大模型训练技巧|单卡&多卡|训练性能评测
原视频:【单卡、多卡 BERT、GPT2 训练性能【100亿模型计划】】
此笔记主要参考了李沐老师的视频,感兴趣的同学也可以去看视频~
视频较长,这里放上笔记,与大家分享~
大模型对于计算资源的要求越来越高,如何在有限的资源下开展训练?
对于公司尤其是个人开发者来说,是一个非常有价值的问题。
本文将主要介绍大模型训练技巧,在单卡和多卡上的不同策略,以及对于性能的评测。
文章目录
1.GPU训练性能的测试脚本
2.设置
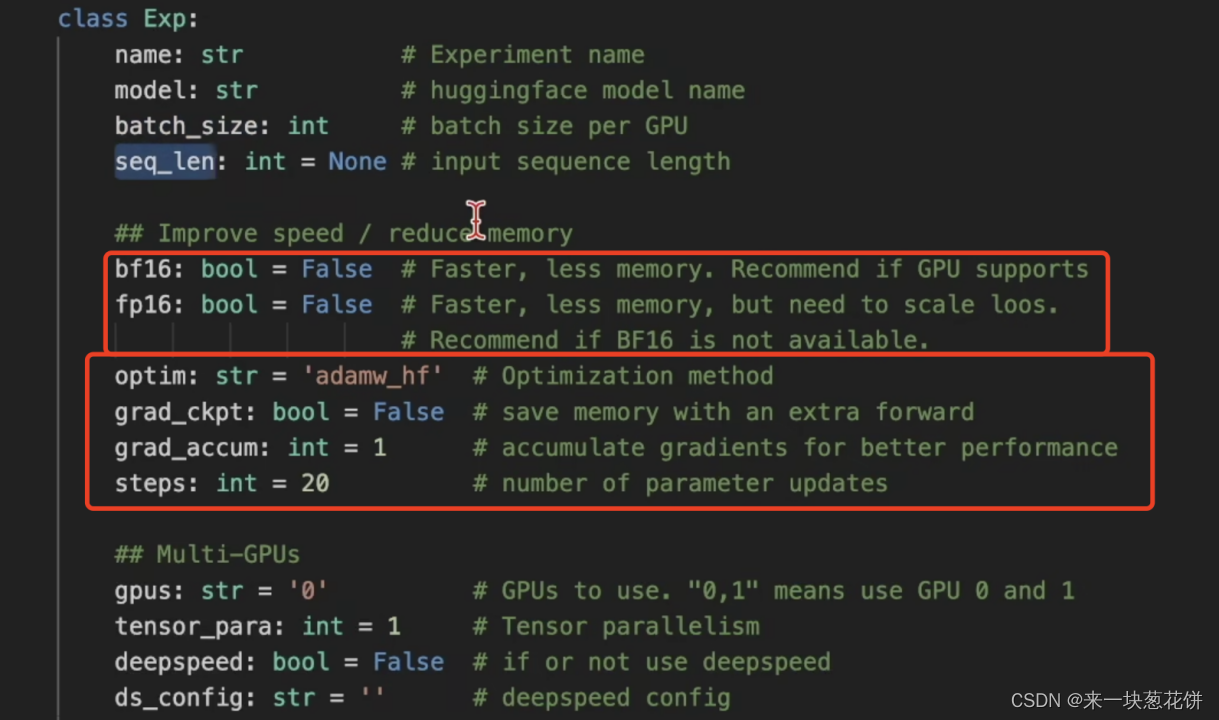
画红框的部分,会影响GPU的性能。
16位是半精度,32位是单精度,64位是双精度。bf16和fp16是精度。
optim是优化器。(adamw其实是一个多此一举的优化器。直接使用adam优化器就行。)
grad_accum表示是否要做梯度的累加。
steps表示要跑多少次的模型更新。
deepspeed是一种跑分布式的方式。
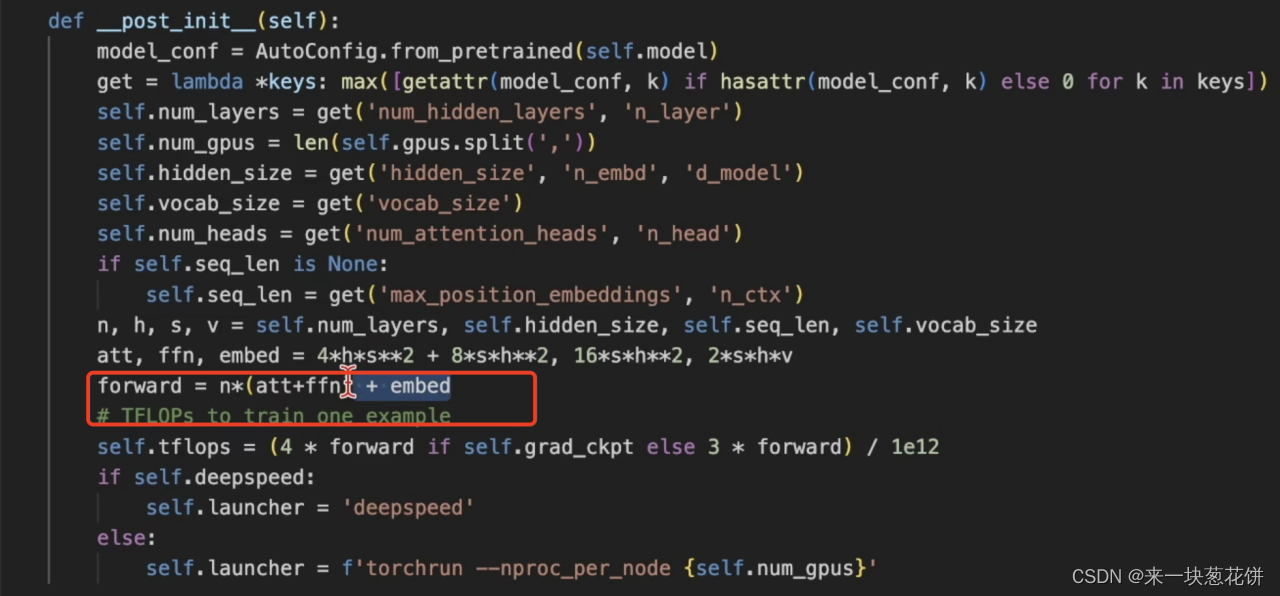
计算量:TFLOPS
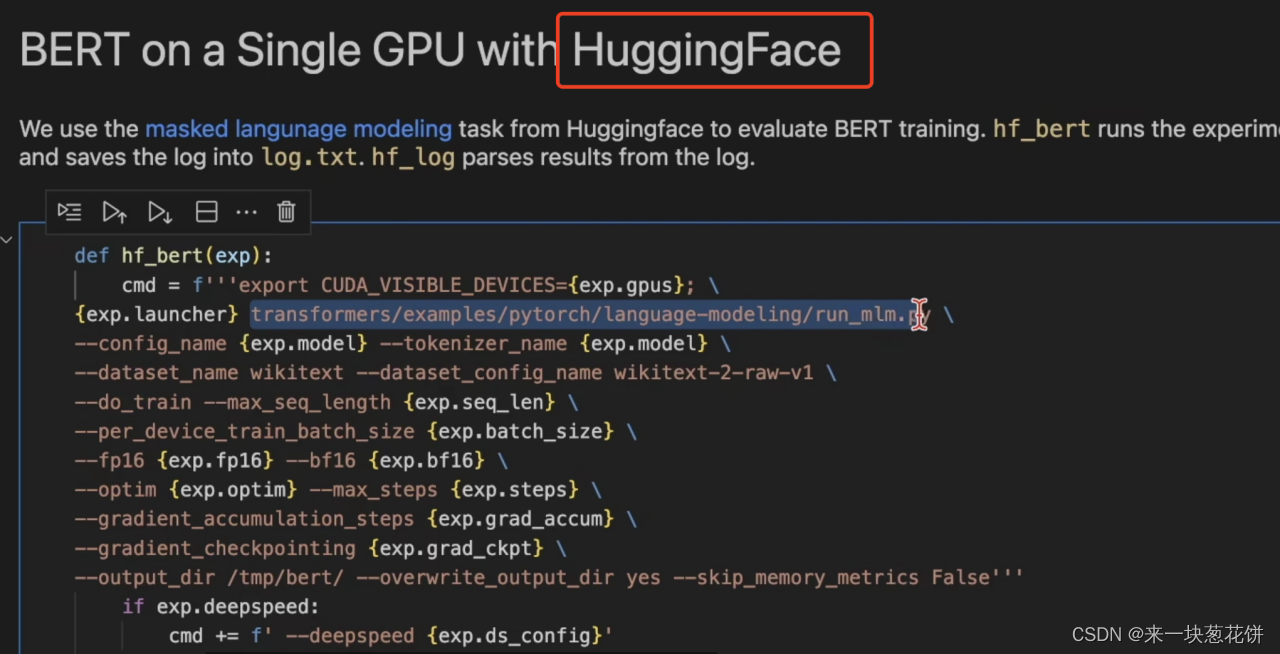
huggingface是一个模型库
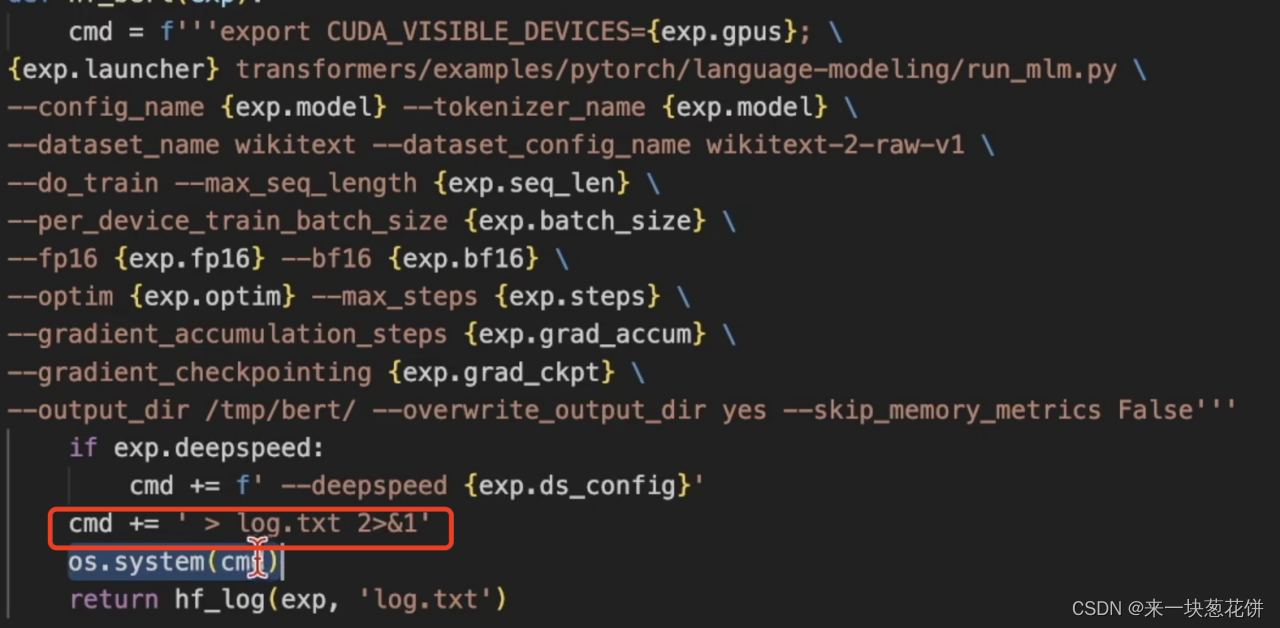
log文件
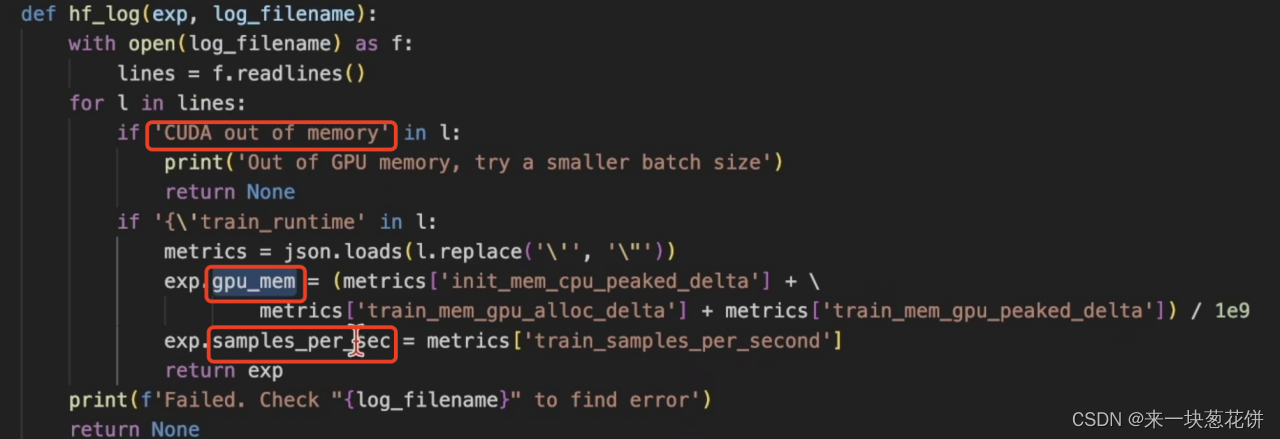
读取和解析log文件
核心是读取两个参数:gpu显存的峰值,和每秒读取的样本数
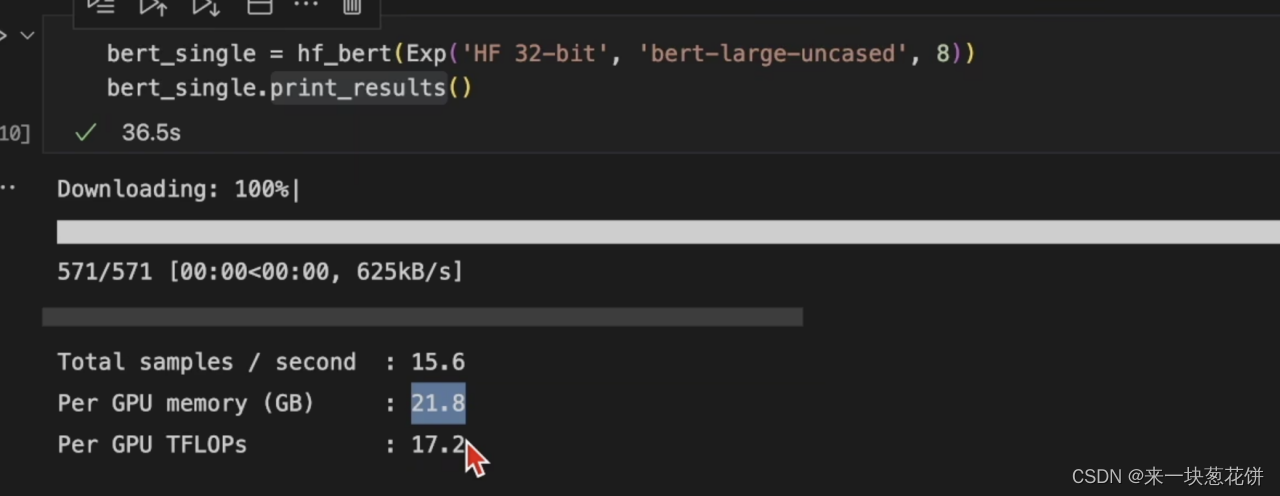
3.单卡性能
内存消耗(这里指GPU的内存,即显存)
1.模型的参数(大模型参数量大,占用空间大)
2.每一层的输出,即前向运算的中间计算结果,也叫activation
3.用的库,背后所占的内存。比如通信、cudnn
一般来说,占大头的是前两个。
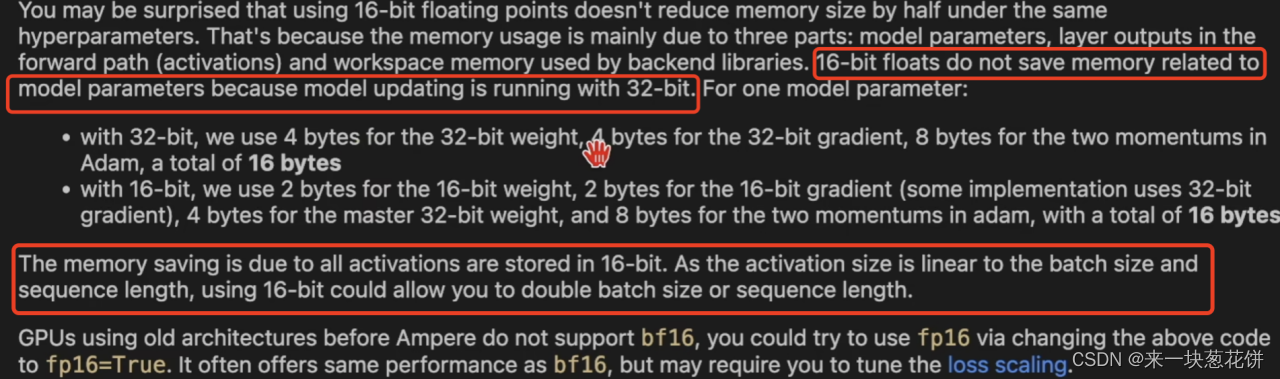
注意:使用16位计算,并不能节省模型占用的空间。因为模型还是用32位来存的,模型的权重还是会转化为32位,进行更新。
但是如果使用16位运算,前向计算的中间结果(即activation)是16位的,这样就节省了空间。而且activation的大小和batchsize、序列长度、浮点运算量呈正比,所以如果使用16位运算,可以提高batchsize或者序列长度。
优先使用bf16,其次是fp16。
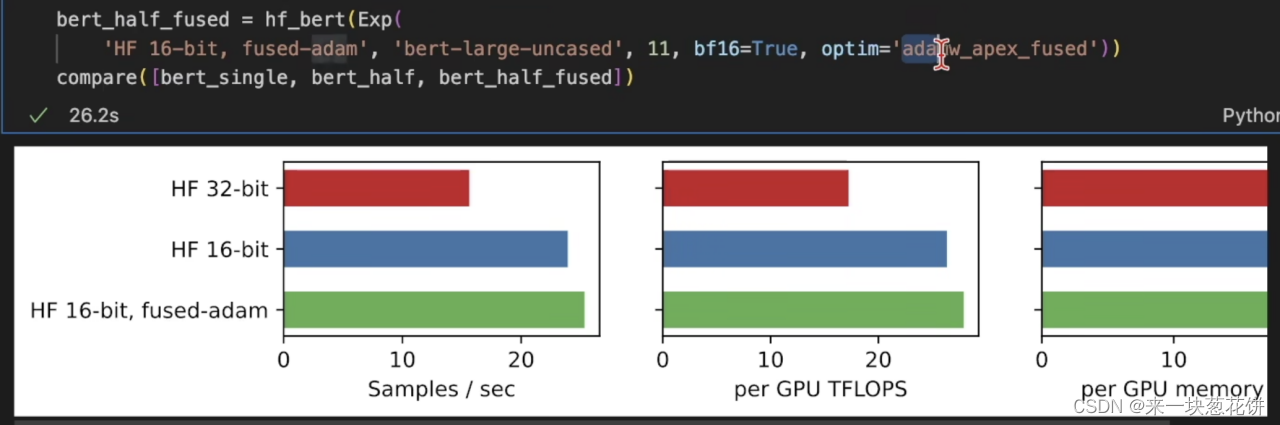
实验现象
fp32换为了fp16,性能并没有翻倍,说明还有别的地方在使用内存。
可能是内存带宽,造成了GPU性能的瓶颈。
性能优化
1.kernal fusion操作:
麻烦的python操作,用c++的for loop重写一遍。
目的:减少中间变量的读写过程,同时减少调用python运算产生的额外开销。
一般不需要自己重写,直接调用apex库就可以。
2.grad_accum
每次处理完一个batch,不直接更新梯度。而是计算多个batch,将梯度进行累加,再做梯度更新。
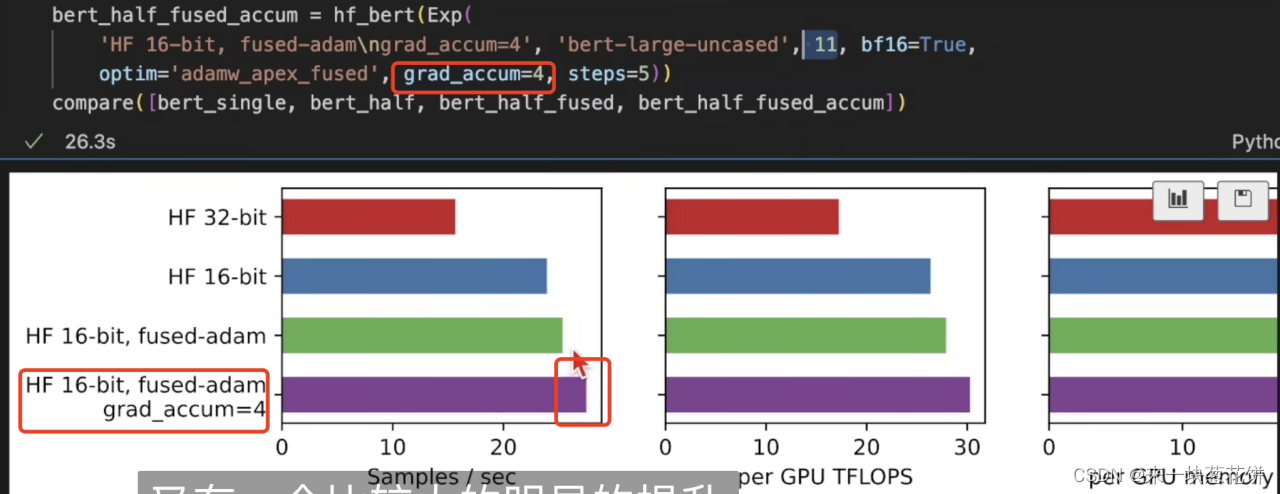
如果batchsize=10,grad_accum=4,那么会在总的10*4=40个batch后,才会进行梯度更新。
但是grad_accum或者总的批量大小不能太大,批量大小太大会影响算法的收敛。
做微调的时候,批量大小不能太大,因为数据集本来就不大;如果做预训练,批量大小可以大一些,因为数据集本身就很大。
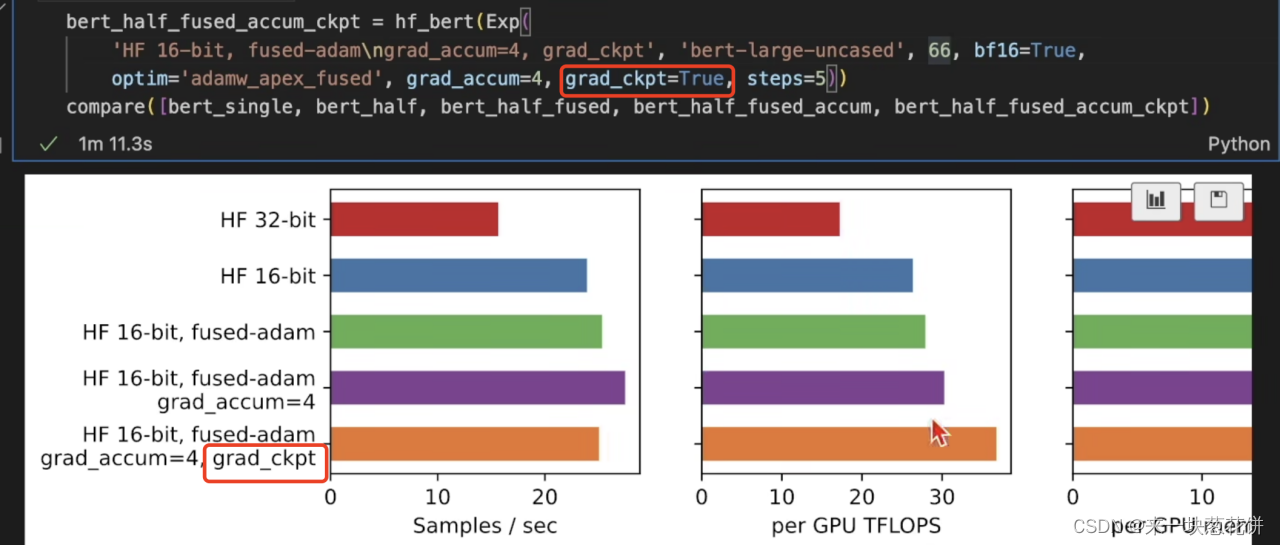
3.丢弃中间结果
前向运算的时候,每一层的中间结果都会被保存。
可以将中间的一些结果丢弃,节省内存消耗。等运算完最后输出,进行梯度反传的时候,再重新进行前向计算,重新得到中间结果。
增加一部分计算量,换取一部分内存空间,至少能让模型跑起来。
当模型真的非常大的时候,这一操作特别有用!可以用来增加批量大小。
Megatron模型库
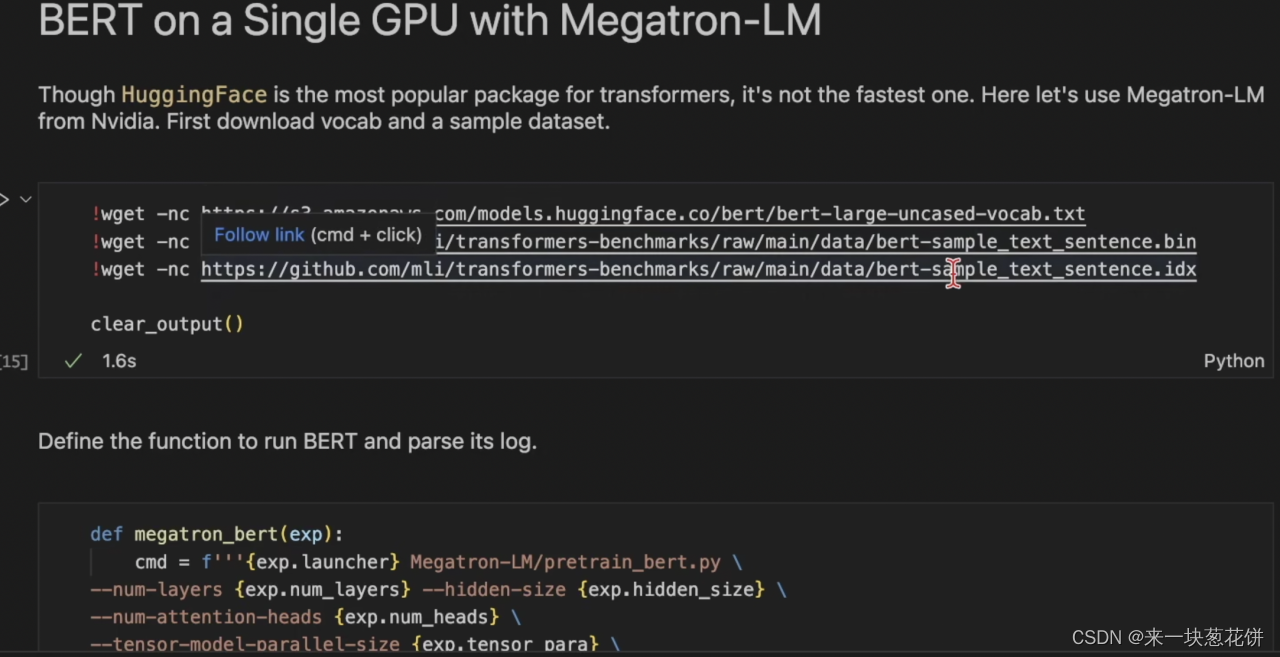
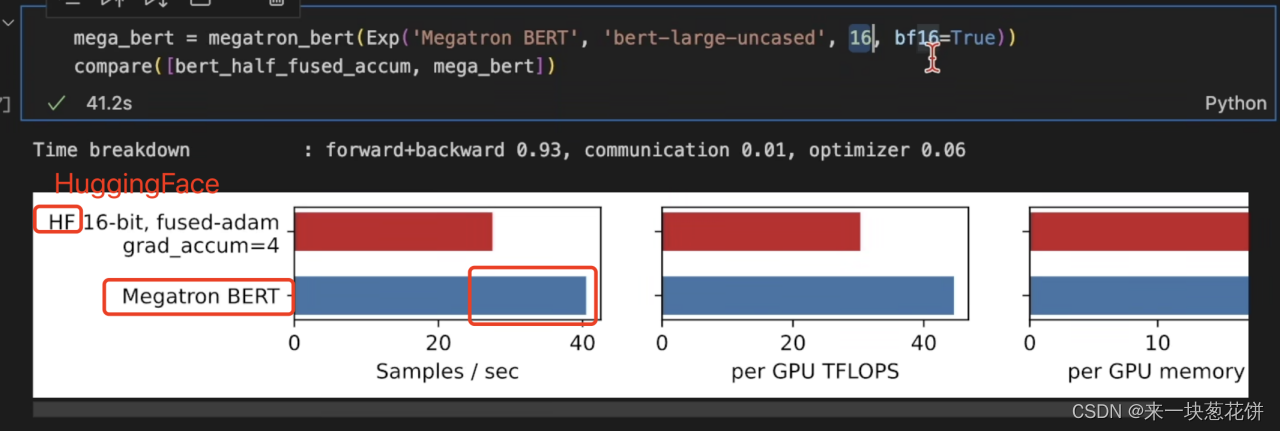
Megatron模型库性能好,是因为自己手写了很多算子:

优化总结
1.尽量增加批量大小(提高训练效率)
2.尽量使用16位的浮点数(降低中间结果占用内存数目)
3.使用Megatron这样的模型库(对重点算子,进行了手写,优化性能)
4.多卡性能
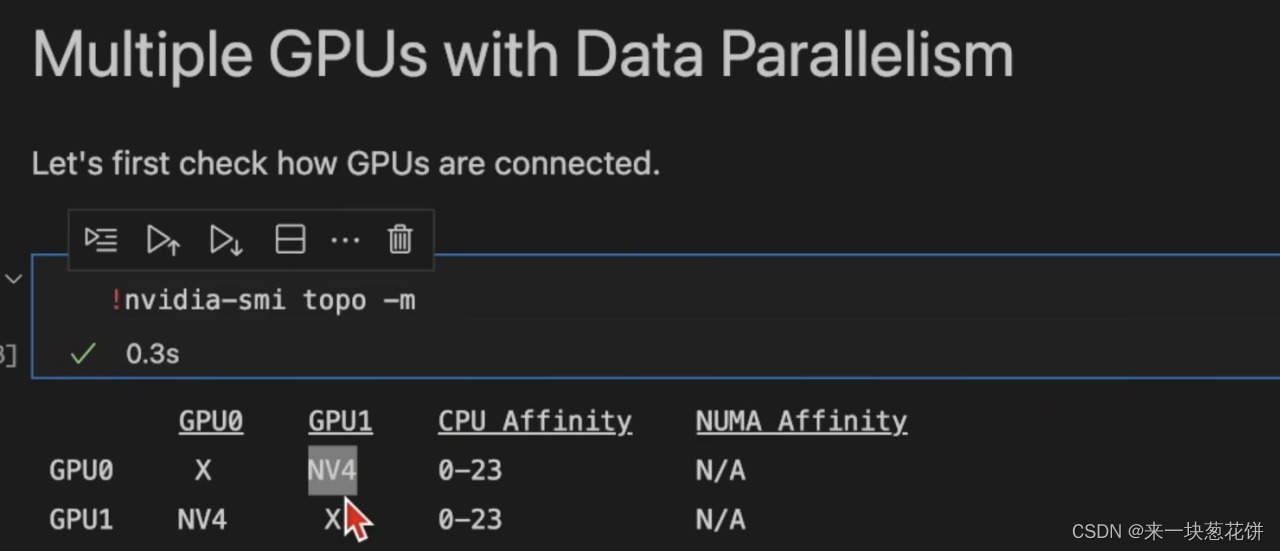
NV4表示两张卡使用四条nv-link进行两张GPU的连接。
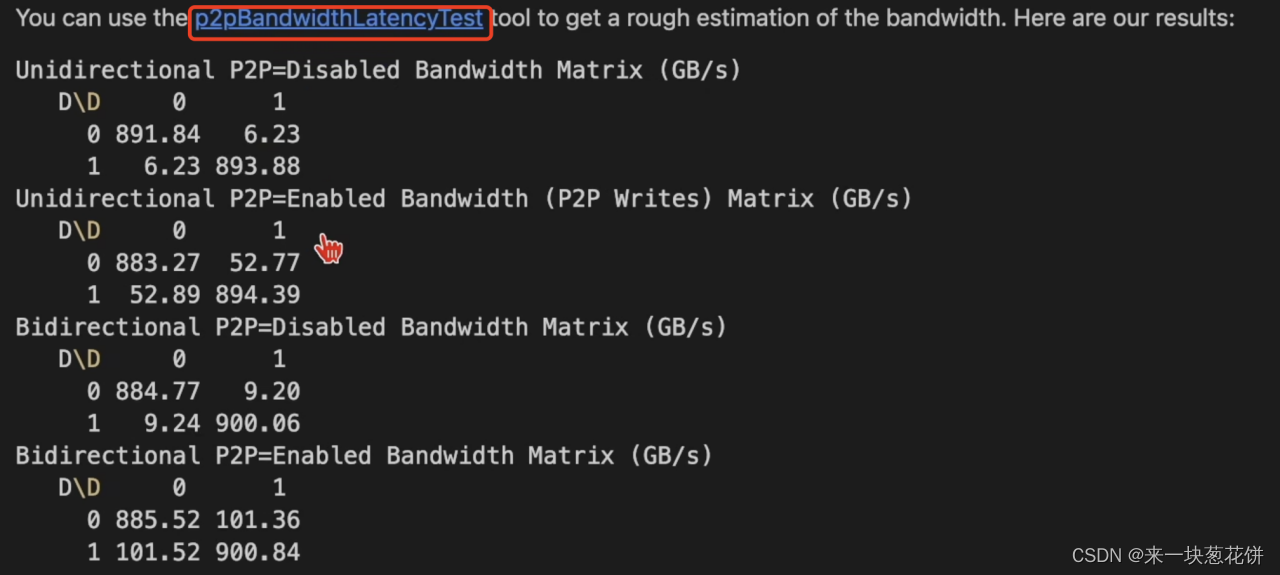
使用一个脚本进行gpu之间的带宽的测试。
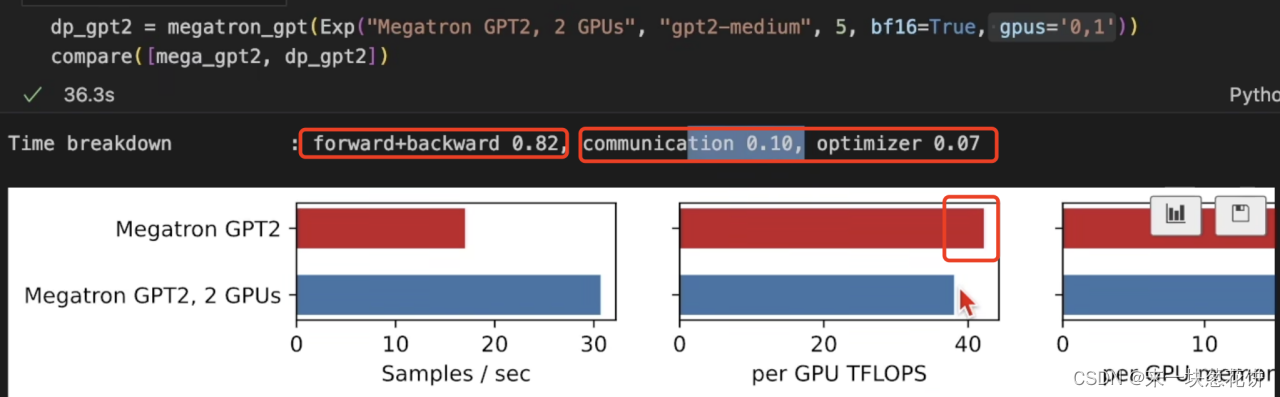
由于除了前向计算和反向计算,通信和模型更新还占用了新能。
所以一张GPU变为两张GPU,性能并没有翻倍。(只有一张GPU,并不需要GPU间的通信)
数据并行
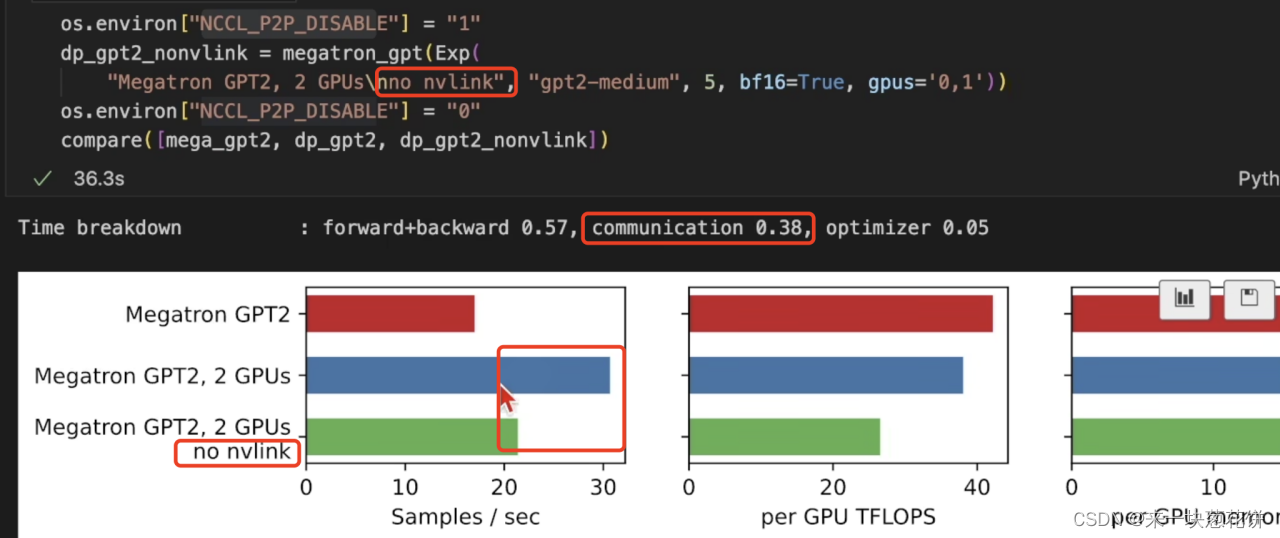
没有使用nv-link,导致通信减慢,耗时明显增加。
nv-link可以增加带块,每次通信可以多传输信息,减少每一轮的通信次数。
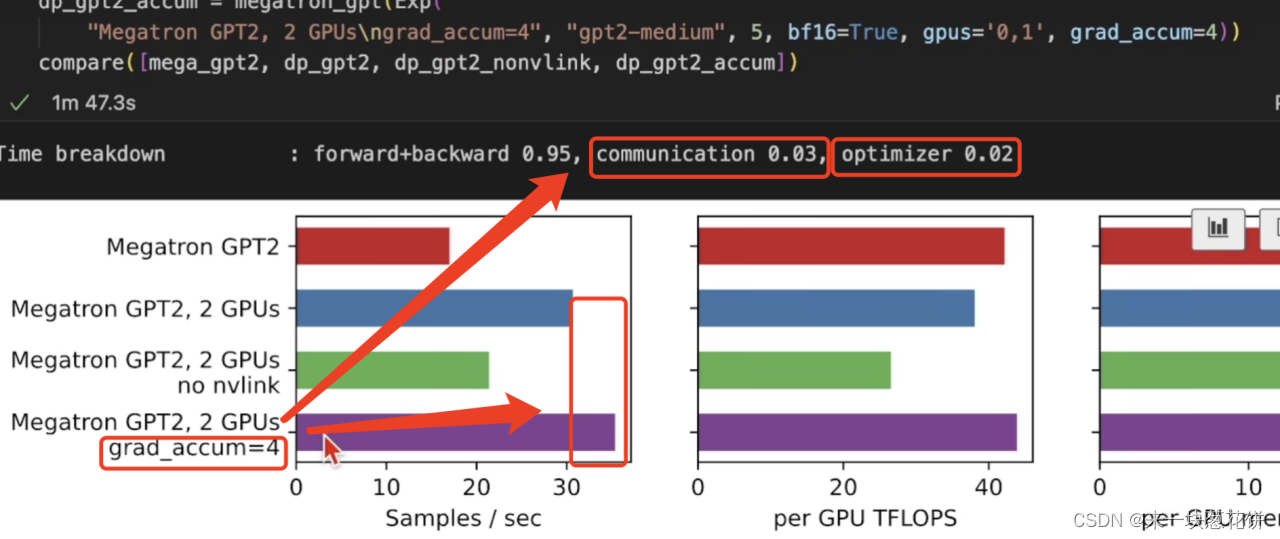
数据并行的时候,每次梯度更新,GPU间都要进行通信。
所以使用梯度累加(grad-accum),减少梯度更新次数,从而减少通信次数,可以提高性能。
张量并行
如果有2张GPU,则将每一层的张量计算,拆为两部分。每个GPU计算完一部分张量后,再进行通信的交互。
好处是每张GPU的计算量减少了,坏处是需要计算和通信必须是串行的。
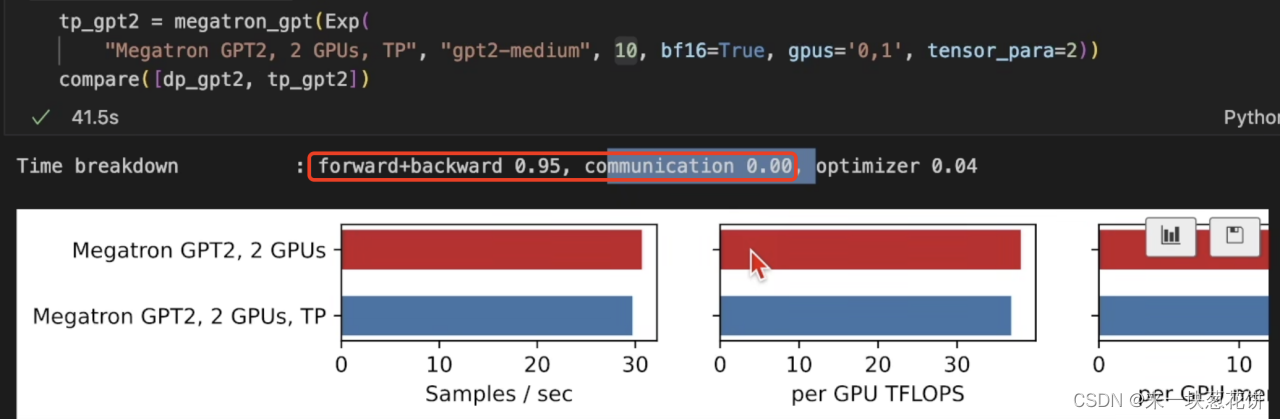
这里无法计算通信事件,因为通信时间都在前向计算和反向计算里了。
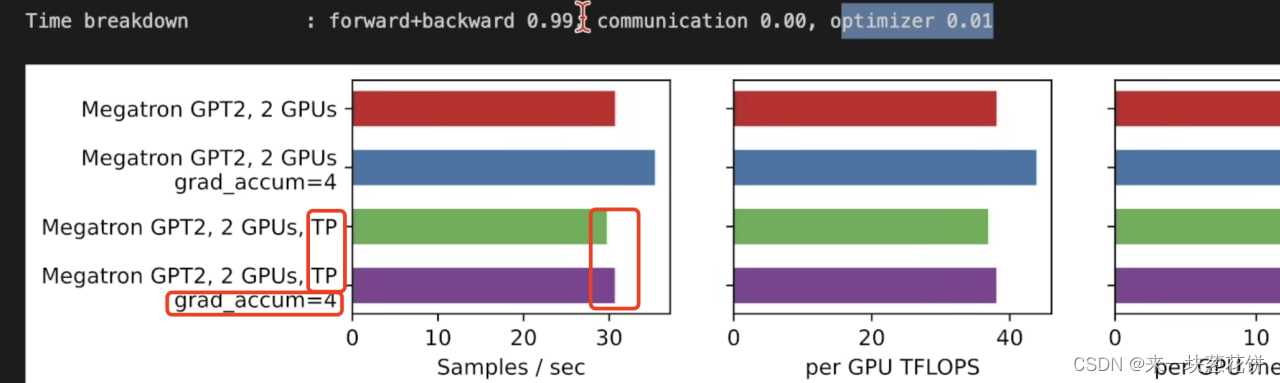
TP表示张量并行。TP的时候,梯度累加效果很小。因为通信次数已经很多了,就算减少梯度更新的次数,也没用。
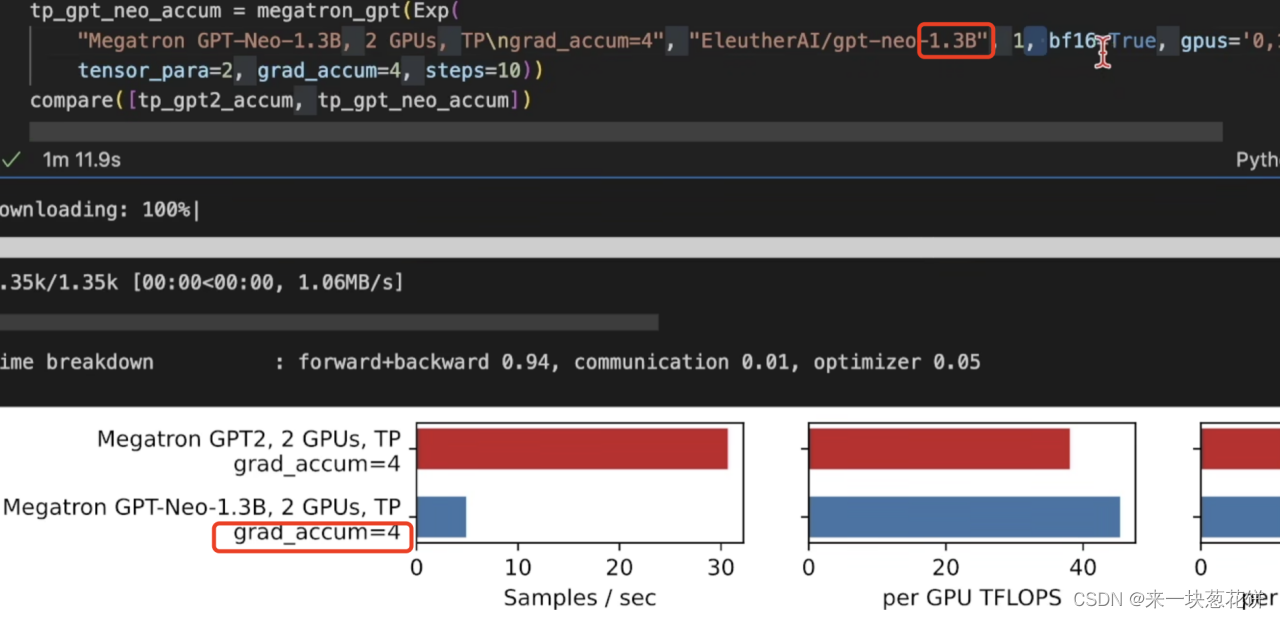
张量并行的好处是,可以训练大模型(比如1.3B的参数量)。将每一层的运算在多个卡上计算。否则,批量大小为1也跑不起来。
由于参数量太大,所以梯度更新、进行优化的时间占比就比较大。所以使用梯度累加,还是有一些效果的。
ZeRO并行

使用ZeRO2,是将整个模型和adam里的状态,将梯度进行切分,每个GPU只需要维护一部分。
这样可以显著降低模型相关的内存占用,可以训练更大的模型。
5.结论
训练大模型的方法
1.使用足够大的批量大小。
一方面可以使得单个的算子的性能上升。另一方面可以降低模型梯度更新和通信带来的额外开销。
处理方法:1.GPU内存更大。2.使用16位运算。3.kernal fusion合并运算。4.梯度累加。5.梯度的ckpt记录中间结果。
但是特别大批量大小,会使得算法收敛变慢,需要更多的迭代才能使得算法收敛。
微调的时候,数据规模小,就不能使用太大的批量大小。预训练的时候,可以使用更大的批量大小。
当GPU数目特别大(成百上千)的时候,每张卡分配到的批量大小也会缩小,这个也需要改变。
2.并行运算
优先在单卡内部做数据并行。因为通信消耗少。
多卡并行。
ZeRO并行。划分模型和中间状态。
张量并行。将每一层的计算切开。
3.设备性能
nvi-link优化通信。
更大内存的GPU。