Retinal Structure Detection in OCTA Image via Voting-Based Multitask Learning论文总结
论文:Retinal Structure Detection in OCTA Image via Voting-Based Multitask Learning - AMiner
代码:https://codeload.github.com/iMED-Lab/VAFF-Net/zip/refs/heads/master
目录
一、摘要
研究背景:自动检测视网膜结构,如视网膜血管(RV)、中央凹血管区(FAZ)和视网膜血管连接(RVJ),对了解眼部疾病和临床决策具有重要意义。
主要工作:在本文中,提出了一种新的基于投票的自适应特征融合多任务网络(VAFF-Net),用于光学相干断层扫描血管造影(OCTA)中RV、FAZ和RVJ的联合分割、检测和分类。
提出了一种针对特定任务的 投票门模块 ,从两个层面对特定任务自适应地提取和融合不同的特征:来自单个编码器的不同空间位置的特征和来自多个编码器的特征。特别是,由于OCTA图像中微血管的复杂性,使得同时精确定位和分类视网膜血管连接为分叉/交叉是一项具有挑战性的任务,专门设计了一个结合热图回归和网格分类的 任务头 。利用来自不同视网膜层的三种不同的面血管造影,而不是遵循仅使用单一面造影的现有方法。
实验结果:对使用不同成像设备获取的三个octa数据集进行了广泛的实验,结果表明,所提出的方法总体上优于最先进的单一用途方法或现有的多任务学习解决方案。我们还证明了我们的多任务学习方法可以推广到其他成像模式,如彩色眼底摄影,并且可能被用作通用的多任务学习工具。我们还构建了三个用于多结构检测的数据集,其中部分数据集的源代码和评估基准已经对外开放。
二、方法
所提出的VAFF-Net的整体架构如图所示:
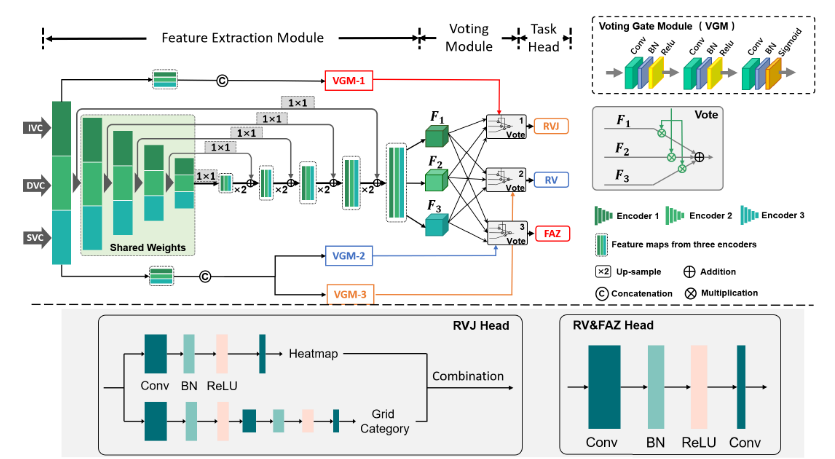
VAFF-Net包括三个主要组件:特征提取模块、投票门模块(VGM)和任务头。
A. 特征提取器和投票模块
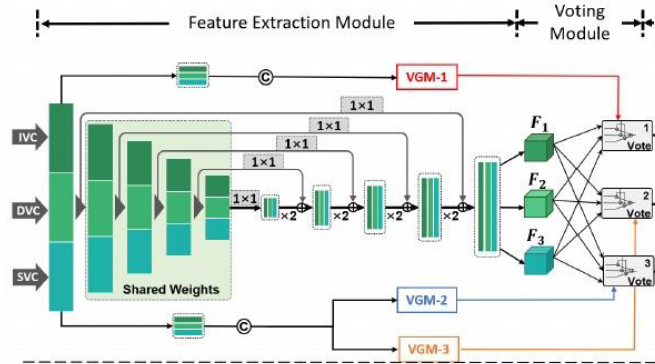
目的:使用包含深度信息的输入同时提取多个视网膜结构。VAFF-Net的输入是IVC、SVC和DVC三个面投影。通过特征提取器和三个任务头,可以同时获得RV、FAZ和RVJ的检测结果。特征提取模块由三个特征提取器组成,分别对应三个输入的面部血管图,即IVC、SVC和DVC。
特征提取器:作者采用ResNet-50作为特征提取器,其中将第一个7 × 7卷积层替换为具有相同填充的3 × 3卷积,以确保投票门模块的输出大小与输入图像的大小一致。在作者的实现中,除了第一个卷积层,三个提取器共享权重,以限制可学习参数的数量。由于不同的输入和第一层的独立性,这三个编码器能够提取不同的特征,尽管在后面使用了共享权重的策略。
投票模块:投票模块包含三个独立的特定于任务的投票门模块,每个模块对应一个任务,并自适应学习如何进行特征选择和融合。
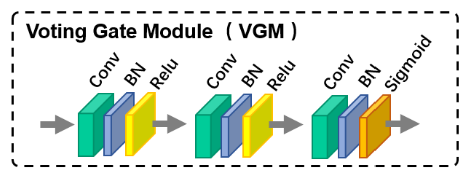
- 1. 模块组成:VGM由多个3 × 3的卷积层组成,经过批处理归一化(batch normalization, BN)和ReLU激活,最后的卷积层使用sigmoid算子将特征映射成具有3个通道的概率形式,作为选择特征的门。(重点)
- 2. 输入/输出:每个task∈{RV, FAZ, RVJ}的VGM以来自三个编码器的第一层输出的拼接作为输入,对应的输出
 是学习的投票门特征。
是学习的投票门特征。 - 3. 作用:投票门可以选择两个层次的特征:不同层面的图像,以及来自编码器的不同空间位置的特征。(前者考虑到从三幅图像中获得的特征对于每个任务的重要性是不同的。对于后者,我们可以利用以下空间特性:FAZ分割任务侧重于黄斑区域;RVJ检测任务依赖于相交血管的位置,而血管分割任务则需要更多地关注血管的边缘。)
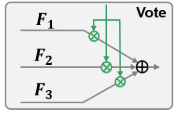
在得到每个任务的投票门特征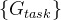 后,将三个编码器的多尺度融合特征
后,将三个编码器的多尺度融合特征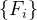 (i∈{1,2,3})分别与
(i∈{1,2,3})分别与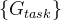 (task∈{RV, FAZ, RVJ})相乘,求和得到相应任务的综合特征映射
(task∈{RV, FAZ, RVJ})相乘,求和得到相应任务的综合特征映射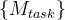 。这些操作可以表述为:
。这些操作可以表述为:
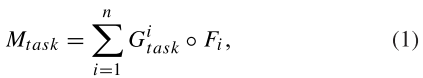
其中 n 是特征通道的数量,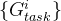 表示投票门
表示投票门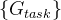 的第 i 个通道,◦ 表示元素相乘。然后将特定于任务的特征映射
的第 i 个通道,◦ 表示元素相乘。然后将特定于任务的特征映射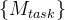 馈送到相应的任务头部,以获得特定于任务的最终结果。
馈送到相应的任务头部,以获得特定于任务的最终结果。
Q:权重共享怎么实现的?
A:调用相同的编码器层分别依次对IVC、SVC和DVC图像进行卷积。
Q:F1、F2、F3是怎么得到的?
A:相当于使用了三个相同的编码器路径和解码器路径,最终的输出也是三个不同的特征图。
代码如下:
resnet = models.resnet50(pretrained=True)
#self.firstconv = resnet.conv1
self.firstconv_1 = nn.Conv2d(in_ch, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.firstbn_1 = resnet.bn1
self.firstrelu_1 = resnet.relu
self.firstdownsample_1 = nn.Conv2d(64, 64, kernel_size=7, stride=2, padding=3, bias=False)
# self.encoder1_1 = resnet.layer1
#2
self.firstconv_2 = nn.Conv2d(in_ch, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.firstbn_2 = resnet.bn1
self.firstrelu_2 = resnet.relu
self.firstdownsample_2 = nn.Conv2d(64, 64, kernel_size=7, stride=2, padding=3, bias=False)
# self.encoder1_2 = resnet.layer1
#3
self.firstconv_3 = nn.Conv2d(in_ch, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.firstbn_3 = resnet.bn1
self.firstrelu_3 = resnet.relu
self.firstdownsample_3 = nn.Conv2d(64, 64, kernel_size=7, stride=2, padding=3, bias=False)
# self.encoder1_3 = resnet.layer1
self.encoder1 = resnet.layer1
self.encoder2 = resnet.layer2
self.encoder3 = resnet.layer3
self.encoder4 = resnet.layer4
self.toplayer = nn.Conv2d(2048, 256, kernel_size=1, stride=1, padding=0) # Reduce channels
# 投票门
self.gate_conv_FAZ = nn.Sequential(
nn.Conv2d(64*3, 256, 3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, 3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 64, 3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 3, kernel_size=1, stride=1, padding=0),
nn.Sigmoid()
)
self.gate_conv_vessel = nn.Sequential(
nn.Conv2d(64*3, 256, 3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, 3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 64, 3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 3, kernel_size=1, stride=1, padding=0),
nn.Sigmoid()
)
self.gate_conv_juncM = nn.Sequential(
nn.Conv2d(64*3, 256, 3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, 3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 64, 3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 3, kernel_size=1, stride=1, padding=0),
nn.Sigmoid()
)
def _upsample_add(self, x, y):
_,_,H,W = y.size()
return F.interpolate(x, size=(H,W), mode='bilinear',align_corners=True) + y
def _upsample_(self, x, y):
_,_,H,W = y.size()
out = F.interpolate(x, size=(H,W), mode='bilinear',align_corners=True)
return out # x_w
x_w = self.firstconv_1(x_w)
x_w = self.firstbn_1(x_w)
x_w = self.firstrelu_1(x_w)
down_x_w = self.firstdownsample_1(x_w)
# e1_w = self.encoder1_1(down_x_w)
e1_w = self.encoder1(down_x_w)
e2_w = self.encoder2(e1_w)
e3_w = self.encoder3(e2_w)
e4_w = self.encoder4(e3_w)
p5_w = self.toplayer(e4_w)
p4_w = self._upsample_add(p5_w, self.latlayer1(e3_w))
p3_w = self._upsample_add(p4_w, self.latlayer2(e2_w))
p2_w = self._upsample_add(p3_w, self.latlayer3(e1_w))
p1_w = self._upsample_add(p2_w, self.latlayer4(x_w))
# x_d
x_d = self.firstconv_2(x_d)
x_d = self.firstbn_2(x_d)
x_d = self.firstrelu_2(x_d)
down_x_d = self.firstdownsample_2(x_d)
# e1_d = self.encoder1_2(down_x_d)
e1_d = self.encoder1(down_x_d)
e2_d = self.encoder2(e1_d)
e3_d = self.encoder3(e2_d)
e4_d = self.encoder4(e3_d)
p5_d = self.toplayer(e4_d)
p4_d = self._upsample_add(p5_d, self.latlayer1(e3_d))
p3_d = self._upsample_add(p4_d, self.latlayer2(e2_d))
p2_d = self._upsample_add(p3_d, self.latlayer3(e1_d))
p1_d = self._upsample_add(p2_d, self.latlayer4(x_d))
# x_s
x_s = self.firstconv_3(x_s)
x_s = self.firstbn_3(x_s)
x_s = self.firstrelu_3(x_s)
down_x_s = self.firstdownsample_3(x_s)
# e1_s = self.encoder1_3(down_x_s)
e1_s = self.encoder1(down_x_s)
e2_s = self.encoder2(e1_s)
e3_s = self.encoder3(e2_s)
e4_s = self.encoder4(e3_s)
p5_s = self.toplayer(e4_s)
p4_s = self._upsample_add(p5_s, self.latlayer1(e3_s))
p3_s = self._upsample_add(p4_s, self.latlayer2(e2_s))
p2_s = self._upsample_add(p3_s, self.latlayer3(e1_s))
p1_s = self._upsample_add(p2_s, self.latlayer4(x_s))
gate_FAZ = self.gate_conv_FAZ(torch.cat([x_w,x_d,x_s],dim=1))
gate_vessel = self.gate_conv_vessel(torch.cat([x_w,x_d,x_s],dim=1))
gate_juncM = self.gate_conv_juncM(torch.cat([x_w,x_d,x_s],dim=1))
#gate_juncR = self.gate_conv_juncR(torch.cat([x_w,x_d,x_s],dim=1))
p_FAZ = gate_FAZ[:,0,:,:].unsqueeze(1)*p1_w + gate_FAZ[:,1,:,:].unsqueeze(1)*p1_d + gate_FAZ[:,2,:,:].unsqueeze(1)*p1_s
p_vessel = gate_vessel[:,0,:,:].unsqueeze(1)*p1_w + gate_vessel[:,1,:,:].unsqueeze(1)*p1_d + gate_vessel[:,2,:,:].unsqueeze(1)*p1_s
p_juncM = gate_juncM[:,0,:,:].unsqueeze(1)*p1_w + gate_juncM[:,1,:,:].unsqueeze(1)*p1_d + gate_juncM[:,2,:,:].unsqueeze(1)*p1_s
#p_juncR = gate_juncR[:,0,:,:].unsqueeze(1)*p2_w + gate_juncR[:,1,:,:].unsqueeze(1)*p2_d + gate_juncR[:,2,:,:].unsqueeze(1)*p2_sB. RVJ 检测与分类任务头
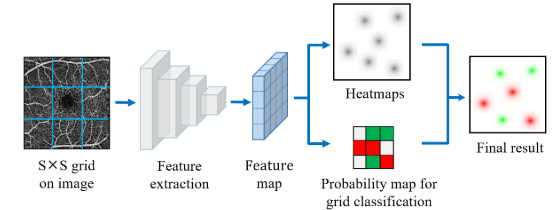
研究问题:RVJ 是仅覆盖几个像素的小目标,基于边界盒的目标检测方法,通常难以在 RVJ 检测任务上获得令人满意的性能。
解决方案:引入了一个具有两个分支的任务头,它结合了热图回归和网格分类,用于分叉和交叉的检测和分类。我们将这个相对复杂的任务分成两个简单的任务:使用热图回归来定位 RVJs,使用网格分类分支来区分分叉和交叉。
RVJ任务头:
- 1. 输入:是由RVJ的VGM(投票门)重新加权的特征提取器的输出
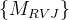 。
。 - 2. 结构:首先,将用于RVJ检测的特征图
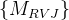 输入到一个卷积块中,该卷积块由两个具有BN和ReLU激活函数的3 × 3卷积层组成。最后一个卷积层具有sigmoid激活函数,通过1通道的热图输出获得所有结点的位置。另一个分支也以
输入到一个卷积块中,该卷积块由两个具有BN和ReLU激活函数的3 × 3卷积层组成。最后一个卷积层具有sigmoid激活函数,通过1通道的热图输出获得所有结点的位置。另一个分支也以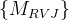 作为输入:它将图像划分为S × S网格,并对每个网格单元预测3个类别概率(即包含分叉、包含交叉和仅背景)和1个置信度分数(置信度分数表示模型对网格包含RVJ的置信度,并可用于在最终处理期间选择阈值)。这些预测值被编码为S × S × 4张量。
作为输入:它将图像划分为S × S网格,并对每个网格单元预测3个类别概率(即包含分叉、包含交叉和仅背景)和1个置信度分数(置信度分数表示模型对网格包含RVJ的置信度,并可用于在最终处理期间选择阈值)。这些预测值被编码为S × S × 4张量。
在实现中,将每个网格单元设置为8 × 8,因此该分支的最终预测是一个输入为304 × 304的图像的38 × 38 × 4张量。一个分支的输出是所有节点的热图,另一个分支的输出是每个网格中包含的节点的类别。通过组合两个分支的结果来获得最终的预测。网格的大小是一个超参数。对于304 × 304的输入,作者根据经验发现网格大小为8 × 8是合适的,这样可以保证网格中尽可能多地有一个分支/交叉点。网格的大小可以根据输入图像的大小进行调整。
代码如下:
#heatmap branch
self.finaldeconv1_map = nn.Conv2d(256, 64, 3, 1, 1) #152*152
self.finalBN_map = nn.BatchNorm2d(64)
self.finalrelu_map = nn.ReLU(inplace=True)
self.finalconv2_map = nn.Conv2d(64, 1, kernel_size=1, stride=1, padding=0)
#detetion
#self.finaldeconv1 = nn.Conv2d(256, 256, 3, 1, 1)
#self.finaldeconv1_d = nn.Conv2d(256, 128, 4, 2, 1) #grid=4\
self.finaldeconv1_d = nn.Conv2d(256, 128, 6, 4, 1) #grid=8
self.finalBN_d = nn.BatchNorm2d(128)
self.finalrelu_d = nn.ReLU(inplace=True)
self.finaldeconv1_d2 = nn.Conv2d(128, 128, 4, 2, 1)
self.finalBN_d2 = nn.BatchNorm2d(128)
self.finalrelu_d2 = nn.ReLU(inplace=True)
self.finalconv2_d = nn.Conv2d(128, 6, kernel_size=1, stride=1, padding=0) #junction map
out_map = self.finaldeconv1_map(p_juncM)
out_map = self.finalBN_map(out_map)
out_map = self.finalrelu_map(out_map)
out_map = self.finalconv2_map(out_map)
out_map = nn.Sigmoid()(out_map)
#detection
out_d = self.finaldeconv1_d(p_juncM)
out_d = self.finalBN_d(out_d)
out_d = self.finalrelu_d(out_d)
out_d = self.finaldeconv1_d2(out_d)
out_d = self.finalBN_d2(out_d)
out_d = self.finalrelu_d2(out_d)
out_d = self.finalconv2_d(out_d)