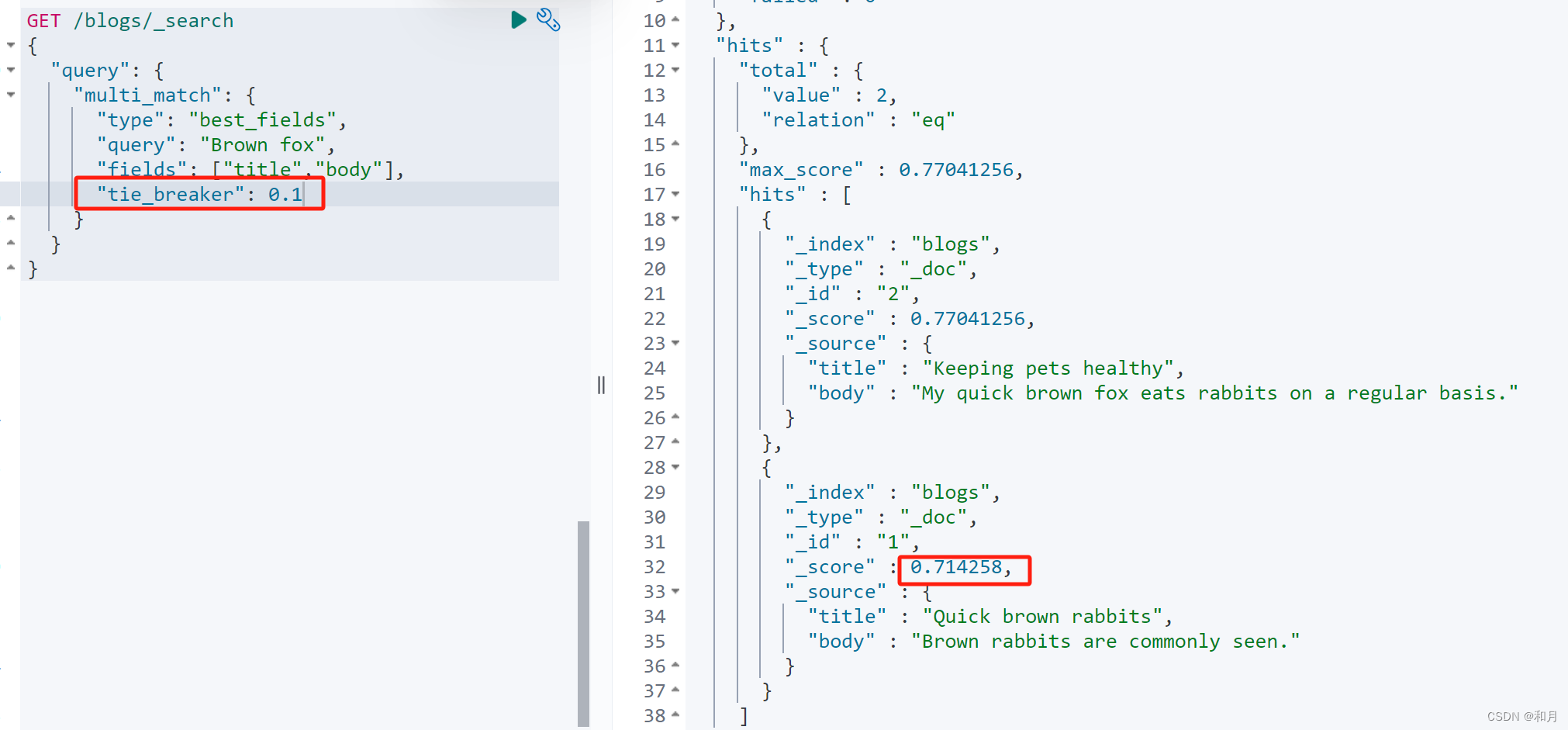
GET /blogs/_search
{
"query": {
"multi_match": {
"type": "best_fields",
"query": "Brown fox",
"fields": ["title","body"],
"tie_breaker": 0.1
}
}
}multi_mahch 有三种方式
best_fields
这种方式就是默认的方式,就不再演示了
GET /blogs/_search
{
"query": {
"multi_match": {
"type": "best_fields",
"query": "Brown fox",
"fields": ["title","body"]
}
}
}most_fields
这种方式就是上面 bool should 求和的方式
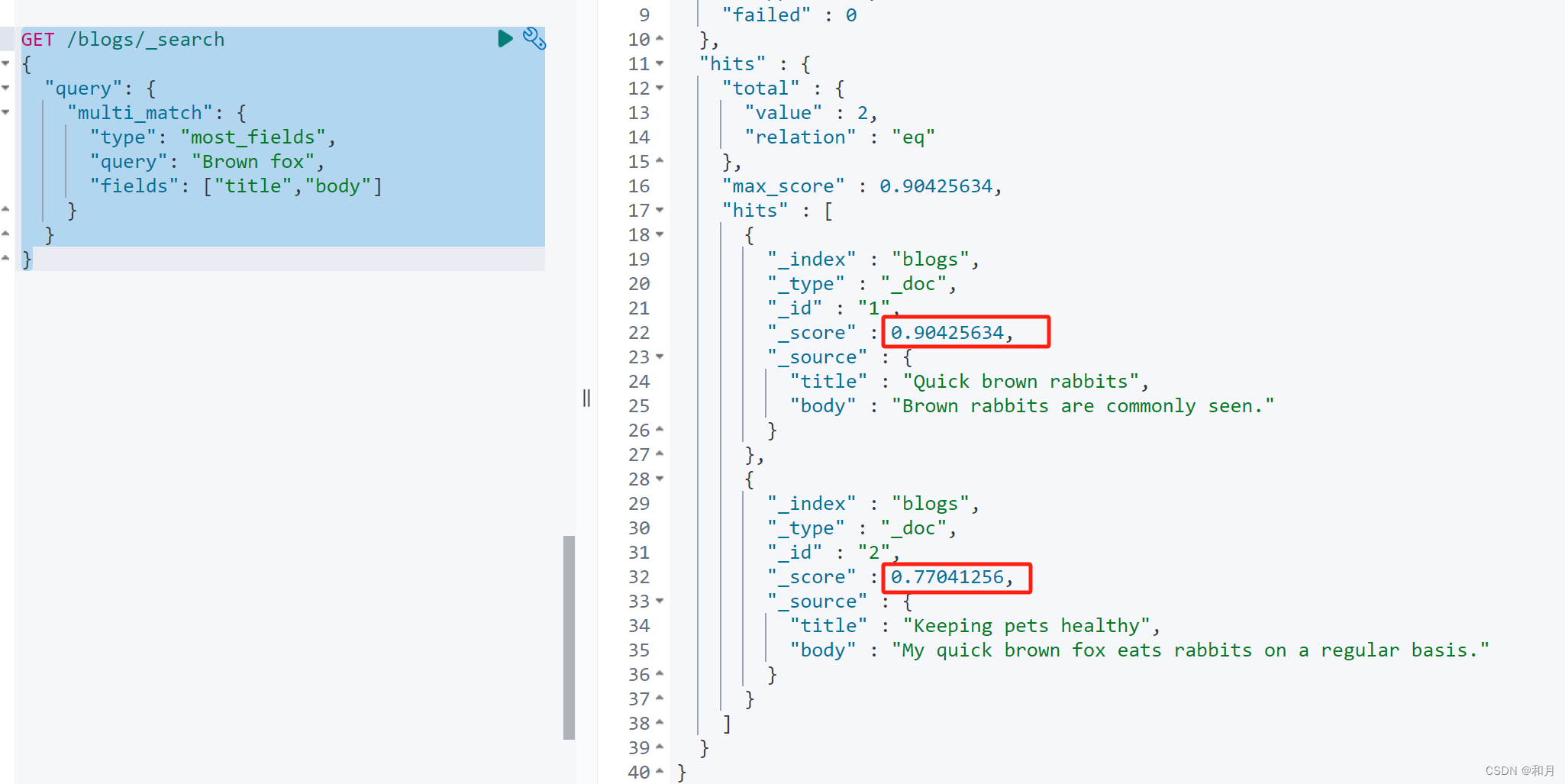
GET /blogs/_search
{
"query": {
"multi_match": {
"type": "most_fields",
"query": "Brown fox",
"fields": ["title","body"]
}
}
}cross_fields
跨字段查询
搜索内容在多个字段中都显示,类似 bool+dis_max 组合
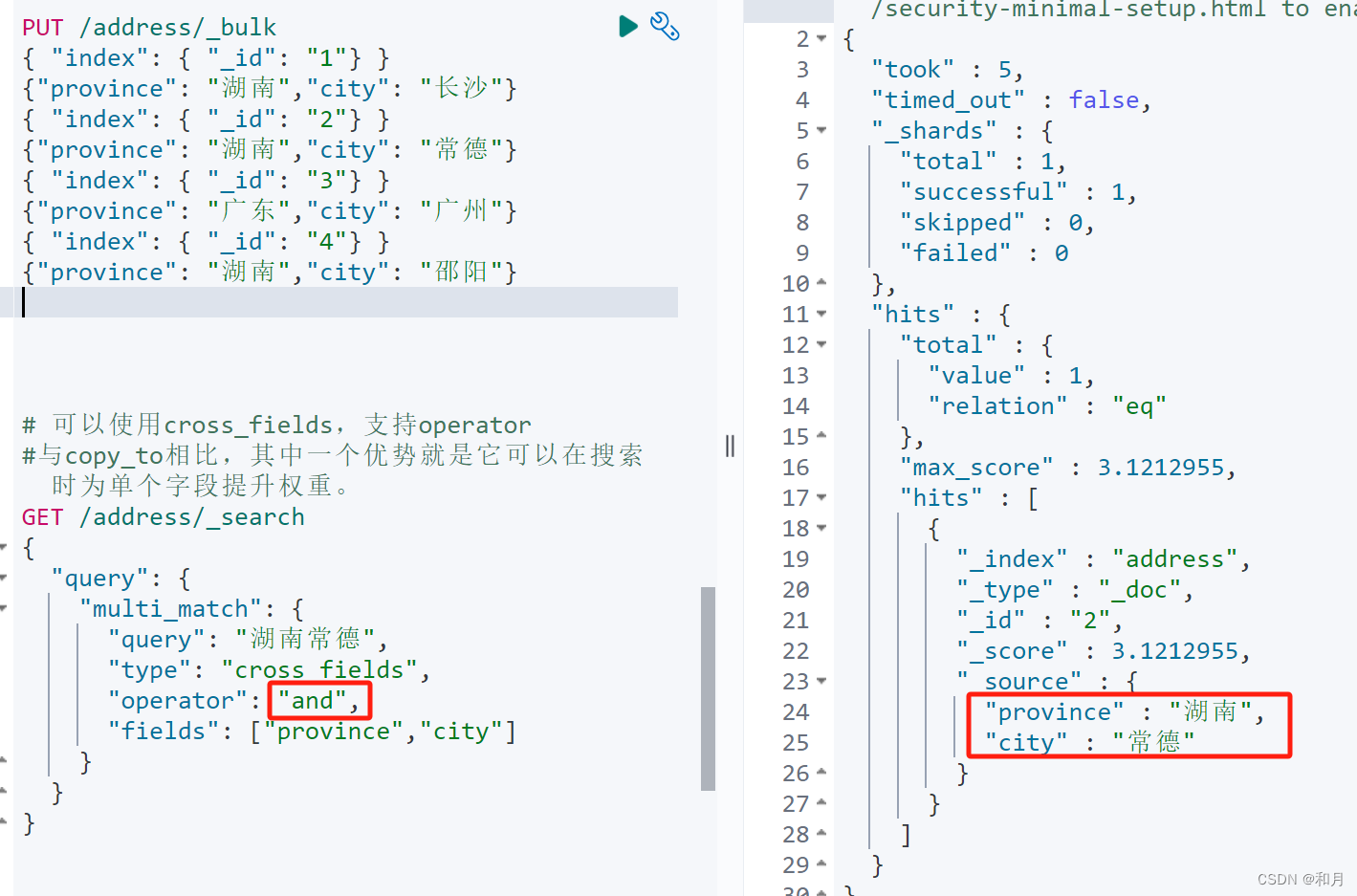
PUT /address/_bulk
{ "index": { "_id": "1"} }
{"province": "湖南","city": "长沙"}
{ "index": { "_id": "2"} }
{"province": "湖南","city": "常德"}
{ "index": { "_id": "3"} }
{"province": "广东","city": "广州"}
{ "index": { "_id": "4"} }
{"province": "湖南","city": "邵阳"}
# 可以使用cross_fields,支持operator
#与copy_to相比,其中一个优势就是它可以在搜索时为单个字段提升权重。
GET /address/_search
{
"query": {
"multi_match": {
"query": "湖南常德",
"type": "cross_fields",
"operator": "and",
"fields": ["province","city"]
}
}
}这里跨字段还有另一种方式:
可以用copy...to 解决,但是需要额外的存储空间

DELETE /address
# copy_to参数允许将多个字段的值复制到组字段中,然后可以将其作为单个字段进行查询
PUT /address
{
"mappings" : {
"properties" : {
"province" : {
"type" : "keyword",
"copy_to": "full_address"
},
"city" : {
"type" : "text",
"copy_to": "full_address"
}
}
},
"settings" : {
"index" : {
"analysis.analyzer.default.type": "ik_max_word"
}
}
}
PUT /address/_bulk
{ "index": { "_id": "1"} }
{"province": "湖南","city": "长沙"}
{ "index": { "_id": "2"} }
{"province": "湖南","city": "常德"}
{ "index": { "_id": "3"} }
{"province": "广东","city": "广州"}
{ "index": { "_id": "4"} }
{"province": "湖南","city": "邵阳"}
GET /address/_search
{
"query": {
"match": {
"full_address": {
"query": "湖南常德",
"operator": "and"
}
}
}
}本次先分享到这里,感谢各位观看!!!感兴趣的小伙伴可以关注收藏,持续更新中~~~