【数据结构】TrieTree(字典树、前缀树)—— C++实现
前言
TrieTree(字典树、前缀树、单词查找树)
字典树,看名字好像和字符串相关。
如果你能看到这一篇文章,那么肯定学过字符串串匹配算法,即BF和KMP的模式匹配。
字典树并不是来解决字符串匹配问题,而是用于以下场景:
大量的单词(串),实现单词的排序功能、快速检索功能、前缀搜索功能…
文章目录
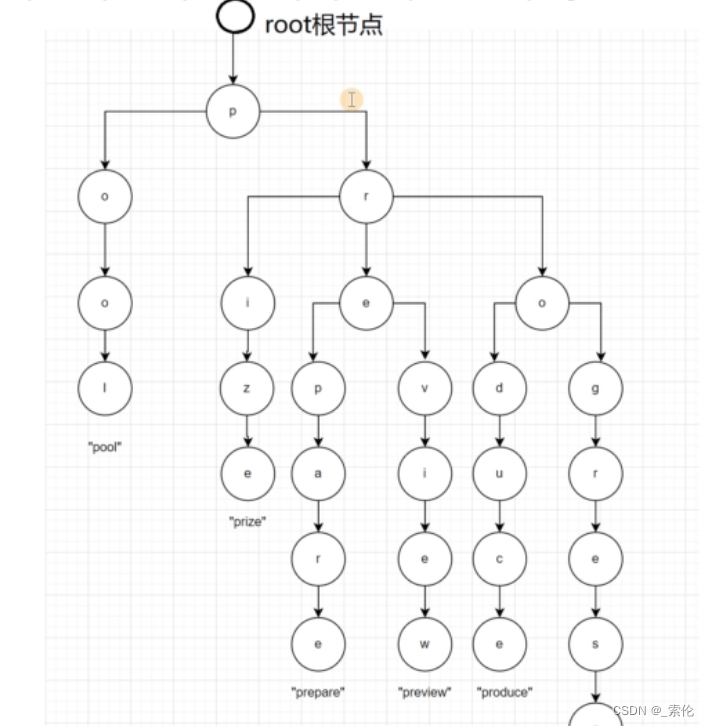
基本性质
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符;
- 从根节点到某一结点,路径上经过的字符连接起来,为该节点对应的字符串;
- 每个节点的所有子节点包含的字符都不相同。
适用范围:
- 单词检索
- 统计和排序字符串
- 字符串前缀检索
算法核心
利用字符串的公共前缀来减少查询时间,最大限度的减少无畏的字符串比较。
时间复杂度
字典树查找效率很高,时间复杂度是O(m),m是要查找的单词中包含的字母的个数。
图示:pool、prize、preview、prepare、produce、progress
在一些代码实现中,会在单词的结尾处设置一个类似于isend的标记。例如:hello和hel。
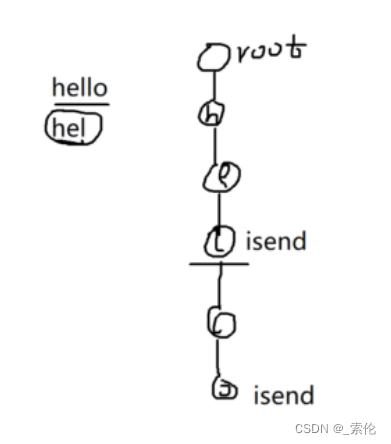
但是这样存储携带的信息太少,这样只知道树中有这个单词,但不知道该单词出现过几次,所以一般会在单词的最后一个字符节点,添加一个freqs标记,记录该单词出现过几次。
一、TrieTree节点的设计
需要的成员为:
- 存储字符的变量;
- 存储单词频率的变量;
- 存储孩子节点字符数据和节点指针的对应关系;因为要实现一个自动排序的前缀树,所以这里采用的是STL中的红黑树map<>。
#include <iostream>
#include <map>
using namespace std;
class TrieTree
{
private:
struct TrieNode
{
TrieNode(char ch, int freqs)
: ch_(ch)
, freqs_(freqs)
{}
// 节点存储的字符数据
char ch_;
// 单词的末尾字符存储单词的数量(频率)
int freqs_;
// 存储孩子节点字符数据和节点指针的对应关系
map<char, TrieNode*> nodeMap_;
};
private:
TrieNode* root_; // 根节点
};
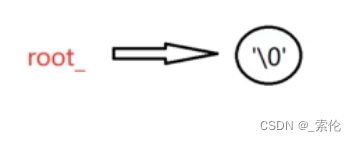
因为TrieTree的根节点不存放任何字符,所以这里实现一个构造函数:
public:
TrieTree()
{
root_ = new TrieNode('\0', 0);
}
二、添加单词串——add()
思路:
定义一个cur指针指向根节点;
遍历当前单词的字符,如果孩子有当前字符数据的节点,则移动cur指向当前节点,遍历下一个字符;
如果没有孩子节点,则创建相应的节点,移动cur指向当前节点,遍历下一个字符。
// 添加单词
void add(const string& word)
{
TrieNode* cur = root_; // 1
for (int i = 0; i < word.length(); ++i)
{
auto childIt = cur->nodeMap_.find(word[i]); // 2
if (childIt == cur->nodeMap_.end()) // 3
{
// 表示相应字符的节点没有,创建它
TrieNode* child = new TrieNode(word[i], 0);
cur->nodeMap_.emplace(word[i], child);
cur = child;
}
else
{
// 相应的字符节点存在,移动cur指向对应的字符节点 // 4
cur = childIt->second;
}
}
// cur指向word单词的最后一个节点 // 5
cur->freqs_++;
}
- 定义一个指向根节点的指针;
- 遍历单词的每个字符,利用STL的find()查找当前字符,返回一个迭代器;
- 如果该迭代器指向end(),说明没找到当前字符,则创建新节点child,并将该新节点插入到cur的nodeMap_中。最后让cur指向child;
- 如果迭代器没有指向end(),说明相应的字符节点存在,则移动cur指向对应的字符节点,这里就是让cur指向迭代器的second (TrieNode类型的指针节点);
- 退出循环后,cur就指向单词的最后一个字符节点,这时候对该节点的freqs加一。(这里不是直接置为1,因为之前这个位置可能已经存在单词)
三、查询单词——query()
// 查询单词
int query(const string& word)
{
TrieNode* cur = root_; // 1
for (int i = 0; i < word.length(); ++i) // O(m)
{
auto childIt = cur->nodeMap_.find(word[i]); // 2
if (childIt == cur->nodeMap_.end())
{
return 0;
}
// 移动cur指向的下一个单词的字符节点上
cur = childIt->second; // 3
}
return cur->freqs_; // 4
}
- 定义一个指向根节点的指针;
- 遍历单词的字符,在当前节点cur的nodeMap_里查找,返回迭代器类型,如果没有找到,则直接返回0;
- 如果当前字符存在,则移动cur,将其指向下一个单词的字符节点上,这里就是让其指向迭代器的second(TrieNode类型的指针);
- 如果整个单词都能遍历完,说明该单词确实存在,则返回这个单词出现的频率freqs_。
add()和query()的测试
添加一些带有公共前缀的数据:
int main(void)
{
TrieTree trie;
trie.add("hello");
trie.add("hello");
trie.add("hel");
trie.add("hel");
trie.add("hel");
trie.add("China");
trie.add("ch");
trie.add("ch");
trie.add("helloworld");
cout << trie.query("hello") << endl;
cout << trie.query("hel") << endl;
cout << trie.query("ch") << endl;
return 0;
}
四、前序遍历字典树
#include <vector>
#include <string>
// 前序遍历字典树
void preOrder()
{
string word;
vector<string> wordList;
preOrder(root_, word, wordList); // 1
for (string word : wordList)
{
cout << word << endl;
}
cout << endl;
}
private:
// 前序遍历字典树
void preOrder(TrieNode* cur, string word, vector<string>& wordList)
{
// 前序遍历 VLR
if (cur != root_) // V // 2
{
word.push_back(cur->ch_);
if (cur->freqs_ > 0) // 3
{
// 已经遍历到一个有效单词
wordList.emplace_back(word);
}
}
// 递归处理孩子节点
for (auto pair : cur->nodeMap_) // 4
{
preOrder(pair.second, word, wordList);
}
}
- 前序遍历,这里编写的是递归函数,首先定义两个输出参数word和wordList,一个存放当前单词,一个存放遍历到的单词;
- 进入递归函数,边界条件为:如果当前节点没有指向根节点,那么就可以把当前节点的字符添加到word字符串里;
- 如果遇到freqs_大于0,说明这各位置存在一个单词,则把当前word记录到wordList中;
- 递归处理孩子节点,这里遍历的是当前节点的nodeMap_,递归后又递归孩子的孩子节点,相当于做一个深度优先遍历。
前序遍历测试
int main(void)
{
TrieTree trie;
trie.add("hello");
trie.add("hello");
trie.add("hel");
trie.add("hel");
trie.add("hel");
trie.add("china");
trie.add("ch");
trie.add("ch");
trie.add("helloworld");
cout << trie.query("hello") << endl;
cout << trie.query("hel") << endl;
cout << trie.query("ch") << endl;
cout << "===========================" << endl;
trie.preOrder();
return 0;
}
可以看出完全根据字典顺序输出单词,如果有比较多的公共前缀,那么处理起来效率会很高,而如果单词都不同,时间复杂度、特别是空间复杂度会很高。
五、前缀搜索功能——prefix()
// 串的前缀搜索
vector<string> queryPrefix(const string& prefix)
{
TrieNode* cur = root_; // 1
for (int i = 0; i < prefix.length(); ++i) // 2
{
auto childIt = cur->nodeMap_.find(prefix[i]);
if (childIt == cur->nodeMap_.end()) // 3
{
return {};
}
cur = childIt->second; // 4
}
// 循环退出,cur就指向了前缀的最后一个字符节点了
vector<string> wordList;
preOrder(cur, prefix.substr(0, prefix.length() - 1), wordList); // 5
return wordList;
}
- 定义一个指向根节点的指针;
- 遍历前缀prefix的每个字符,在nodeMap_中查找,返回迭代器;
- 如果没找到当前字符,直接返回空的容器,这里返回的是一个空的初始化列表;
- 如果找到了,就让cur往下走;
- 循环退出后,cur指向了前缀的最后一个字符节点,这时候进行前序遍历,但第二个参数word此时是prefix,需要做出改变,因为前序遍历刚进去时候就把当前节点的字符添加到word里,如果直接把前缀传入,那么有这样的情况:前缀为pre,cur指向e这个字符,那么一进入前序遍历,就再次把e这个字符添加到word里,那么就会导致后续递归的时候返回的单词是pree…。所以传入前缀的时候需要减去前缀的最后一个字符比如pre只传入pr,使用substr()即可。
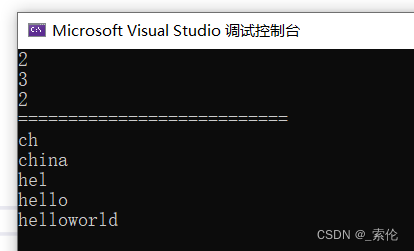
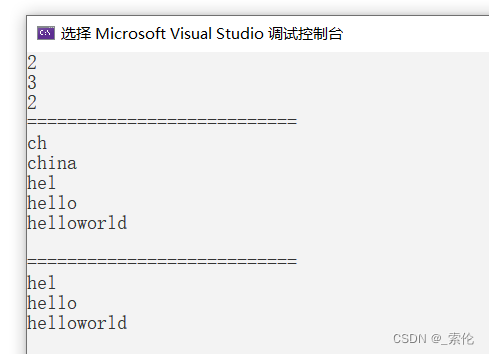
前缀搜索的测试
这里测试以he开头的
int main(void)
{
TrieTree trie;
trie.add("hello");
trie.add("hello");
trie.add("hel");
trie.add("hel");
trie.add("hel");
trie.add("china");
trie.add("ch");
trie.add("ch");
trie.add("helloworld");
cout << trie.query("hello") << endl;
cout << trie.query("hel") << endl;
cout << trie.query("ch") << endl;
cout << "===========================" << endl;
trie.preOrder();
cout << "===========================" << endl;
vector<string> words = trie.queryPrefix("he");
for (string word : words)
{
cout << word << endl;
}
cout << endl;
return 0;
}
输出hel、hello、helloworld
六、删除单词——remove()
析构函数
~TrieTree()
{
queue<TrieNode*> que;
que.push(root_);
while (!que.empty())
{
TrieNode* front = que.front();
que.pop();
// 把当前节点的孩子节点全部入队
for (auto& pair : front->nodeMap_)
{
que.push(pair.second);
}
// 释放节点资源
delete front;
}
}
删除代码解析
// 串的删除
void remove(const string& word)
{
TrieNode* cur = root_; // 1
TrieNode* del = root_;
char delch = word[0];
for (int i = 0; i < word.length(); ++i) // 2
{
auto childIt = cur->nodeMap_.find(word[i]);
if (childIt == cur->nodeMap_.end()) // 3
{
// 没找到相应字符
return;
}
// 有一个独立的单词,移动del指针 // 4
if (cur->freqs_ > 0 || cur->nodeMap_.size() > 1)
{
del = cur;
delch = word[i];
}
// cur移动到子节点
cur = childIt->second; // 5
}
// cur指向了末尾字符节点,word单词是存在的,接下来删除
if (cur->nodeMap_.empty()) // 6
{
// 删除
TrieNode* child = del->nodeMap_[delch];
del->nodeMap_.erase(delch);
// 释放相应的节点内存 // 7
queue<TrieNode*> que;
que.push(child);
while (!que.empty())
{
TrieNode* front = que.front();
que.pop();
// 把当前节点的孩子节点入队列
for (auto& pair : front->nodeMap_)
{
que.push(pair.second);
}
// 释放节点资源
delete front;
}
}
else
{
// 末尾字符还有字符节点,那么就不删除节点
// 只是把freqs变为0
cur->freqs_ = 0; // 8
}
}
- 定义两个TrieNode类型指针,一个cur指向当前节点,一个del指向待删除节点,再定义一个字符类型变量delch,指向待删除字符;
- 遍历这个待删除单词word,每次从当前节点的nodeMap_里找,返回迭代器类型;
- 如果没有当前字符找到,说明单词不存在,直接返回;
- 如果遍历过程中,发现当前节点对应的freqs_(单词出现次数)大于0,或者当前节点有多个孩子节点,说明遍历到这里,有一个独立的单词,那么就将删除指针del移动到当前节点位置,这里如果不理解,往下看,到释放内存的部分就可以理解了。同时也把删除字符delch指向当前字符;
- 常规操作,当前节点指针cur往下走,指向上面找到的字符节点;
- 退出循环后,表示当前想要删除的单词是存在的,cur也指向待删除单词的末尾结点,判断cur是否还有孩子节点(即判断cur的nodeMap_是否为nullptr),如果没有,这时候使用一个TrieNode类型的指针child保存del指针的nodeMap_[delch],并让del删除这个字符的孩子节点;
- 这里的释放内存操作,类似于析构函数,使用一个队列,先把child指针入队,遍历nodeMap_把孩子节点入队,依次释放(delete);
- 如果cur指向的节点的nodeMap_不为nullptr,说明末尾字符还有孩子节点,那么就不删除节点了,只把出现次数freqs_置为0。删除完成!
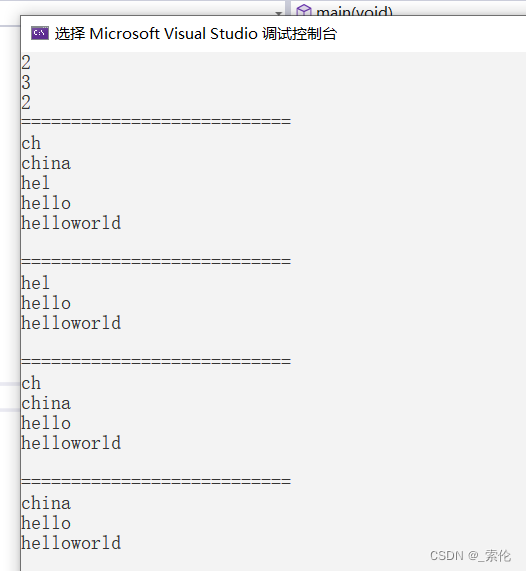
删除代码测试
int main(void)
{
TrieTree trie;
trie.add("hello");
trie.add("hello");
trie.add("hel");
trie.add("hel");
trie.add("hel");
trie.add("china");
trie.add("ch");
trie.add("ch");
trie.add("helloworld");
cout << trie.query("hello") << endl;
cout << trie.query("hel") << endl;
cout << trie.query("ch") << endl;
cout << "===========================" << endl;
trie.preOrder();
cout << "===========================" << endl;
vector<string> words = trie.queryPrefix("he");
for (string word : words)
{
cout << word << endl;
}
cout << endl;
trie.remove("hel");
cout << "===========================" << endl;
trie.preOrder();
trie.remove("ch");
cout << "===========================" << endl;
trie.preOrder();
return 0;
}
如图
应用场景
- 串的快速检索:给出N各单词组成的熟词表,以及一篇全用小写英文书写的文章,请你按最早出现的顺序写成所有不在熟词表中的生词。
- 单词自动完成:编辑代码时,输入字符,自动提示可能的关键字、变量或函数等信息。
- 最长公共前缀:对所有串建立字典树,对于两个串的最长公共前缀的长度即他们所在的节点的公共祖先个数,问题就转化为最近公共祖先问题。
- 串排序方面问题的应用:给定N各互不相同的仅由一个单词构成的英文名,将他们按照字典序从小到大输出。用字典树进行排序,这棵树的每个节点的所有儿子很明显地按照其字母大小排序。对这棵树进行前序遍历即可。
字典树的常用优化(待补充。。)
TrieTree完整代码
#include <iostream>
#include <map>
#include <string>
#include <vector>
#include <queue>
using namespace std;
class TrieTree
{
public:
TrieTree()
{
root_ = new TrieNode('\0', 0);
}
~TrieTree()
{
queue<TrieNode*> que;
que.push(root_);
while (!que.empty())
{
TrieNode* front = que.front();
que.pop();
// 把当前节点的孩子节点全部入队
for (auto& pair : front->nodeMap_)
{
que.push(pair.second);
}
// 释放节点资源
delete front;
}
}
// 添加单词
void add(const string& word)
{
TrieNode* cur = root_;
for (int i = 0; i < word.length(); ++i)
{
auto childIt = cur->nodeMap_.find(word[i]);
if (childIt == cur->nodeMap_.end())
{
// 表示相应字符的节点没有,创建它
TrieNode* child = new TrieNode(word[i], 0);
cur->nodeMap_.emplace(word[i], child);
cur = child;
}
else
{
// 相应的字符节点存在,移动cur指向对应的字符节点
cur = childIt->second;
}
}
// cur指向word单词的最后一个节点
cur->freqs_++;
}
// 查询单词
int query(const string& word)
{
TrieNode* cur = root_;
for (int i = 0; i < word.length(); ++i) // O(m)
{
auto childIt = cur->nodeMap_.find(word[i]);
if (childIt == cur->nodeMap_.end())
{
return 0;
}
// 移动cur指向的下一个单词的字符节点上
cur = childIt->second;
}
return cur->freqs_;
}
// 前序遍历字典树
void preOrder()
{
string word;
vector<string> wordList;
preOrder(root_, word, wordList);
for (string word : wordList)
{
cout << word << endl;
}
cout << endl;
}
// 串的前缀搜索
vector<string> queryPrefix(const string& prefix)
{
TrieNode* cur = root_;
for (int i = 0; i < prefix.length(); ++i)
{
auto childIt = cur->nodeMap_.find(prefix[i]);
if (childIt == cur->nodeMap_.end())
{
return {};
}
cur = childIt->second;
}
// 循环退出,cur就指向了前缀的最后一个字符节点了
vector<string> wordList;
preOrder(cur, prefix.substr(0, prefix.length() - 1), wordList);
return wordList;
}
// 串的删除
void remove(const string& word)
{
TrieNode* cur = root_;
TrieNode* del = root_;
char delch = word[0];
for (int i = 0; i < word.length(); ++i)
{
auto childIt = cur->nodeMap_.find(word[i]);
if (childIt == cur->nodeMap_.end())
{
// 没找到相应字符
return;
}
// 有一个独立的单词,移动del指针
if (cur->freqs_ > 0 || cur->nodeMap_.size() > 1)
{
del = cur;
delch = word[i];
}
// cur移动到子节点
cur = childIt->second;
}
// cur指向了末尾字符节点,word单词是存在的,接下来删除
if (cur->nodeMap_.empty())
{
// 删除
TrieNode* child = del->nodeMap_[delch];
del->nodeMap_.erase(delch);
// 释放相应的节点内存
queue<TrieNode*> que;
que.push(child);
while (!que.empty())
{
TrieNode* front = que.front();
que.pop();
// 把当前节点的孩子节点入队列
for (auto& pair : front->nodeMap_)
{
que.push(pair.second);
}
// 释放节点资源
delete front;
}
}
else
{
// 末尾字符还有字符节点,那么就不删除节点
// 只是把freqs变为0
cur->freqs_ = 0;
}
}
private:
struct TrieNode
{
TrieNode(char ch, int freqs)
: ch_(ch)
, freqs_(freqs)
{}
// 节点存储的字符数据
char ch_;
// 单词的末尾字符存储单词的数量(频率)
int freqs_;
// 存储孩子节点字符数据和节点指针的对应关系
map<char, TrieNode*> nodeMap_;
};
private:
// 前序遍历字典树
void preOrder(TrieNode* cur, string word, vector<string>& wordList)
{
// 前序遍历 VLR
if (cur != root_) // V
{
word.push_back(cur->ch_);
if (cur->freqs_ > 0)
{
// 已经遍历到一个有效单词
wordList.emplace_back(word);
}
}
// 递归处理孩子节点
for (auto pair : cur->nodeMap_)
{
preOrder(pair.second, word, wordList);
}
}
private:
TrieNode* root_;
};
int main(void)
{
TrieTree trie;
trie.add("hello");
trie.add("hello");
trie.add("hel");
trie.add("hel");
trie.add("hel");
trie.add("china");
trie.add("ch");
trie.add("ch");
trie.add("helloworld");
cout << trie.query("hello") << endl;
cout << trie.query("hel") << endl;
cout << trie.query("ch") << endl;
cout << "===========================" << endl;
trie.preOrder();
cout << "===========================" << endl;
vector<string> words = trie.queryPrefix("he");
for (string word : words)
{
cout << word << endl;
}
cout << endl;
trie.remove("hel");
cout << "===========================" << endl;
trie.preOrder();
trie.remove("ch");
cout << "===========================" << endl;
trie.preOrder();
return 0;
}