NDT点云配准
NDT算法介绍
NDT正态分布点云算法,即Normal Distribution Transform,是将参考点云转换成多维变量的正态分布来进行配准。如果变换参数能够使得两幅激光数据匹配得很好,那么变换点在参考点云中对应的概率密度将会很大。因此,要使得两幅激光点云数据匹配最优,只需用优化方法迭代计算使得概率密度之和最大的转换矩阵。
现实中,LiDAR扫描得到的点云可能和参考点云(如高精地图点云)存在细微的区别,此偏差可能来自于测量误差,也有可能是“场景”发生了一下变化(比如说行人,车辆)。NDT配准可以忽略细微变化,因此可用于解决这些细微的偏差问题。同时,NDT相对与ICP,它耗时稳定,跟初值相关不大,初值误差大时,也能很好得纠正过来。计算正态分布是个一次性的工作,因为其在配准中不利用对应点的特征计算和匹配,不需要消耗大量代价计算最邻近点,所以时间较快。
NDT算法流程

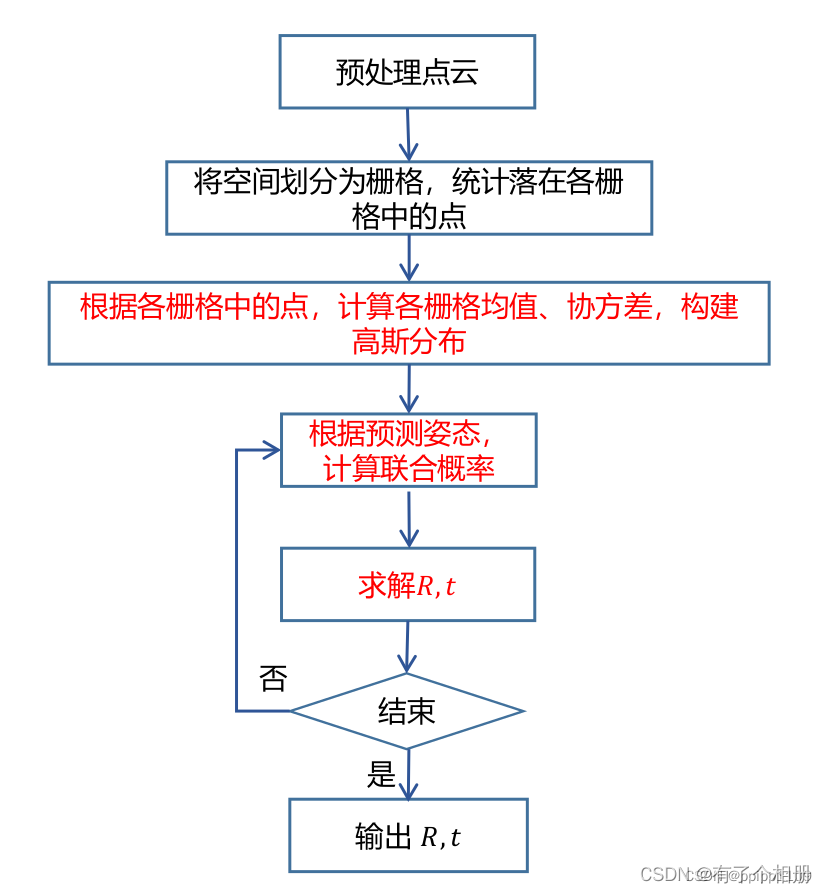
NDT公式推导
NDT算法的基本思想是先根据参考数据(reference scan)来构建多维变量的正态分布,如果变换参数能使得两幅激光数据匹配的很好,那么变换点在参考系中的概率密度将会很大。因此,可以考虑用优化的方法求出使得概率密度之和最大的变换参数,此时两幅激光点云数据将匹配的最好。



NDT缺点:格子参数最重要,太大导致精度不高,太小导致内存过高,并且只有两幅图像相差不大的情况才能匹配。
改进:
- 八叉树建立,格子有大有小 ,迭代,每次使用更精细的格子
- K聚类,有多少个类就有多少个cell,格子大小不一
- 三线插值 平滑相邻的格子cell导致的不连续,提高精度
NDT代码实战
#ifdef USE_FAST_PCL
#include <fast_pcl/registration/ndt.h>
#else
#include <pcl/registration/ndt.h>
#endif
#ifdef CUDA_FOUND
#include <fast_pcl/ndt_gpu/NormalDistributionsTransform.h>
#endif
...........核心算法代码,构建地图使用ndt算法
static std::shared_ptr<gpu::GNormalDistributionsTransform> new_gpu_ndt_ptr = std::make_shared<gpu::GNormalDistributionsTransform>();//创建NDT转换矩阵类
new_gpu_ndt_ptr->setResolution(ndt_res);//网格大小设置
new_gpu_ndt_ptr->setInputTarget(map_ptr);//参考帧
new_gpu_ndt_ptr->setMaximumIterations(max_iter);//迭代最大次数
new_gpu_ndt_ptr->setStepSize(step_size);//牛顿法优化的最大步长
new_gpu_ndt_ptr->setTransformationEpsilon(trans_eps);//连续变换之间允许的最大差值
pcl::PointCloud<pcl::PointXYZ>::Ptr dummy_scan_ptr(new pcl::PointCloud<pcl::PointXYZ>());
pcl::PointXYZ dummy_point;
dummy_scan_ptr->push_back(dummy_point);//构建地图map
new_gpu_ndt_ptr->setInputSource(dummy_scan_ptr);//当前帧
new_ndt.omp_align(*output_cloud, Eigen::Matrix4f::Identity());
fitness_score = ndt.omp_getFitnessScore();
t = ndt.getFinalTransformation();
// Update localizer_pose
localizer_pose.x = t(0, 3);
localizer_pose.y = t(1, 3);
localizer_pose.z = t(2, 3);
. .........
-------------使用ndt算法与地图参考帧进行匹配---------------举一个列子gpu_ndt_ptr->setInputSource(),其他和地图一致
#ifdef CUDA_FOUND//在代码中标记可以用GPU并行加速
if (_use_gpu == true)
{
gpu_ndt_ptr->setInputSource(filtered_scan_ptr);//参考点云
}
else
{
#endif
if (_use_fast_pcl)
{
cpu_ndt.setInputSource(filtered_scan_ptr);
}
else
{
ndt.setInputSource(filtered_scan_ptr);
}
#ifdef CUDA_FOUND
}
#endif
//NDT默认值设置
static int max_iter = 30; // 最大迭代次数
static float ndt_res = 1.0; // 分辨率1m
static double step_size = 0.1; // 步长0.1m
static double trans_eps = 0.01; // 变换矩阵差值
其中 ndt.setTransformationEpsilon() 即设置变换的 ϵ(两个连续变换之间允许的最大差值),这是判断我们的优化过程是否已经收敛到最终解的阈值。ndt.setStepSize(0.1) 即设置牛顿法优化的最大步长。ndt.setResolution(1.0) 即设置网格化时立方体的边长,网格大小设置在NDT中非常重要,太大会导致精度不高,太小导致内存过高,并且只有两幅点云相差不大的情况才能匹配。ndt.setMaximumIterations(30) 即优化的迭代次数,我们这里设置为35次,即当迭代次数达到35次或者收敛到阈值时,停止优化。
由于NDT算法不需要匹配各个点计算速度较ICP快,官方建议定位模块使用NDT算法,然后通过使用CUDA实现的 fast_pcl package实现了对NDT优化过程的并行加速。
参考链接:
NDT点云配准算法_海清河宴的博客-CSDN博客_ndt配准