【自然语言处理六-最重要的模型-transformer-下】
自然语言处理六-最重要的模型-transformer-下
transformer decoder
今天接上一篇文章讲的encoder 自然语言处理六-最重要的模型-transformer-上,继续讲transformer的decoder,也就是下图中的红框部分
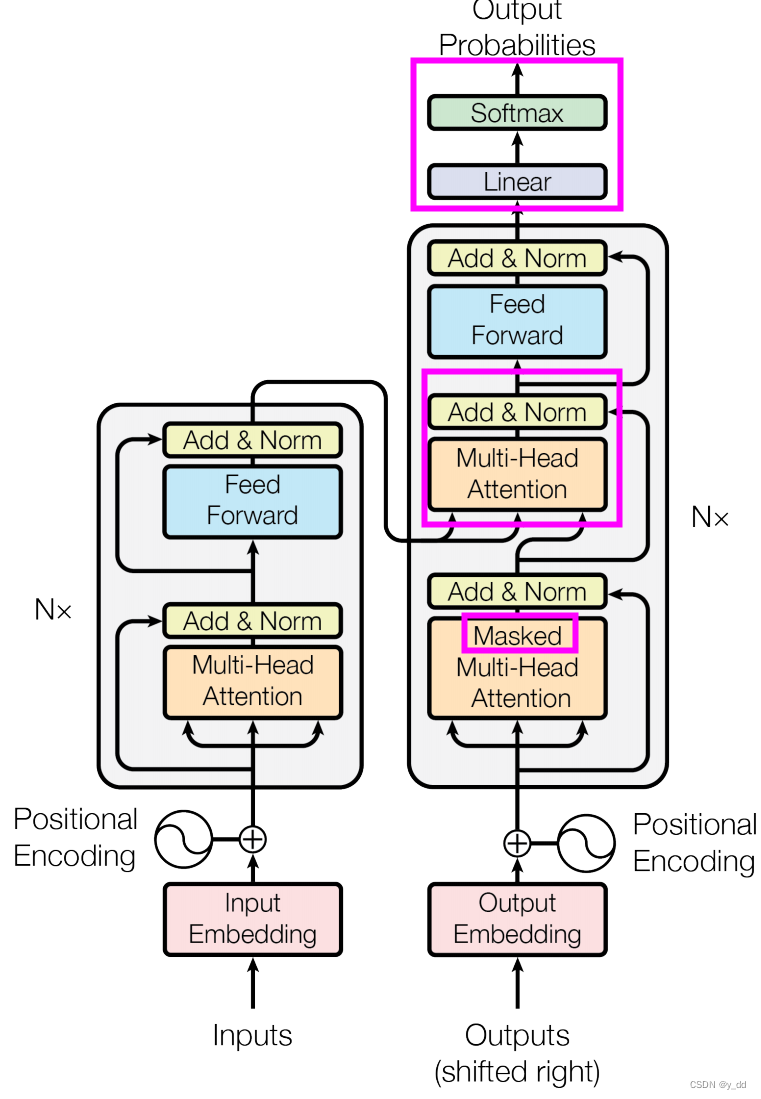
可以看出encoder和decoder部分去掉粉红色框的部分,结构几乎一样,下面分三部分介绍不同点
Masked multi-head attention
decoder的注意力是masked的注意力,什么是masked的attention呢? 下面是self attention:
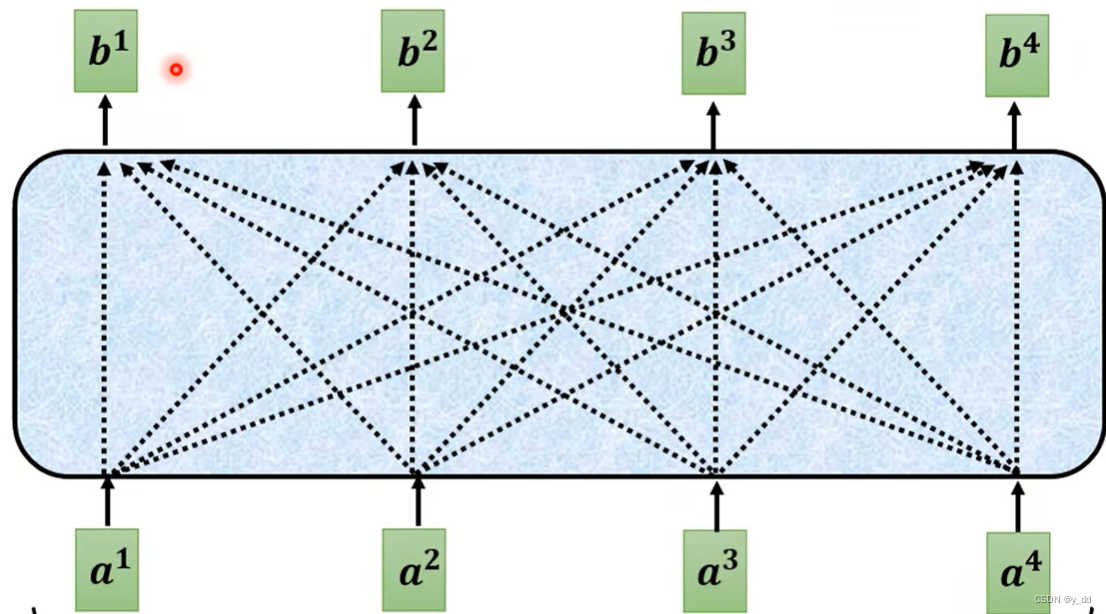
需要注意的是:
selfattention中注意力bi的输出是需要关注所有的输入,也就是下面那一整排向量
但如果是masked self-attention,注意力是这样子的:
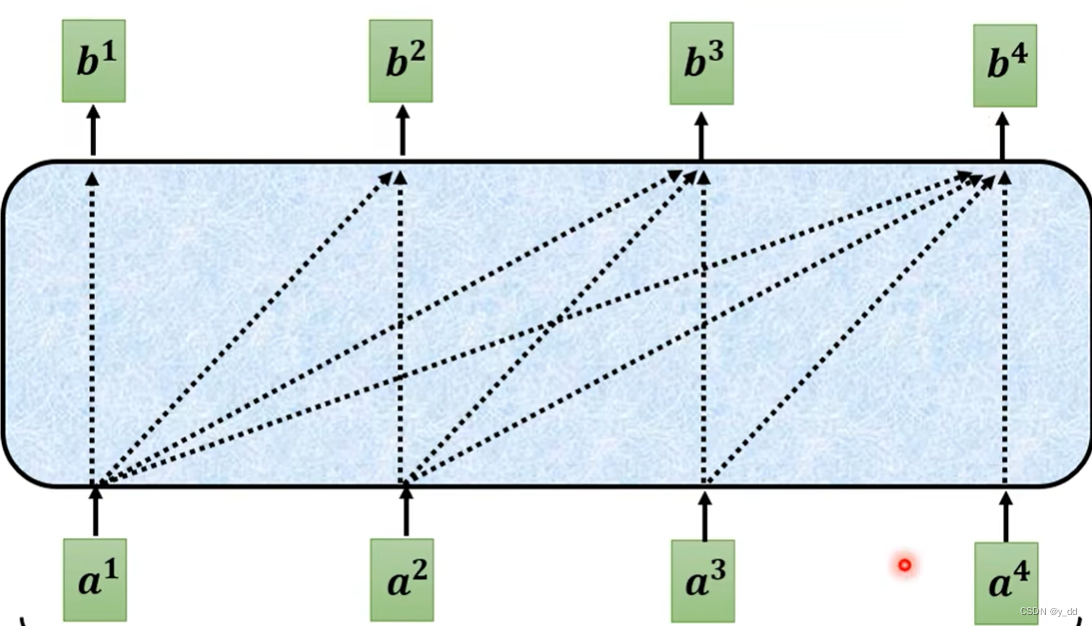
这个与普通的self attention的区别:
bi只能关注a0到ai的输入,不能包括ai+1后的输入,那么为什么需要masked attention呢?
用下面的语音辨识,举个例子说明一下:
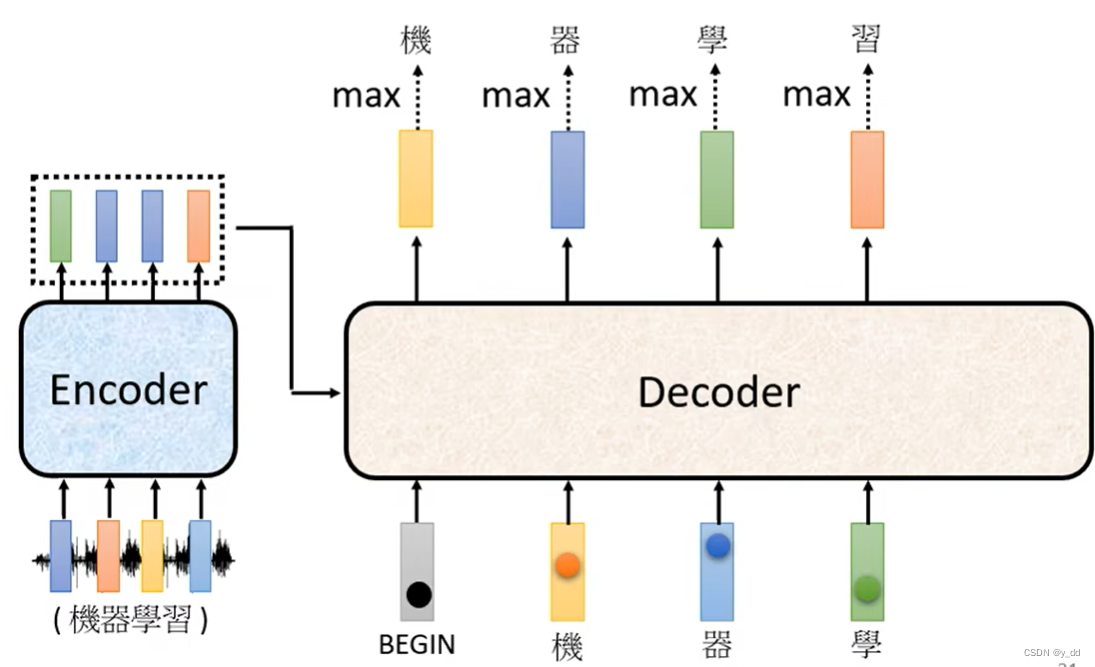
encoder是把一次性把所有的输入都输入到模型,计算注意力分数,但是对于decoder来说,它是一个字一个字产生:
比如decoder计算第一个位置应该输入什么的时候,它并不知道下一个的输入是“機”,所以必须遮蔽右边的输入,因此又叫masked self-attention。
decoder中下一次的输入是在本次输入BEGIN计算出来以后“機”这个字,作为下一次的输入。
需要说明的一点是:
实际上我们在训练的时候是知道每个输入的,因为这些信息是训练资料提供的,但真正测试使用的时候,是无法知晓的。
encoder和decoder的连接部分-cross attention
下面是encoder和decoder的互连部分:
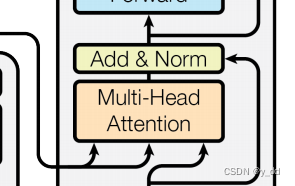
相同的Add和Norm不再赘述,下面是attention部分,这个attention部分的输入分为3部分:
有两个箭头来自encoder的输出(这部分用作self attention中的k和v)
一个箭头来自decoder上一层的输出(这一部分用作q)
所以计算attention的流程是这样的:
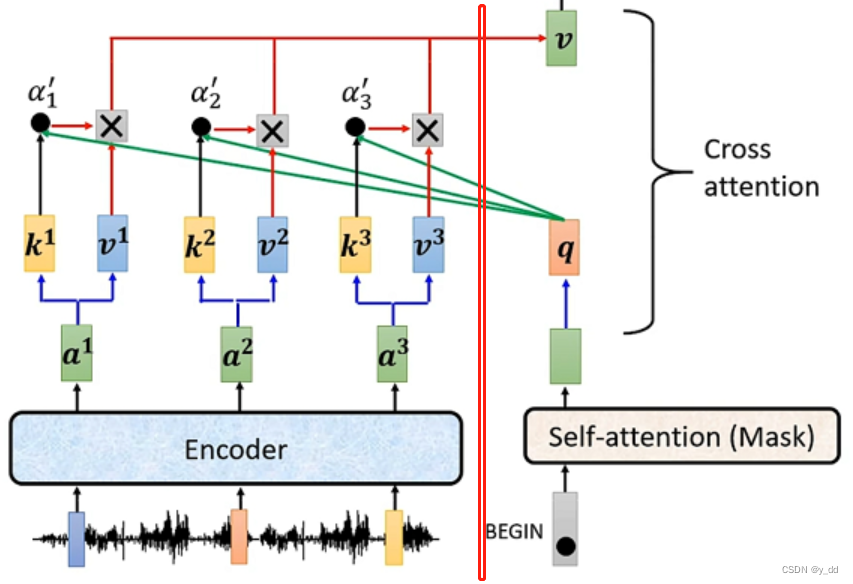
左边这边encoder的输出,用于生成k v,右边decoder上一层的输出,用作q
按照普通的attention计算注意力分数后,最终生成v
然后进行add 残差连接和norm 归一化后,作为这一层的输出
然后继续输入到FC(feed forward netword)中
除了上面几部分不同,还需要关注的decoder如何处理输出。
decoder的输出
decoder输出的序列长度应该是多长呢?
比还是以语音辨识为例,输入一段语音究竟应该输出多少个字符根本无法确认,那么decoder究竟是怎么确定输出的长度的呢?有两种做法AT和NAT (AT是Autoregresssive的缩写)
AT(Autoregresssive)
这种做法就是让机器自己决定要输多少长度的sequence,当模型输出END的时候,就认为decoder输出完毕
NAT
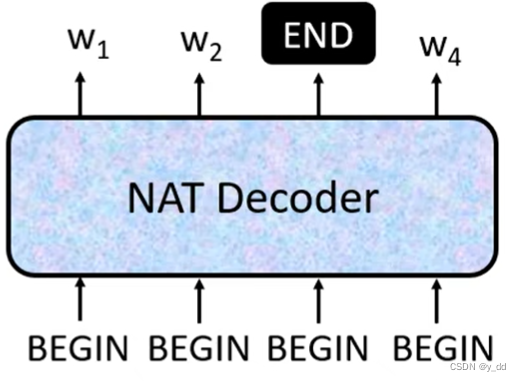
这种情况下有几种方法确定decoder输出的长度:
1.添加一个网络来预测输出的长度
2.输入一排BEGIN向量,输出一排向量即可,最终的输出截止到输出为END
通常情况下,我们都是用AT,效果更好一些