【Python实用技能】建议收藏:自动化实现网页内容转PDF并保存的方法探索(含代码,亲测可用)
- 大家好,我是同学小张,日常分享AI知识和实战案例
- 欢迎 点赞 + 关注 👏,持续学习,持续干货输出。
- +v: jasper_8017 一起交流💬,一起进步💪。
- 微信公众号也可搜【同学小张】 🙏
本站文章一览:
有时候,我们想要将一些网页数据下载到本地,一般有两种做法。
第一种,打开网页,将网页中的内容复制粘贴到本地新建的一个空白文档中。
第二种,打开网页,右键 —> 打印,另存为PDF,如下图
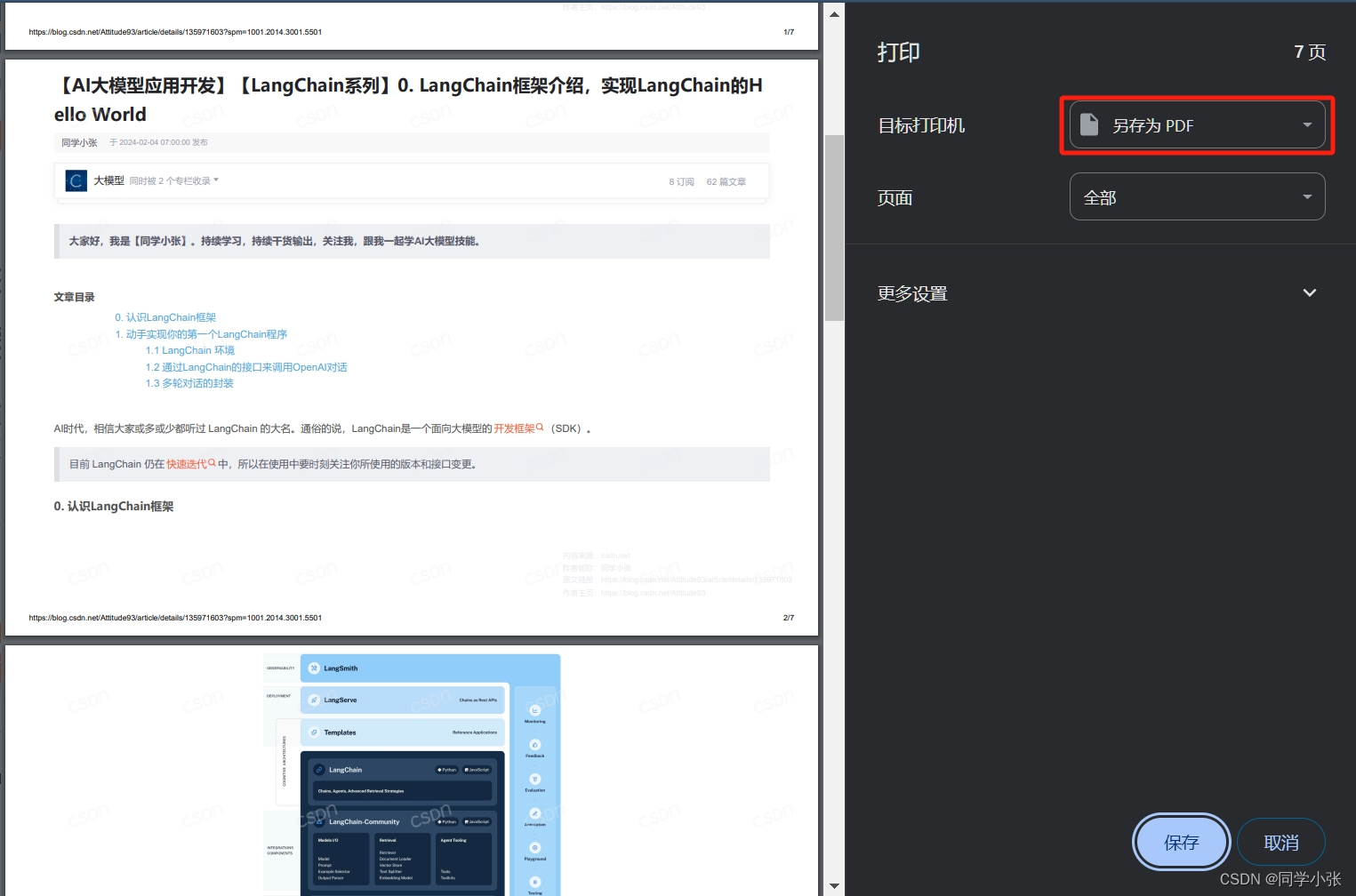
第二种将网页保存成PDF的方法,能更好地保证网页内容的完整性和格式,看起来也比较美观,操作起来也比较方便。但是当URL数量多起来之后,这个重复的工作就比较枯燥了。
本文将探索自动化把URL列表所对应的网页打印成PDF文件的实现方法,内含完整代码,可直接运行使用,建议收藏备用。
文章目录
1. 自动化方法探索
1.1 通过 pdfkit
参考:https://blog.csdn.net/dchzxl/article/details/125363204
1.1.0 环境准备
1.1.0.1 安装 pdfkit
pip install pdfkit
1.1.0.2 安装 wkhtmltopdf
下载地址:https://wkhtmltopdf.org/downloads.html
1.1.1 实现代码
import pdfkit
path_wk = r'd:\\wkhtmltopdf\\bin\\wkhtmltopdf.exe' #你的wkhtmltopdf安装位置
config = pdfkit.configuration(wkhtmltopdf = path_wk)
url = 'https://mp.weixin.qq.com/s/2m8MrsCxf5boiH4Dzpphrg' # 你要转的网页链接
pdfkit.from_url(url, r'D:\\GitHub\\LEARN_LLM\\WeChat\\pdfkit_test.pdf', configuration=config) # 你要保存到的路径及pdf名字
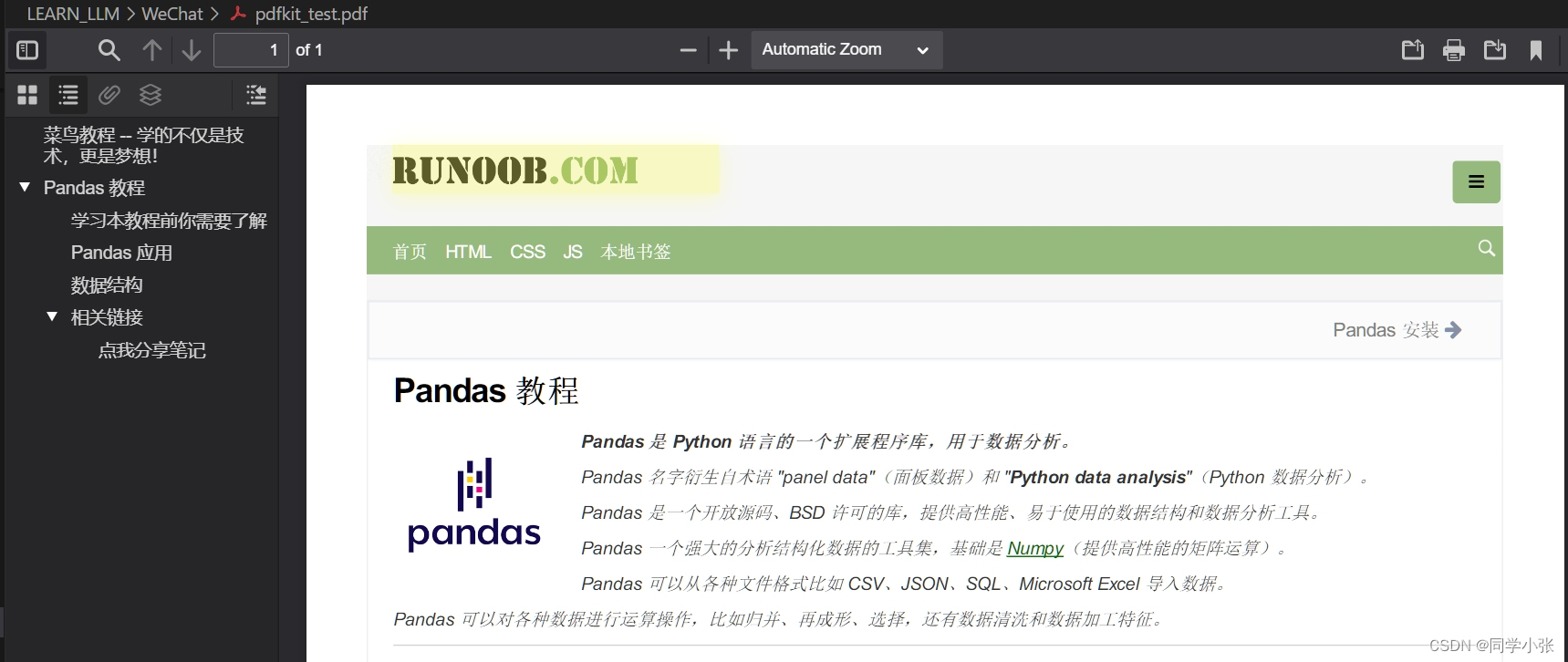
1.1.2 实现效果
有的网页可以打印成功:
但有的网页打印出来内容是空白:
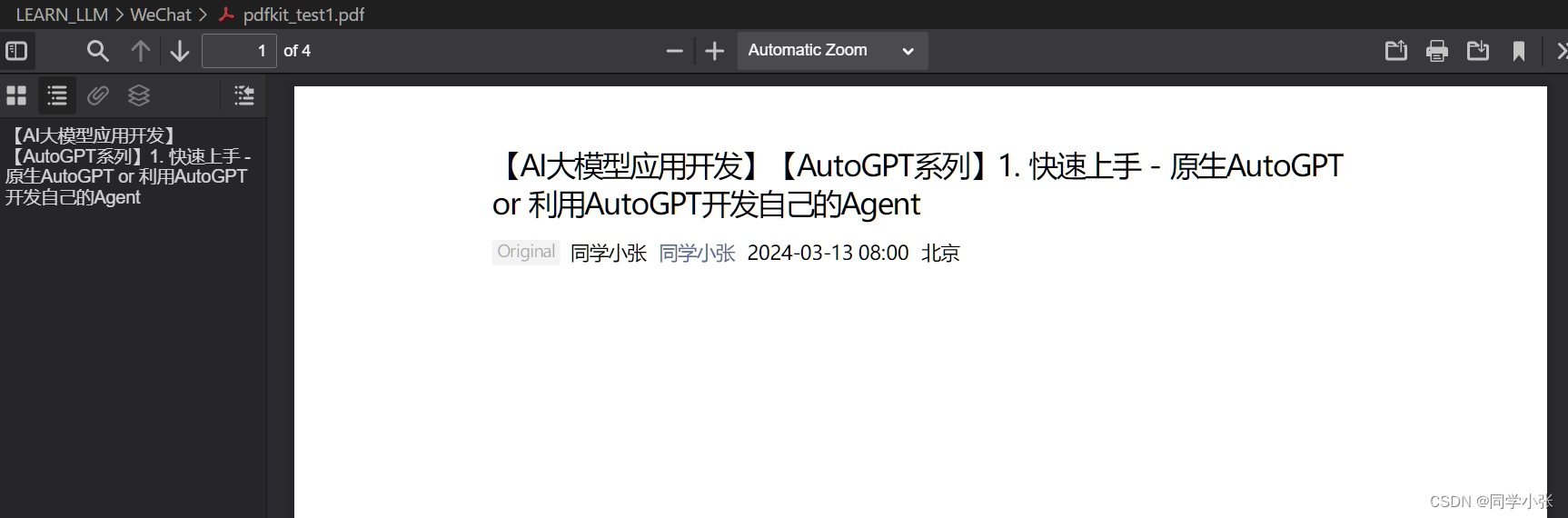
没细研究,是需要补充什么参数才能打印全?
1.1.3 踩坑
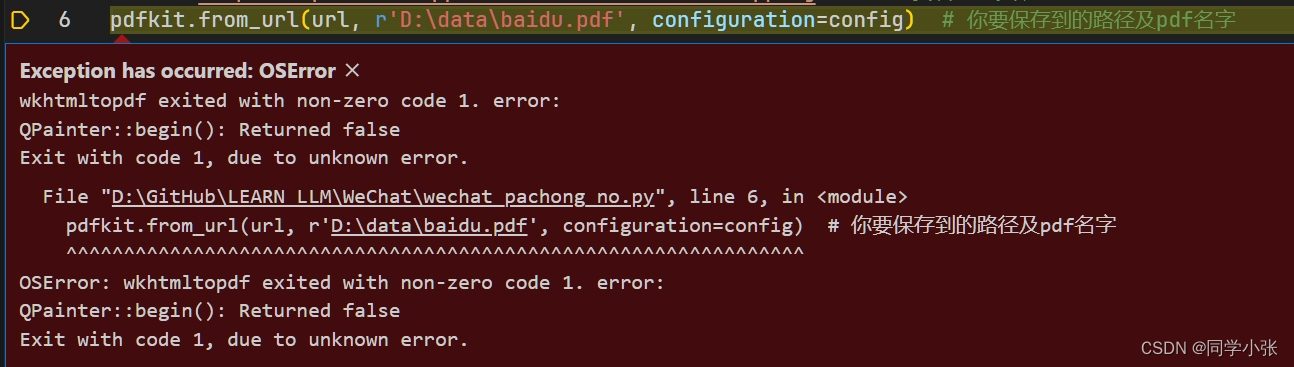
遇到上面这个错,一般是from_url设置的文件保存路径不存在。
1.2 通过 selenium
1.2.1 实现代码
参考:https://www.cnblogs.com/new-june/p/14509601.html
import os,json,time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
chrome_options = webdriver.ChromeOptions()
settings = {
"recentDestinations": [{
"id": "Save as PDF",
"origin": "local",
"account": ""
}],
"selectedDestinationId": "Save as PDF",
"version": 2,
"isHeaderFooterEnabled": False,
# "customMargins": {},
# "marginsType": 2,
# "scaling": 100,
# "scalingType": 3,
# "scalingTypePdf": 3,
"isLandscapeEnabled":False,#landscape横向,portrait 纵向,若不设置该参数,默认纵向
"isCssBackgroundEnabled": True,
"mediaSize": {
"height_microns": 297000,
"name": "ISO_A4",
"width_microns": 210000,
"custom_display_name": "A4 210 x 297 mm"
},
}
chrome_options.add_argument('--enable-print-browser')
#chrome_options.add_argument('--headless') #headless模式下,浏览器窗口不可见,可提高效率
prefs = {
'printing.print_preview_sticky_settings.appState': json.dumps(settings),
'savefile.default_directory': 'D:\GitHub\LEARN_LLM\WeChat' #此处填写你希望文件保存的路径
}
chrome_options.add_argument('--kiosk-printing') #静默打印,无需用户点击打印页面的确定按钮
chrome_options.add_experimental_option('prefs', prefs)
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://mp.weixin.qq.com/s/2m8MrsCxf5boiH4Dzpphrg')
driver.maximize_window()
time.sleep(3)
driver.execute_script('document.title="my_test_file1.pdf";window.print();') #利用js修改网页的title,该title最终就是PDF文件名,利用js的window.print可以快速调出浏览器打印窗口,避免使用热键ctrl+P
driver.close()
1.2.2 实现效果
内容出来了:
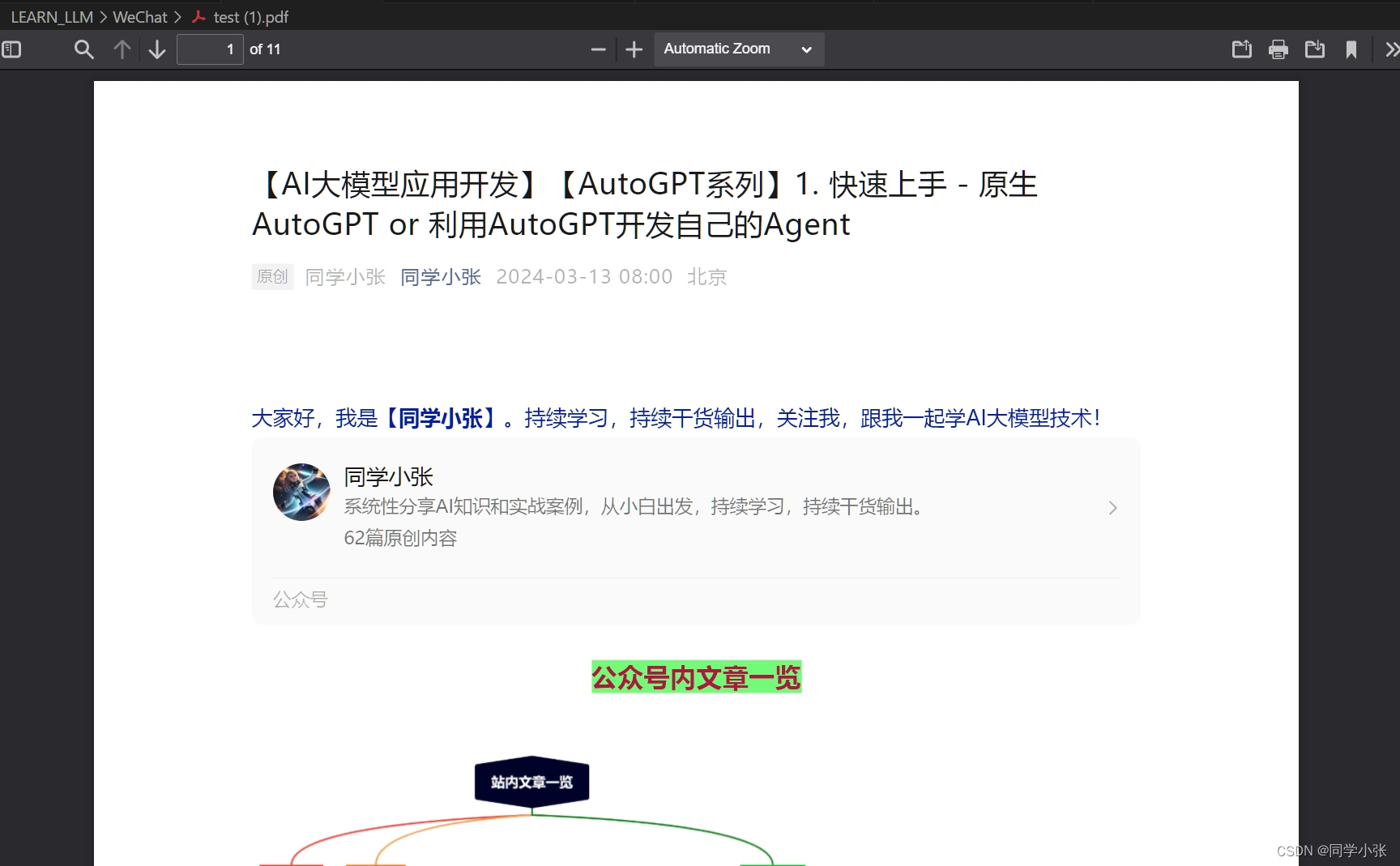
但是图片不全:
1.2.3 代码改进
这是从网上找的另一段程序,主要是在打印前增加了从页面顶端滑动页面到底端的过程。
import os,json,time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
def print_url_to_pdf(url, save_root,
file_name='demo.pdf',
scroll_distance=500,
scroll_interval=0.5,
headless=False):
"""
save_root: pdf 保存目录,建议绝对路径
file_name:pdf保存名称
scroll_distance:每次向下滑动距离,模拟浏览页面,获得全部页面元素
scroll_interval:滑动一次后,间隔时间
headless:是否可见窗口,True, 不可见;False,可见,调试时可设为可见
"""
chrome_options = webdriver.ChromeOptions()
settings = {
"recentDestinations": [{
"id": "Save as PDF",
"origin": "local",
"account": ""
}],
"selectedDestinationId": "Save as PDF",
"version": 2,
"isHeaderFooterEnabled": False,
# "customMargins": {},
# "marginsType": 2,
# "scaling": 100,
# "scalingType": 3,
# "scalingTypePdf": 3,
"isLandscapeEnabled":False,#landscape横向,portrait 纵向,若不设置该参数,默认纵向
"isCssBackgroundEnabled": True,
"mediaSize": {
"height_microns": 297000,
"name": "ISO_A4",
"width_microns": 210000,
"custom_display_name": "A4 210 x 297 mm"
},
}
chrome_options.add_argument('--enable-print-browser')
if headless:
chrome_options.add_argument('--headless') #headless模式下,浏览器窗口不可见,可提高效率
prefs = {
'printing.print_preview_sticky_settings.appState': json.dumps(settings),
'savefile.default_directory': save_root #此处填写你希望文件保存的路径
}
chrome_options.add_argument('--kiosk-printing') #静默打印,无需用户点击打印页面的确定按钮
chrome_options.add_experimental_option('prefs', prefs)
driver = webdriver.Chrome(options=chrome_options)
print('-'*100)
print(f'now: url: {url}')
driver.get(url)
# 获取当前所有窗口的句柄
handles = driver.window_handles
# 切换到最后一个窗口(假设最后一个窗口是要操作的窗口)
driver.switch_to.window(handles[-1])
# 获取当前视口的高度
viewport_height = driver.execute_script("return window.innerHeight;")
# 获取滚动条的位置
current_scroll_position = driver.execute_script("return window.scrollY;")
# 定义滚动的距离和间隔时间
scroll_distance = 200 # 每次滚动的距离
scroll_interval = 0.5 # 每次滚动的间隔时间(秒)
# 计算需要滚动的次数
num_scrolls = int((driver.execute_script("return document.body.scrollHeight;") - current_scroll_position) / scroll_distance)
print('scroll pages...')
# 循环滚动页面
for _ in range(num_scrolls):
driver.execute_script(f"window.scrollBy(0, {scroll_distance});")
time.sleep(scroll_interval)
# # 执行 JavaScript 代码,将页面滚动到底部
# driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# 等待页面加载完成
# 添加适当的等待时间或条件,确保页面已完全加载
time.sleep(5)
driver.maximize_window()
#利用js修改网页的title,该title最终就是PDF文件名,
# 利用js的window.print可以快速调出浏览器打印窗口,避免使用热键ctrl+P
path = os.path.join(save_root, file_name)
print(f'save pdf: {path}')
driver.execute_script(f'document.title="{file_name}";window.print();')
driver.close()
def download_urls(url_list, name_list, save_root):
for url, name in zip(url_list, name_list):
print_url_to_pdf(url, save_root, name)
time.sleep(5)
url_list =[
'https://mp.weixin.qq.com/s/2m8MrsCxf5boiH4Dzpphrg'
]
name_list = [
'test.pdf'
]
save_root = 'D:\\GitHub\\LEARN_LLM\\WeChat\\'
download_urls(url_list, name_list, save_root)
1.2.4 改进后效果
图片也正常生成了PDF:
图片能正常生成PDF的原因,其实就是在代码改进中,增加了页面加载的时间(页面从顶端滑到底部需要时间),这个过程中,图片就已经加载完了,然后打印,才能将图片打印出来。
1.2.5 踩坑
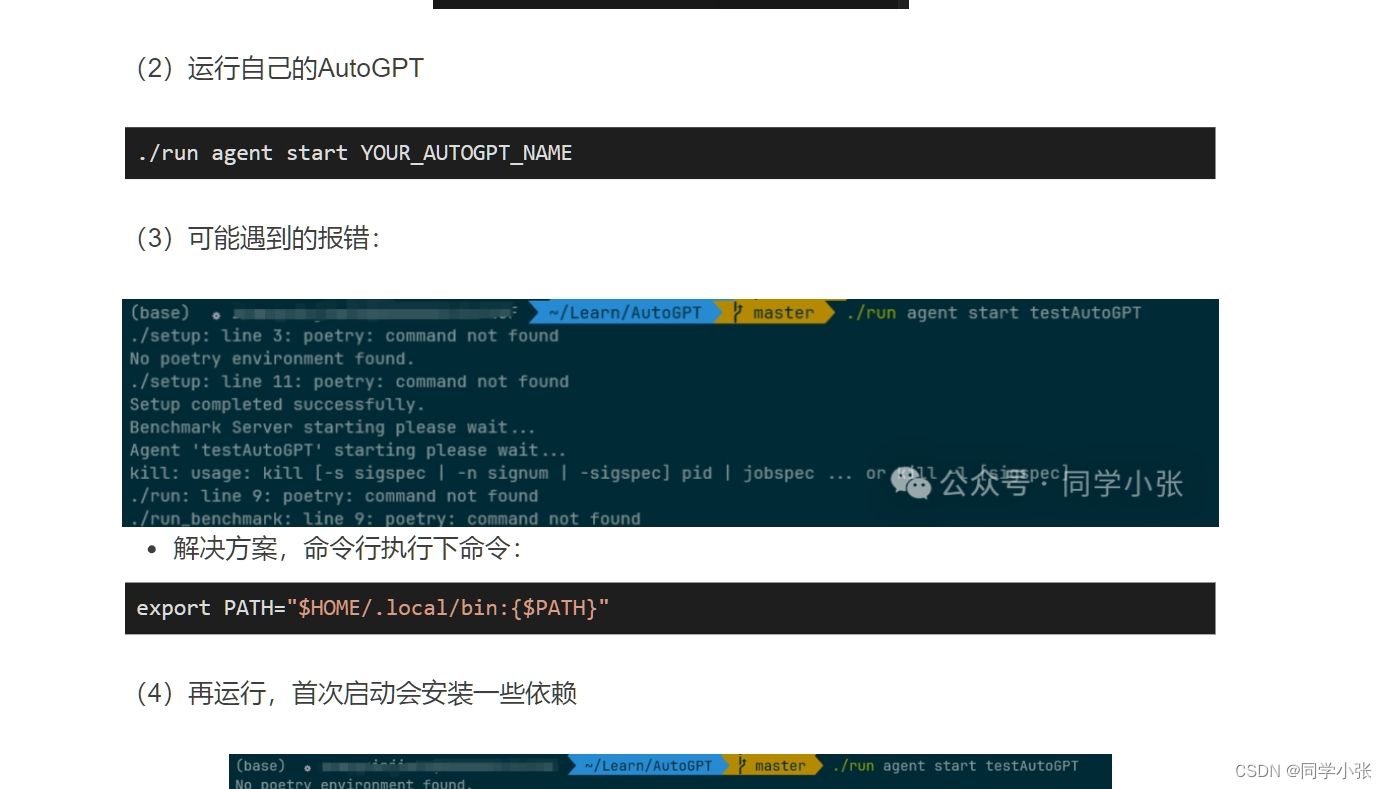
-
错误:TypeError: WebDriver.init() got multiple values for argument ‘options’
-
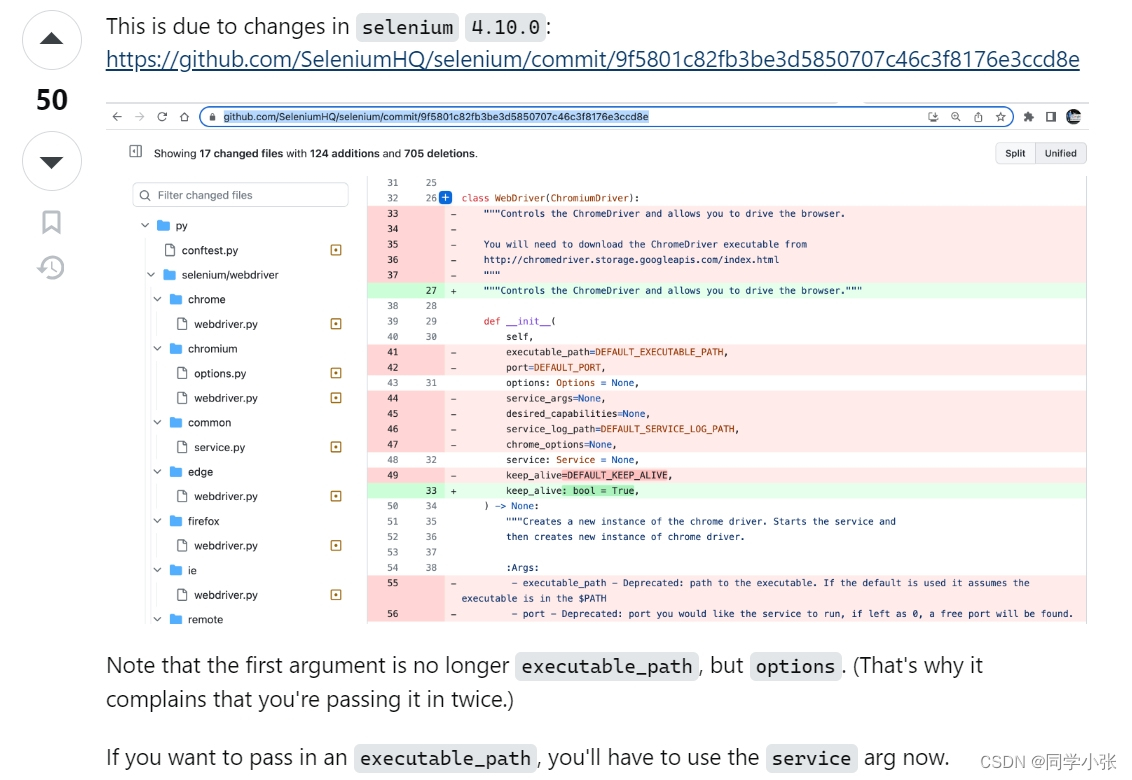
原因:selenium 4.10.0的接口变化导致。
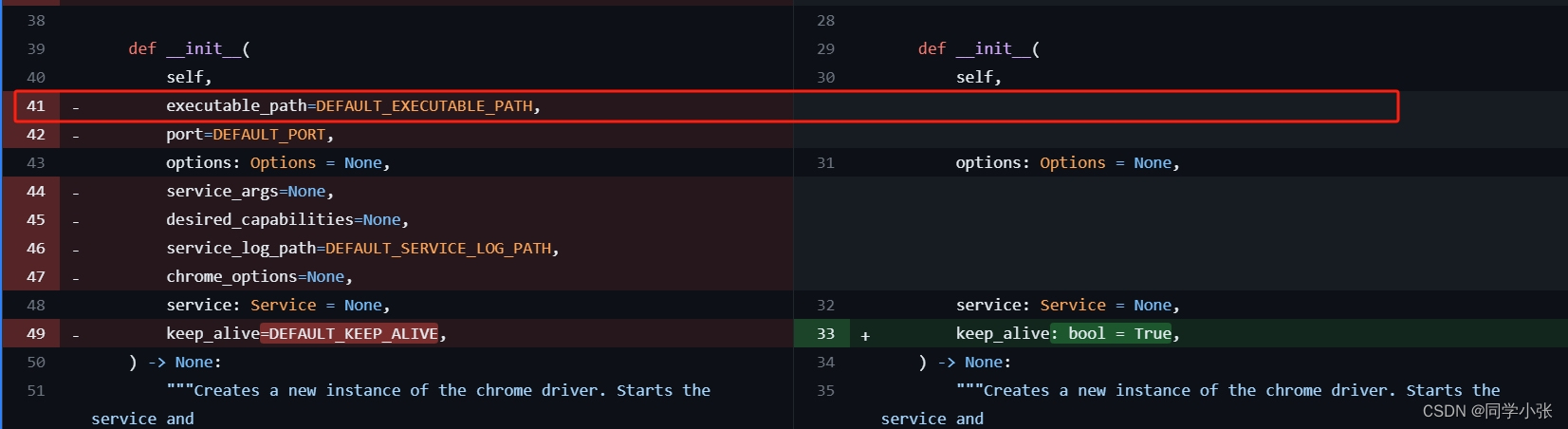
-
解决:
## driver = webdriver.Chrome("./chromedriver", options=chrome_options) # 报错的代码
driver = webdriver.Chrome(options=chrome_options)
- 解决方案来源参考:https://stackoverflow.com/questions/76428561/typeerror-webdriver-init-got-multiple-values-for-argument-options
2. 该工作的意义与用途畅想
本文的代码实现的功能就是将URL背后的网页转换成PDF保存到本地。
可以畅想一下,有了这个功能,我们可以干些什么。最起码,我去探索本文内容的初衷是:
(1)爬取URL背后网页的信息,作为AI大模型RAG应用的知识库。
(2)给应用一个URL,应用自动帮我总结里面的要点,摘要,并且可以进行针对此文档的问答
(3)最基本的数据收集功能,将自己看到的好的文章,URL丢到应用中,自动分类存放。
这只是一点点的作用。
你会用来做什么呢?
如果觉得本文对你有帮助,麻烦点个赞和关注呗 ~~~
- 大家好,我是 同学小张,日常分享AI知识和实战案例
- 欢迎 点赞 + 关注 👏,持续学习,持续干货输出。
- +v: jasper_8017 一起交流💬,一起进步💪。
- 微信公众号也可搜【同学小张】 🙏
本站文章一览: