【AI大模型应用开发】【LangChain系列】3. 一文了解LangChain的记忆模块(理论实战+细节)
大家好,我是【同学小张】。持续学习,持续干货输出,关注我,跟我一起学AI大模型技能。
大多数LLM应用程序都有一个会话接口。会话的一个重要组成部分是能够参考会话早期的信息(上文信息)。这种存储过去互动信息的能力就称为“记忆(Memory)”。LangChain提供了许多用于向系统添加Memory的封装。
目前 LangChain 中大多数的Memory封装还都是测试版本。成熟的Memory主要是
ChatMessageHistory。
0. 认识Memory
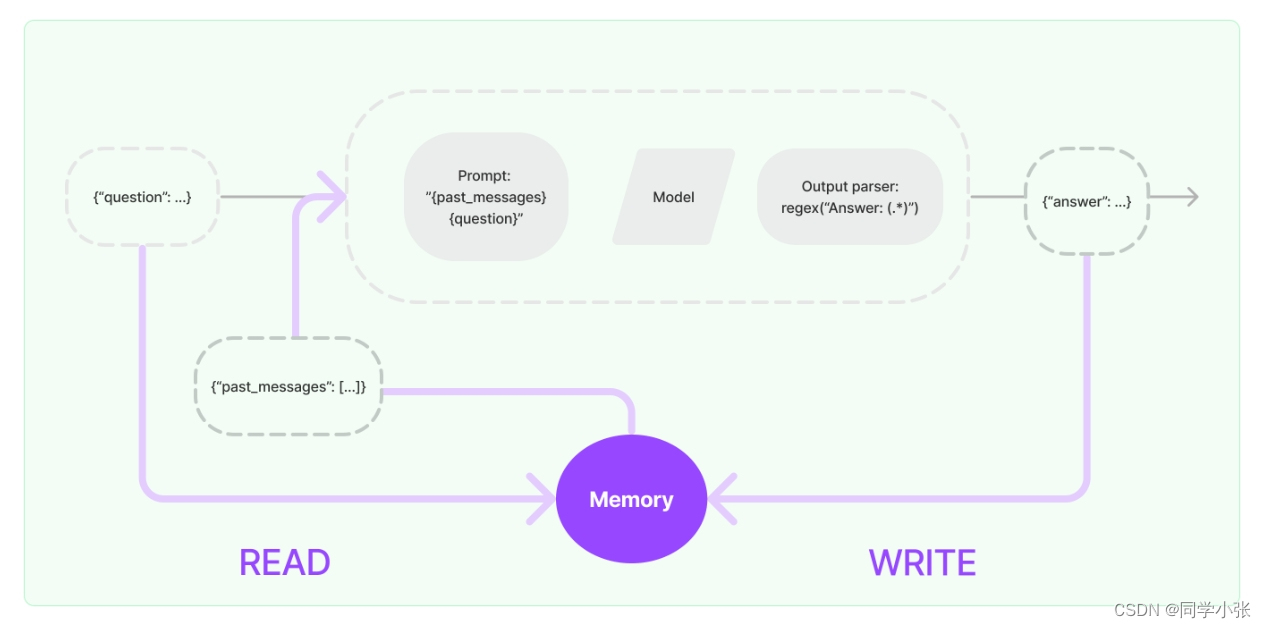
Memory,通俗的讲,就是记录对话的上下文信息,在有需要的时候补充到用户的提问中去。看上图,简单说下Memory的使用流程:
- 当用户输入一个问题,首先从Memory中读取相关的上文信息(历史对话信息),然后组装成一个Prompt,调用大模型,大模型的回复作为历史对话信息保存在Memory中,供之后的对话使用。
下面让我们来看一看LangChain的Memory到底长什么样。
0. 对话上下文ConversationBufferMemory
这是最简单的Memory形式,保存形式类似是chat message的数组。
使用方法如下:
save_context可以保存信息到memory中load_memory_variables获取memory中的信息chat_memory.add_user_message和chat_memory.add_ai_message也可以用来保存信息到memory中
from langchain.memory import ConversationBufferMemory, ConversationBufferWindowMemory
history = ConversationBufferMemory()
history.save_context({"input": "你好啊"}, {"output": "你也好啊"})
print(history.load_memory_variables({}))
history.save_context({"input": "你再好啊"}, {"output": "你又好啊"})
print(history.load_memory_variables({}))
history.chat_memory.add_user_message("你在干嘛")
history.chat_memory.add_ai_message("我在学习")
print(history.load_memory_variables({}))
## 或者直接使用 ChatMessageHistory 添加memory,效果一样
# from langchain.memory import ChatMessageHistory
# chat_history = ChatMessageHistory()
# chat_history.add_user_message("你在干嘛")
# chat_history.add_ai_message("我在学习")
# print(history.load_memory_variables({}))
运行结果:

上面的结果,可以看到返回的信息永远都是以“history”开头的,怎么修改这个key呢?只需要修改下面一句,填入 memory_key 参数。
history = ConversationBufferMemory(memory_key="chat_history_with_同学小张")
运行结果:

返回的结果还有一点值得注意,那就是它目前返回的是一个json字符串,这是可以直接给LLMs对话输入的。但对于ChatModels对话,它接收的参数是Chat Messages数组。我们可以通过改变参数return_messages=True,让这个memory的返回变成Chat Messages数组。
history = ConversationBufferMemory(memory_key="chat_history_with_同学小张", return_messages=True)
返回结果:

1. 只保留k个窗口的上下文:ConversationBufferWindowMemory
ConversationBufferWindowMemory允许用户设置一个K参数,来限定每次从记忆中读取最近的K条记忆。
from langchain.memory import ConversationBufferWindowMemory
window = ConversationBufferWindowMemory(k=1)
window.save_context({"input": "第一轮问"}, {"output": "第一轮答"})
window.save_context({"input": "第二轮问"}, {"output": "第二轮答"})
window.save_context({"input": "第三轮问"}, {"output": "第三轮答"})
print(window.load_memory_variables({}))
运行结果:

2. 通过 Token 数控制上下文长度:ConversationTokenBufferMemory
ConversationTokenBufferMemory允许用户指定最大的token长度,使得从记忆中取上文时不会超过token限制。
from langchain.memory import ConversationTokenBufferMemory
memory = ConversationTokenBufferMemory(
llm=llm,
max_token_limit=45
)
memory.save_context(
{"input": "你好啊"}, {"output": "你好,我是你的AI助手。"})
memory.save_context(
{"input": "你会干什么"}, {"output": "我什么都会"})
print(memory.load_memory_variables({}))

3. 更多记忆类型
-
ConversationSummaryMemory: 对上下文做摘要
-
ConversationSummaryBufferMemory: 保存 Token 数限制内的上下文,对更早的做摘要
-
VectorStoreRetrieverMemory: 将 Memory 存储在向量数据库中,根据用户输入检索回最相关的部分
-
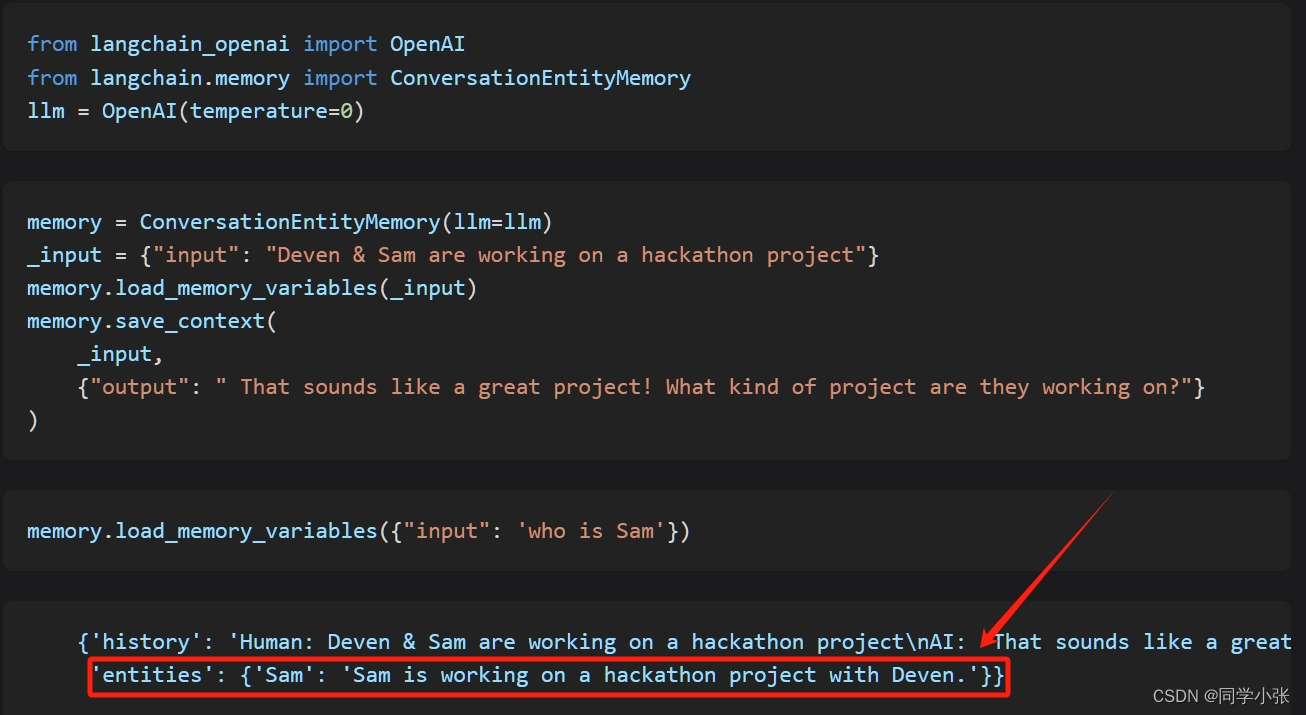
ConversationEntityMemory:保存一些实体信息,例如从输入中找出一个人名,保存这个人的信息。
4. 总计
本文我们学习了 LangChain 的 Memory 记忆模块,可以看到它里面封装了很多的记忆类型,在项目中可以按需选用。但是也应该认识到,目前LangChain的记忆模块还不成熟,是测试版本。LangChain的快速迭代,需要我们时刻关注它的变化。
如果觉得本文对你有帮助,麻烦点个赞和关注呗 ~~~
- 大家好,我是同学小张
- 欢迎 点赞 + 关注 👏,促使我持续学习,持续干货输出。
- +v: jasper_8017 一起交流💬,一起进步💪。
- 微信公众号也可搜【同学小张】 🙏
- 踩坑不易,感谢关注和围观
本站文章一览: