UUID介绍
UUID
Universally Unique Identifier:通用唯一识别码
使用某种规则,不是某种中心化的自增方式,来保证这个识别码的全局唯一性
生成规则: RFC4122来进行定义。
根据生日悖论,若每秒产生 10 亿笔 UUID,100 年后只产生一次重复的概率是 50%。如果地球上每个人都各有 6 亿笔 UUID,发生一次重复的概率是 50%。产生重复UUID 并造成错误的情况非常低,是故大可不必考虑此问题。
最早被用于阿波罗网络计算系统(Apollo Network Computing System) 和微软的 Windows 平台,如今 OpenStack 也广泛的使用它来标志计算、存储和网络等资源
GUID :
- 微软按照 UUID 的规则实现的一套方法。
- 目的:保证全局唯一性。
- 微软已经使用 GUID 在 Windows 的 COM,ActiveX 等技术上了。
- 注意:
- UUID 本质是有多种版本的,
- GUID 也是在不同的使用场景实现的是不同的 UUID 版本,
- 比如 COM 是使用 UUID 版本1 进行实现的
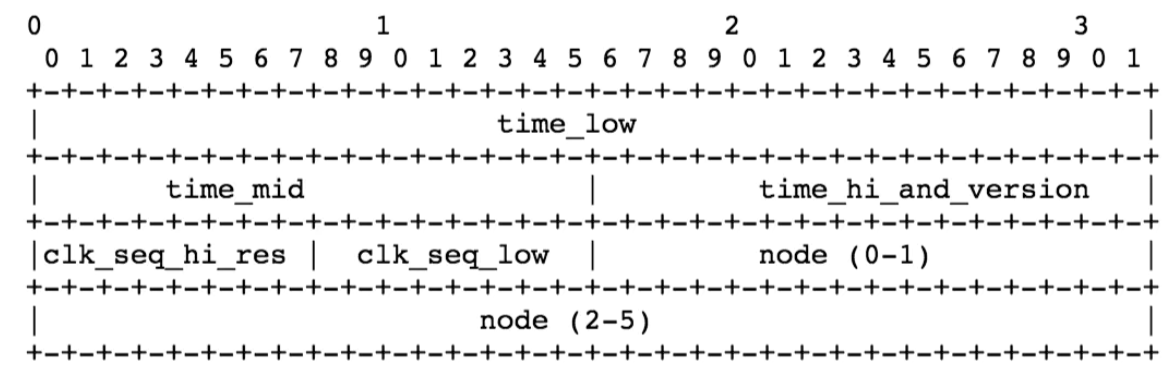
1、构成:
长度:128bit 16字节,换算成16进制数(32个16进制)加上中间杠隔开
格式:xxxx xxxx-xxxx-Mxxx-Nxxx-xxxx xxxx xxxx(8-4-4-4-12)
M:UUID版本,1,2,3,4,5
N:8、5、a、b
可变因子
- 时间戳
- 时钟序列
- 节点信息(机器)—MAC地址
1.1、时间戳
Timestamp
60bit 无符号数
- version为1:1582-10-15 00:00:000000000 到当前UTC时间,每隔100纳秒加1
- 对于无法获取UTC时间的系统,统一采用
localtime。(实际上一个系统时区相同就可以了)。 - time_low:0-31bit,32bit
- time_mid: 32-47bit,16bit
- time_hi_and_version: 包含两部分,version和time_h1
- version 占用 bit 数为4. 代表它最多可以支持31个版本(2^4 -1)
- time_hi:剩余的12bit,一共是16bit
1.2、时钟序列(clock sequence)
- 如果计算 UUID 的机器进行了时间调整,或者是
nodeId变化了(主机更换网卡),和其他的机器冲突了。那么这个时候,就需要有个变量因子进行变化来保证再次生成的 UUID 的唯一性。 Clock Sequence的变化算法很简单,当时间调整,或者nodeId变化的时候,直接使用一个随机数/在原先的Clock Sequence值上面自增加一也是可以的。- 共14bit
- clock_seq_low:0-7bit 共8bit
clock_seq_hi_and_reserved包含两个部分:clock_seq_hi: 8~13 bit 共6个bit,reserved:2bit,reserved一般设置为10。
- 发生时间回调或者更换网卡时:
- 如果之前的 clock sequence 存在,则增大 clock sequence 的值
- 如果之前不存在 clock sequence,则随机生成一个 clock sequence
1.3、node - 节点信息(机器)
- Node 是一个 48 bits 的无符号数,
- 对于 version 为 1 的 UUID,它选取 IEEE 802 MAC 地址,即网卡的 MAC 地址。
- 当系统有多块网卡时,任何一块有效的网卡都可被做 Node 数据;
- 对于没有网卡的系统,取值为随机数。
- 不同的主机在任何时刻生成的 UUID 均不相同。
2、版本:
统共有5个版本
结构均相同。
这个结构是按照版本1进行定义的,只是在其他版本中,版本1中的几个变量因子都进行了变化。
version1:
- 严格按照时间戳+时钟序列+节点信息组成变量因子
- 一些分布式系统场景下是能严格保证全局唯一
- twitter 的 snowflake 可以看作是是 UUID 版本1 的简化版。
- 算法:
- 从数据表读取(读取需加锁)曾经被用于生成 UUID 的 timestamp, clock sequence 和 node 等信息
- 获取当前的 timestamp
- 获取当前的 node 信息
- 如果第 1 步读取信息失败,或者读取的 node 与当前的 node 不一致,生成一个随机的 clock sequence
- 如果 timestamp 比当前的 timestamp 小,clock sequence 调大
- 把当前 timestamp,node 和 clock sequence 存入数据表
- 根据当前的 timestamp,node 和 clock sequence 生成 UUID,细节如下:
- time_low 为 timestamp[28:59]
- time_mid 为 timestamp[12:27]
- time_hi_and_version[4:15] 为 timestamp[0]…timestamp[11]
- time_hi_and_version[0:3] 为 0001
- clock_seq_low 为 clock_sequence[6:13]
- clock_seq_hi_and_reserved[2:7] 为 clock_sequence[0:5]
- clock_seq_hi_and_reserved[0:1] 为 10
- node 为 MAC[0:47]
version2:
- 基本和版本1一致,
- 主要多DCE(IBM 的一套分布式计算环境)
- 参考:https://pubs.opengroup.org/onlinepubs/9668899/chap1.htm
- 把时间戳的前4位置换为POSIX的UID或GID。
- 很少使用
version3:
-
变量因子:基于name和namespace 的hash
-
hash算法:md5
-
其中的name 和namespace 基本上和我们很多语言的命名空间,类名一样,它的基本要求就是,name + namespace 才是唯一确定hash串的标准
-
一样的namespace + name 使用相同的hash算法(比如version3的md5)计算出来的结果必须是一样的,但是不同的 namespace 中的同样的 name 生成的结果是不一样的。
System.out.println(UUID.nameUUIDFromBytes("myString".getBytes("UTF-8")).toString());//version为3
version4:
-
变量因子:随机/伪随机
-
jdk1.8默认使用
-
timestamp,clock sequence, node都是随机或者伪随机的
System.err.println(UUID.randomUUID().toString());
version5:
- 变量因子:基于name和namespace 的hash
- hash算法:sha1
- 同三