Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Sora 是一项重大突破,类似于 ChatGPT 在 NLP 领域的影响。Sora 是第一个能够根据人类指令生成长达一分钟视频的模型,同时保持较高的视觉质量和引人注目的视觉连贯性,从第一帧到最后一帧都具有渐进感和视觉连贯性。
PDF: https://arxiv.org/pdf/2402.17177.pdf
1 Sora
在本质上,Sora 是一种具有灵活采样维度的扩散转换器,如下图所示。它包含三个主要部分:(1)时空压缩器首先将原始视频映射到潜在空间。(2)接着,ViT 对标记化的潜在表示进行处理,并输出去噪后的潜在表示。(3)类似于 CLIP 的条件机制接收经过 LLM 增强的用户指令以及可能的视觉提示,引导扩散模型生成具有特定风格或主题的视频。经过多次去噪步骤后,获得生成视频的潜在表示,并通过相应的解码器将其映射回像素空间。
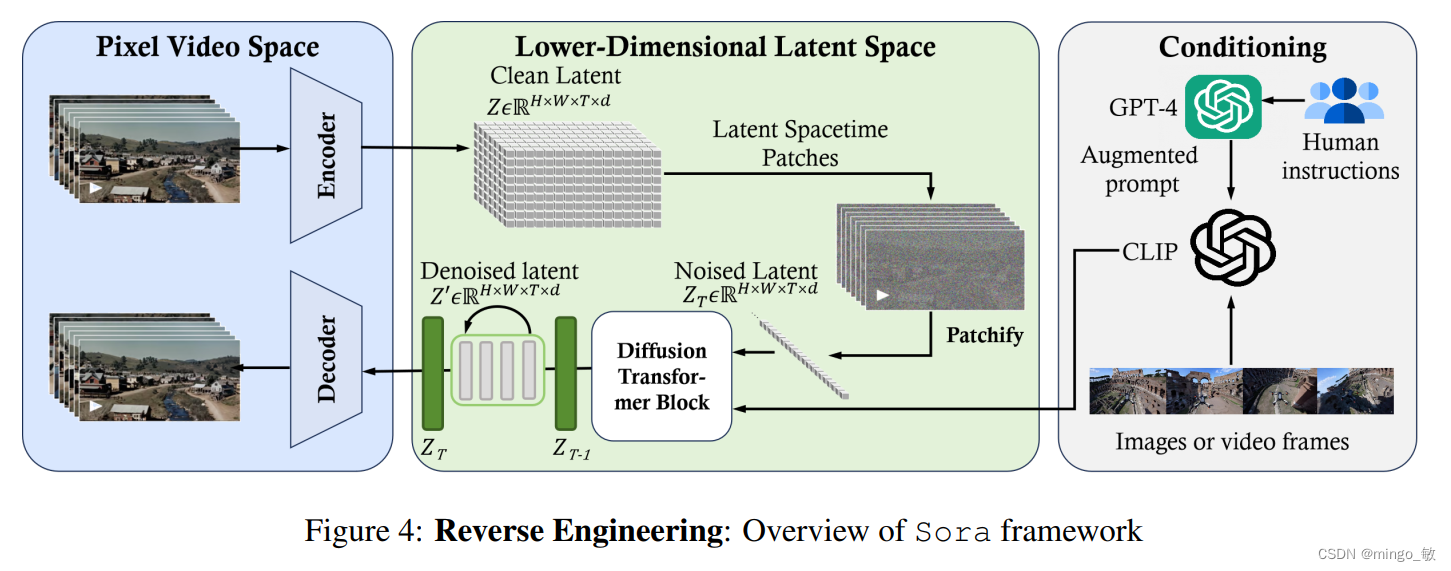
2 数据预处理 Data Pre-processing
2-1 可变时长、分辨率、纵横比 Variable Durations, Resolutions, Aspect Ratios
利用扩散 Transformer 架构,Sora能够训练、理解和生成原始尺寸的视频和图像。而传统方法通常会调整视频大小、裁剪或调整视频的长宽比以适应统一的视频和图像。因此Sora 生成的视频能够更好的展现主题。

2-2 统一视觉表示 Unified Visual Representation
Sora 通过首先将视频压缩到低维潜在空间,然后将表示分解为时空块来将视频进行块化处理。即将所有形式的视觉数据转化为统一的表示形式,这有助于进行大规模生成模型的训练。
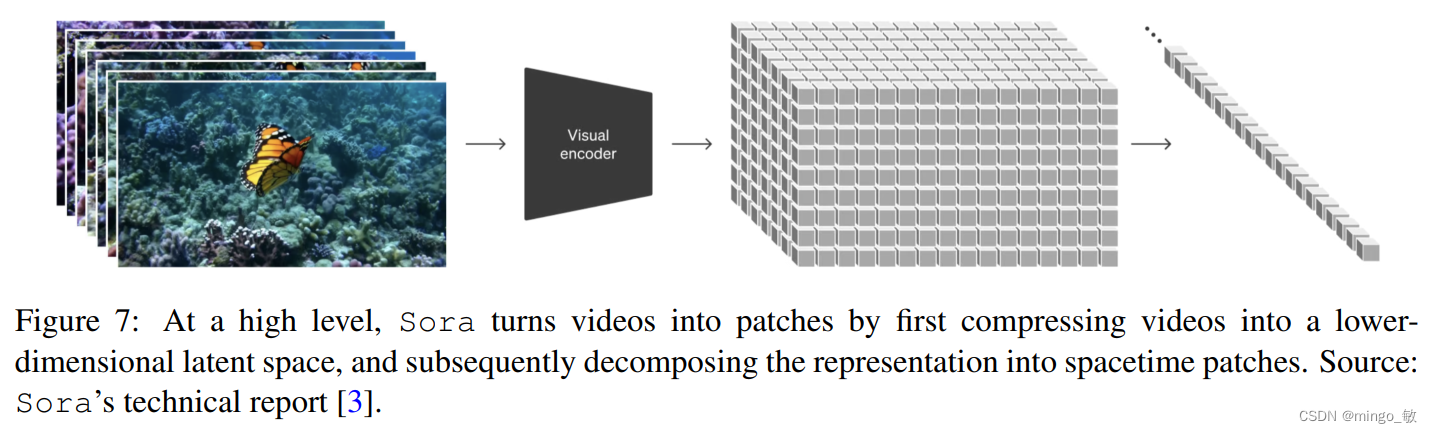
2-3 视频压缩网络 Video Compression Network
Sora 的视频压缩网络(或视觉编码器)旨在降低输入数据(尤其是原始视频)的维度,并输出在时间和空间上压缩过的潜在表示。Sora 压缩网络是基于 VAE 或 VQ-VAE 技术的,但是不对视频和图像调整大小和裁剪。因此Sora可能使用Spatial-patch Compression或者Spatial-temporal-patch Compression,将任何大小的视觉数据映射到统一且固定大小的潜在空间
**Spatial-patch Compression 空间patch压缩:**类似于 ViT 和 MAE 中常用的方法,将视频帧转换为固定大小的 patch,然后将其编码到潜在空间中,这种方法对于适应不同分辨率和宽高比的视频特别有效。随后,将这些空间 token 按时间序列组织在一起,以创建时间 - 空间潜在表征。

**Spatial-temporal-patch Compression 时间-空间patch压缩:**通过3D卷积捕获帧之间的运动和变化,超越了仅分析静态帧的局限,从而捕捉视频的动态特性。
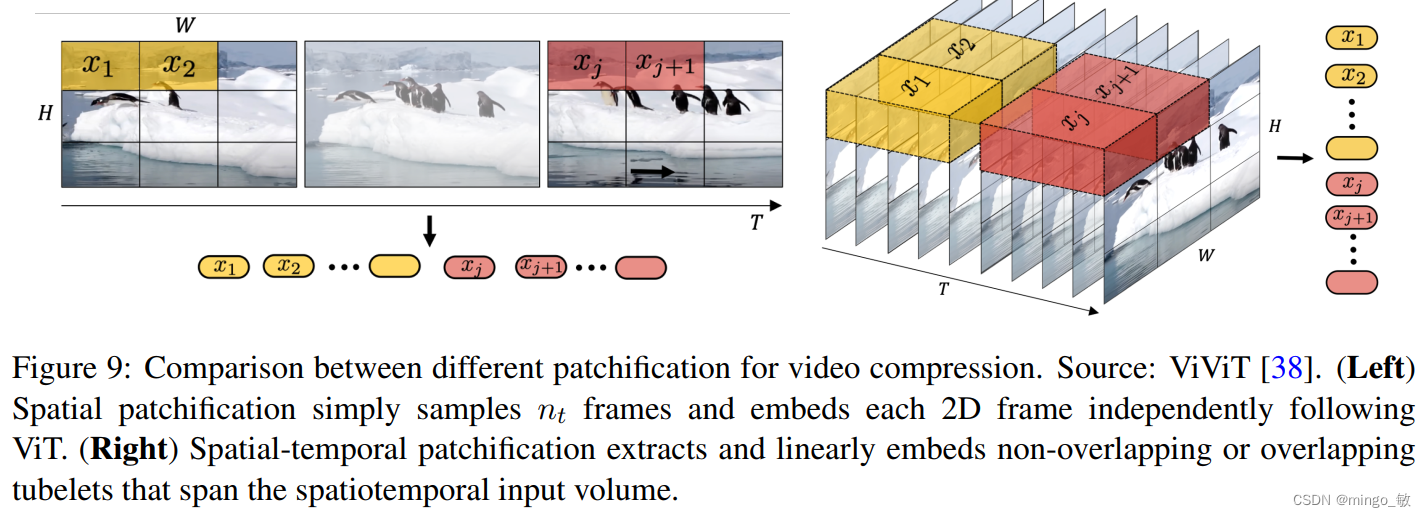
2-4 Spacetime Latent Patches
在将 patch 送入扩散 Transformer 的输入层之前,如何处理潜在空间维度的变化(即不同视频类型的潜在特征块或 patch 的数量)。
patch n’ pack (PNP)将来自不同图像的多个 patch 打包在一个序列中,通过丢弃 token 来实现对不同长度输入的高效训练。在这里,patch 化和 token 嵌入步骤需要在压缩网络中完成,但 Sora 可能会像 Diffusion Transformer(扩散 Transformer)那样,为 Transformer token 进一步 patch 化。
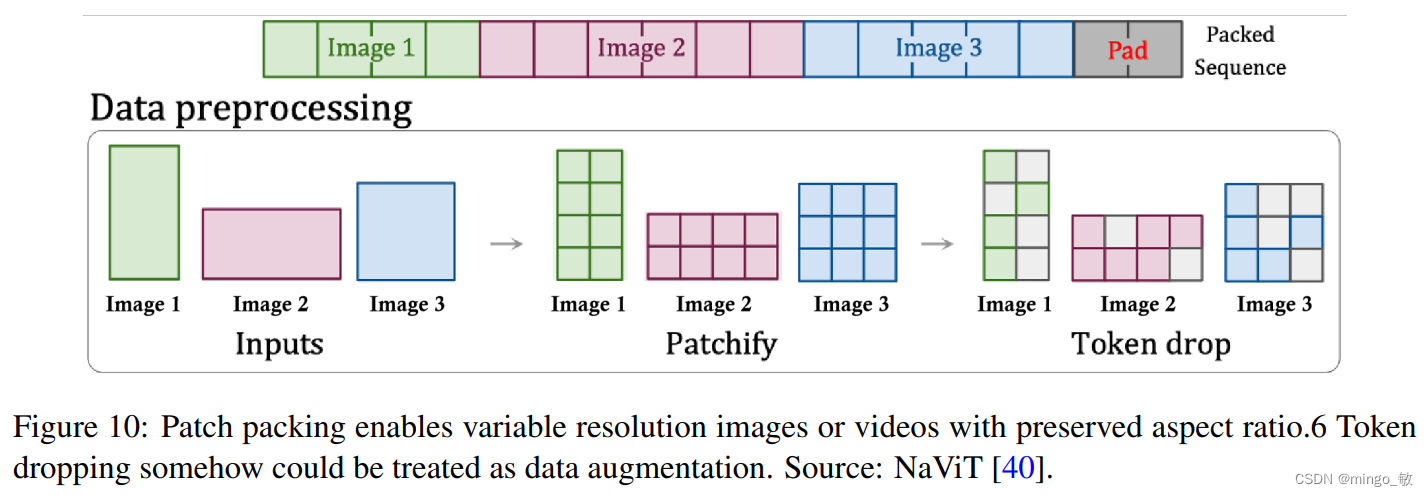
但是在训练过程中,丢弃 token 可能会忽略细粒度的细节。因此 OpenAI很可能会使用一个超长的上下文窗口,并将视频中的所有标记打包在一起。具体来说,来自长时间视频的时空潜在块可以打包到一个序列中,而来自几个短时间视频的块则会被连接起来。
3 Diffusion Transformer
3-1 Image Diffusion Transformer
传统的扩散模型主要利用包含下采样和上采样块的卷积 U-Net 作为去噪网络骨干。然而最近的研究表明,U-Net 架构对扩散模型的良好性能并非不是很重要。通过采用更灵活的 Transformer 架构,基于 Transformer 的扩散模型可以使用更多的训练数据和更大的模型参数。
DiT 采用多头自注意力层和层范数和缩放层交错的逐点前馈网络。此外,DiT 还通过 AdaLN 进行调节,并增加了一个用于零初始化的 MLP 层,将每个残差块初始化为一个恒等函数,从而大大稳定了训练过程。
U-ViT 将包括时间、条件和噪声图像片段在内的所有输入都视为 token,并在浅层和深层 Transformer 层之间提出了长跳跃连接。
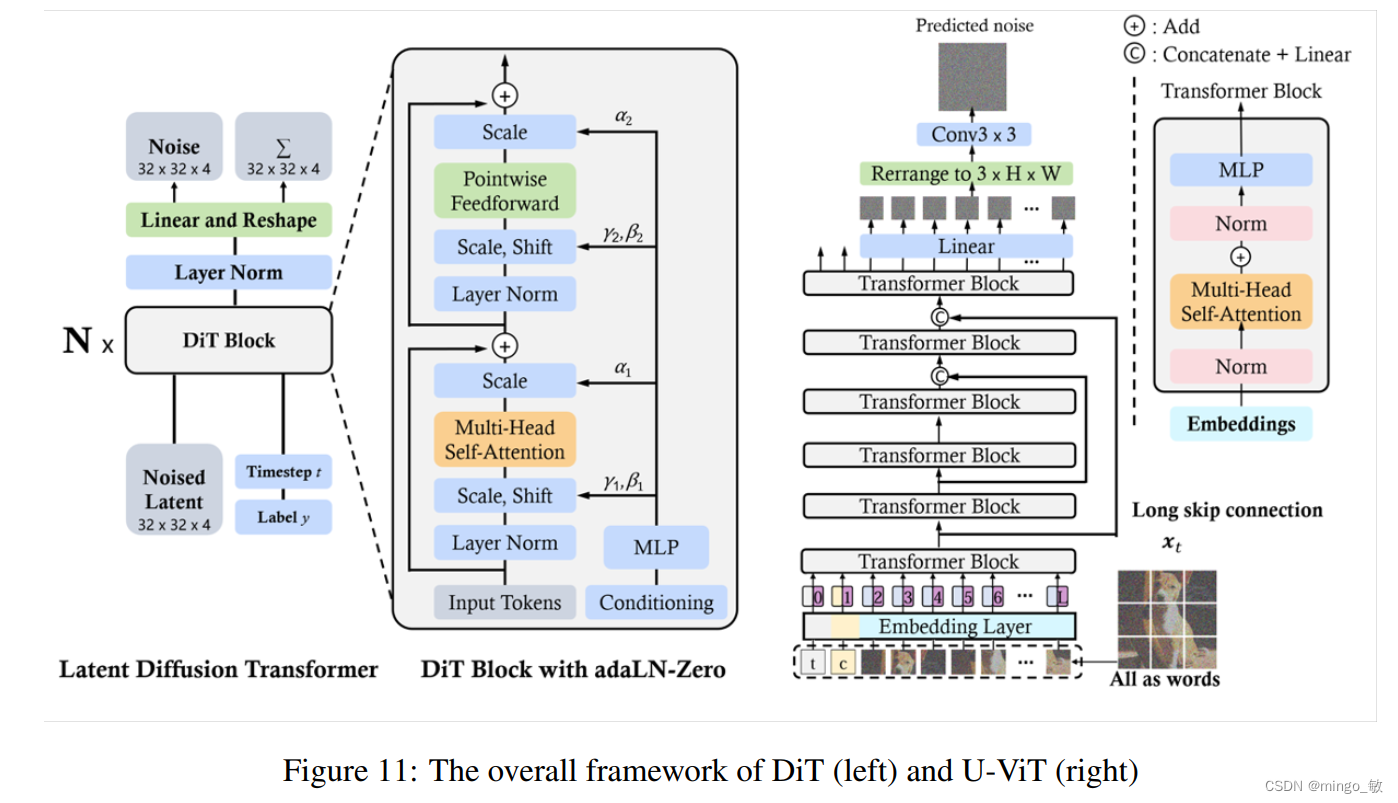
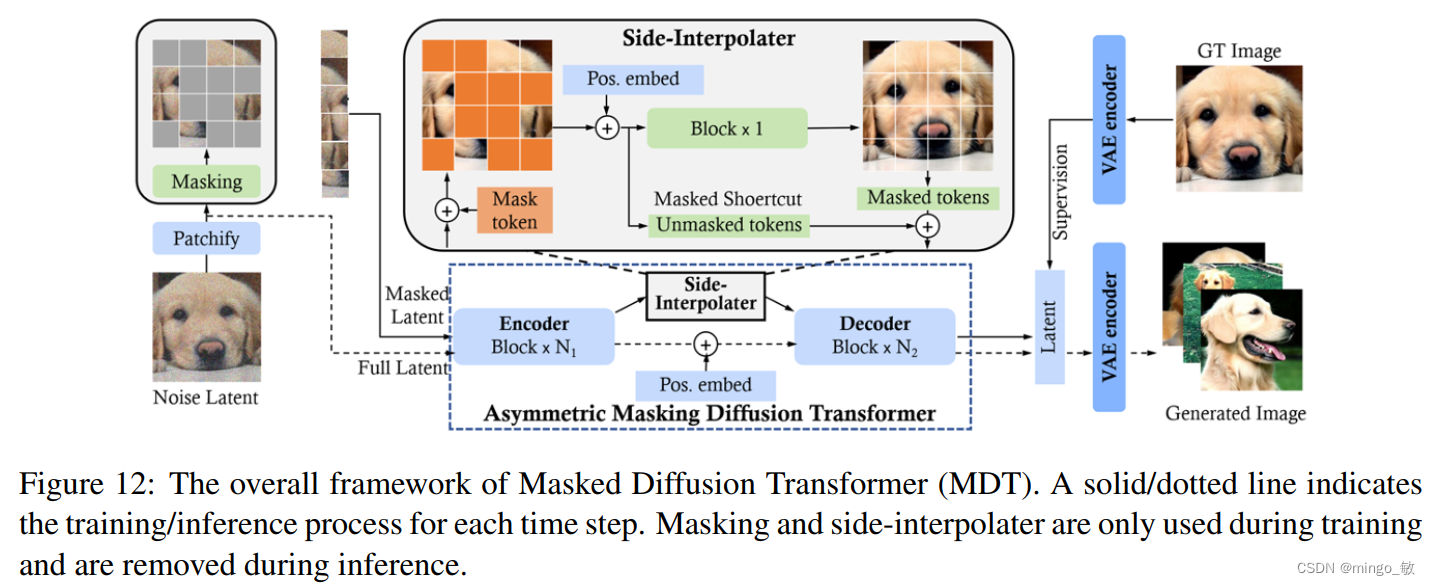
MDT 在训练过程中使用边缘插值(side-interpolated)进行额外的掩蔽 token 重建任务,以提高训练效率,同时加入掩码潜在模型,以明确增强图像合成中对象语义部分之间的上下文关系学习。与 DiT 相比,MDT 实现了更好的性能和更快的学习速度。
3-2 Video Diffusion Transformer
在视频领域应用DiT的主要挑战包括:i) 如何有效压缩视频至潜在空间以高效去噪;ii) 如何将压缩后的潜在空间转换为patches并输入Transformer;iii) 如何处理长序列的时空依赖性并保持内容一致性。
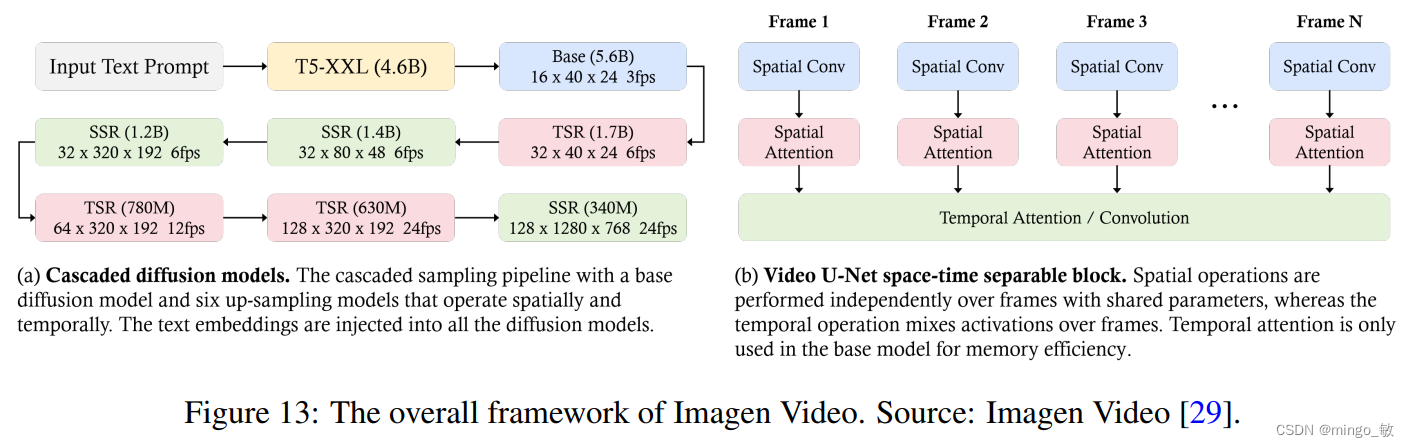
Imagen Video 利用级联扩散模型(由 7 个子模型组成,分别执行文本条件视频生成、空间超分辨率和时间超分辨率)将文本提示转化为高清视频。
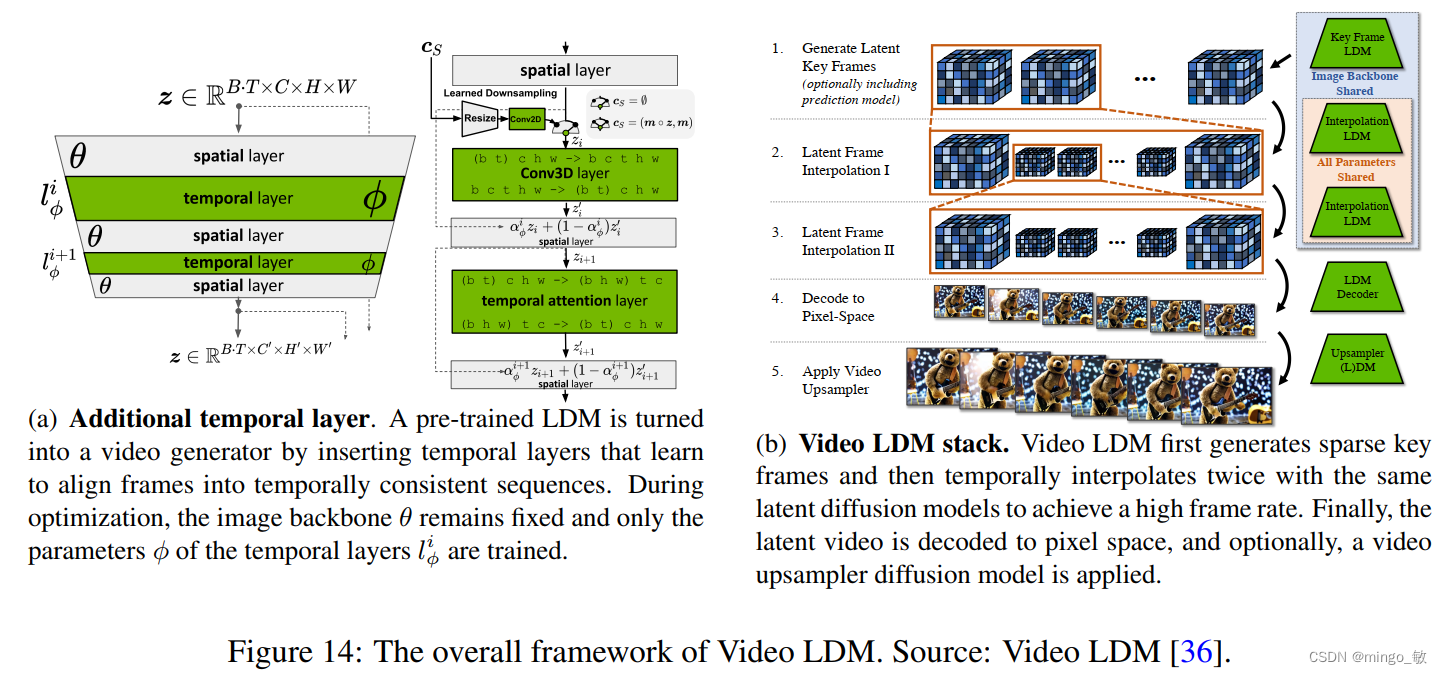
Video LDM在 U-Net 主干网和 VAE 解码器的现有空间层中添加了一些临时时间层,以学习如何对齐单个帧。这些时间层在编码视频数据上进行训练,而空间层则保持固定,从而使模型能够利用大型图像数据集进行预训练。
4 语言指令跟随 Language Instruction Following
用户主要通过自然语言指令与生成式AI模型进行交互,这些指令被称为text prompts。模型指令调优旨在增强AI模型准确遵循提示的能力。这种在遵循提示方面的改进能力,使模型能够生成更接近人类对自然语言查询的响应的输出。
4-1 Large Language Models
遵循指令使LLMs能够读取、理解并恰当响应描述未见过任务的指令,无需依赖示例。通过针对一系列以指令形式呈现的任务进行微调,LLMs可以增强遵循指令的能力,这一过程被称为指令调优。
4-2 Text-to-Image
DALL·E 3 采用了创新的标题改进方法来优化指令遵循,这一方法基于一个核心观点:模型训练的文本-图像对质量直接决定了其生成文本对应图像的性能。然而,数据质量参差不齐,特别是充斥着噪声数据以及缺少关键视觉信息的简短标题,这些问题经常导致模型在生成图像时忽略关键词、词序混乱,甚至误解用户意图。
为了解决这些挑战,标题改进方法采用了一种策略:为现有图像重新添加详细且描述性强的标题。该方法的核心在于训练一个图像标题生成器,这是一个视觉与语言融合的高级模型,能够生成精确且富含细节的图像标题。随后,这些精心生成的描述性标题被用来对文本到图像模型进行微调,以提升其生成图像的质量和准确性。
通过这一方法,DALL·E 3 在文本到图像的转换过程中,不仅确保了图像与文本的高度一致性,还显著提升了模型对用户意图的捕捉能力,为用户带来了更加精准和个性化的图像生成体验。
4-3 Text-to-Video
为了进一步提升遵循指令的能力,Sora采纳了与DALL·E 3类似的标题改进策略。该方法的核心在于精心训练一个视频标题生成器,这个生成器拥有卓越的能力,能够为视频提供详尽且精准的描述。随后,这个先进的视频标题生成器被全面应用于训练数据集中的每一个视频,生成出大量高质量的(视频,描述性标题)配对数据。这些配对数据不仅丰富多样,而且质量上乘,它们被用来对Sora进行精细的调整和优化,从而显著增强其遵循指令的精准度和效率。通过这一创新方法,Sora不仅提升了其文本到视频的转换能力,更在理解和实现用户意图方面迈出了坚实的一步。
5 提示工程 Prompt Engineering
提示工程是指为AI系统设计并优化输入的过程,以实现特定或优化的输出。提示工程以引导模型产生尽可能准确、相关和连贯的响应的方式,精心打造这些输入。
5-1 Text Prompt
文本提示工程在指导文本视频模型制作出既具有视觉冲击力又能精确满足用户规格的视频方面发挥着至关重要的作用。为了弥合人类创造力与人工智能执行能力之间的鸿沟,这一工程需要精心制作详细的描述,以有效指导模型,确保生成的视频既符合用户期望又具有高度的视觉吸引力。

5-2 Image Prompt
图像提示为即将生成的视频内容以及其他元素(如角色、场景和氛围)提供了视觉上的依托。此外,文本提示可以指导模型对这些元素进行动画处理,例如通过添加动作层次、互动和叙事进展,使静态图像生动起来。通过使用图像提示,Sora能够利用视觉和文本信息,将静态图像转化为动态、叙事驱动的视频。
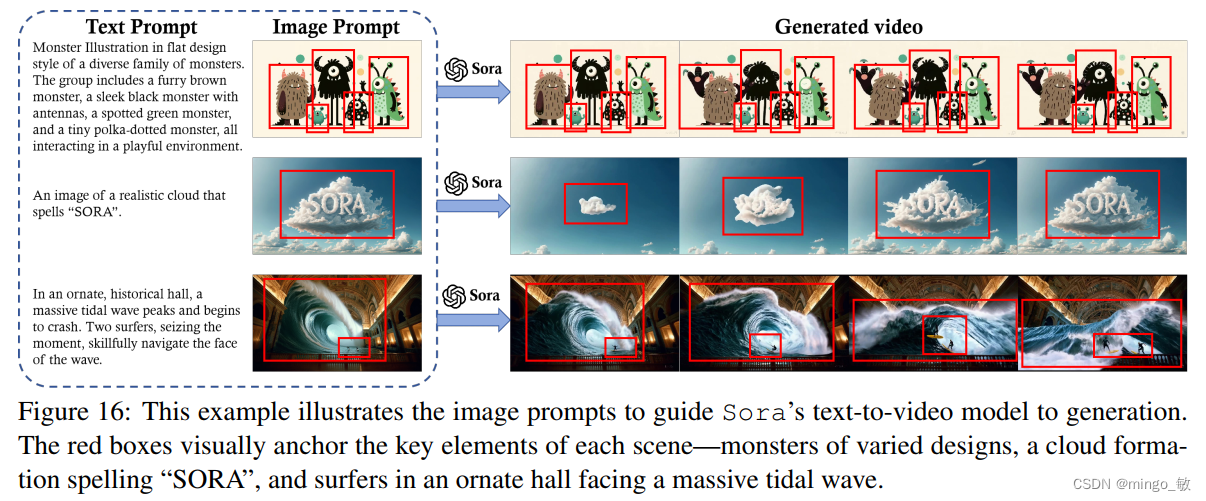
5-3 Video Prompt
优质的视频提示需要兼具明确性和灵活性。这既确保了模型能够接收到关于特定目标(如特定物体和视觉主题的呈现)的清晰指引,又允许最终输出中充满富有想象力的变化。
