Transformer——位置编码(Positional embding)
位置编码
为什么需要位置编码
Attention机制相较于RNN 以及LSTM 解决了以下两个问题:
- 长序列依赖问题
- 并行计算问题
但是由于并行计算,原有的词向量失去了其在原有语句中的位置信息。为了解决这个问题,故提出了位置编码这个方案。
位置编码机制
位置编码机制的核心就是将位置信息添加到原有词向量之中!
那我们来看下位置编码是怎么将位置信息添加到词向量之中的:
原先无位置编码的做法是对输入Je 进行self-attention运算,得到N维词向量
x
1
x_1
x1。引入位置编码之后,我们对位置信息也计算出一个N维位置词向量
t
1
t_1
t1,输入词向量
x
1
x_1
x1与位置词向量
t
1
t_1
t1进行叠加,我们便能得到蕴含位置信息的词向量
X
1
X_1
X1。
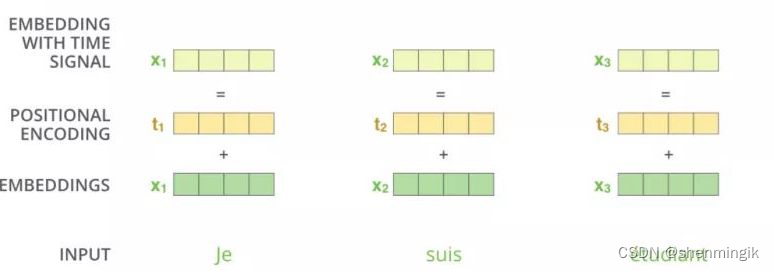
位置编码运算
公式:
P
E
(
p
o
s
,
2
i
)
=
s
i
n
(
p
o
s
/
1000
0
2
i
/
d
m
o
d
e
l
)
PE(pos,2i)=sin(pos/10000^{2i/d_{model}})
PE(pos,2i)=sin(pos/100002i/dmodel)
P
E
(
p
o
s
,
2
i
+
1
)
=
c
o
s
(
p
o
s
/
1000
0
2
i
/
d
m
o
d
e
l
)
PE(pos,2i+1)=cos(pos/10000^{2i/d_{model}})
PE(pos,2i+1)=cos(pos/100002i/dmodel)
来源于和差化积公式:
s
i
n
(
α
+
β
)
=
s
i
n
α
∗
c
o
s
β
+
c
o
s
α
∗
s
i
n
β
sin(\alpha+\beta) = sin\alpha*cos\beta+cos\alpha*sin\beta
sin(α+β)=sinα∗cosβ+cosα∗sinβ
c
o
s
(
α
+
β
)
=
c
o
s
α
∗
c
o
s
β
−
s
i
n
α
∗
s
i
n
β
cos(\alpha+\beta) = cos\alpha*cos\beta-sin\alpha*sin\beta
cos(α+β)=cosα∗cosβ−sinα∗sinβ
由此,我们可以得到如下公式:
P
E
(
p
o
s
+
k
,
2
i
)
=
P
E
(
p
o
s
,
2
i
)
∗
P
E
(
k
,
2
i
+
1
)
+
P
E
(
p
o
s
,
2
i
)
∗
P
E
(
k
,
2
i
)
PE(pos+k,2i)=PE(pos,2i)*PE(k,2i+1)+PE(pos,2i)*PE(k,2i)
PE(pos+k,2i)=PE(pos,2i)∗PE(k,2i+1)+PE(pos,2i)∗PE(k,2i)
P
E
(
p
o
s
+
k
,
2
i
+
1
)
=
P
E
(
p
o
s
,
2
i
+
1
)
∗
P
E
(
k
,
2
i
+
1
)
−
P
E
(
p
o
s
,
2
i
)
∗
P
E
(
k
,
2
i
)
PE(pos+k,2i+1)=PE(pos,2i+1)*PE(k,2i+1)-PE(pos,2i)*PE(k,2i)
PE(pos+k,2i+1)=PE(pos,2i+1)∗PE(k,2i+1)−PE(pos,2i)∗PE(k,2i)
这意味这第 p o s + k pos+k pos+k 位置的词向量 t p o s + k t_{pos+k} tpos+k,其可以由第 p o s pos pos位的词向量信息 t p o s t_{pos} tpos和第 k k k位的词向量信息 t k t_k tk经过线性组合得到,这也就可以说明第 p o s + k pos+k pos+k 个位置的单词会和第 p o s pos pos以及第 k k k个单词存在关联关系,也就可以证明:这个词向量蕴含了位置关系,可以区分不同词向量 X i X_i Xi之间的位置关系。
注:位置最合理的表示是0,1,2,3,4…,但是每个词用的是嵌入向量表示,不是一个值,没法加,所以得做一个变换映射成嵌入维度,变换后还得包含位置属性,正好和差化积公式可以包含。
最后举个计算的例子方便大家理解:
| pos | word | i = 0 | i = 1 | i = 2 | |||
|---|---|---|---|---|---|---|---|
| 0 | 我 | s i n ( 0 / 1000 0 0 / 6 ) sin(0/10000^{0/6}) sin(0/100000/6) | c o s ( 0 / 1000 0 1 / 6 ) cos(0/10000^{1/6}) cos(0/100001/6) | s i n ( 0 / 1000 0 2 / 6 ) sin(0/10000^{2/6}) sin(0/100002/6) | c o s ( 0 / 1000 0 3 / 6 ) cos(0/10000^{3/6}) cos(0/100003/6) | s i n ( 0 / 1000 0 4 / 6 ) sin(0/10000^{4/6}) sin(0/100004/6) | c o s ( 0 / 1000 0 5 / 6 ) cos(0/10000^{5/6}) cos(0/100005/6) |
| 1 | 有 | s i n ( 1 / 1000 0 0 / 6 ) sin(1/10000^{0/6}) sin(1/100000/6) | … | … | … | … | … |
| 2 | 一只 | s i n ( 2 / 1000 0 0 / 6 ) sin(2/10000^{0/6}) sin(2/100000/6) | … | … | … | … | … |
| 3 | 猫 | s i n ( 3 / 1000 0 0 / 6 ) sin(3/10000^{0/6}) sin(3/100000/6) | … | … | … | … | … |
和差化积详细推导公式
P E ( p o s , 2 i ) = s i n ( p o s / 1000 0 2 i / d m o d e l ) ( p o s = α + β ) PE(pos,2i)=sin(pos/10000^{2i/d_{model}}) (pos = \alpha+\beta) PE(pos,2i)=sin(pos/100002i/dmodel)(pos=α+β)
s
i
n
(
p
o
s
/
1000
0
2
i
/
d
m
o
d
e
l
)
=
s
i
n
(
α
/
1000
0
2
i
/
d
m
o
d
e
l
+
β
/
1000
0
2
i
/
d
m
o
d
e
l
)
sin(pos/10000^{2i/d_{model}})=sin(\alpha/10000^{2i/d_{model}}+\beta/10000^{2i/d_{model}})
sin(pos/100002i/dmodel)=sin(α/100002i/dmodel+β/100002i/dmodel)
=
s
i
n
(
α
/
1000
0
2
i
/
d
m
o
d
e
l
)
∗
c
o
s
(
β
/
1000
0
2
i
/
d
m
o
d
e
l
)
+
c
o
s
(
α
/
1000
0
2
i
/
d
m
o
d
e
l
)
∗
s
i
n
(
β
/
1000
0
2
i
/
d
m
o
d
e
l
)
=sin(\alpha/10000^{2i/d_{model}})*cos(\beta/10000^{2i/d_{model}})+cos(\alpha/10000^{2i/d_{model}})*sin(\beta/10000^{2i/d_{model}})
=sin(α/100002i/dmodel)∗cos(β/100002i/dmodel)+cos(α/100002i/dmodel)∗sin(β/100002i/dmodel)
=
P
E
(
α
,
2
i
)
∗
P
E
(
β
,
2
i
+
1
)
+
P
E
(
α
,
2
i
)
∗
P
E
(
β
,
2
i
)
=PE(\alpha,2i)*PE(\beta,2i+1)+PE(\alpha,2i)*PE(\beta,2i)
=PE(α,2i)∗PE(β,2i+1)+PE(α,2i)∗PE(β,2i)