【零基础学爬虫】第五章:scrapy框架的使用(一)
目录
一、安装scrapy
①我使用anaconda安装,步骤如下:
注意:如果手动pip安装,需要安装很多依赖包,所以用anaconda很方便
twisted:为scrapy提供异步下载相关操作
pywin32:①捕获窗口 ②模拟鼠标键盘动作 ③自动获取某路径下文件列表 ④PIL截屏功能
conda install scrapy

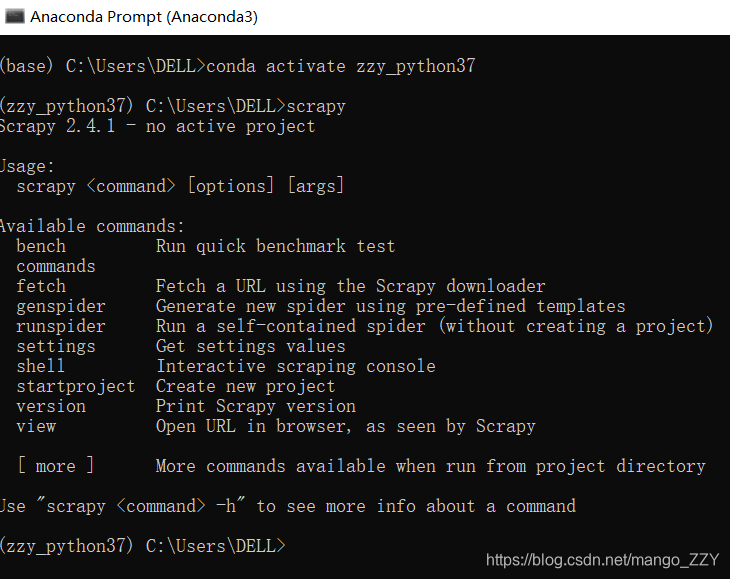
②输入scrapy,检测安装成功!
二、创建scrapy工程
1.点击pycharm左下角的terminal,在终端中输入如下命令:
scrapy startproject firsttest(工程名)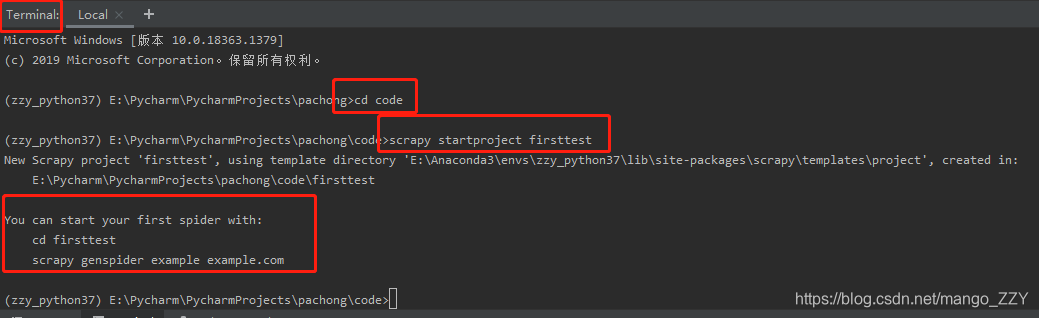
2.创建爬虫文件
创建成功后,目录下就会出现创建的工程文件。
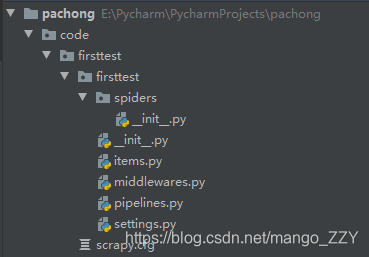
—spiders文件夹叫爬虫文件夹,或爬虫目录,在spiders的子目录中要创建一个爬虫文件。相关操作如下:
首先要进入该工程中:
cd firsttest
然后输入如下命令:(爬虫文件名字不能和工程名相同,后面的url可以临时写一个,在文件中还可以改)
scrapy genspider spiderName www.xxx.com 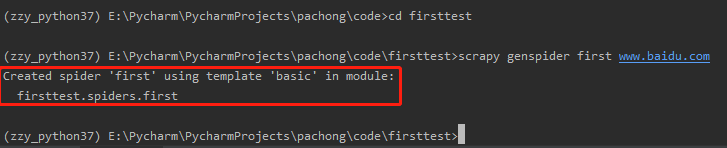
—settings.py是我们当前工程的配置文件。(经常使用)
3.分析爬虫文件(first.py)
点开文件,有一个类,类名就是创建的文件名+Spider,该类的父类是Spider,Spider属于scrapy中的一个类,它是scrapy中所有爬虫类的父类。
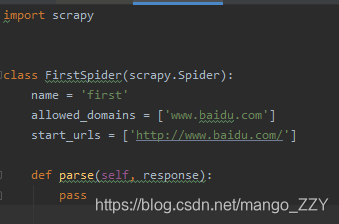
文件中有三个属性和一个方法,解释见代码:
import scrapy
class FirstSpider(scrapy.Spider):
# 爬虫文件的名称:就是爬虫源文件的一个唯一标识
name = 'first'
# 允许的域名:用来限定start_urls列表中,哪些url可以进行请求发送。但是通常不会用它
#allowed_domains = ['www.baidu.com']
# 起始的url列表:该列表中存放的url会被scrapy自动进行请求的发送,可以放多个url
start_urls = ['http://www.baidu.com/','http://www.sogou.com/']
# 用作于数据解析:response参数表示的就是请求成功后对应的响应对象。parse调用的次数由start_urls列表中元素的个数决定。
def parse(self, response):
print(response)
# 之后可以执行代码,不要直接run,要在终端中执行。见下面的命令。三、执行工程
1.编写完代码后,在终端中输入如下命令,即可进行数据的爬取:
scrapy crawl spiderName
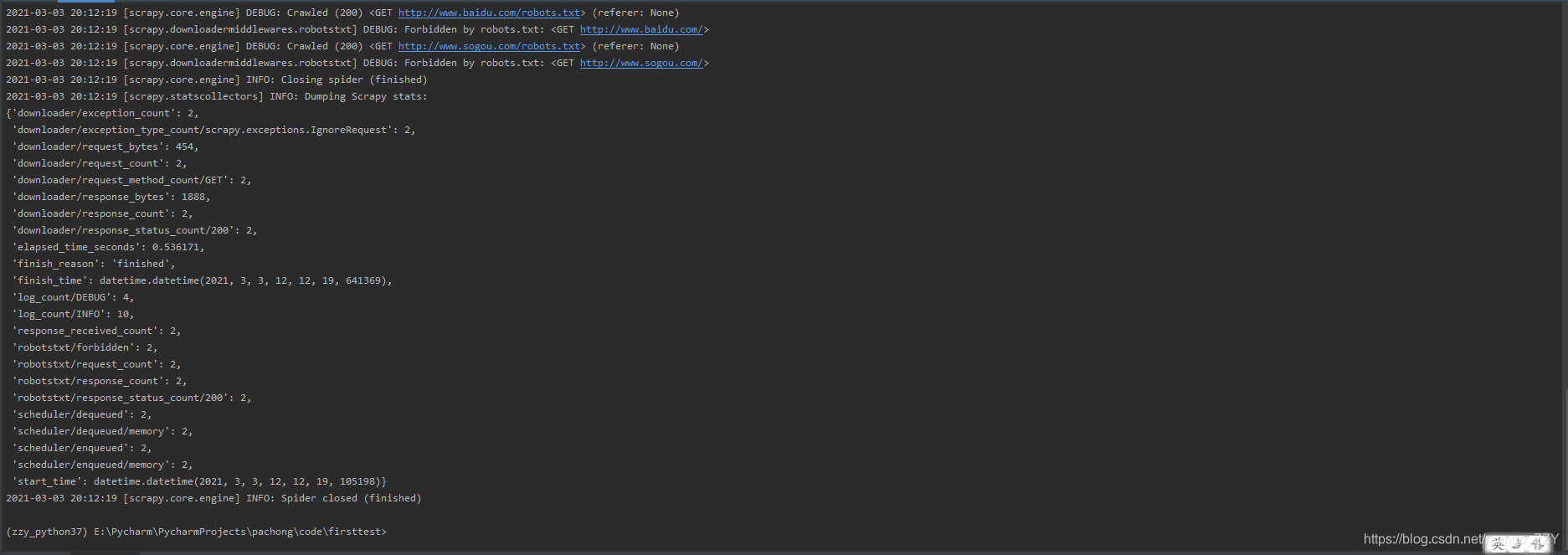
2.输出的是日志信息,如果运行中出现了错误,也会显示出来,但是输出中没有我们想要的response,原因如下:
INFO: Overridden settings:
{'BOT_NAME': 'firsttest',
'NEWSPIDER_MODULE': 'firsttest.spiders',
'ROBOTSTXT_OBEY': True,
'SPIDER_MODULES': ['firsttest.spiders']}
要在settings.py文件中修改 'ROBOTSTXT_OBEY': True——> 'ROBOTSTXT_OBEY': Flase
3.如果不想输出日志,可以使用如下命令,但是不能报错:
scrapy crawl first --nolog4.因此,可以在配置文件中添加如下命令:
# 显示指定类型的日志信息
LOG_LEVEL = 'ERROR'