flink (一)
随着互联网的不断发展,行业内对于数据的处理能力和计算的实时性要求都在不断增加,随之而来的是计算框架的升级。经过了十余年开源社区的不断演进,现在计算框架已经从第一代的雅虎开源的Hadoop体系进化到目前主流的Spark框架,这两套框架的计算主要是从强依赖硬盘存储能力的计算发展到了内存计算,大大增强了计算力。随着5G时代的到来,未来都将会是万物互联,各种各样的设备都会与网络连接起来,会有大量的数据产生。以后这些数据都将需要做实时分析,下一代计算引擎,也就是第三代计算引擎,将会从计算实时性的角度突破,也就是Flink框架。
1.什么是 Flink
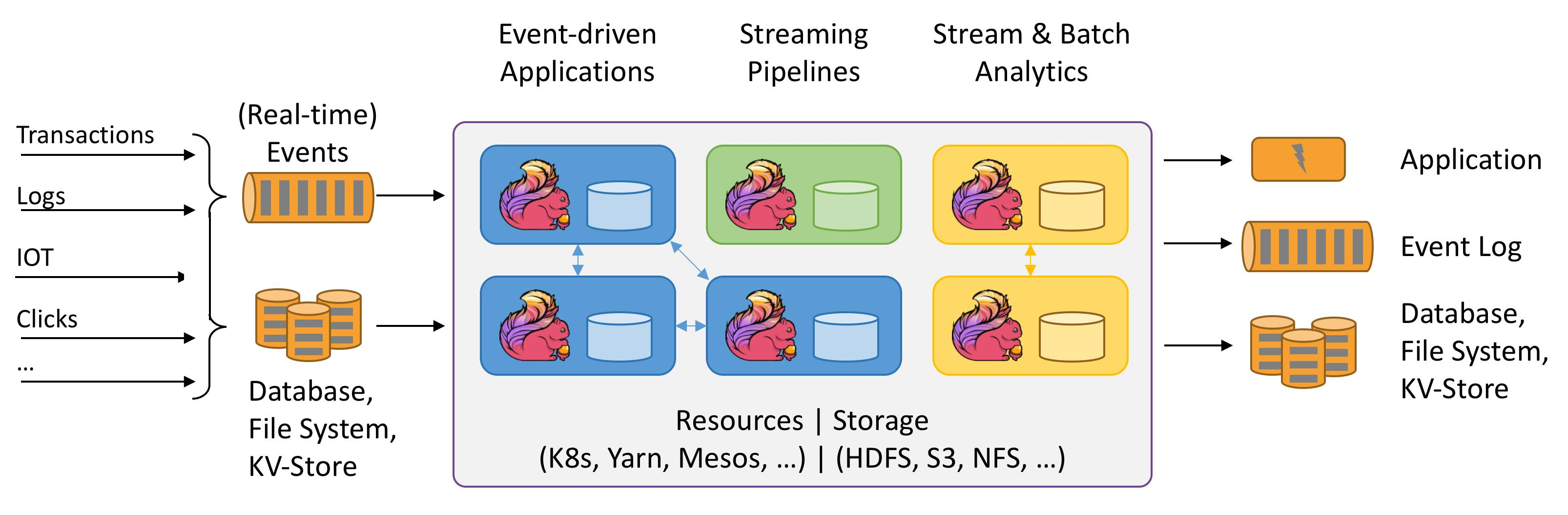
Apache Flink 是一个分布式大数据处理引擎,可对1.有限数据流和2.无线数据流进行有状态计算。可部署在各种集群环境,对各种大小的数据规模进行快速计算。
名词解释:
有限数据流:即数据已经产生,数据大小已经确定。数据有限,可以做离线计算;无限数据流:即数据流一旦产生,不知道什么时候结束。比如:数据实时写入到Kafka。数据无限,可以做实时计算。
1.1.Flink设计初衷
Flink 设计之初,就是为实时计算而设计的。但是因为其计算引擎过于强大,所以也可以做离线计算。它可以部署在各种各样的集群中,比如 Flink自己的 standalone 集群,flink on yarn部署,Flink 还可以跑在K8S上,Flink 还可以跑在各种各样的集群上。Flink为了开发测试比较方便,还可以使用单机模式。可以对各种大小规模的数据进行快速计算。特点就是:快。
2.Flink特点
- 批流统一
- 支持高吞吐、低延迟、高性能的流处
- 支持带有事件事件的窗口(Window)操作
- 支持有状态计算的 Exactly-once 语义
- 支持高度灵活的窗口(Window)操作,支持基于 time、count、session 窗口操作
- 支持具有 Backpressure 功能的持续流模型
- 支持基于轻量级分布式快照(Snapshot)实现的容错
- 支持迭代计算
- Flink 在 JVM内部实现了自己的内存管理
- 支持程序自动优化:避免特定情况下 Shuffle、排序等昂贵操作,中间结果有必要进行缓存。
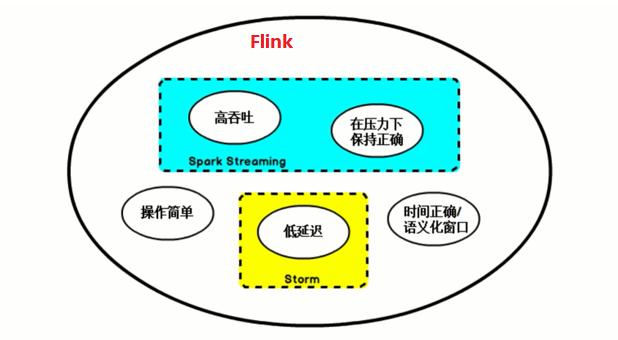
3.Flink 与其他框架的对比
| 框架 | 优点 | 缺点 |
|---|---|---|
| Storm | 低延迟 | 吞吐量第一、不能保证 exactly-once、编程 API 不丰富 |
| Spark Streaming | 吞吐量高、可以保证 exactly-once、编程 API 丰富 | 延迟较高 |
| Storm | 低延迟、吞吐量高、可以保证 exactly-once、编程API丰富(具有Storm+Spark优势) | 快速迭代中,API 变化比较快 |
Spark
Spark 就是为离线计算而设计的,在Spark生态体系中,不论是流处理还是批处理,底层引擎都是Spark Core。Spark Streaming 将微批次小任务不停地提交到 Spark 引擎,从而实现准实时计算,Spark Streaming 只不过是一种特殊的批处理而已。
Flink
Flink 就是为实时计算而设计的,Flink 可以同时实现批处理和流处理,Flink 将批处理(即有界数据/离线处理)视作一种特殊的流处理。
Flink 部署,可以使用本地Local模式,也可以使用Cluster集群模式(可以部署 standalone,yarn上,也可以部署在cloud 云上)。
4.Flink 架构体系简介
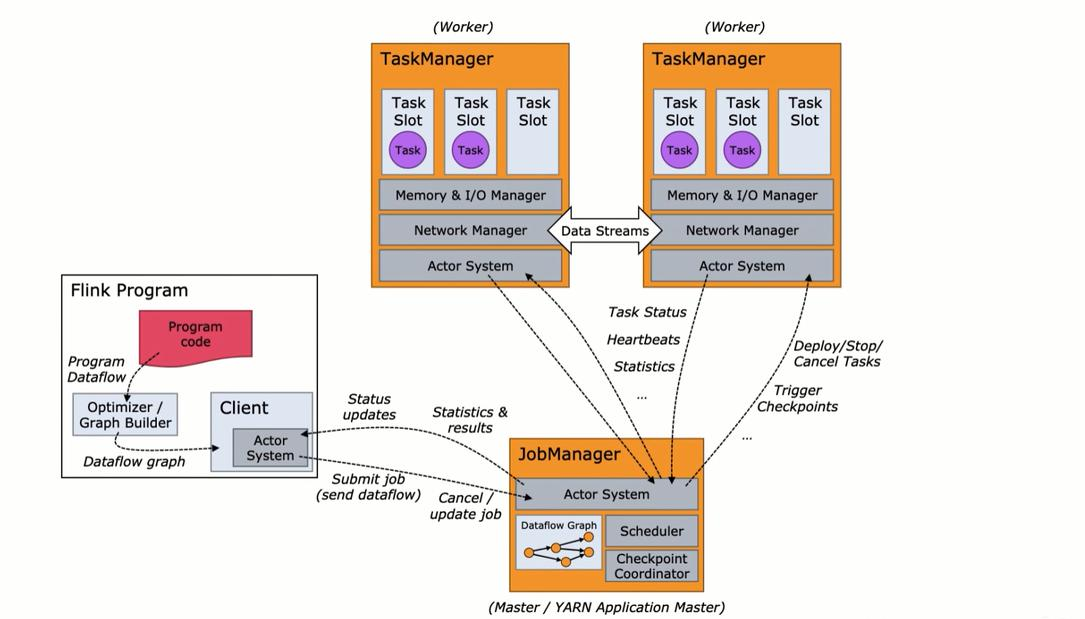
Flink 真正用来做执行操作的,叫做 Worker。进程在不同的环境模式下运行,进程名称不同。如:使用 Standalone集群模式启动,JobManager 叫做 StandaloneSessionClusterEntrypoint,TaskManager叫做 TaskManagerRunner,使用 yarn 集群启动,进程名称又会有所不同。
JobManager介绍:
也称之为 Master,用于协调分布式执行,它用来调度 Task,协调检查点,协调失败时恢复等。Flink 运行时至少存在一个 Master,如果配置高可用模式则会存在多个 Master,他们其中有一个是 Leader,而其他的都是 Standby。
TaskManager介绍:
也称之为 Worker,用于执行一个 dataflow 的 Task、数据缓冲 和 Data Stream 的数据交换,Flink 运行时至少会存在一个 TaskManager。JobManager 和 TaskManager 可以直接运行在物理机上,或者运行在 yarn 这样的资源调度框架。TaskManager 通过网络连接到JobManager,通过 RPC 通信告知自身的可用性进而获得任务分配。
Flink架构流程介绍:
用于工作的叫做 TaskManager(又叫:Worker)。TaskManager 里面以后运行着Task(又叫:subTask)。TaskSlot 中就会运行着真正计算的任务 Task。
TaskManager 相当于用来给 Task 提供执行环境。JobManager相当于是主节点,TaskManager相当于是从节点。JobManager用来负责管理,TaskManager用来负责执行具体的Task,他们之间也要通过网络进行RPC通信。RPC通信,底层使用的是Akka。 我们还会用到一个客户端。这个客户端用来提交任务(左图中的Client)。
客户端提交任务,首先会与 JobManager 进行通信。我们在本地写程序。程序中会构建成一个类似于 Spark 的 DAG(Flink 中叫做Dataflow graph),将 Dataflow graph 提交到 JobManager。JobManager 会把这个Dataflow graph 切分成多个 Task。将 Task 调度到TaskManager中进行执行。(和Spark很相似)
使用客户端提交任务,①可以通过命令来提交 ②也可以通过 Web 页面提交。
5.Sprak 和 Flink角色对比
| 含义 | Spark | Flink |
|---|---|---|
| 离散流 | DStream | DataStream |
| 算子 | Transformation | Transformation |
| Action类算子(xxxx预留) | Action | Sink |
| 任务 | Task | SubTask |
| 流水线 | Pipeline | Oprator chains |
| 有向无环图(Directed Acyclic Graph) | DAG | DataFlow Graph |
| xxxx预留 | Master + Driver | JobManager |
| xxxx预留 | Worker+ Executor | TaskManager |