BOA-SVM算法学习
使用BOA算法来找到SVM的最优超参数
这段代码使用了蝴蝶优化算法(BOA)来优化支持向量机(SVM)的超参数(C和gamma),以提高SVM在分类问题上的性能。以下是主要步骤和作用:
-
定义优化函数
fun(X):fun函数包括了SVM分类器的训练和性能评估。- SVM的超参数C和gamma由优化算法进行调整。
- 优化的目标是最小化错误率,即最大化准确率。
-
数据预处理:
- 通过
ovs_preprocess函数对数据集进行预处理,包括标准化、划分训练集、验证集和测试集等。
- 通过
-
使用蝴蝶优化算法进行超参数优化:
- 设置蝴蝶算法的参数,如种群数量、最大迭代次数、维度、上下界等。
- 调用
BOA.BOA函数进行蝴蝶算法的优化,得到最优适应度值和最优解。
-
训练SVM分类器:
- 利用蝴蝶算法得到的最优超参数,实例化SVM分类器,并使用训练数据进行训练。
-
性能评估:
- 使用训练好的SVM分类器对训练集和测试集进行预测,并计算准确率。
-
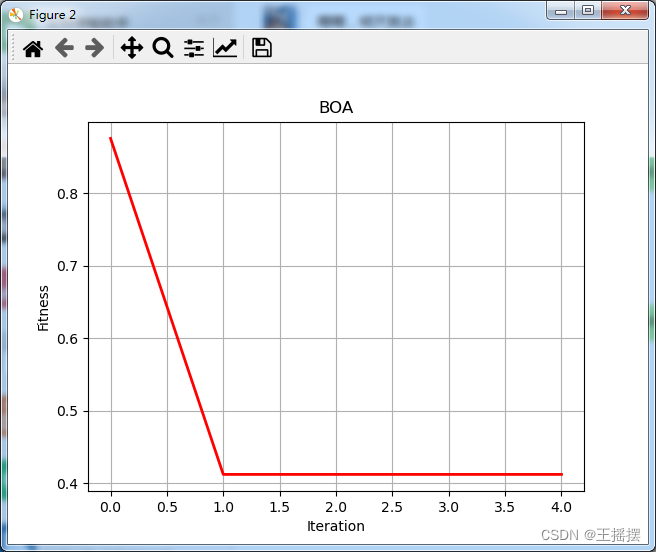
绘制适应度曲线:
- 将蝴蝶算法的适应度曲线绘制出来,以观察算法在迭代过程中的性能变化。
总体而言,这段代码的主要作用是利用蝴蝶优化算法来寻找最优的SVM超参数,以提高在给定数据集上的分类性能。
学习测试代码
import warnings
import BOA_SVM.BOA as BOA
import numpy as np
from matplotlib import pyplot as plt
from sklearn import svm
from sklearn.metrics import accuracy_score
from OriginalVibrationSignal import ovs_preprocess
warnings.filterwarnings("ignore")
'''优化函数
使用了蝴蝶优化算法(BOA)来优化支持向量机(SVM)的超参数(C和gamma),以提高SVM在分类问题上的性能
'''
def fun(X):
classifier = svm.SVC(C=X[0], kernel='rbf', gamma=X[1])
classifier.fit(x_train, y_train)
tes_label = classifier.predict(x_test) # 测试集的预测标签
train_labelout = classifier.predict(x_train) # 测试集的预测标签
output = 2 - accuracy_score(y_test, tes_label) - accuracy_score(y_train, train_labelout) # 计算错误率,如果错误率越小,结果越优
return output
'''
=================================读取数据集,进行数据预处理操作====================================================
'''
num_classes = 10 # 样本类别
length = 784 # 样本长度
number = 200 # 每类样本的数量
normal = True # 是否标准化
rate = [0.5, 0.25, 0.25] # 测试集验证集划分比例
path = r'data/0HP'
# 调用刚才的预处理函数,直接一步到位获取所有数据集
x_train, y_train, x_valid, y_valid, x_test, y_test = ovs_preprocess.prepro(
d_path=path,
length=length,
number=number,
normal=normal,
rate=rate,
enc=False, enc_step=28)
x_train = np.array(x_train)
y_train = np.array(y_train)
x_valid = np.array(x_valid)
y_valid = np.array(y_valid)
x_test = np.array(x_test)
y_test = np.array(y_test)
'''
=================================蝴蝶优化算法的使用,用来获取SVM的最优超参数C和gamma====================================================
'''
# 设置蝴蝶参数
pop = 20 # 种群数量
MaxIter = 5 # 最大迭代次数
dim = 2 # 维度
lb = np.matrix([[0.001], [0.001], [0.001], [0.001]]) # 下边界
ub = np.matrix([[100], [100], [100], [100]]) # 上边界
fobj = fun
GbestScore, GbestPositon, Curve = BOA.BOA(pop, dim, lb, ub, MaxIter, fobj)
print('最优适应度值:', GbestScore)
print('c,g最优解:', GbestPositon)
# 利用最终优化的结果计算分类正确率等信息
#训练svm分类器
'''
=====================================使用最优超参数实例化SVM,并在====================================================
'''
# 实例化SVM并使用SVM进行训练
classifier = svm.SVC(C=GbestPositon[0, 0], kernel='rbf', gamma=GbestPositon[0, 1]) # ovr:一对多策略
classifier.fit(x_train, y_train.ravel()) # ravel函数在降维时默认是行序优先
# 4.计算svc分类器的准确率
tra_label = classifier.predict(x_train) # 训练集的预测标签
tes_label = classifier.predict(x_test) # 测试集的预测标签
print("训练集准确率:", accuracy_score(y_train, tra_label))
print("测试集准确率:", accuracy_score(y_test, tes_label))
# 绘制适应度曲线
plt.figure(2)
plt.plot(Curve, 'r-', linewidth=2)
plt.xlabel('Iteration', fontsize='medium')
plt.ylabel("Fitness", fontsize='medium')
plt.grid()
plt.title('BOA', fontsize='large')
print('【程序执行完毕】')
plt.show()
运行结果
D:\ANACONDA\envs\pytorch\python.exe C:/Users/Administrator/Desktop/Code/Bearing-fault-Diagnosis-based-on-deep-learning-main/BOA_SVM/main.py
第0次迭代
第1次迭代
第2次迭代
第3次迭代
第4次迭代
最优适应度值: [0.41]
c,g最优解: [[4.41017232e+01 1.00000000e-03]]
训练集准确率: 1.0
测试集准确率: 0.59
Process finished with exit code 0