【JVM】优化-基础知识
JVM基础
一、jvm基础
1、JDK JRE JVM
jdk = jre + development kit
jre = jvm + core lib
补充:development kit
英 [dɪˈveləpmənt kɪt] 美 [dɪˈveləpmənt kɪt]
开发工具包;开发包;开发套件;开发工具;软件开发包

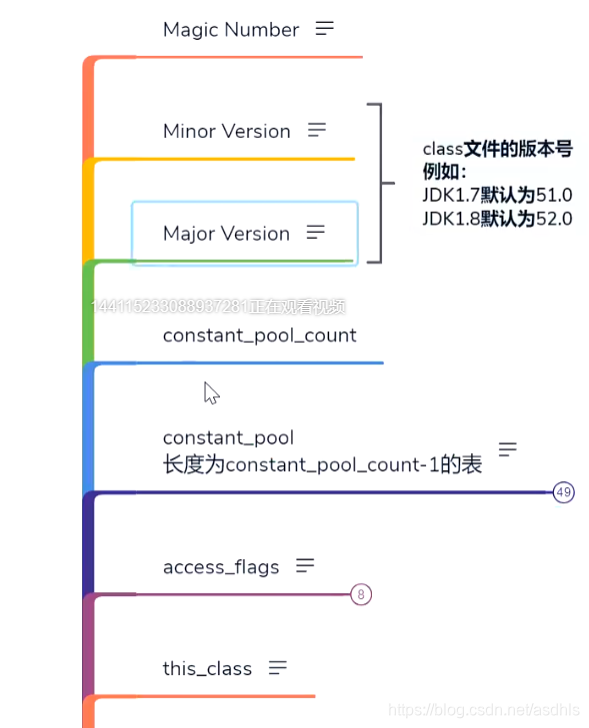
2、Class File Format
1)class文件查看工具
IDEA中的binED插件,可以查看2、8、16进制查看
jclasslib工具可以对class文件每个字节进行编译解释
2)class文件的数据结构
minor
英 [ˈmaɪnə®] 美 [ˈmaɪnər]
adj.少数的;轻微的;较小的;次要的;小调的;小音阶的
n.未成年人;辅修科目;辅修课程 v.辅修
major
英 [ˈmeɪdʒə®] 美 [ˈmeɪdʒər]
n.专业;少校;主修课程;专业课;主修学生
adj.主要的;大的;重要的;严重;大调的
v.主修;专攻
3、类加载
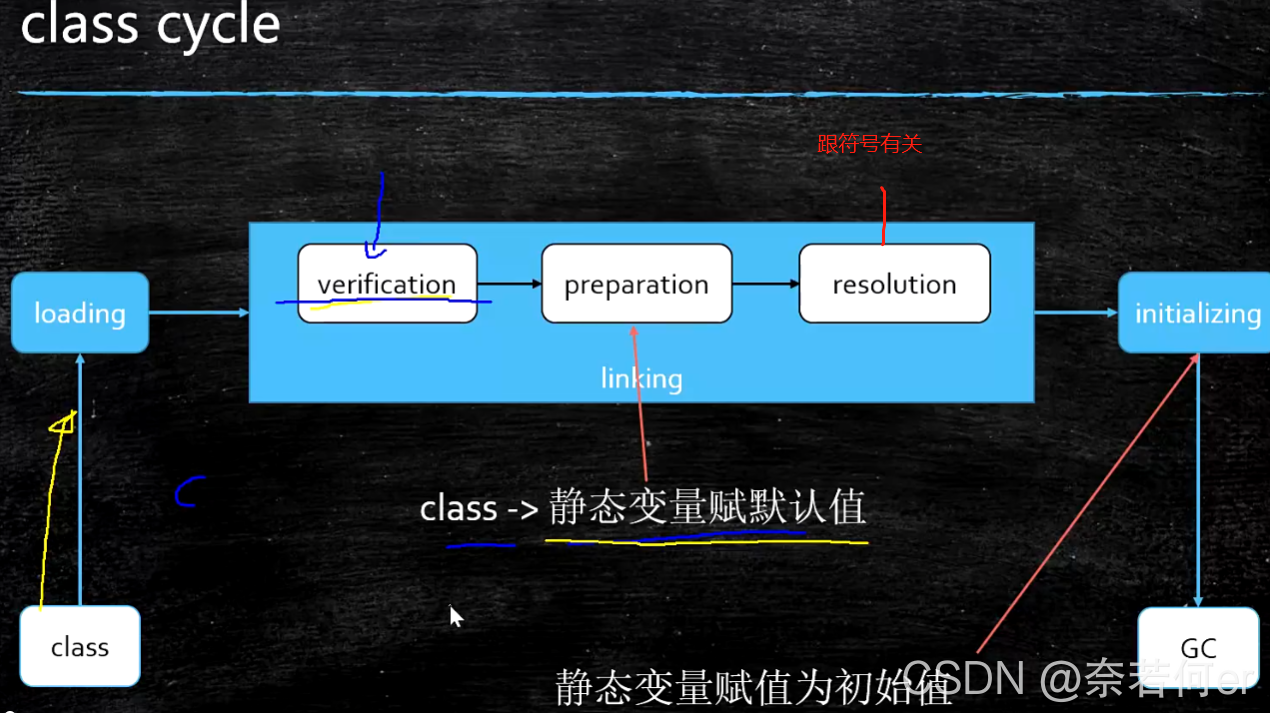
1、calss cycle
主要分为三部分:loading - linking(Verification Prepareation Resolution) - initializing
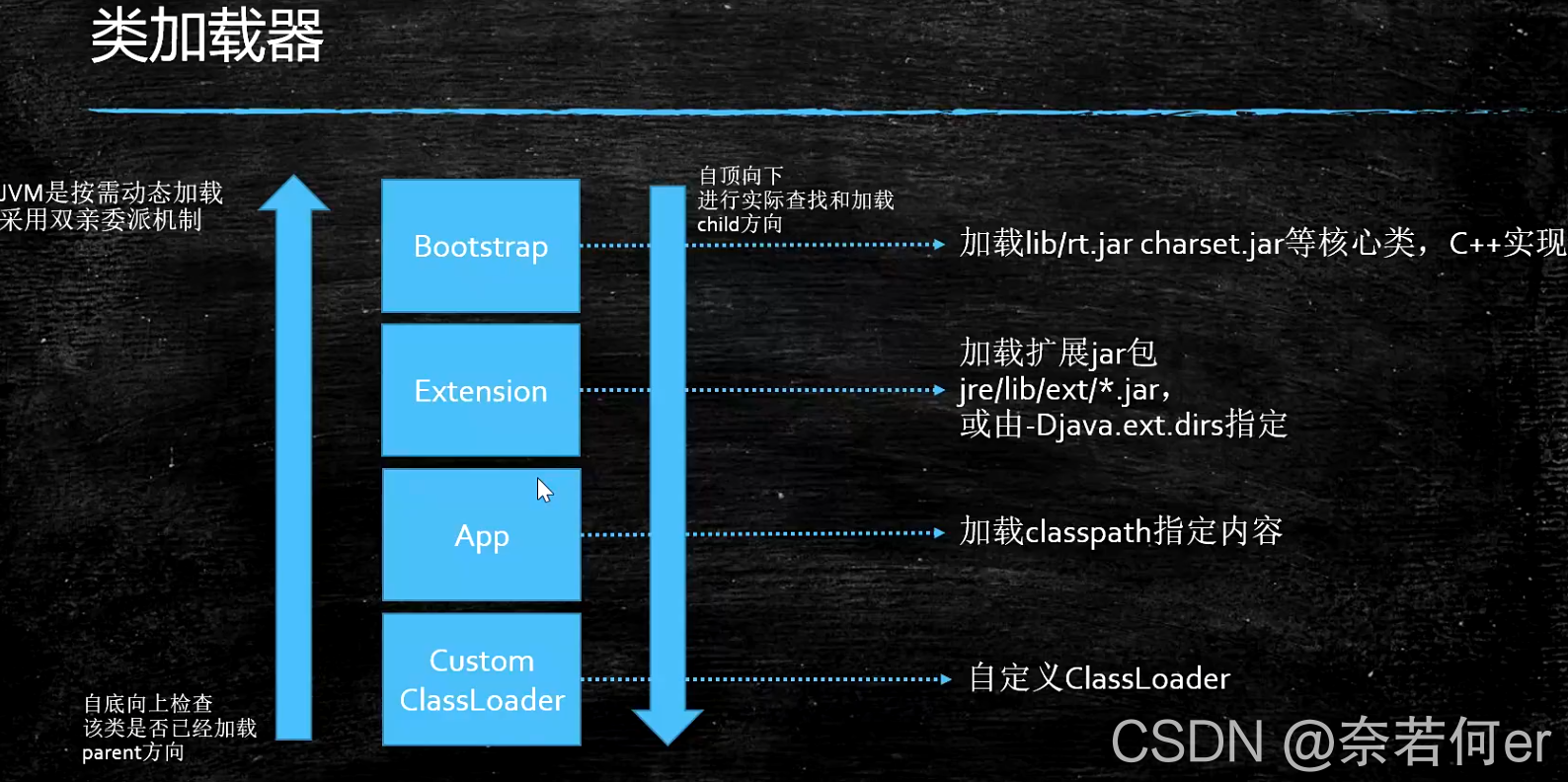
2、双亲委派机制
父加载器不是“父类加载器”,翻译内容不太合适。从子到父检查是否已加载,从父到子进行类的加载。
主要是为了代码安全。(自定义java.lang.string,加入后门则无法保证代码安全)
4、memory Model (JMM)
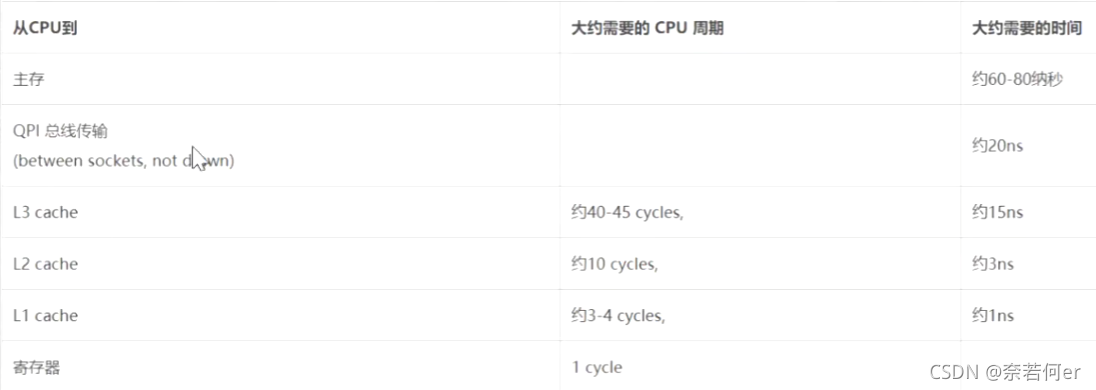
4.1 计算机的存储结构
(1) cpu读取数据从上到下依次进行查找。
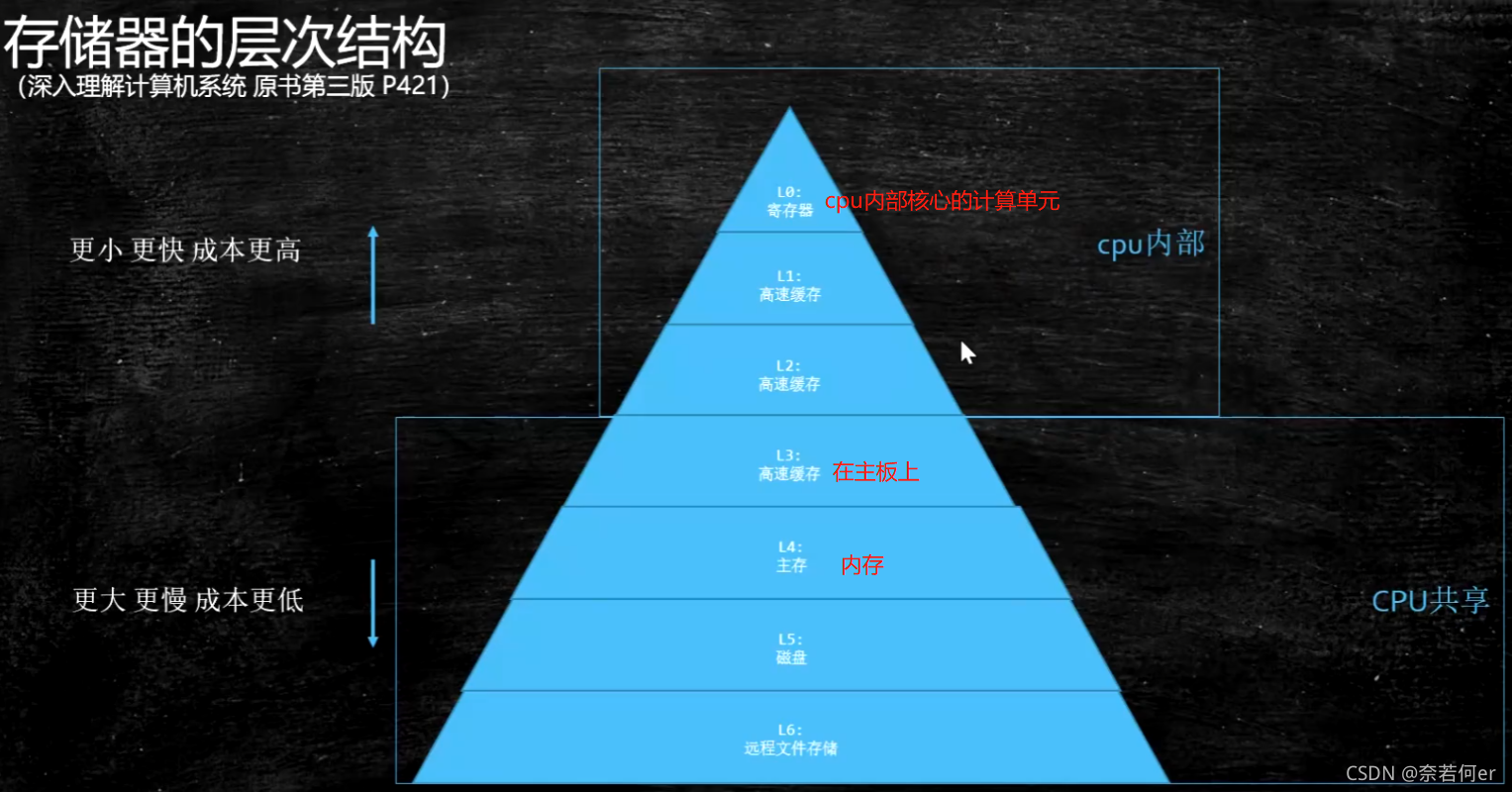
各层级读取速度:
(2)硬件数据一致性
Intel 的芯片底层同步 MESI Cache一致性协议,通过对每个cache line标记不同的状态。
缓存锁比总线锁性能更好,但无法处理不能缓存数据的一致性问题,因此现代cpu一致性=缓存锁+总线锁
(3)缓存行对齐 伪共享问题
缓存读取以cache line为单位,长度为64bytes;(512位)
伪共享问题:通过cache line进行缓存行对齐。
4.2乱序
(1)原因:读指令的同时可以同时执行不影响的其他指令,而写的同时可以进行合并写(WCBuffer合并写)。这样cpu的执行就是乱序的。必须使用Memory Barrier来做好指令排序
volatile的底层就是这么实现的(windows是lock指令)
CPU寄存器执行时间单位1,从内存读取至少100个时间单位,从硬盘读取100万个时间单位级别。cpu为了提高指令执行顺序,会在一条指令执行的过程中,去执行另一条不影响的其他指令。
int a = 1;
int b = a;//这里b依赖a就不会出现乱序问题
(2)合并写技术
(3)保证有序性:
1、件内存屏障(cpu内存屏障,X86):sfence,lfence,mfence。
原子指令,如x86的“lock 。。。”指令是一个full barrier,执行时会锁住内存子系统来确保执行顺序,甚至阔多个CPU。Software Locks 通常使用了内存屏障或原子指令来实现变量可见性和保持程序顺序。
2、jvm级别如何规范(JSP133)
LoadLodad
4.3 volatile实现细节
(1)编辑器层面 在对应的变量前增加volatile
(2)jvm层面:volatile内存区的读写,都加屏障。
(3)操作系统及硬件层面:
5 对象(后续会补充)
5.1 对象创建
(加载类)
1、class loading
2 class linking (verification, preparation,resolution)
3 class initializing
(创建对象)
4 申请内存空间
5 成员变量赋默认值
6 调用构造方法
1) 成员变量顺序赋初始值
2) 执行构造方法语句 (构造方法首先调用super() 方法)
5.2 对象在内存中的布局
1、对象组成:
1)对象头:markword 8
2) ClassPointer指针
3)实例数据Oops Ordinary Object Pointer/(数组对象的话是:数据长度, 数组数据)
4)对齐,8的倍数
6 JVM Runtime Data Area / JVM Instructions
参考资料(以实际版本为准):

java语言:

Run-time data areas
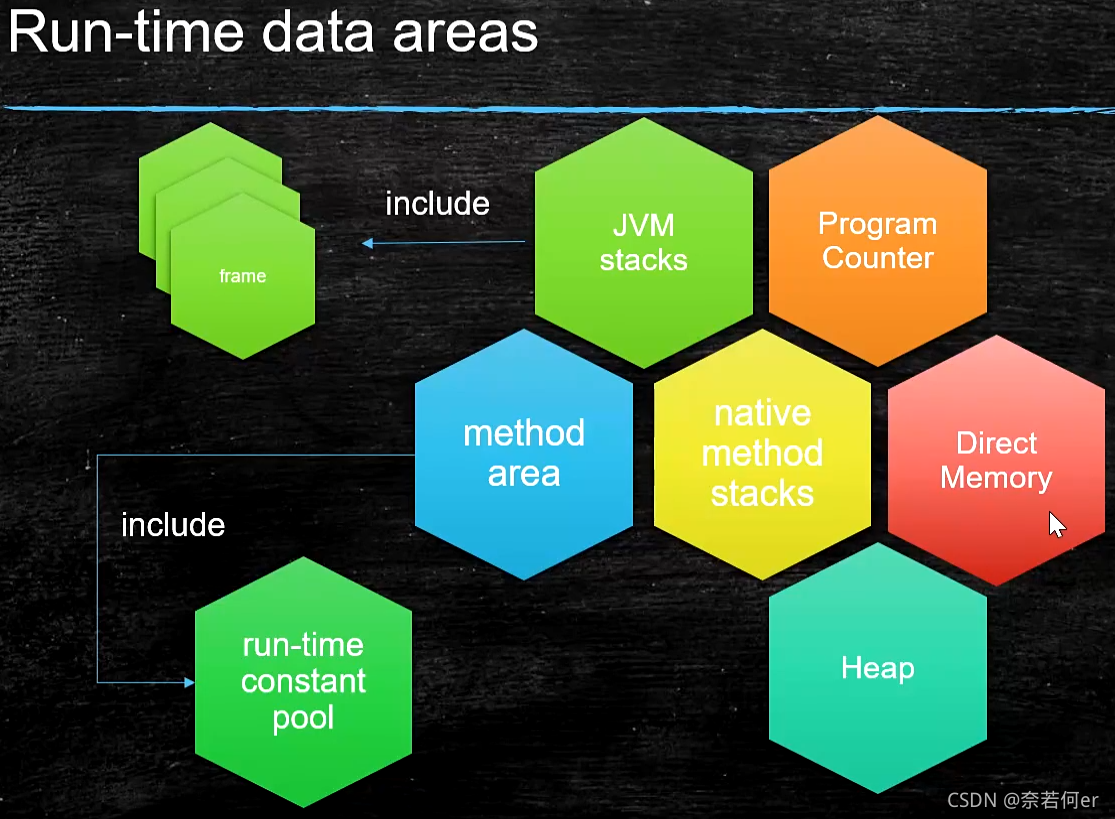
6.1 JVM Stacks
1、frame - 每一个方法对应一个栈帧
1) Local Variable Table - 局部变量表
2) Operand Stack - 操作数栈
3) Dynamic Linking
4) return address a()->b() 方法a调用了方法b,方法b的返回值放在什么地方。
6.2 Method Space
1、Perm Space(<1.8)
字符串常量位于Perm Space
FGC不会清理
大小启动的时候指定,不能改变
2、Meta Space
字符串常量位于堆
会触发FGC清理
不设定的,最大就是物理内存
6.3 Direct Memory
JVM可以直接访问的内核空间的内存(OS管理的内存)
NIO,提高效率,实现zero copy
6.2常用指令
1、store 存储
2、load 加载指令
3、invoke指令
invoke
英 [ɪnˈvəʊk] 美 [ɪnˈvoʊk]
vt.
援引;援用(法律、规则等作为行动理由);提及(某人、某理论、实例等作为支持);提出(某人的名字,以激发某种感觉或行动)
1、InvokeStatic 调用静态方法
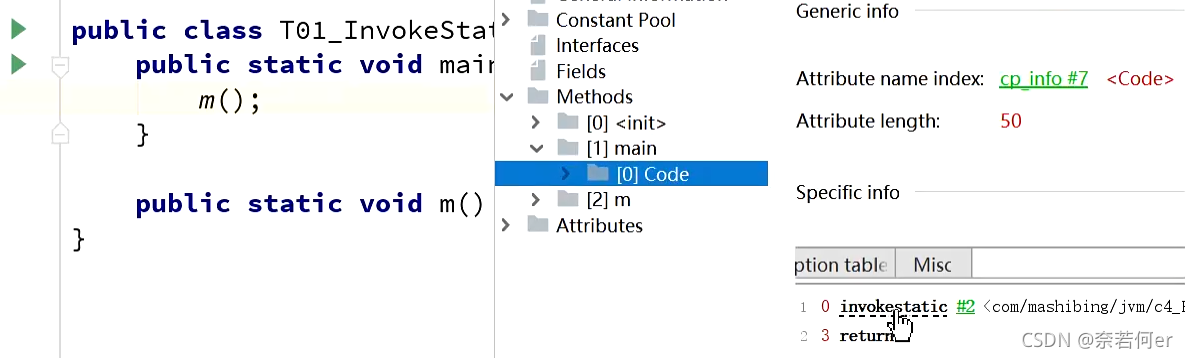
2、InvokeVirtual 自带多态(final修饰的也是这个指令)
3、InvokeInterface
4、InvokeSpecial 调用构造方法、私有方法。可以直接定位,不需要多态的方法。
5、InvokeDynamic JVM最难的指令,lambda表达式或反射或其他动态语言scala kotlin,或者CGLib ,动态产生
7 JVM调优
7.1 Garbage
没有一个引用指向的一个对象或者一堆对象,都叫garbage
7.2 如何找到Garbage
Reference Counter 对象被引用几次就有几个的状态值,为0就会被发现。但是无法发现循环引用的一组对象。
Root Searching跟可达算法,没有根引用的对象
Whice instances are roots?
JVM stacks, native method stack, run-time constant pool, static refences in method area, clazz
7.3 GC Algorithms (常见的垃圾回收算法)
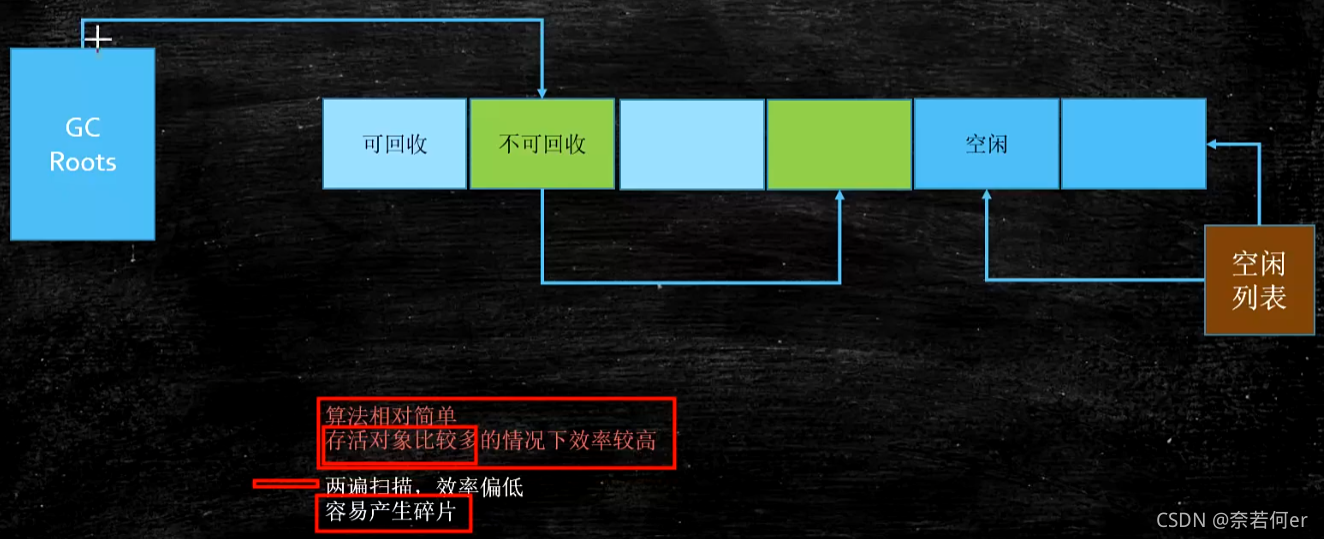
Mark-Sweep(标记清除)
算法相对简单,存活对象比较多的情况下效率较高。
两边扫描,效率偏低(一次扫描找出存活的,另一边清除G)。
容易产生碎片。
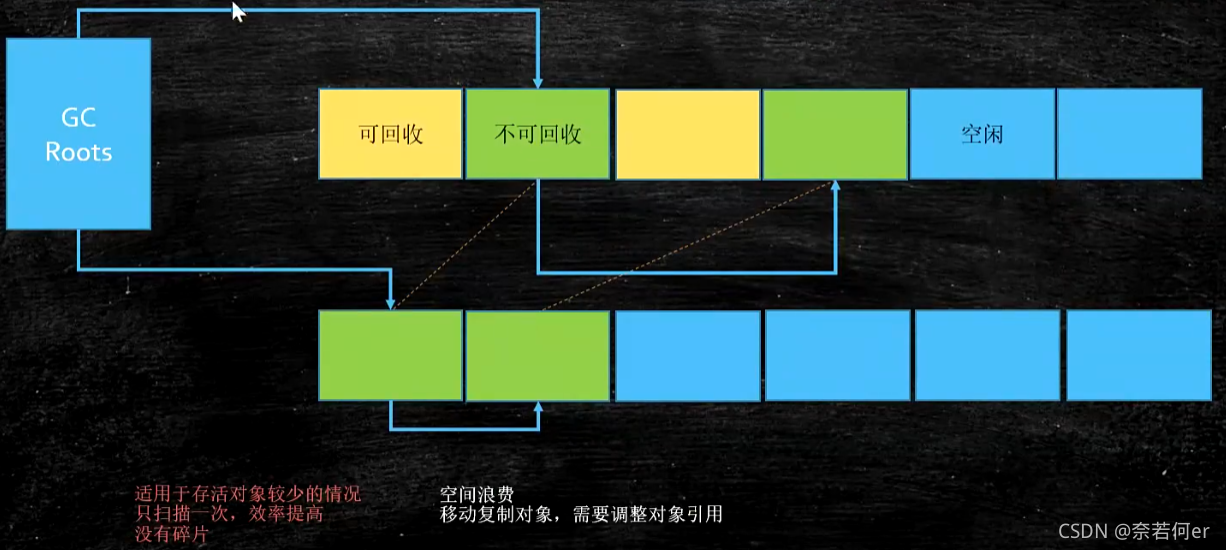
Coping(拷贝)
适用于存活对象较少情况,只扫描一次,效率提高。没有碎片
空间浪费,移动复制对象,需要调整对象引用(空间一分为二,将一边的全部移动复制到右边,左边全部清除)
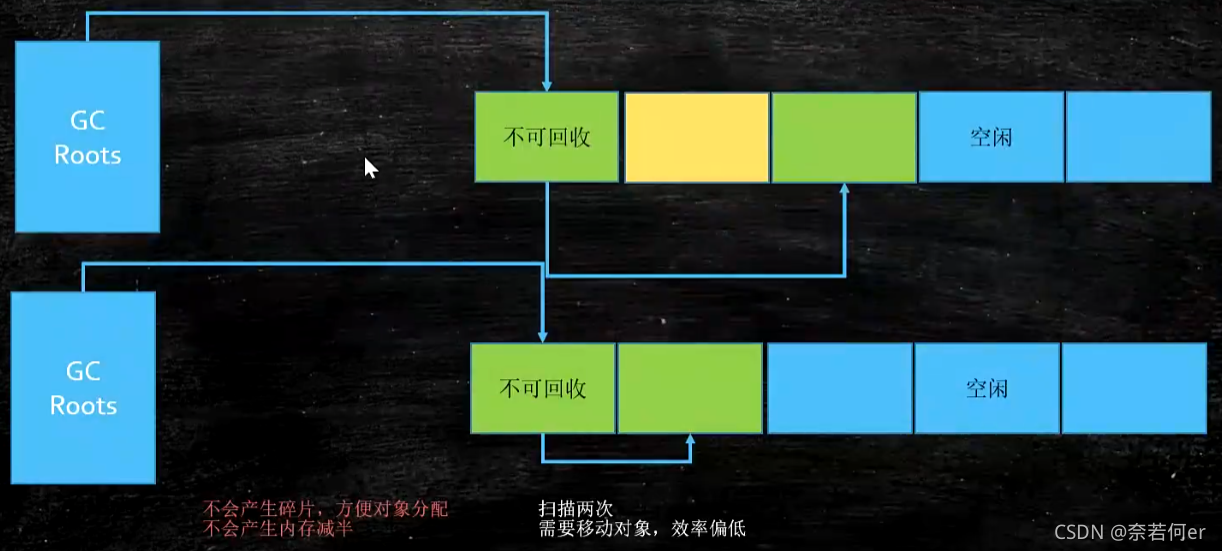
Mark-Compact(标记压缩) 没有碎片,效率偏低(需要两次扫描,同时指针需要调整)
7.4 JVM内存分代模型(用于分代垃圾回收算法)
1、部分垃圾回收器使用的模型
除Epsilon ZGC Shenandoah之外的GC都是使用逻辑分代模型
G1是逻辑分代,物理不分代
除此之外不仅逻辑分代,而且物理分代
堆内存逻辑分区(不适用不分代垃圾收集器)
参考链接

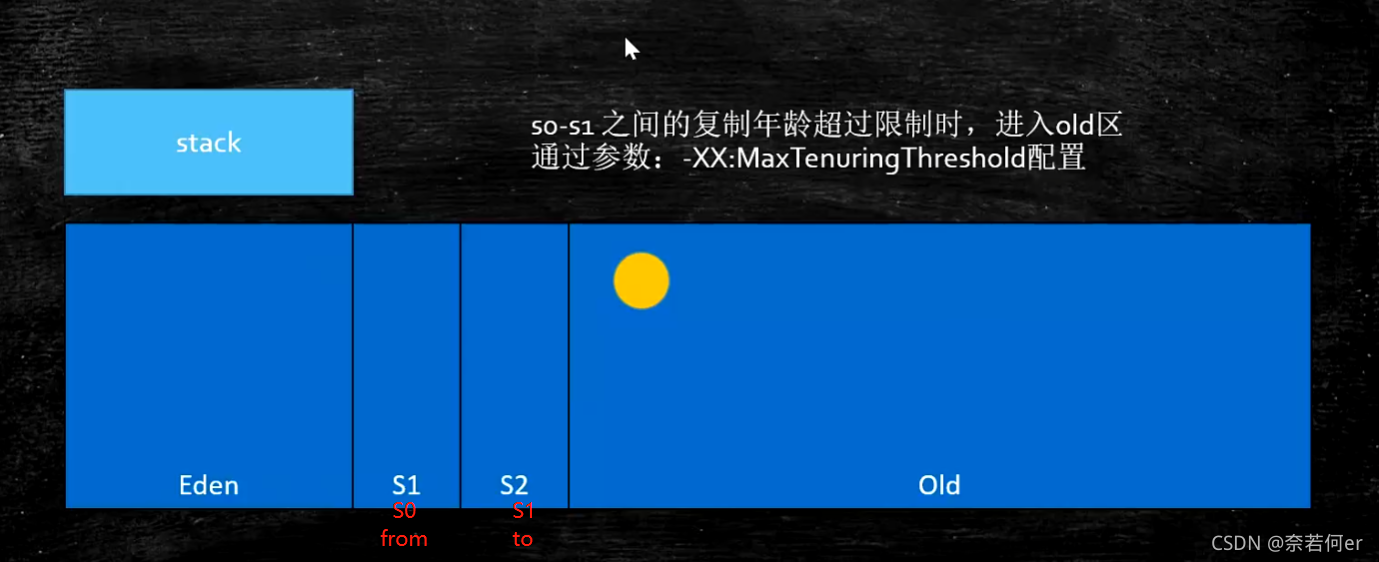
2、新生代+老年代+永久代(1.7 Perm Genration)/ 元数据区(1.8)metaspace
a.永久代 元数据 --Class
b. 永久代必须指定大小限制,一旦指定则无法修改(会出现内存溢出问题);元数据可以设置,也可以不设置,无上限(受限于内存空间)
c.字符串常量1.7-永久代 1.8-堆
d.MethodArea逻辑概念 - 永久代、元数据
3、新生代 = Eden + 2个suvivor区
4、老年代
5、GC Tuning(Generation)
a.尽量减少FGC
b.Minor GC = YGC
c.Major GC = FGC
6、对象分配过程
8 常用的垃圾回收器
Garbage Collector与内存大小关系
1.Serial + Serial Old 几十兆 (单线程)
2.Parallel Scavenge + Parallel Old 上百兆 - 几个G (并行回收,垃圾回收器工作时,工作线程停止)
3.PN + CMS 20G(并发模式)
4.G1 上百G
5.ZGC 4T - 16T(13里面支持16个T)
常见垃圾回收器组合
G1比CMS吞吐量少了15%,G1响应时间更快一些
9 调优
9.1 基础概念
1、吞吐量
=用户代码执行时间/(用户代码执行时间+垃圾收集执行时间)
2、响应时间快=用户线程停顿的时间短,STW越短,响应时间越好。
确定调优之前,应该确定到底是哪个优先,是计算型任务还是响应型任务。
科学计算,吞吐量优先的一般:(PS+PO)
响应时间:网站 GUI API (1.8 G1) po调优实战
调优
1、根据需求进行JVM规划和预调优
2、优化运行JVM运行环境(慢、 卡顿)
3、解决JVM运行过程中出现的各种问题
优化环境
1、有一个50万PV的资料类网站(从磁盘提取文档到内存)原服务器32位,1.5G的堆,用户反馈网站比较缓慢,因此公司决定升级,新的服务器为64位,16G的堆内存,结果用户反馈卡顿十分严重,反而比以前效率更低了
为什么?
内存较小,频繁GC,STW时间较长。
为什么更卡顿了
内存越大,GC频率虽然低了,但是FGC时间边长,STW时间过长。
解决措施
将原有的ps+po,更换为pn+cms或者G1
2、系统CPU经常100,如何调优?
CPU100一定有线程在占用系统资源,先确认工作线程占比高,垃圾回收占比高。
- 找出哪个进程CPU高 (top)
- 该进程中哪个线程cpu高(top-Hp)
- 导出该线程的堆栈(jstack)
- 查找哪个方法(栈帧)消耗时间(jstack)
3、系统内存飙高,如何查找问题?
导出堆内存(jmap)
分析(jhat jvisualvm mat jprofiler…)
4、如何监控JVM
jstat jvisualvm jprofiler arthas top 。。。
调优,从规划开始
- 调优,从业务场景开始
- 无监控(压力测试,能看到结果),不调优
- 步骤
1、
2、选择回收器组合
3、计算内存需求
4、选定CPU(越高越好)
5、设定年代大小,升级年龄
6、设定日志参数
-Xloggc:/opt/xxx/logs/systemname-xxx-%t.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=20M
-XX:+PrintGCDetails -XX:PrintGCDateStamps -XX:+PrintGCCause
7、观察日志情况
- 大流量的处理方法:分而治之
- 案例1:垂直电商,最高每日百万订单,处理订单系统需要什么样的服务器配置?
这个问题比较业余,因为很多不同的服务器配置都能支撑(1.5G 16G)
1小时360000集中时间段, 100个订单/秒,(找一小时内的高峰期,1000订单/秒)
经验值,
非要计算:一个订单产生需要多少内存?512K * 1000 500M内存
专业一点儿问法:要求响应时间100ms
压测!
- 案例2:12306遭遇春节大规模抢票应该如何支撑?
12306应该是中国并发量最大的秒杀网站:
号称并发量100W最高
CDN -> LVS -> NGINX -> 业务系统 -> 每台机器1W并发(10K问题) 100台机器
普通电商订单 -> 下单 ->订单系统(IO)减库存 ->等待用户付款
12306的一种可能的模型: 下单 -> 减库存 和 订单(redis kafka) 同时异步进行 ->等付款
减库存最后还会把压力压到一台服务器
可以做分布式本地库存 + 单独服务器做库存均衡
大流量的处理方法:分而治之
9.2 案例分析
1、入门案例
触发GC代码:
import java.math.BigDecimal;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.concurrent.ScheduledThreadPoolExecutor;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
/**
* 从数据库中读取信用数据,套用模型,并把结果进行记录和传输
*/
public class T15_FullGC_Problem01 {
private static class CardInfo {
BigDecimal price = new BigDecimal(0.0);
String name = "张三";
int age = 5;
Date birthdate = new Date();
public void m() {}
}
private static ScheduledThreadPoolExecutor executor = new ScheduledThreadPoolExecutor(50,
new ThreadPoolExecutor.DiscardOldestPolicy());
public static void main(String[] args) throws Exception {
executor.setMaximumPoolSize(50);
for (;;){
modelFit();
Thread.sleep(100);
}
}
private static void modelFit(){
List<CardInfo> taskList = getAllCardInfo();
taskList.forEach(info -> {
// do something
executor.scheduleWithFixedDelay(() -> {
//do sth with info
info.m();
}, 2, 3, TimeUnit.SECONDS);
});
}
private static List<CardInfo> getAllCardInfo(){
List<CardInfo> taskList = new ArrayList<>();
for (int i = 0; i < 100; i++) {
CardInfo ci = new CardInfo();
taskList.add(ci);
}
return taskList;
}
}
2、arthas
arthas命令参考文章
10 垃圾回收的算法
10.1 CMS
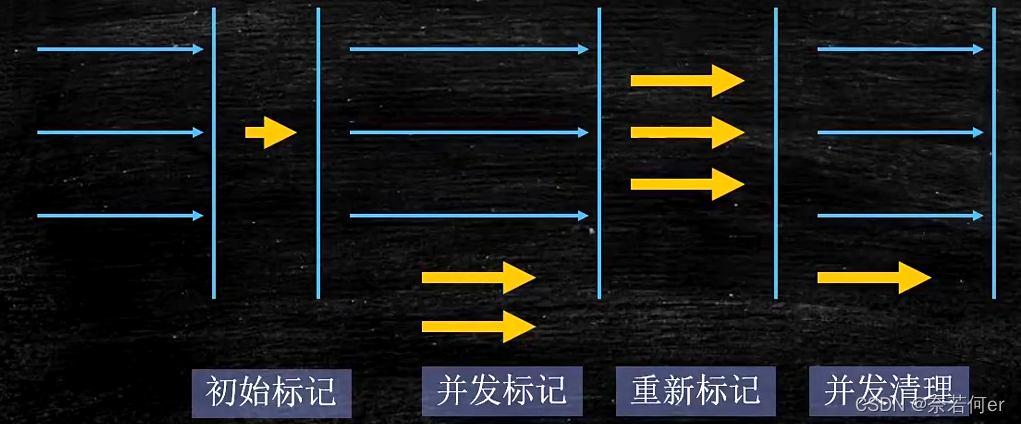
1、 实现逻辑
1) 初始标记:标记根, GC roots ,此阶段是STW,但是时间很短
2) 并发标记:并发标记阶段,比较耗时间,但是业务程序依然运行;
3) 重新标记:remark阶段,是STW,但是依然很短;
4) 并发清理:多线程并发清理,会产生浮动垃圾(floating Garbage)
10.2 G1
10.3 三色标记法
11 日志及参数分析
11.1 CMS日志
-XX:+UseConcMarkSweepGC // 开启cmsGC,默认在young区开启PN
11.2 G1日志分析
-XX:+UseG1GC // 开启g1
G1不推荐指定young区的大小,通过设置暂停时间,G1会动态调整young区的大小(5%~60%)
G1的调优目标是不要有FGC
11.3 GC常用参数
-Xmn -Xms -Xmx -Xss 年轻代 最小堆,最大堆,栈空间
-XX:+PrintGC -XX:PrintGCDetails
java -XX:+PrintFlagsFinal -version | grep G1 查找G1的相关参数
-Xloggc:opt/log/gc.log 日志打印位置
-XX:MaxTenuringThreshold 升代年龄
11.4 Parallel常用参数
11.5 CMS常用参数
12 纤程(协程)
支持语言:go语言,python。。。
至jdk13都不支持,想用需要引入依赖库
<dependy></dependy>