深度学习框架的发展历程
现在深度学习框架已经这么多了,为什么还有这么多人不断推出新的深度学习框架?
这个问题问的非常好,想要看看目前为什么这么多深度学习框架的出现,还真的不得不回头看看深度学习框架出现的历史趋势,然后去理解目前深度学习发展,给框架带来的要求,就会明白除了政治因素之外,新的深度学习框架推出原因。
首先我们来看看AI框架具体有什么用呢?
AI在现实生活中发挥的作用越来越多,不知不觉我们用的越来越多的产品都内嵌了AI功能,包括我现在给你们录制视频的字幕,都是纯AI算法进行识别和时间轴对齐的。就好像,不提自家产品有AI功能,都显得落伍了。下面来随机看看几款产品。

在全球迎来移动互联网后,基本上人手一台移动手机,一台手机算上前后置摄像头,动辄像华为P50 Pro有6个摄像头,少则前置摄像头1个后置摄像头1个。移动视觉领域的发展当然离不开AI的身影。以花瓣视频剪辑APP为例,视频里面的人脸贴图功能,当XXX明星出轨X、吸毒X、睡粉X,这时候需要后台剪辑小哥人工和谐掉,使用了AI人脸贴上马赛克功能后,“妈妈再也不但担心我要加班打码了”。当然这个功能,不是单凭一个算法,就可以实现。首先,我们需要有一个算法,这个算法只是一些数学公式,接着使用AI框架提供的接口,来实现这些数学公式,实现完后,我们还需要使用AI框架,长期稳定地在手机里面小小的一块芯片上运行,这就需要AI软件对硬件资源的调度、跟操作系统的协同。
所以,简单来说AI框架,就是实现数学算法的软件工具,释放硬件澎湃的算力。
到了第二点,下面来看看AI发展过程当中,所使用到的一些工具。
20世纪30年代,通用计算机还没有出现之前,实际上人们还不知道“算法”是什么。不过,当时数学领域中已经有很多问题都是跟“算法”密切相关,有大量跟计算性理论相关的研究。
正是这个年代,图灵在二战的时候思考智能与可计算问题,提出了图灵机,用于任何人类能够完成的逻辑推理和计算过程,从而慢慢形成算法的概念。在这之前,“计算”能力是被视为与“思考”相类似的人类抽象能力,大家一时间很难接受“计算”可以被如此简单的模型所概括。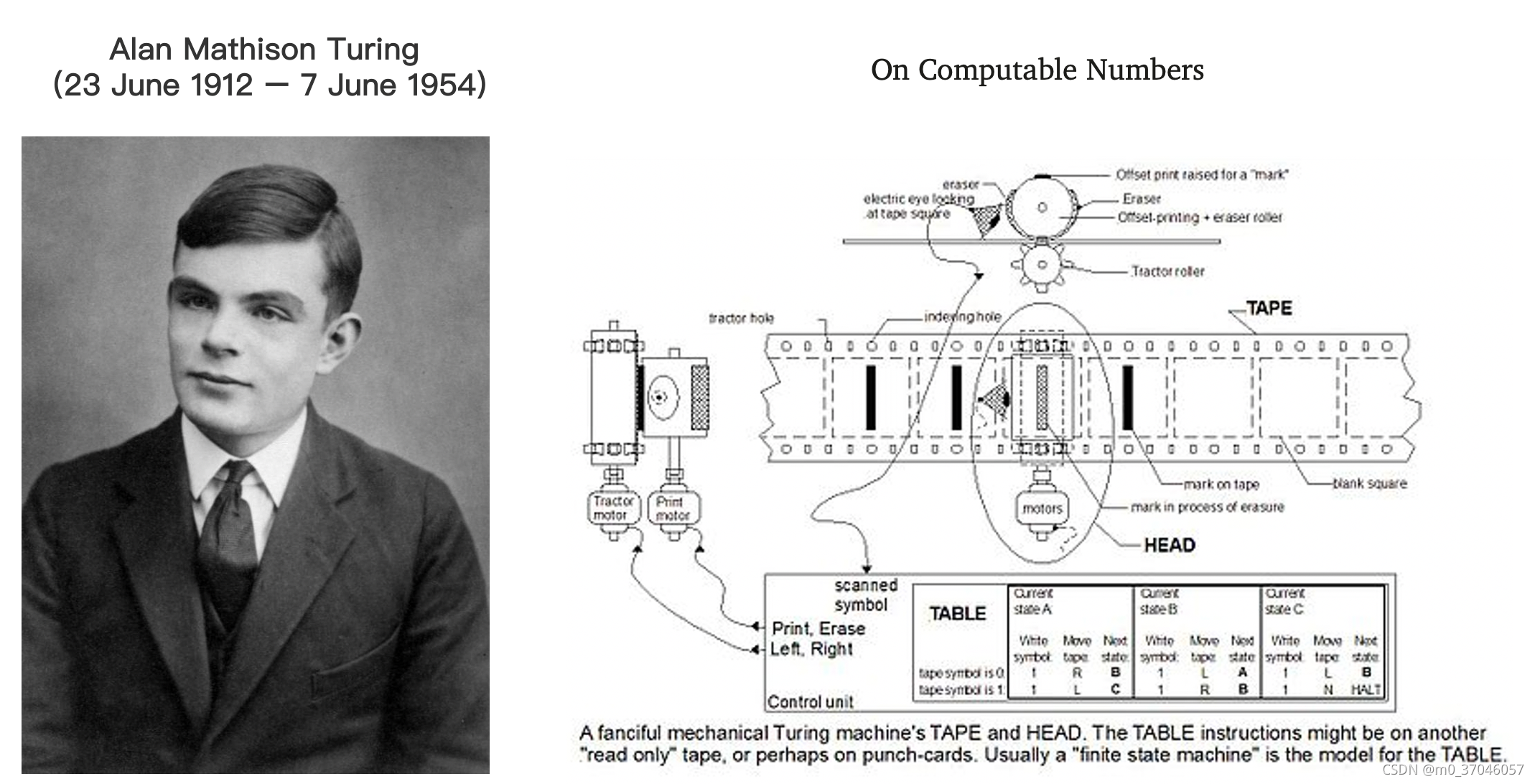
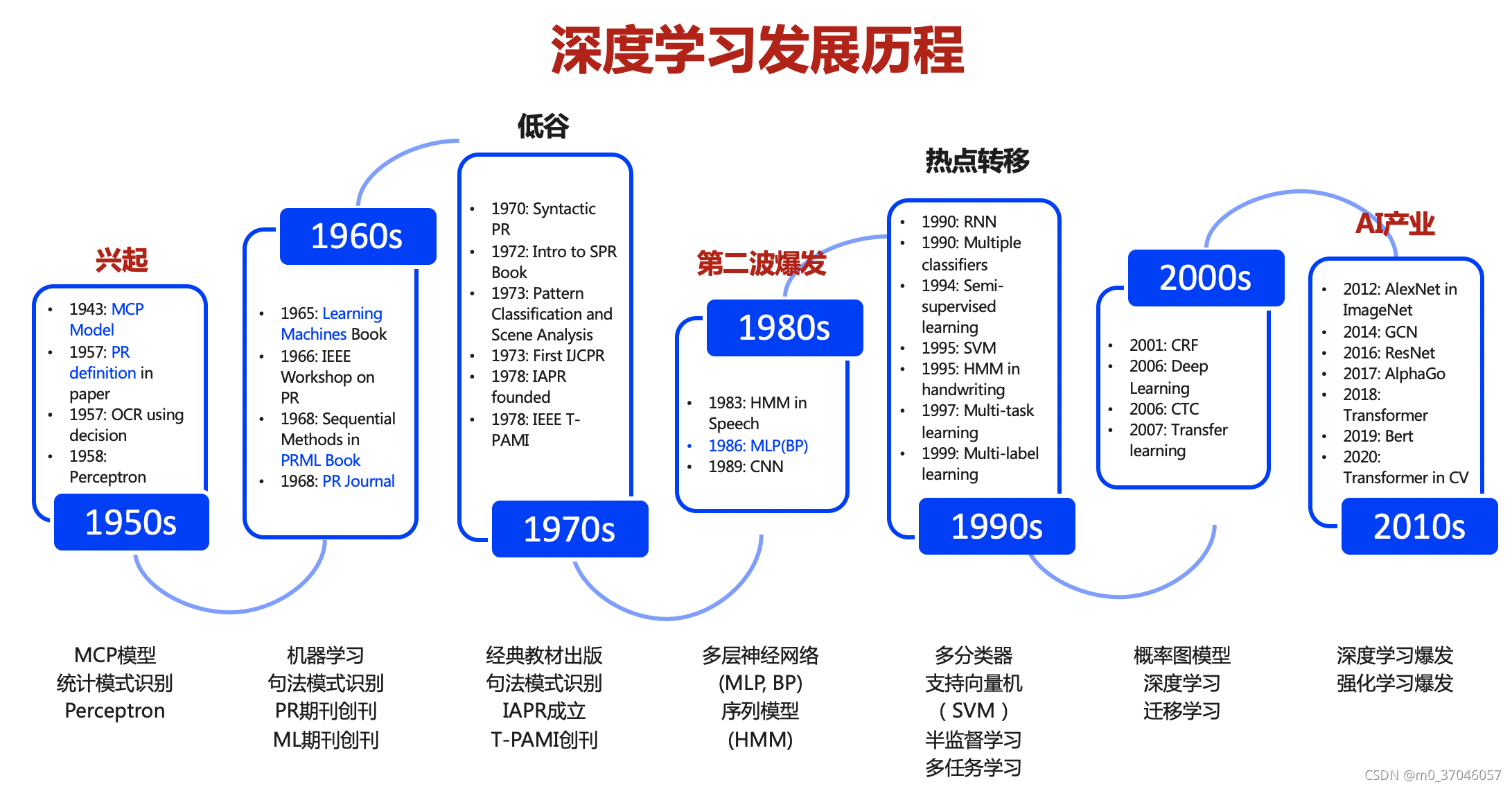
1943年,麦卡洛克(W.S.McCulloch)和 皮兹(W.Pitts) 联合发表的论文里面,给出了人工神经元的第一个数学模型,神经网络第一个模型(MCP模型)的提出,也只是单纯一个数理逻辑概念。那时候,世界上第一台计算机还没有诞生。图灵只是给智能和算法进行了定义和思考。
1957年我国大跃进年代,Rosenblatt 提出由两层神经元组成一个神经网络,称之为感知器(Perceptrons),并且在他的论文里面详细地介绍感知器的具体硬件实现电路方案,还具体地给出了感知器具体学习算法,就是利用梯度下降法,对损失函数计算极小值,求出可将输入数据进行,线性划分的分离超平面,从而求得感知器模型。 
1986年,美国IBM发布了第一台笔记本电脑,同一年里Geoffrey Hinton发表了能够在多层感知器(MLP)上快速计算梯度的反向传播(Back propagation)算法,也就是我们经常说的BP算法,这时候Hinton不需要自行实现硬件,而是基于微型计算机的操作系统之上的算法程序来实现的。 
了解完算法的定义、计算机的出现到深度学习算法的发展,现在来看看AI框架的发展历程,聊聊AI框架的出现原因和对AI产业的意义。
进入2010年后,随着深度学习的使用越来越广泛,于是便开始出现了AI框架,通过软件来快速实现深度学习算法。从图中,我们可以看到Theano作为第一个支持深度学习框架,到了2012年开始后,开始慢慢每隔1-2年就出现两三个新的AI框架。
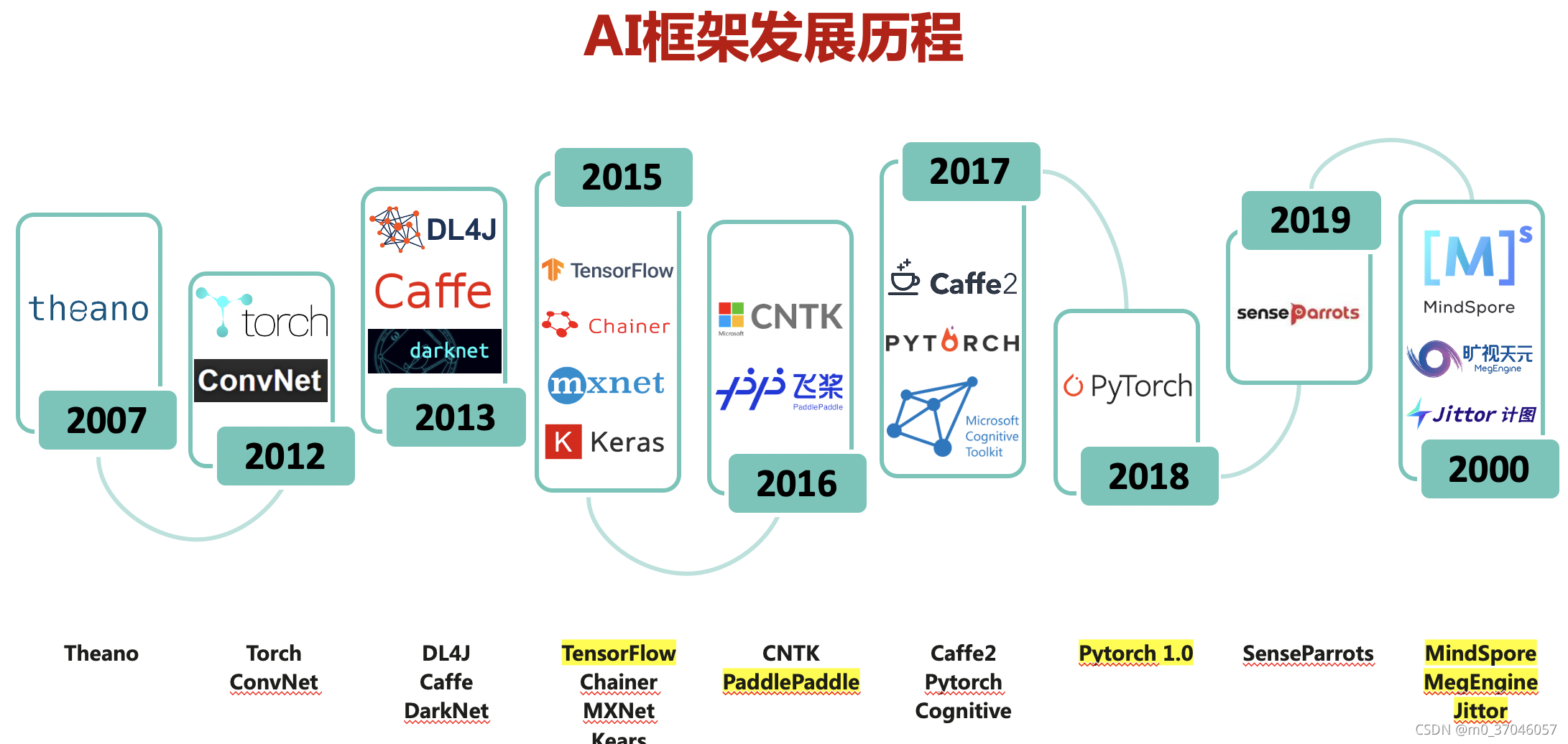
早期学术界针对深度学习框架主要有Theano、ConvNet、Caffe和Torch等。刚推出的时候主要是面向学术研究而设计,进行一些小规模的原型算法研究,像是Theano能够利用符号化式语言定义深度学习算法公式,然后运行在硬件设备上。而2012年Alex觉的Theano并不能进行分布式和并行计算,于是使用C++实现了ConvNet框架,实现AlexNet算法,并且利用两块GPU进行并行加速训练和推理功能,最终赢得2012年ImageNet图像分类比赛冠军。
人工智能正是在近十几年来形成革命性地爆发。从学术理论研究,到生产应用的产品化开发过程中,通常会涉及到多个不同的步骤,这使得人工智能开发,依赖的环境安装、部署、测试,以及不断迭代改进算法准确性,推理性能调优的工作变得非常繁琐耗时。AI框架从学术的研究,慢慢随着深度学习只能做个简单的文字识别分类,到图像目标检测、语义分割,扩展到文字识别、文字生成,语音翻译等不同的领域,乃至现在的AI+科学计算,在电磁仿真、蛋白质折叠、移动视觉等应用范围也越来越广。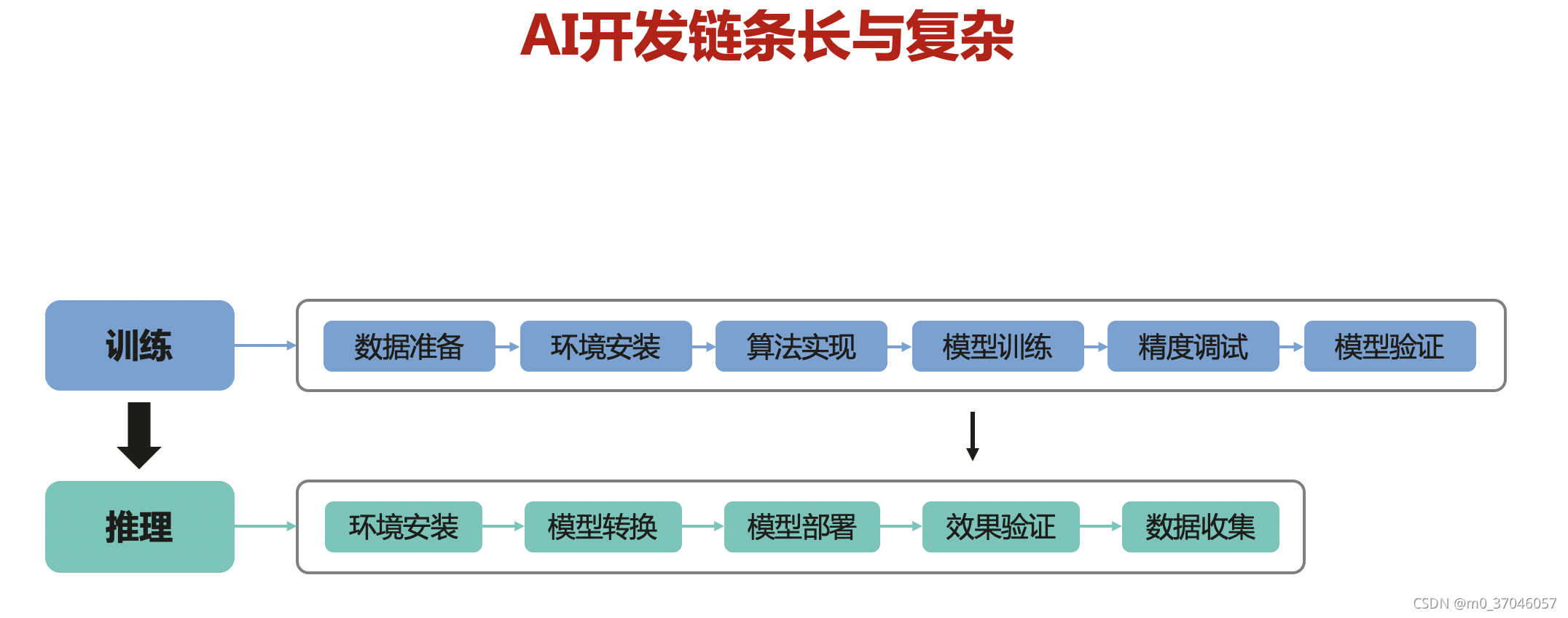
既然AI这么火,流程这么复杂,为了简化、加速和优化AI的流程,于是产业界开始纷纷入局AI,开发并完善了多个基础的平台和通用工具,这时候AI的基础软件开始被称为深度学习框架或者AI框架。有了这些基础的平台和工具,就可以避免大家重复发明轮子,专注于AI领域的算法研究和产品创新。到现在为止,产业界有Google领导的TensorFlow,Amazon选择押注的MXNet,Facebook倾力打造的PyTorch,Huawei主推开源的MindSpore等不同的AI框架出现。

如果你要问我,这么多框架应该选择哪个?还真不好说,因为AI还在快速发展,前几年出现的框架,到现在为止,基本上剩下图中黄色的,仍然活跃在业界,大部分都AI框架都沉寂下去了。
----
最后便是未来AI框架的研究意义和挑战。
AI开发者追求的是易用,尤其在训练方面,易用框架的生态会建立得非常快。由于AI领域发展很快,新特性的快速支持,能够吸引更多开发者和研究者留存。性能方面,反而在前期对开发者来说不是那么重要,因为在训练上更关注开发的效率、算法原型设计的效率,更少关注的是硬件成本。
对推理部署来说,在实际的生产业务系统里,希望追求极致的性能。推理业务对企业来说,部署量非常大的,假如能够把性能做好,5个百分点的性能提升能节省5%的硬件成本和耗电量,还可以减少机房部署的额外开销,对于企业来说是实际的账面收益。
由此可见,训练测讲究易用性,端侧讲究性能。一方面,AI框架在训练测,开始逐渐地跟端侧推理融合,推理框架直接基于芯片运行,脱离可操作系统还可以进行少量的学习,赋能芯片智能。另外一方面,随着AI在安全、大模型、科学计算、物理模拟、蛋白质折叠等场景对AI应用领域的拓展,会新增越来越多的功能。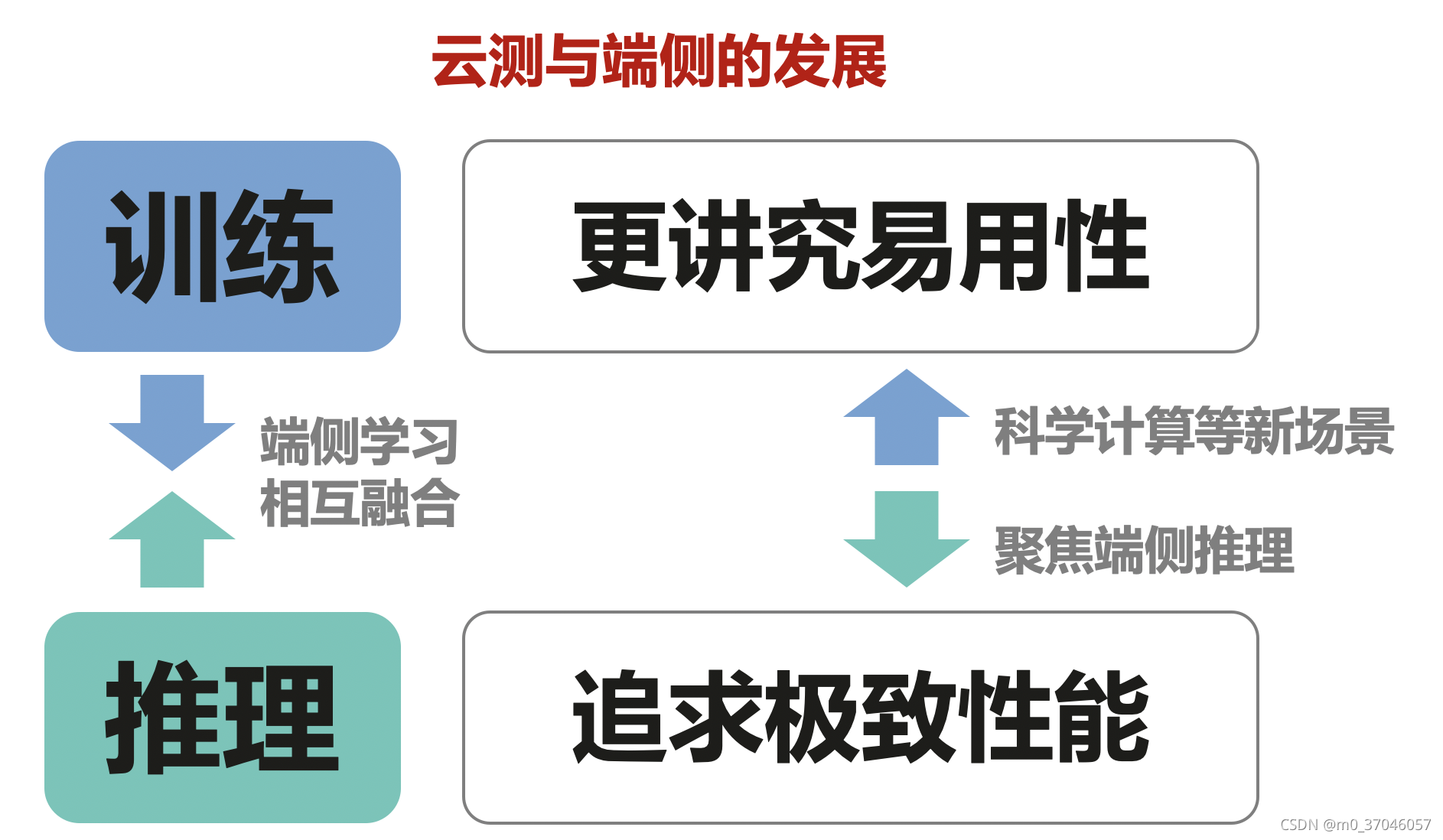
[AI系统] 1.3 AI框架的兴起
欢迎大家关注我的知乎和Bilibili账号:ZOMI酱