AI Benchmark测试原理、v4测试项变化以及榜单数据解读
田海立@csdn 2020-10-3
AI Benchmark这里特指ETHZ(苏黎世联邦理工学院)的AI性能评测工具。最新其发布了v4版本以及基于这个版本的soc和手机AI性能数据。本文分析了AI Benchmark测试的原理,v4版本的变化,以及榜单头部海思麒麟990 5G与MTK天玑1000+的对比。据此也就能解读AI-Benchmark榜单上各个数据的含义了。
我尽量用公开的技术和客观的数据来说话,不用非公开渠道获得的信息,仅代表个人观点,不代表所服务公司态度。但有涉密或不可公开信息,会及时删除。
一、AI Benchmark测试相关
1. 移动端侧AI推理的碎片化
AI的发展,先是有了各家设备的私有实现,然后才有AndroidNN试图统一Android平台上端侧的推理框架。所以AI性能评测工具也就有了安兔兔、鲁大师的基于soc厂商私有sdk的实现,也就有了ETHZ基于AndroidNN的实现。安兔兔、鲁大师等起个大早赶了个晚集,AI评测领域并没有多大声音;而各soc厂商(高通、华为、MTK、紫光展锐...)却不断拿AI Benchmark说事,发布新芯片时宣传其AI性能。
2. AI Benchmark测试原理
AI Benchmark是基于AndroidNN的,所以讲AI Benchmark的原理离不开AndroidNN。先看一下,AndroidNN的框架:
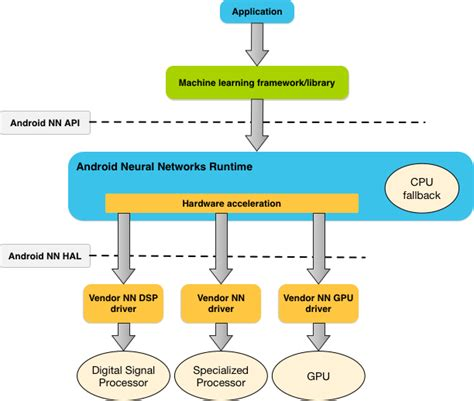
上层通过NNAPI提供API给上层使用,注意这里的API还是比较lower level的,对于不是关注AI实现的开发者来说不是很友好的。Android NN在诞生之初就不是提供给最终应用开发者的,更上层是推荐TensorFlow Lite这样的基于Model级别的ML框架的。
NN HAL定义一层NN device的抽象层,屏蔽细节,只要DSP/GPU/NPU基于NN HAL实现,NN Runtime就能基于其能力(Capabilities)来调度使用。
所以,AI Benchmark在这个生态链里,也就是应用层的概念,只是TFLite因为晚于AndroidNN集成于Android,所以TFLite是直接被打包于AI Benchmark的apk里的。
AI性能除了运行时间之外,基于数据集的精度也是一个很重要的指标。试想如果一个NN Device跑的是很快,但是丢失关键的数据结果都不对,那快又如何。所以,AI Benchmark里集成了很多的TFLite模型来分别测试CPU/INT8/FP16/FP32/INIT数据;还内置数据集测试特定测试项来评估精度数据。
二、AI Benchmark v4更新
前面说了v3之前的测试项,当然这也是一个变化的过程,比如性能测试是v3才加入的。
今年5月31号,AI Benchmark官方网站上公布了v4版本的变化,这里简要总结一下:
1. TFLite delegates
因为最近TFLite的变化,对Device利用Delegate机制直接做了支持,这些包括github里GPU的直接支持,也与Qualcomm合作实现了Hexagon的支持(与Samsung的合作未在TensorFlow官方发布,但AI Benchmark那里应该拿到了Samsung提供的Delegate支持)。
所以,v4版本里Qualcomm与Samsung的TFLite Delegate支持直接集成到了apk里,这两家的手机直接通过TFLite Delegate支持。
2. NNAPI-1.2
v3版本的时候,NNAPI-1.2还没正式发布,所以v3版本之前不会有NN1.2的特性。在V4版本里,针对NNAPI设计了case。
3. 并行执行
NNAPI可以看到可以有多个NN Device,这些Device是可以并行执行的。当然这里的并行也可以是不同数据类型的模型的支持。这里也有了很好的设计与实现。
4. 评分系统
这里数据集与测试模型以及测试项都有了变化,所以评分系统也有相应的变化。
不过这里,并没有详细列举测试项以及对应比值,而v3版本在其paper里是有详细描述评分标准里各个测试项所占的比重的。这里可以期待其在最新paper里公开,也或许可能不对大众开放了,仅对其合作伙伴开放。
三、AI Benchmark v4测试数据简要解读
AI Benchmark网站上已经发布了v4的性能数据,移动端数据包括了phone数据与soc数据。
Phone数据里采用同一soc的厂家差别都不大,所以手机厂商所做的努力有限,基本还是由soc来决定。但phone厂家的这点微小的差异也反应了各家的实力。
这里来看soc榜单
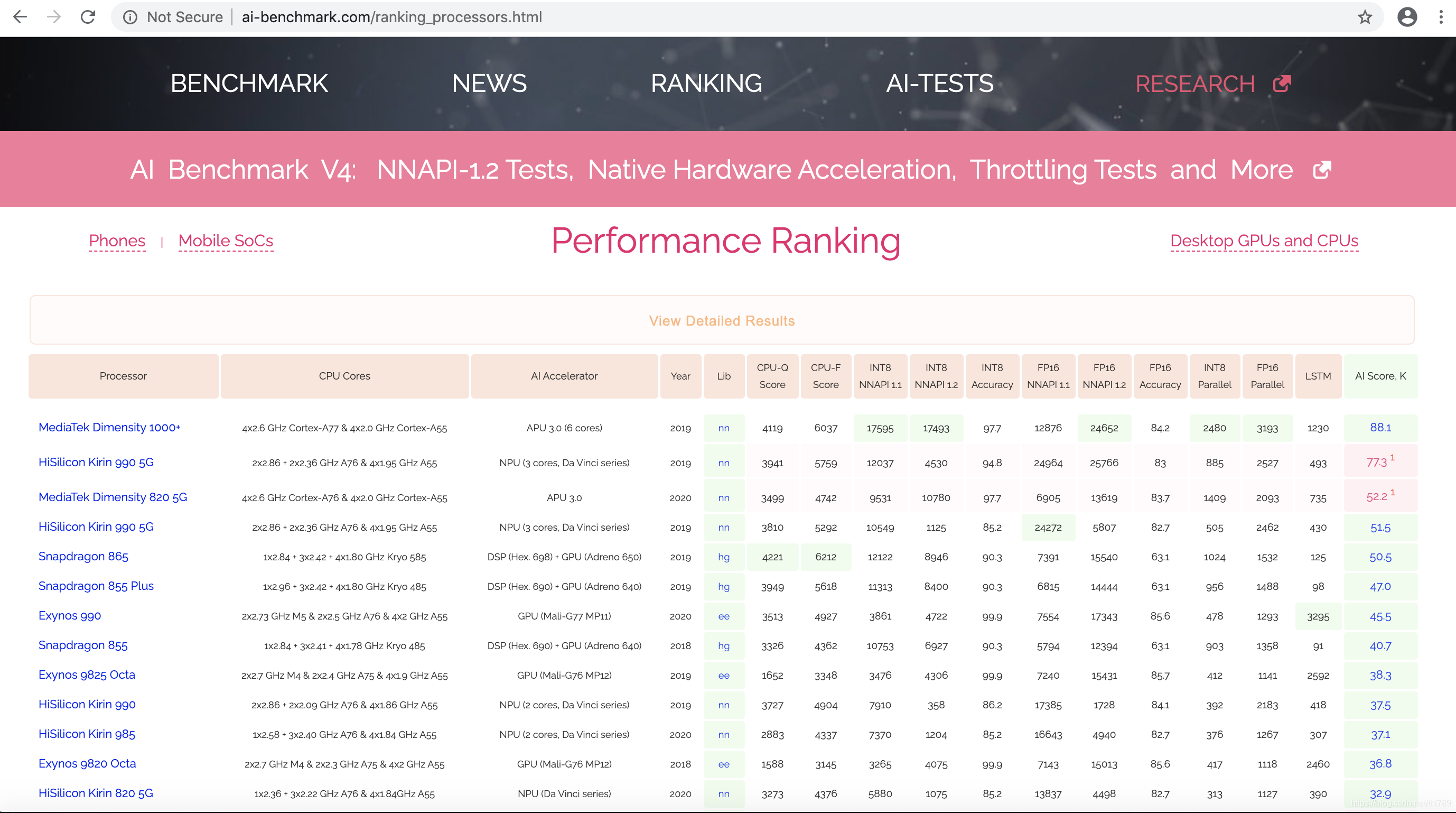
1. 执行设备
MTK/海思使用的NN device,也就是TFLite -> NNAPI -> NNHAL到NN Device这一同之前版本一样的路径;
而Qualcomm对quantized走的是Hexagon Delegate;FP类型走的是GPU Delegate。Samsung的Quantized与FP类型走的都是其Eden Delegate。
当然没有NN设备的终端,直接走的是TFLite / NNRuntime的CPU实现。
2. 类别支持的差异
分析一下头部MTK天玑1000+与海思990 5G的差异(这里只大致从官方数据分析,更详细的也不便再公开分析,再说真有这数据也不能随便给你了)
记得v3最后版本的时候,海思990 5G应该是遥遥领先,但这个版本MTK天玑1000+却领先这么多。(可惜v3版本的结果没有截图,如果你有数据,麻烦给个链接)
海思990 5G对FP16做了很好的支持,而v3之前的版本FP16评分中占的比重较大,所以990 5G芯片领先于其他家。反观现在这个榜单:
CPU数据,海思990 5G略低于MTK天玑1000+,这CPU架构决定,厂家能做的有限;
量化数据,NNAPI1.1,海思990 5G略低于MTK天玑1000+,正常情况;
量化数据,NNAPI1.2,海思990 5G远低于MTK天玑1000+,这说明了对新NNAPI的支持,海思做的比起MTK很差,或根本没做支持;(感兴趣的读者,有他们家手机可以自己抓数据分析一下)
FP16数据,NNAPI1.1,海思990 5G虽然远高于MTK天玑1000+(近两倍,24964 vs 12876);而NN1.2,海思990 5G却仅与MTK天玑1000+相当,真的是NN1.2没做升级支持啊。
LSTM/RNN,MTK天玑1000+也做了更好的支持。
结语
本文简要分析AI Benchmark测试的原理,v4版本的变化,以及榜单头部海思990 5G与MTK天玑1000+的对比。
当然了,这个榜单高也并不能说明问题的全部,比如海思990 5G位置在v3/v4榜单的变化也说明了这类榜单并不能反应AI能力的全部。真正注重用户体验,场景做得好的话,也就不用靠这个榜单来说话了。
而这里评分标准的变化也反应了产业界对量化与浮点模型支持的趋势,虽然AI Benchmark算是学院派做的,但这一趋势反应的是产业的变化。AI趋势的引导甚至是产业界领先于学术界,谁做的好,占据了产业生态主导谁就掌握了话语权。
参考资源
1. AI Benchmark:All about Deep Learning on Smartphones
4. AI Benchmark v4: Pushing Mobile NPUs to Their Limits
6. AI tests