从零开始:调用MapReduce进行单词的词频统计
相信大家在复习英语相关考试时,都会很关注也很想知道试题中出现频率较高的单词是哪些从而提高复习的命中率对吧?今天我就告诉大家一个方法,使用MapReduce对指定文本进行单词的词频统计。那接下来我就带领大家从零开始一步步搭建环境,到最后的结果呈现,Let's go!
前置环境:
虚拟机Ubuntu系统
首先第一步要做的是Hadoop的生态安装:
1.在Oracle VM VirtualBox安转Ubuntu linux系统
2. 安装SSH、配置SSH无密码登陆
2.1因为ubuntu默认已经安装SSH client,所以只需安装SSH server: 命令:Sudo apt-get install openssh-server

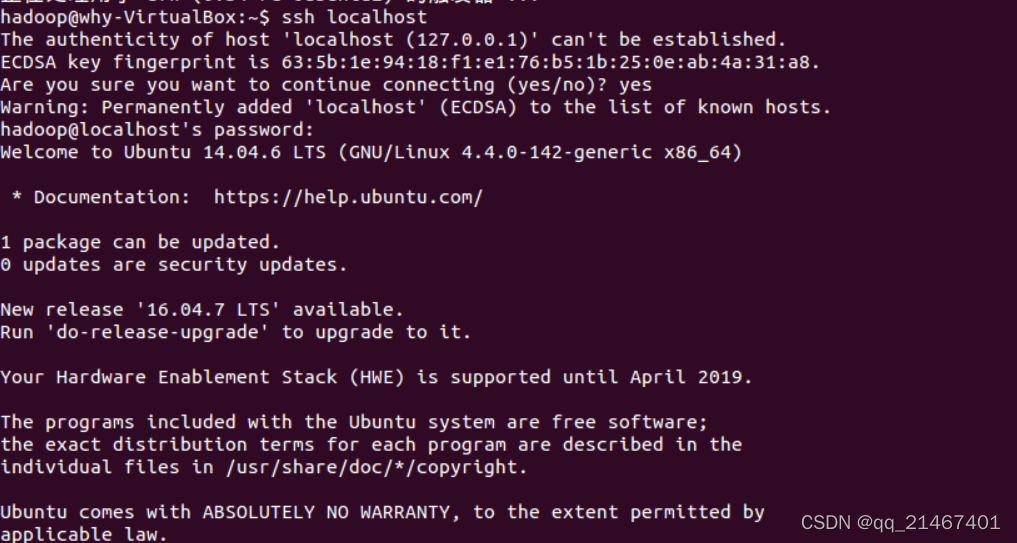
2.2安装SSH服务后使用ssh localhost命令登陆本机
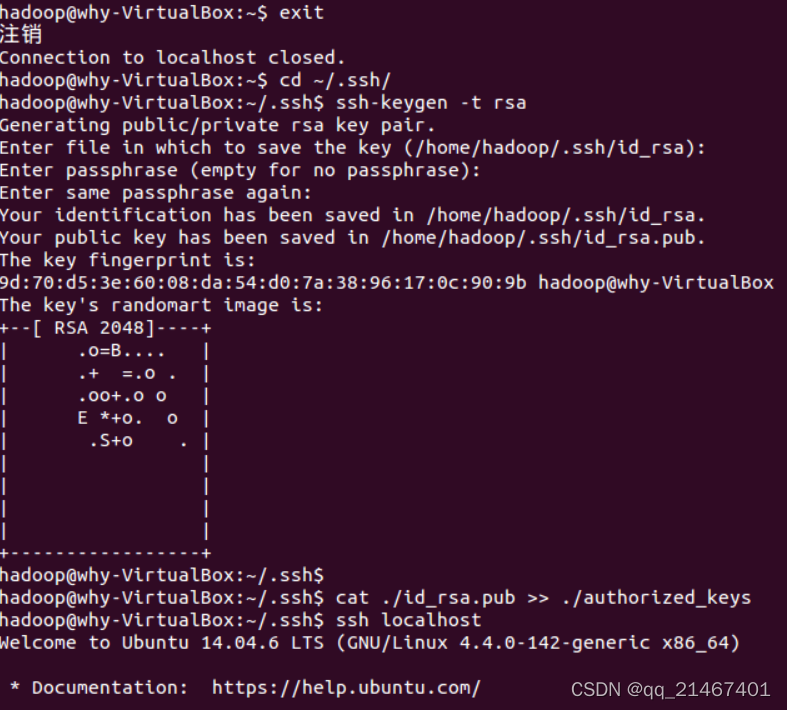
2.3 为了方便不用每次登陆SSH都需要密码,所以就将其配置成无密登陆。首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen 生成密钥,并将密钥加入到授权中
之后再次使用localhost命令登陆则无需输入密码

3. 安装Java环境
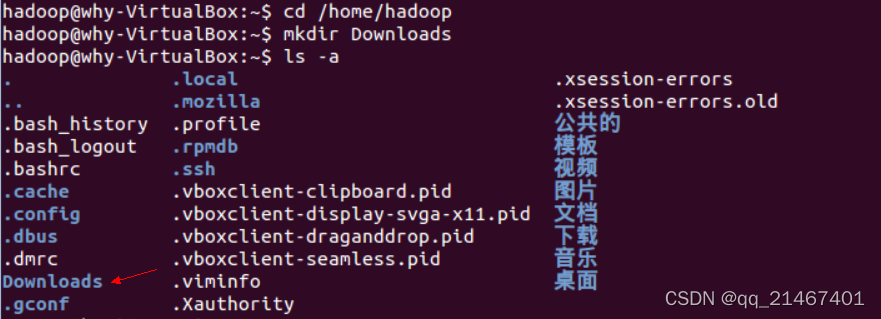
首先在ubuntu的hadoop用户下创建一个Downloads的文件夹用于存放JDK的压缩包
JDK文件使用FileZilla传输到虚拟机Ubuntu里刚创建的Downloads文件夹下
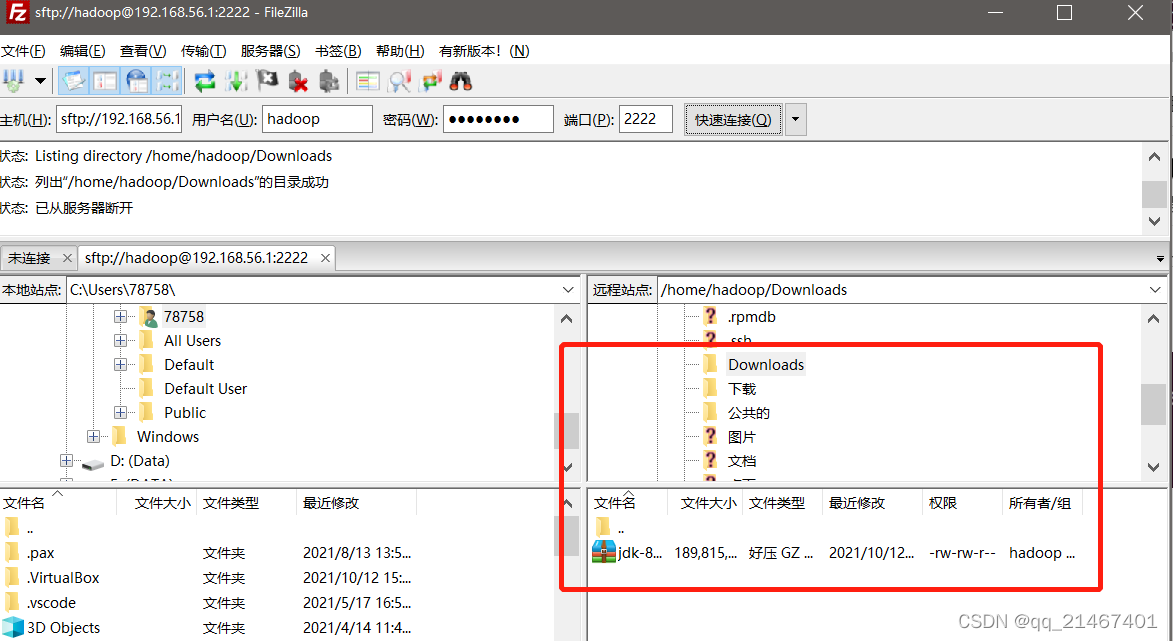

然后接着创建在/usr/lib目录下创建一个jvm的文件夹,将刚才Downloads目录里的JDK压缩包解压到jvm目录下
JDK文件解压后使用cd /usr/lib/jvm进入jvm的目录,再ls命令查看一下解压后的情况

接着使用vim编辑器将以下内容添加到hadoop用户的环境变量配置文件中
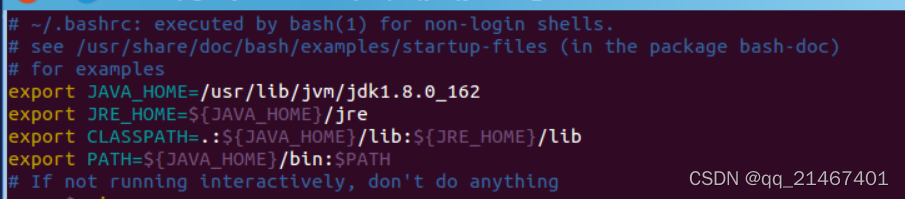
保存.bashrc文件并退出vim编辑器。然后,继续执行source ~/.bashrc命令让配置生效,之后使用java -version命令查看是否成功安装

4. 安装Hadoop 2
首先通过FileZilla把Hadoop文件传输到Ubuntu里hadoop用户下的“Downloads”文件夹目录下
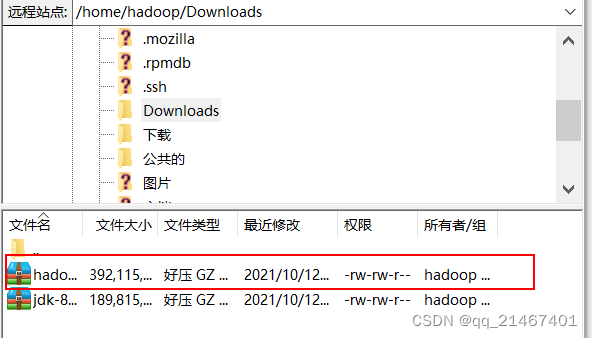
接着将Hadoop解压到/usr/local/里,并查看确认是否解压成功

解压后将文件夹名改为 hadoop 并修改文件权限

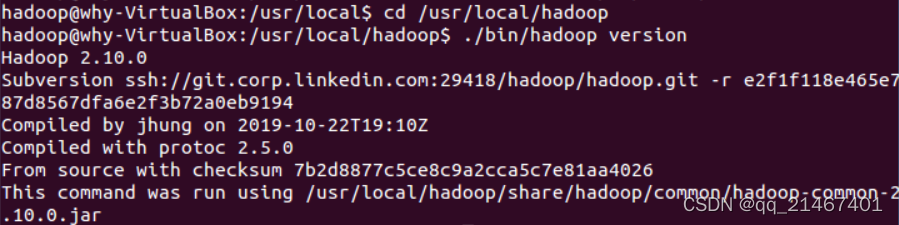
最后输入以下命令检查Hadoop是否可用,可用则会显示hadoop的版本信息
5. Hadoop伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
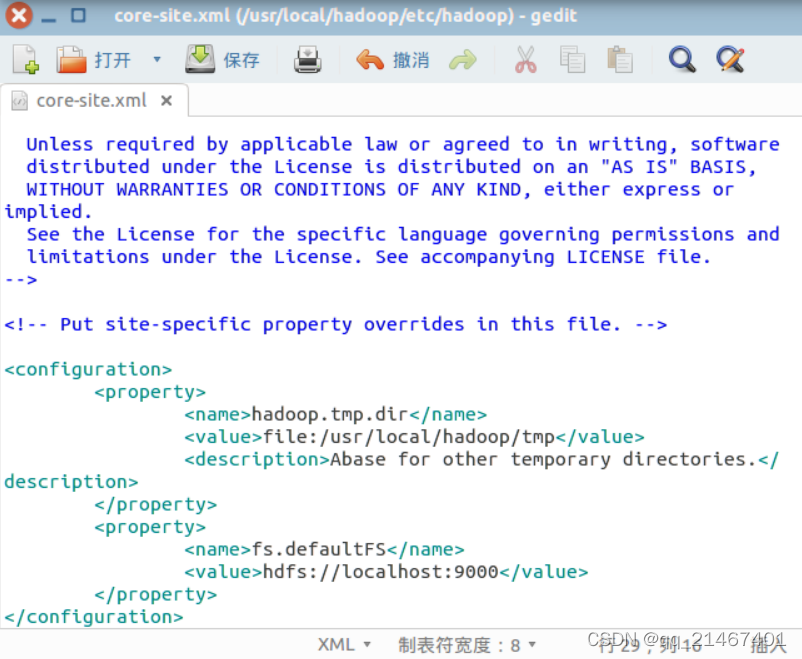
通过 gedit 编辑修改配置文件 core-site.xml
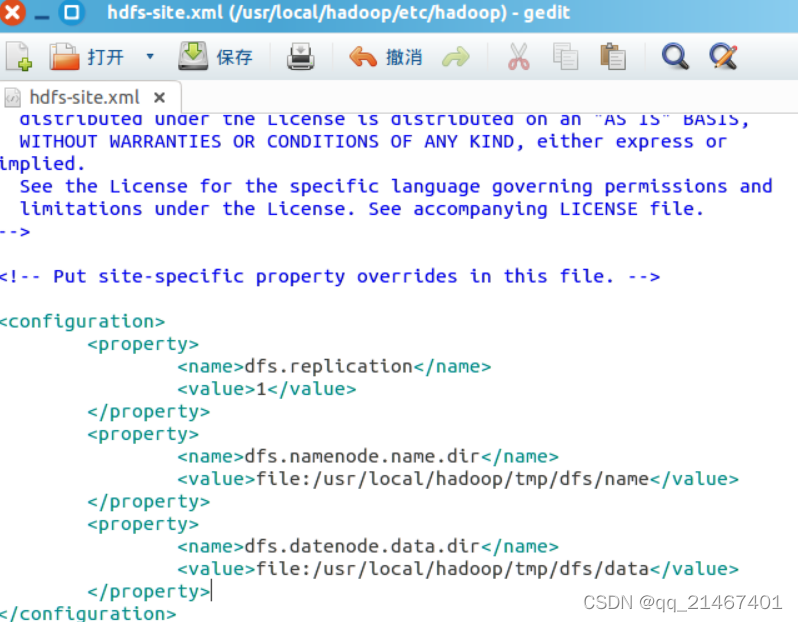
同样通过 gedit 编辑修改配置文件 hdfs-site.xml后保存退出
配置完成后,执行 NameNode 的格式化

完成后开启 NameNode 和 DataNode 守护进程,此刻会出现SSH提示,输入yes即可

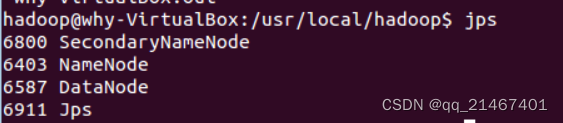
启动完成后通过命令jps来判断是否成功开启,若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”,以下显示表明已经成功开启!!!(如果没有显示“SecondaryNameNode”这一项则需要运行 sbin/stop-dfs.sh 命令关闭进程,然后运行sbin/start-dfs.sh命令重启尝试)
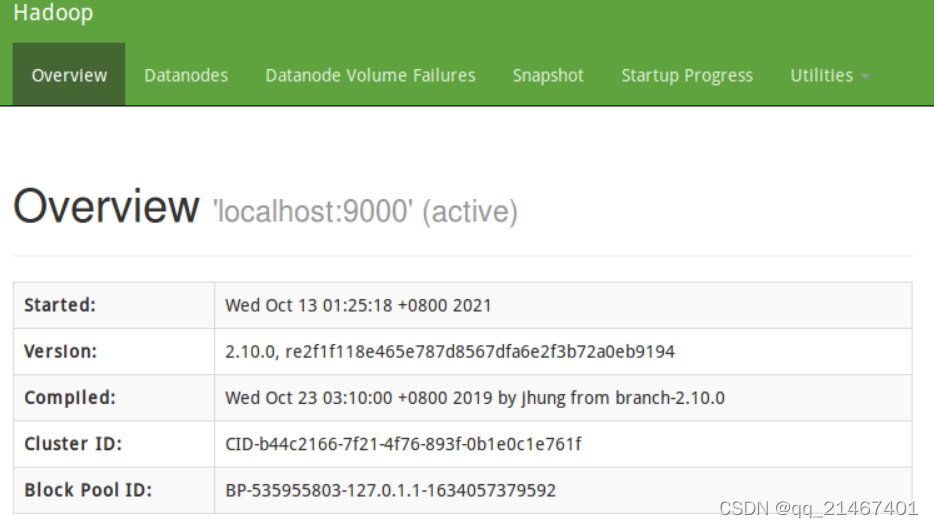
成功启动后打开浏览器在地址栏输入http://localhost:50070进入Web界面可浏览相关信息以及在线查看HDFS里的文件。
第二步完成JAVA API与HDFS的交互:
1. 在Ubuntu中安装Eclipse
在左侧应用栏打开软件中心并搜索eclipse进行下载应用
下载完成打开运行安装
2. 在Eclipse创建项目
打开安装好的eclipse软件
选择“Project-New Java Project”,开始创建一个Java工程
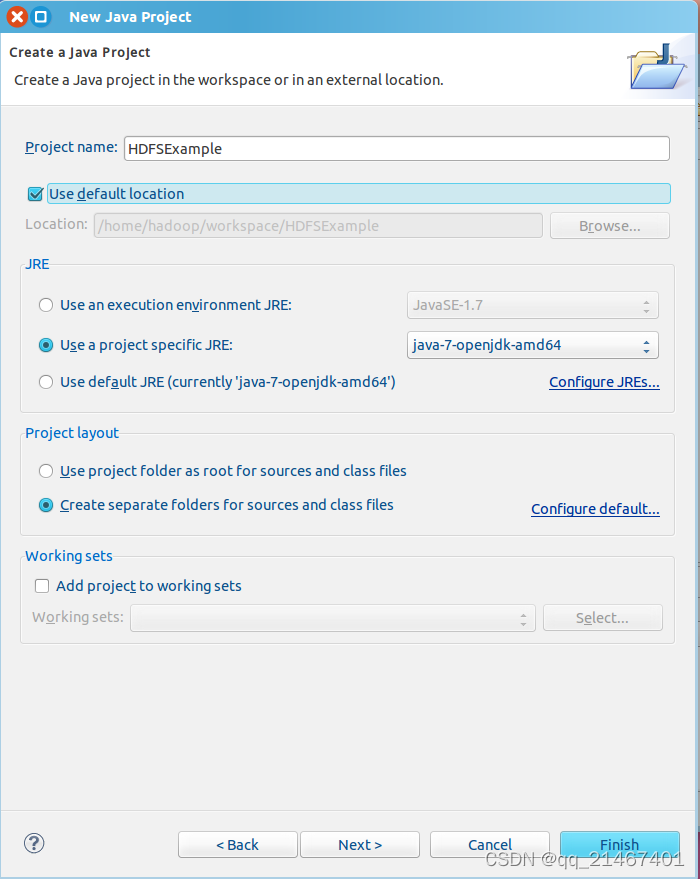
3. 为项目添加需要用到的JAR包
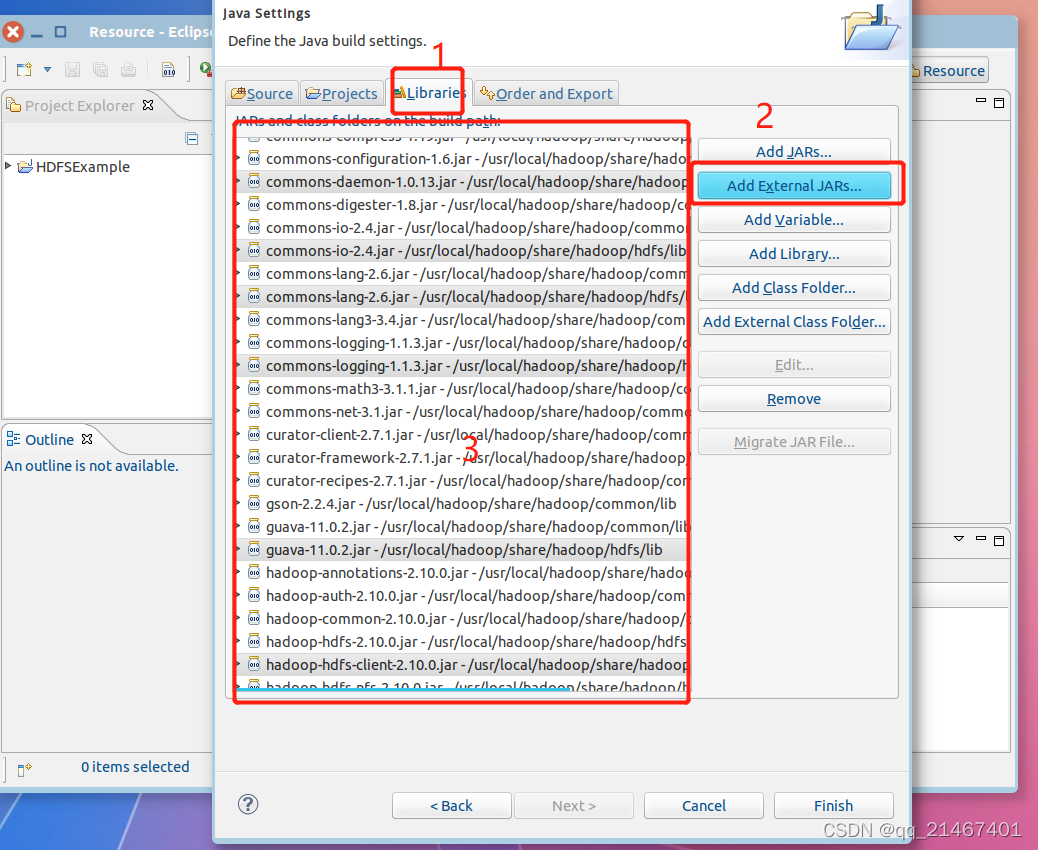
点击next进入下一步,右侧点击Add External JARs..按钮进行选择添加如下所需的JAR包,使其编写一个能够与HDFS交互的Java应用程序
/usr/local/hadoop/share/hadoop/common”目录下hadoop-common-2.10.0.jar和haoop-nfs-2.10.0.jar;
/usr/local/hadoop/share/hadoop/common/lib”目录下的所有JAR包;
/usr/local/hadoop/share/hadoop/hdfs”目录下的haoop-hdfs-2.10.0.jar和haoop-hdfs-nfs-2.10.0.jar;
“/usr/local/hadoop/share/hadoop/hdfs/lib”目录下的所有JAR包
全部选择完成后先检查核对一遍名称和目录是否有遗漏或者选错,无误后再点击Finish完成
4. 编写Java应用程序代码
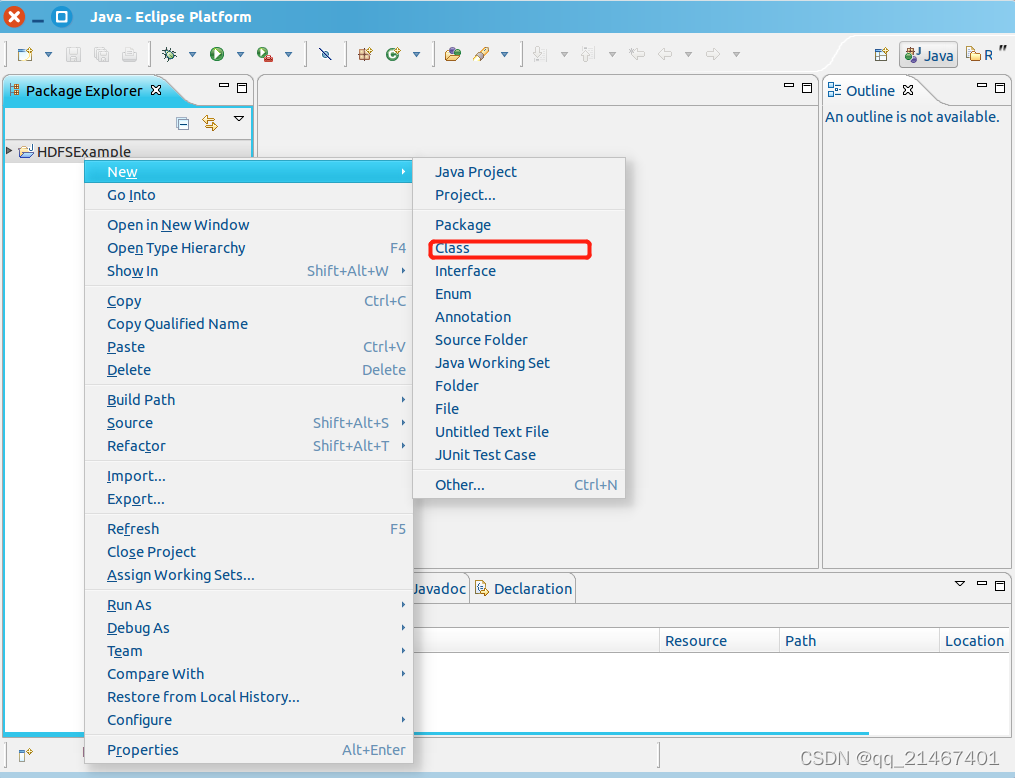
找到刚才创建好的工程名称“HDFSExample”,然后在该工程名称上点击鼠标右键,在弹出的菜单中选择“New-Class”菜单
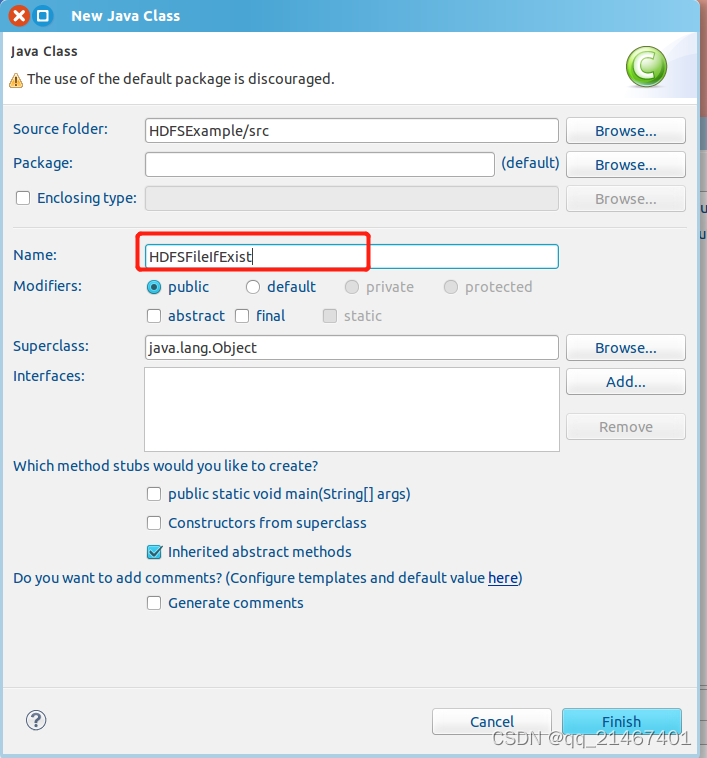
在name中输入新建的JAVA类文件的名称,如此次使用名称为“HDFSFileIfExist”,其他采用默认设置,完成后点击Finish
在新创建的名为 DFSFileIfExist.java 的源代码文件中输入一下代码,其中有一行代码为String fileNmae =“test”是测试HDFS中的“/user/hadoop/”目录下是否存在test文件。
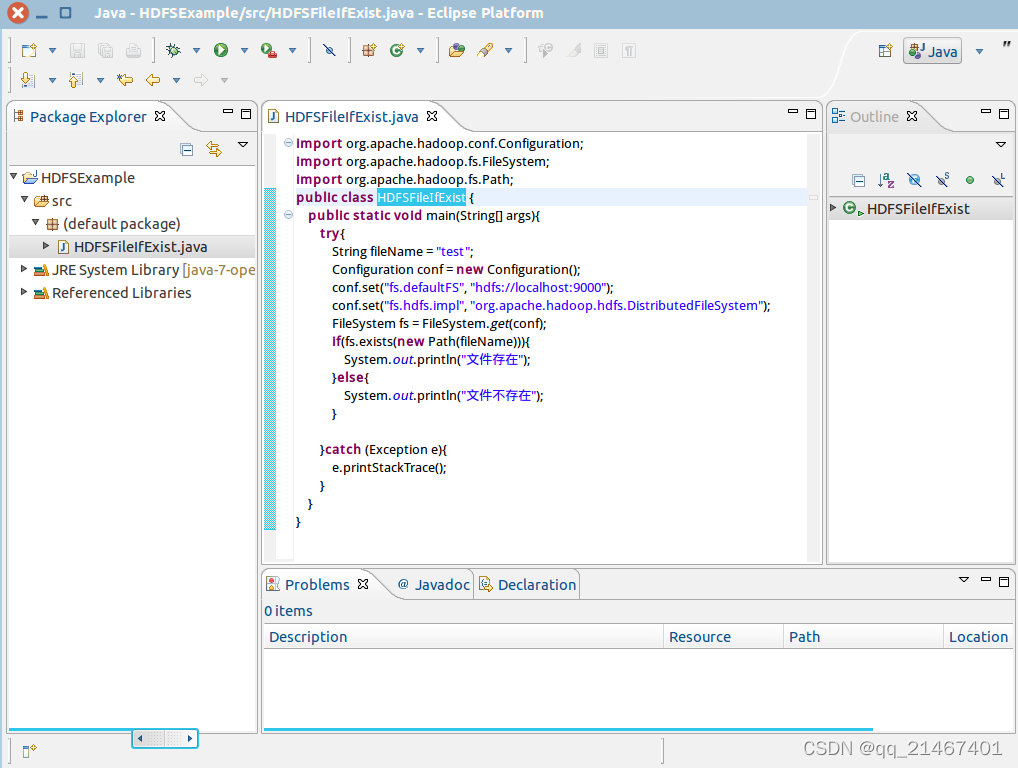
5. 编译运行程序
在编译代码运行之前先确保hadoop已成功开启
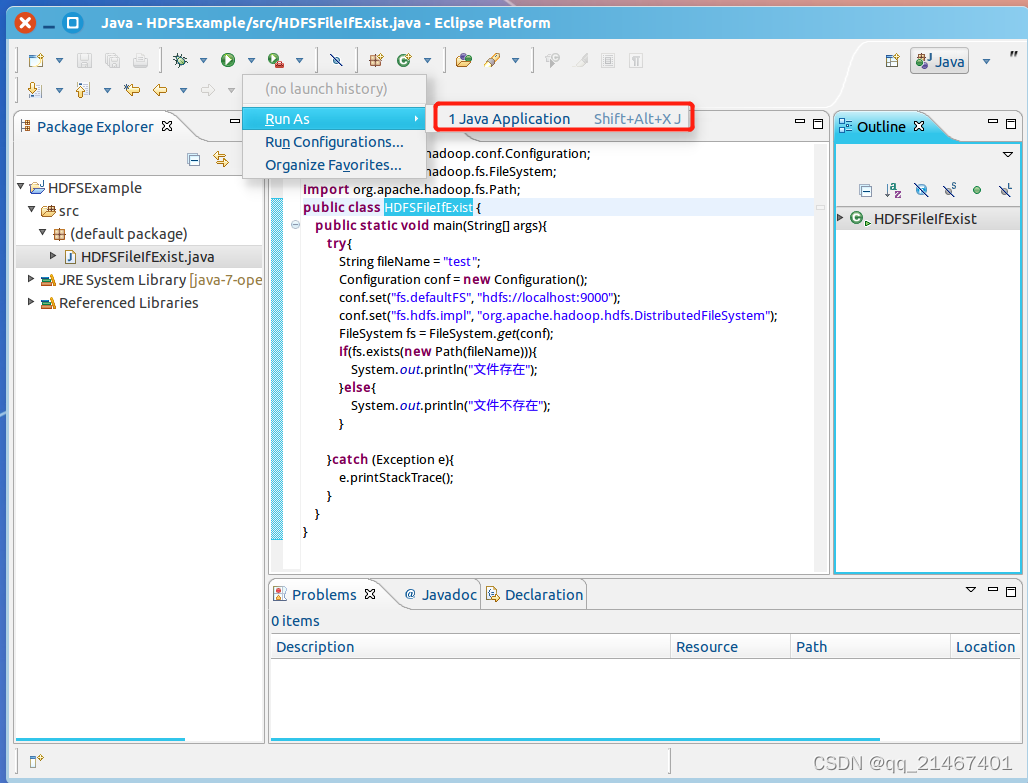
接着开始编译运行代码
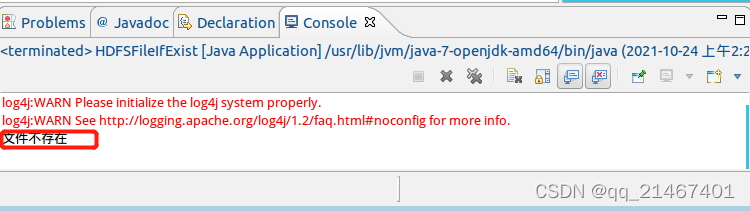
运行结束后结果显示“文件不存在”是由于目前HDFS的“/user/hadoop”目录下还没有test文件
6. 应用程序的部署
将Java应用程序生成JAR包,部署到Hadoop平台上运行。首先,在Hadoop安装目录下新建一个名称为myapp的目录,用来存放我们自己编写的Hadoop应用程序

然后在左侧Package Explorer栏中,右键名为“HDFSExample”的工程,弹出的菜单点击选择“Export”
弹出窗口中依次选择Java-Runnable JAR file
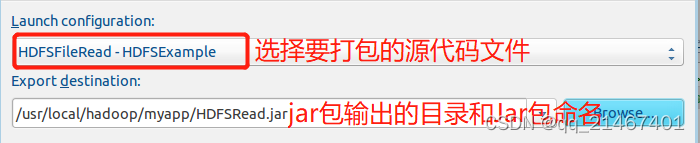
选择刚配置的类HDFSFileIfExist-HDFSExample,然后选择设置JAR包输出保存的目录
在Ubuntu终端窗口中查看一下生成的HDFSExample.jar文件
使用hadoop jar命令运行程序,成功则提示刚JAVA运行的结果“文件不存在”,同时也印证了部署成功

7. 写入文件test
创建一个名为“HDFSFileWriteIn”的源代码文件并编写输入以下代码创建test文件,定义的类名要与源文件名保持一致!
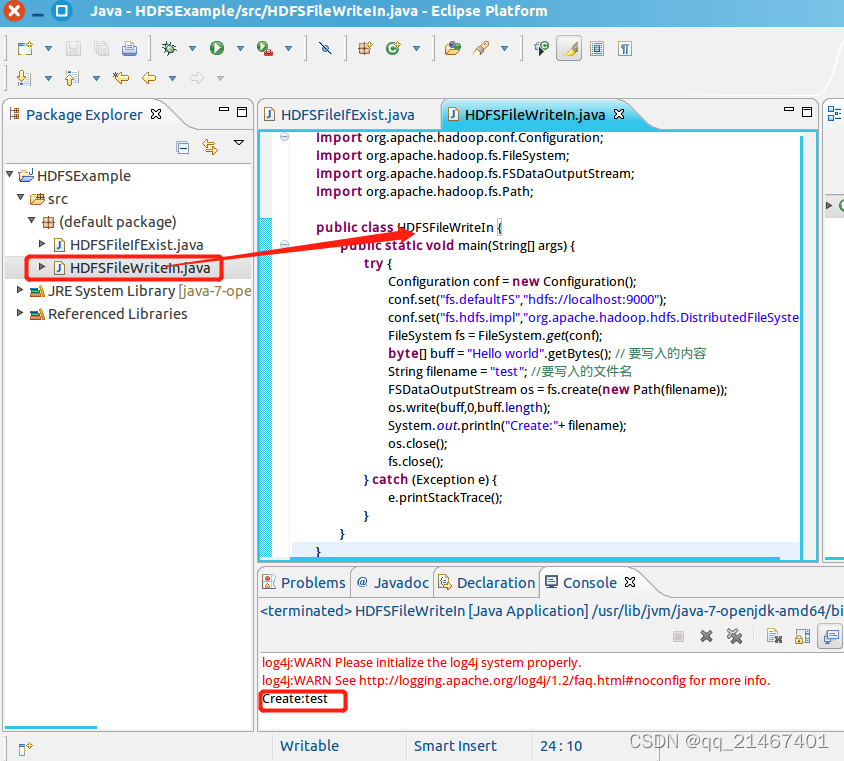
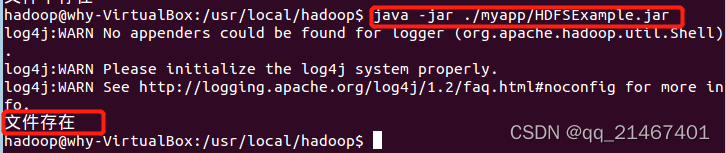
再次在终端窗口下使用hadoop jar命令运行名为HDFSFileIfExist那个程序,此时test文件已显示存在
8.读取文件
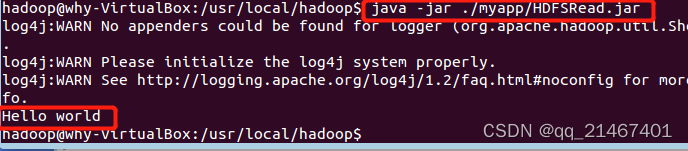
创建一个名为“HDFSFileRead”的源代码文件,并编写输入以下代码实现读取test文件中内容
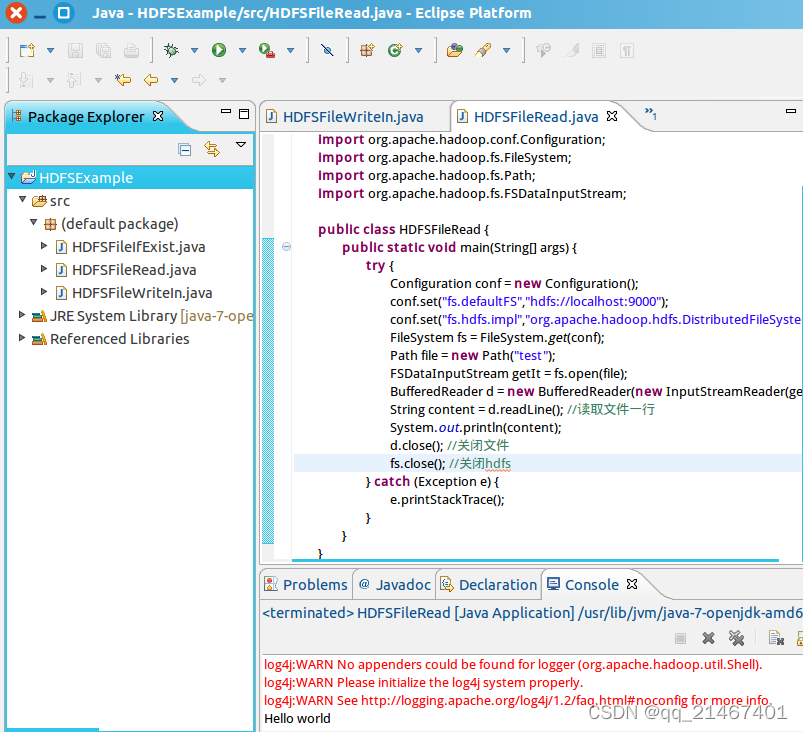
最后将该代码文件打包成JAR包在Ubuntu命令窗口下运行并读取test文件中的内容,结果显示“Hello World”成功读取
![]()
第三步就是文章此次的重头戏也是最终的目的
调用MapReduce对文件中各个单词出现的次数进行统计:
数据来源及数据上传
1. 首先在任意一个英文pdf电子书上下载一本电子书,并摘取其中几章作为本次作业的素材文件,素材文本符合要求达一万单词量以上,最终素材文本格式转为txt文本格式待用,文件命名为why.txt。
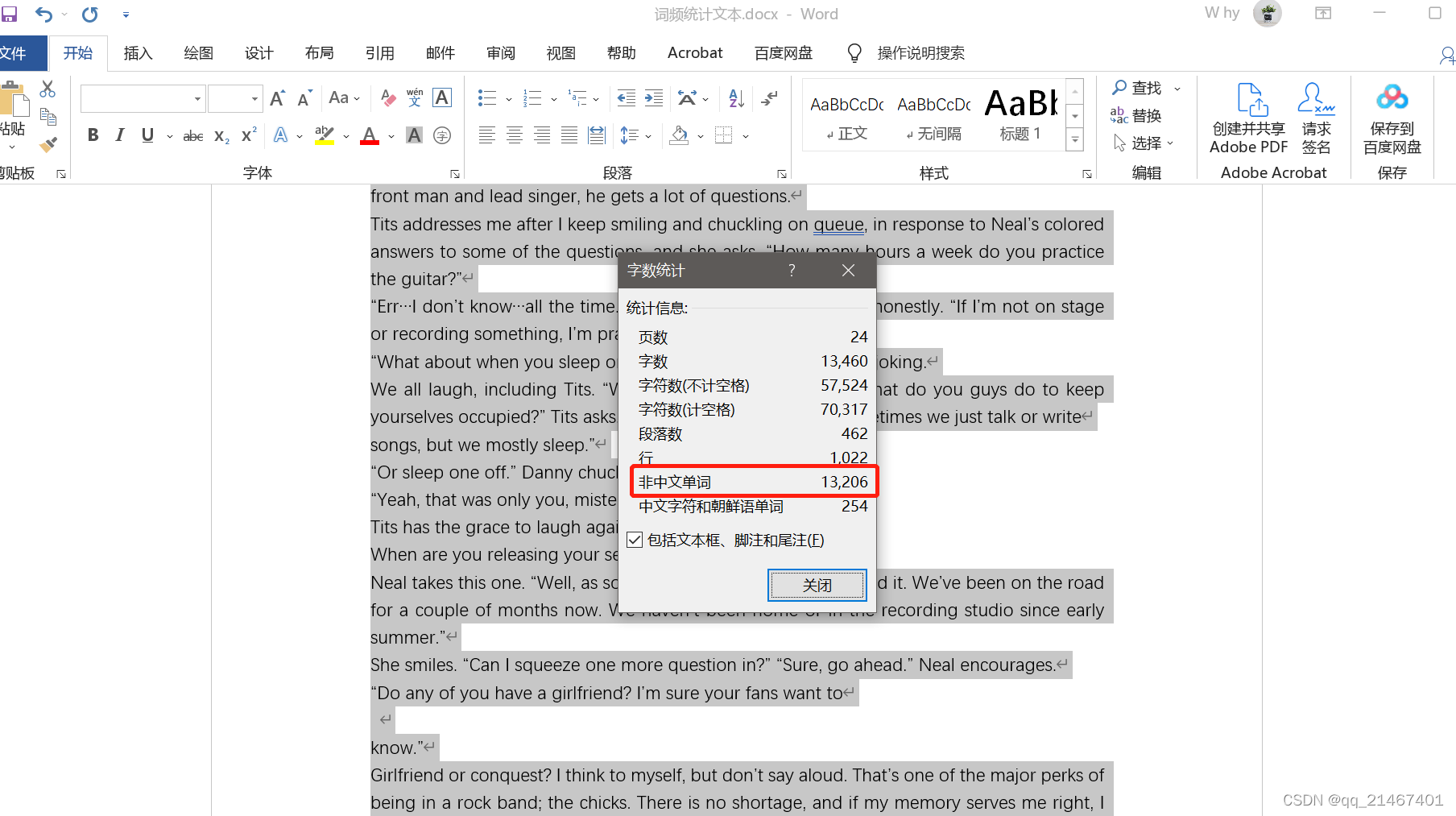
2. 将本地主机准备好的英文素材why.txt文本通过Firezilla文件传输软件传输到虚拟机Ubuntu的hadoop文件夹中
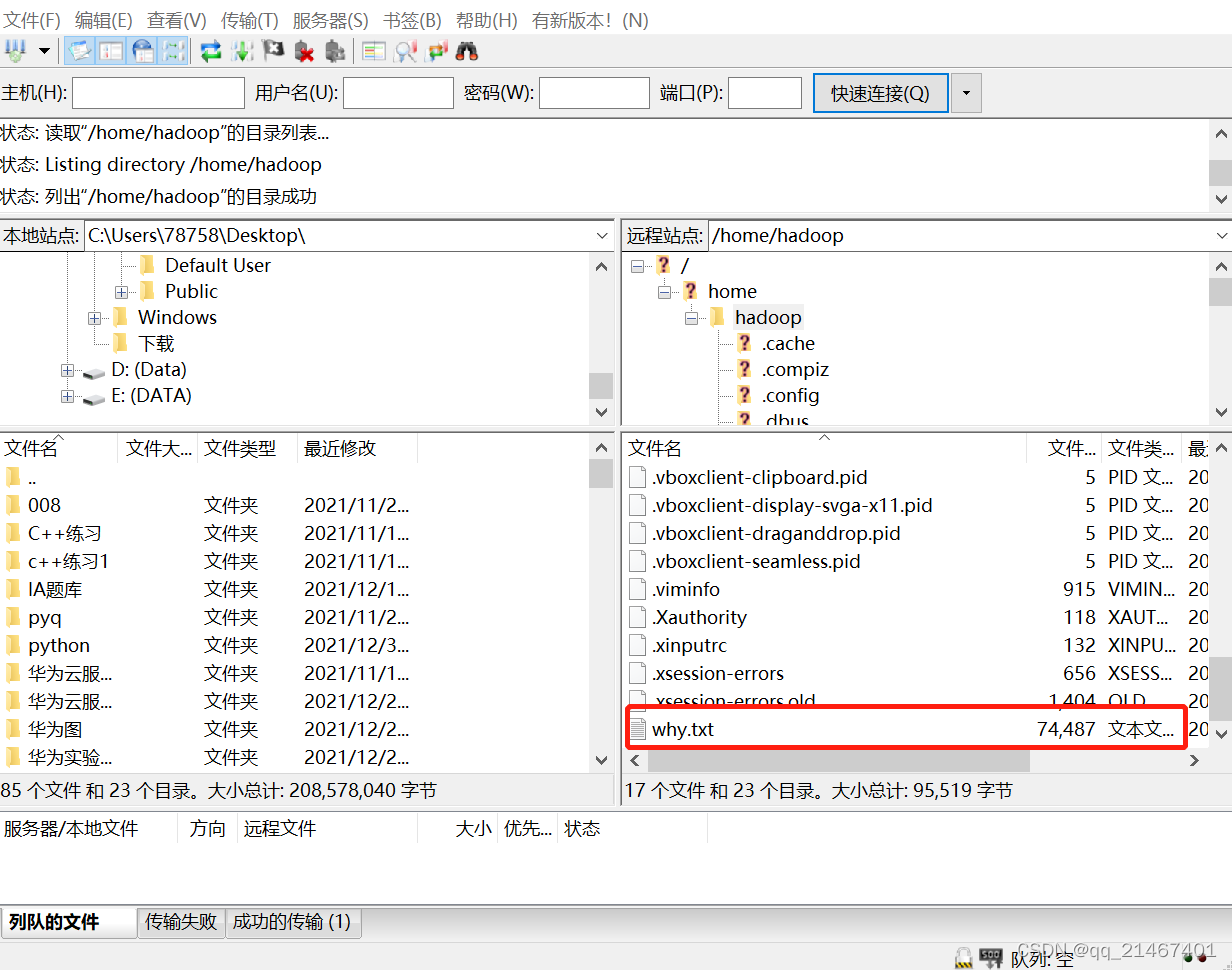
3. 在Ubuntu系统终端窗口下查看/home/hadoop文件夹是否存在why.txt

四、数据上传结果查看
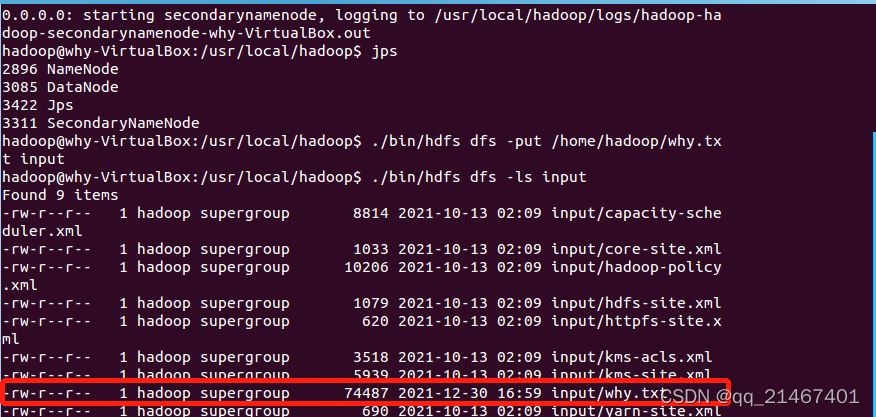
1. 开启hadoop,将why.txt文本上传到HDFS中的input文件夹中
五、数据处理过程的描述
1. 打开eclipse
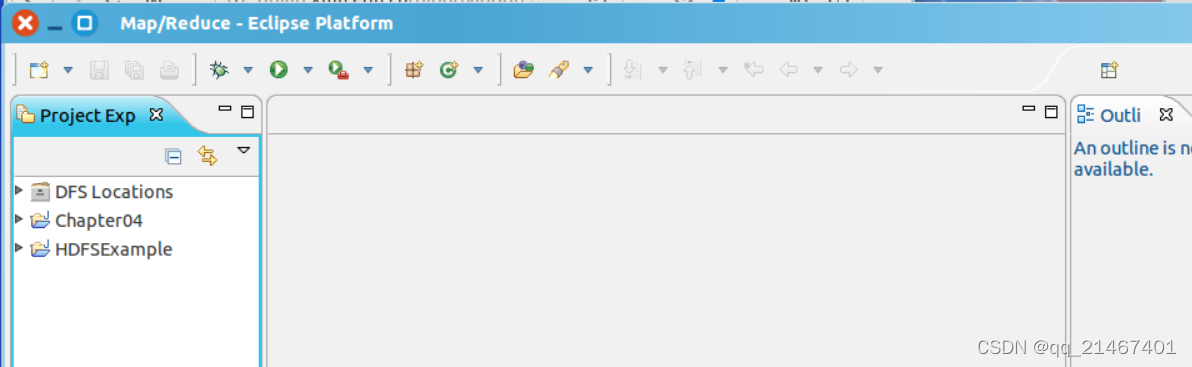
2. 创建MapReduce项目
在创建MapReduce Project项目时,填写 Project name 为 WordCount 即可,点击 Finish 就创建好了项目
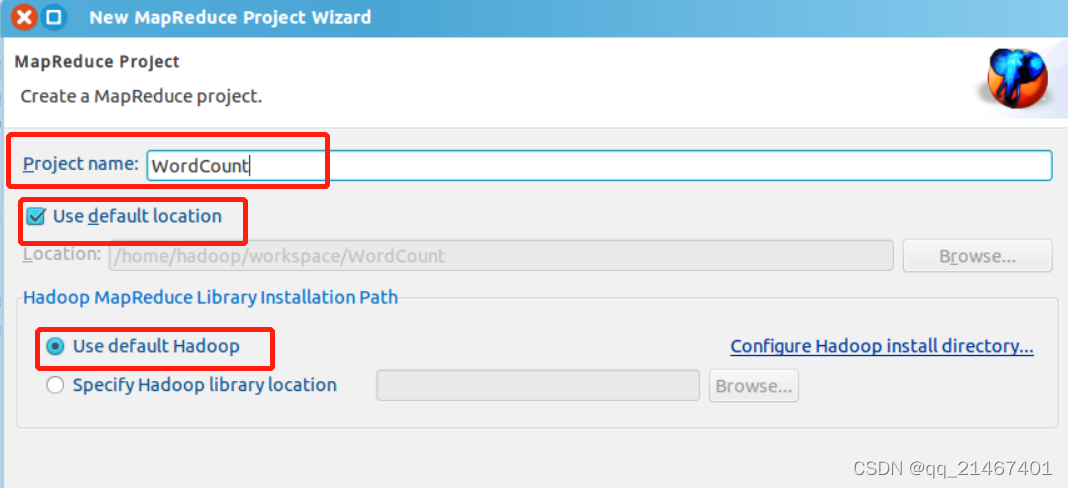
此时在左侧的 Project Explorer 就能看到刚才建立的项目了。
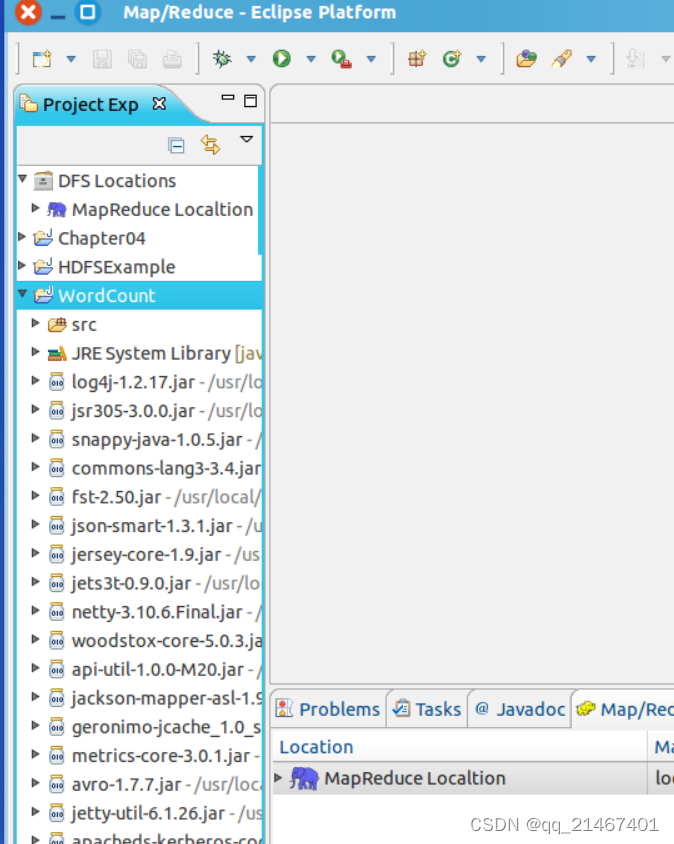
接着右键点击刚创建的 WordCount 项目,选择 New -> Class, 需要填写两个地方:在 Package 处填写 org.apache.hadoop.examples;在 Name 处填写 WordCount
清空WordCount.java里的所有代码,把以下完整的词频统计的程序代码输入到当中去:
package org.apache.hadoop.example;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
}
输入完成后按“Run As”运行,选择“Java Application”
在弹出的窗口中点击ok
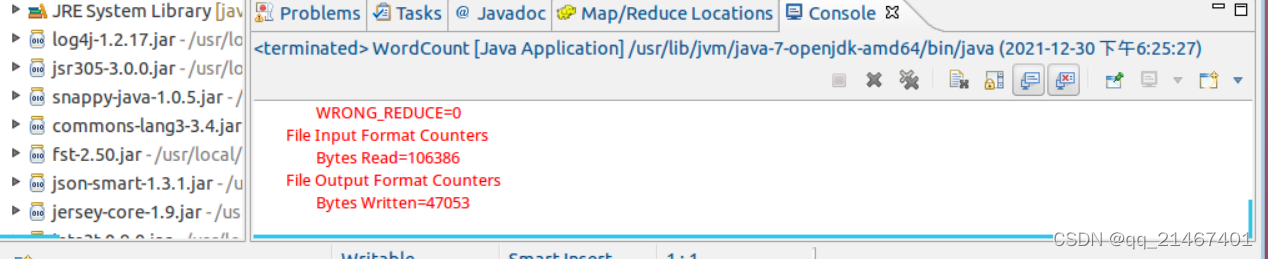
程序运行结束后,在底部的Console面版中查看运行结果:
接下来把java程序打包成JAR包部署到Hadoop上运行,程序存放位置在“/usr/local/Hadoop/myapp”目录下,myapp自行创建:
cd /usr/local/Hadoop
mkdir myapp

右键左侧“package Explorer”面板,在工程名称“WorldCount”中右键选择“Export”,接着在弹出的窗口下依次选择Java->Runnable JAR file
“Launch configuration”这个选项是用于设置生成的JAR包启动运行时的主类,在这里下拉列表选择刚配置的类“WordCount-WordCount”。在“Export destination”这个选项中需要设置的是JAR包输出的目录,此次则输入本次作业中的目录“/usr/local/Hadoop/myapp/WordCount.jar”。在“Library handing”中下拉选择“Extract required libraries into generated JAR”。最后点击finish完成。
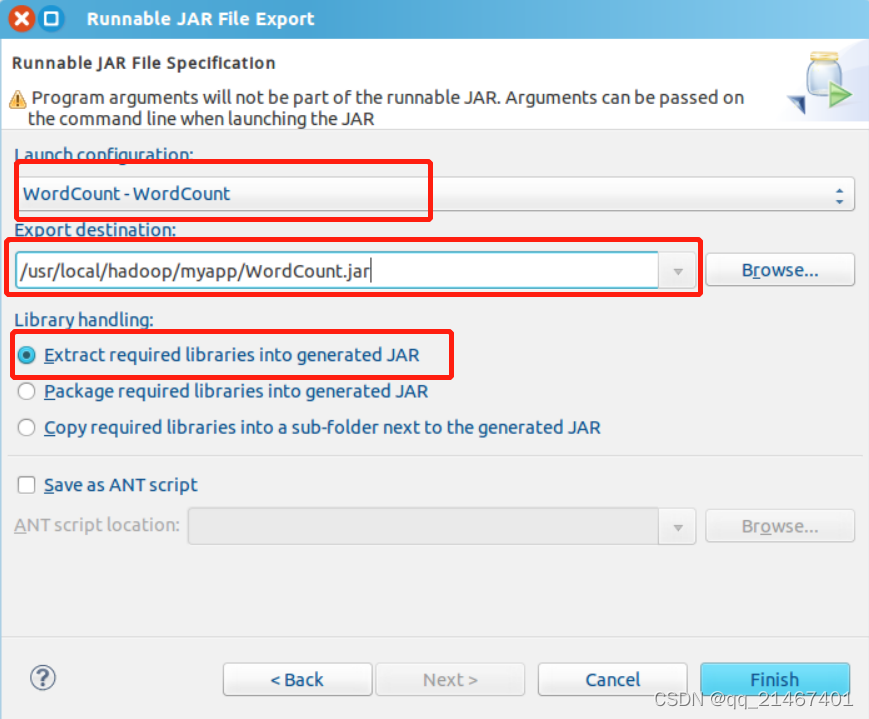
在弹出来的警告窗口中,点击OK忽略。
等待进度条加载完成再次啊点击弹出来的警告窗口OK忽略,至此就已经把WordCount工程打包生成WordCount.jar。
在myapp目录下可以看到WordCount.jar的包已经生成。

六、处理结果的下载及命令行展示
使用hadoop jar命令运行
cd /usr/local/Hadoop
./bin/Hadoop jar ./myapp/WordCount.jar /user/Hadoop/input /user/Hadoop/output1
input和output目录地址要根据自己设定的进行命令配置,这里的output因为在占用着不方便作为输出文件夹,所以再另创一个output1进行结果输出。
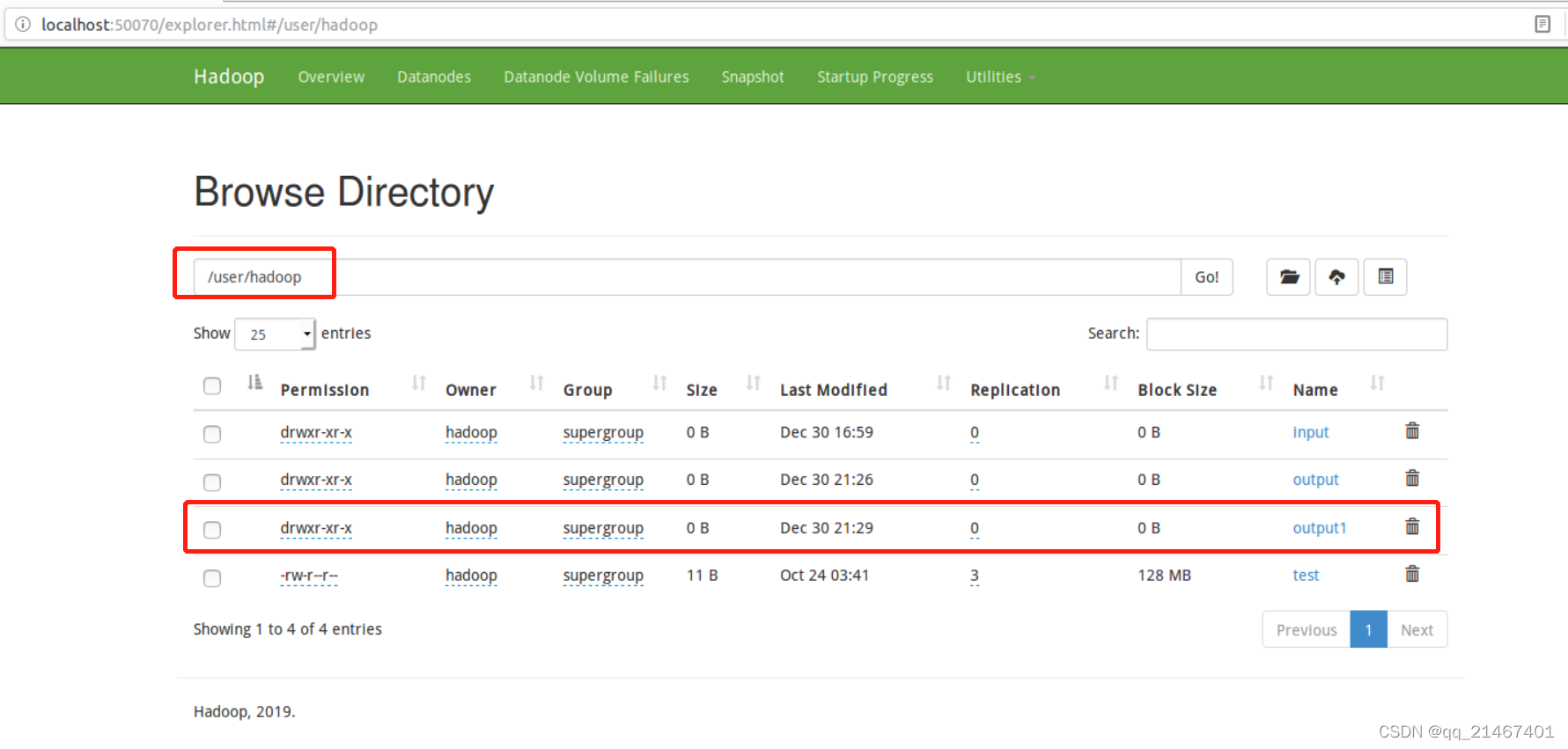
运行命令./bin/hdfs dfs -cat user/Hadoop/output1/part-r-0000进行查看输出结果。
部分结果展示:
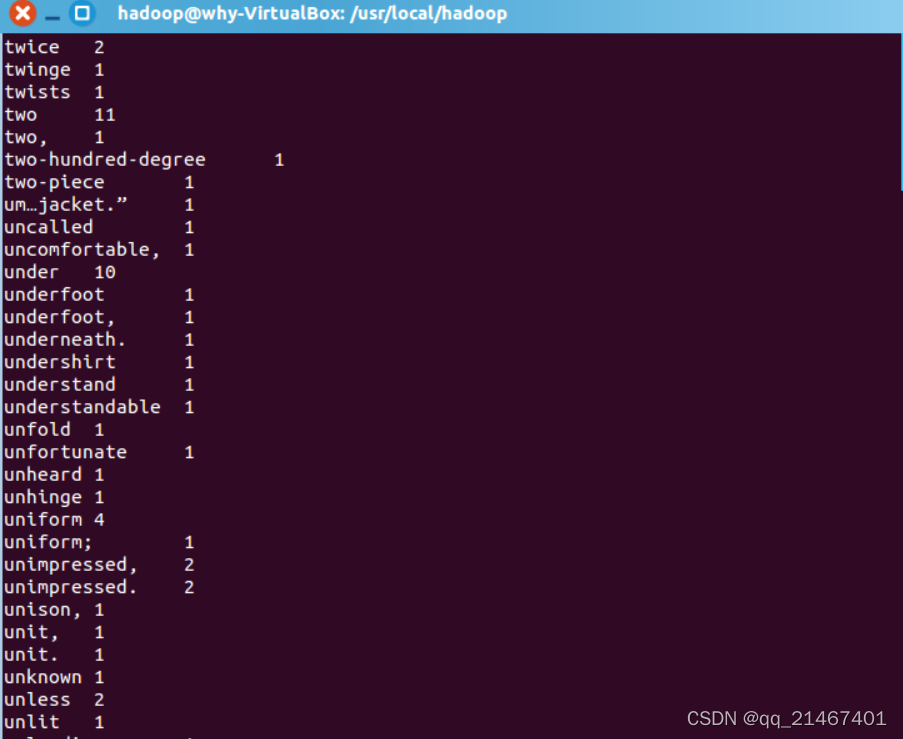
将output文件夹下载至本地:

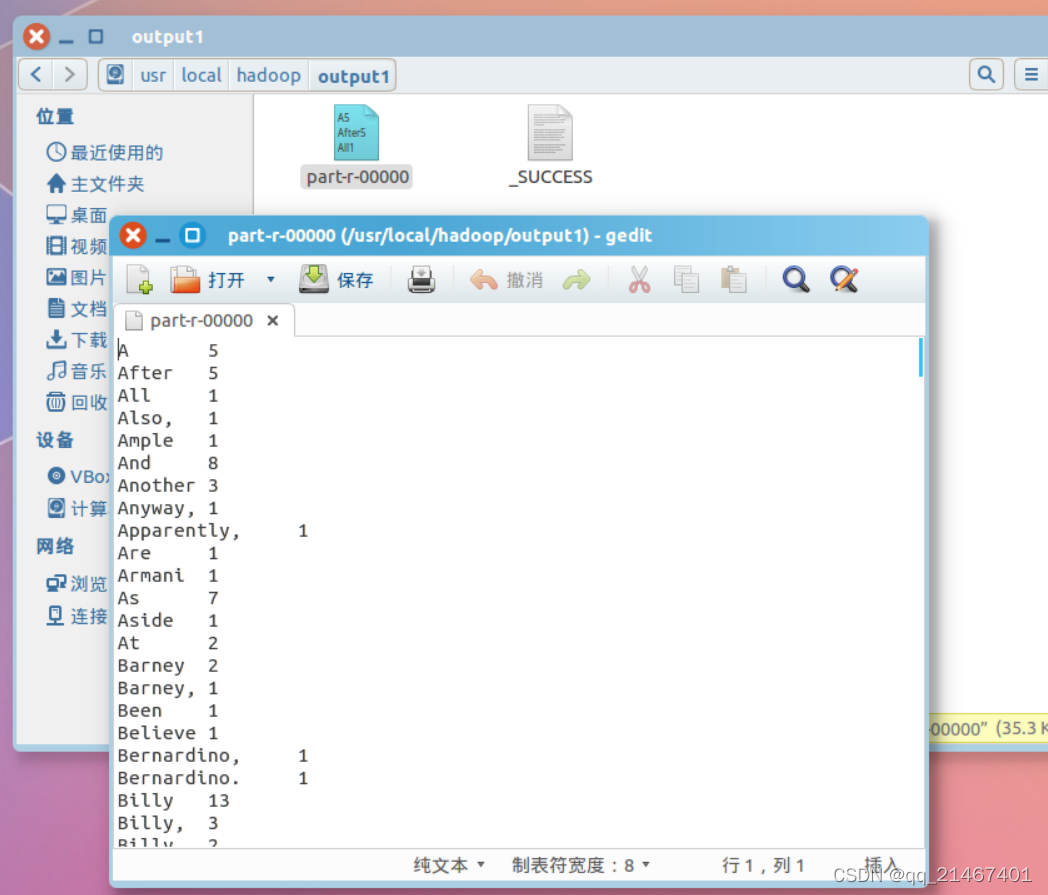
查看part-r-00000文件:
此次使用MapReduce对指定文本进行单词的词频统计就到此结束啦!你学会了吗,赶紧去试试吧!