【JVM】(内存区域划分 为什么要划分 具体如何分 类加载机制 类加载基本流程 双亲委派模型 类加载器 垃圾回收机制(GC))
内存区域划分
为什么要划分
JVM启动的时候会申请到一整个很大的内存区域,JVM是一个应用程序,要从操作系统这里申请内存,JVM就需要根据,把空间,分成几个部分,每个部分各自有不同的功能作用.
具体如何分
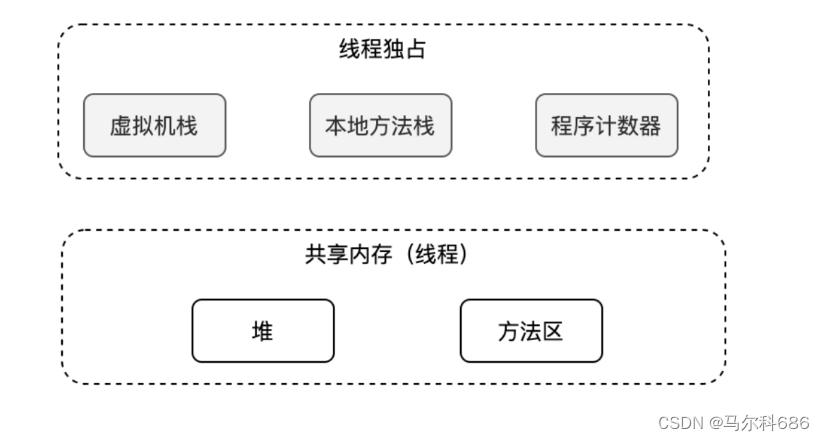
堆 存放new出来的对象
方法区/元数据区,存放类对象(类加载之后,存放的位置)
栈 存放方法之间的调用关系
程序计数器 存放每个线程,下一条要执行的指令的地址

类加载机制
类加载基本流程
java代码会被编译成.class文件(包含一些字节码),java程序要想运行起来,就需要让jvm读取到这些.class文件,并且把里面的内容,构造成类对象,保存到内存的方法区中。所谓的执行代码就是调用方法。
书上和官方文档把类加载过程分成了5个步骤。
- 加载:找到.class文件,打开文件,读取到文件内容。
- 验证:.class文件是一个二进制的格式。(某个字节,都是具有特定含义的),就需要验证你当前读到的这个格式是否符合要求。
- 准备:给类对象分配内存空间。(只分配内存空间,没有初始化,此时空间上的内存的数值是0,此时如果尝试打印类的static成员,就是全0的)
- 解析:针对类对象中包含的字符串常量进行处理,进行一些初始化操作。(java代码中用到的字符串常量在编译之后也会进入到.class文件中)这个过程也叫做:把“符号引用”(文件偏移量)替换成“直接引用”(内存地址)。
- 初始化:针对类对象进行初始化,把类对象中需要的各个属性都设置好,还需要初始化好static成员,还需要执行静态代码块,还可能需要加载一下父类。
双亲委派模型
属于类加载中,第一个步骤“加载”过程中国,其中的一个环节。
负责根据全限定类名找到.class文件。
所谓的“双亲委派模型”就是一个查找优先级问题。
类加载器
是JVM中的一个模块,在JVM中内置了三个类加载器。
- BootStrap ClassLoader
- Extension ClassLoader
- Application ClassLoader
上述三个类加载有父子关系,3是子 2是父 3是爷。

双亲委派模型过程:
类加载的过程(找class文件的过程)
- 给定一个类的全限定类名,形如java.lang.String。
- 从Application ClassLoader作为入口,开始执行查找的逻辑。
- Application ClassLoader,不会立即去扫描自己负责的目录(负责的是搜索项目点前目录和第三方库对应的目录)而是把查找的任务,交给他的父亲,Extension ClassLoader。
- Extension ClassLoader 也不会立即去扫描自己负责的目录,(负责的是JDK中一些扩展的库,对应的目录)而是把查找的任务,交给他的父亲,BootStrap ClassLoader。
- BootStrap ClassLoader 也不想立即扫描自己负责的目录,(负责的是标准库的目录),也想把任务交给它的父亲,结果发现自己没有父亲,因此BootStrap ClassLoader只能亲自负责扫描,标准库的目录。java.lang.String这种类就能够在标准库中,找到对应的.class文件,就可以进行打开文件,读取文件后续操作。此时查找.class文件的过程就结束了。但是,如果给定的类不是标准库的类,任务仍然会被交给孩子来执行。
- 如果没有扫描到就会回到Extension ClassLoader。Extension ClassLoader就会扫描负责的扩展库的目录,如果找到,就执行后续的类加载操作,此时查找过程结束,如果没找到,还是把任务交给孩子来执行。
- 没有扫描到,就会回到Application ClassLoader,Application ClassLoader就会负责扫描当前目录和第三方库的目录,如果找到,就会执行后续的类加载操作,如果没找到,就会抛出一个ClassNotFoundExcepton。
之所以搞这一套流程,主要目的是为了确保,标准库的类,被加载的优先级最高,其次是扩展库,最后是自己写的类和第三方库。


垃圾回收机制(GC)
让JVM自行判定,某个内存是否就不再使用了,如果这个内存后面确实不用了,JVM就会自动的把这个内存给回收掉,此时就不必要让程序员自己手动写代码回收。
GC这么好为什么C++不引入GC呢?
- 系统缺陷,需要一个/一些特定的线程,不停的扫描内存中的所有的对象,看是否能够回收。此时是需要额外的内存 + CPU资源的。C++要考虑能兼容一些配置特别低的系统。
- 效率问题,这样的扫描线程,不一定能够及时的释放内存(扫描总是有一定周期的),一旦同一时刻,出现大量的对象都需要被回收GC产生的负担就会很大,甚至引起整个程序都卡顿。(STW问题 stop the world)。
GC是垃圾回收,GC回收的目标是内存中的对象,对于Java来说就是new出来的对象。栈里的局部变量,是跟随栈帧的生命周期走的。(方法执行结束,栈帧销毁,内存自然释放)
静态变量,生命周期就是整个程序,这个始终存在,就意味着静态变量是无需释放的。
GC可以理解成两个大的步骤:
- 找到垃圾
- 引用计数(Python PHP)
new出来的对象,单独安排一块空间,来保存一个计数器。
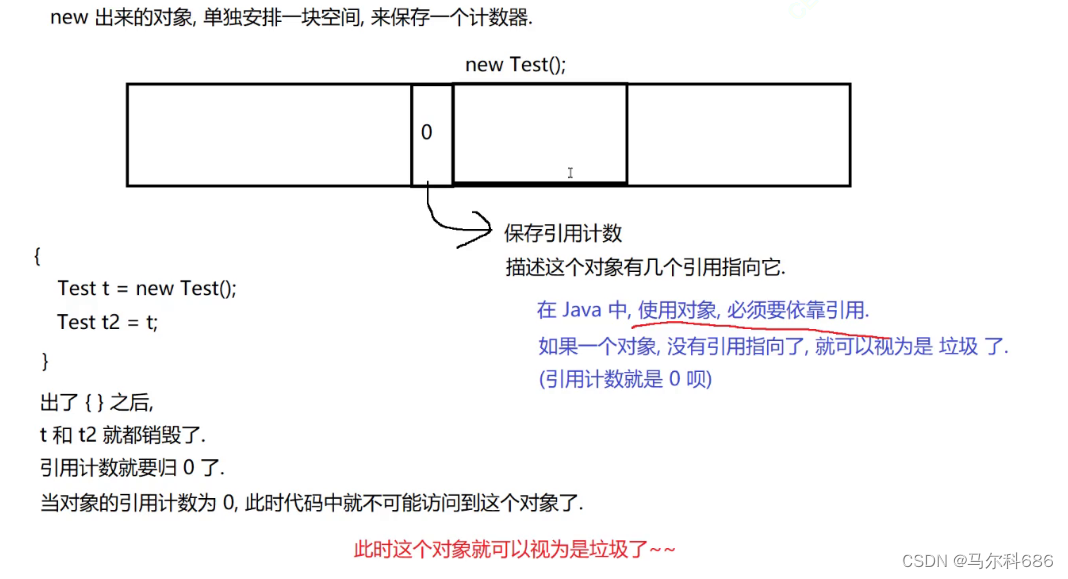
缺陷:
1.浪费内存

2.引用计数机制,存在“循环引用”问题。
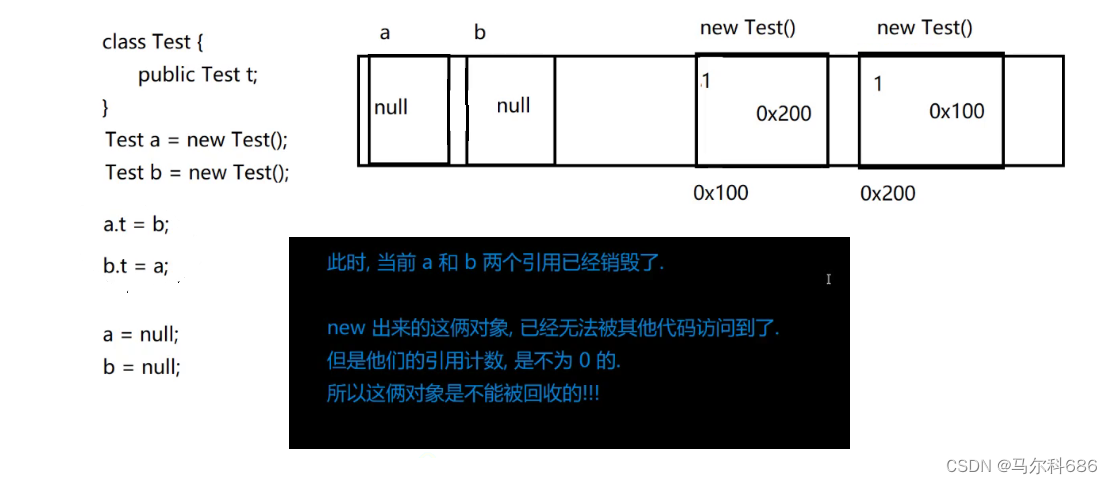
此时第一个对象和第二对象互相引用,要想使用第一个对象,就需要先拿到第二个对象,如果想要拿到第二个对象,又得先拿到第一个对象,这里就非常像死锁。
- 可达性分析(Java)
本质上就是时间换空间这样的手段,有一个/一组线程,周期性的扫描我们代码中所有的对象。(从一些特定的对象触发,尽可能的进行访问的遍历,把所有能够访问到的对象都标记成“可达”,反之经过扫描之后,未被标记的对象就是垃圾(“不可达”)了)
可达性分析出发点很多,不仅仅是所有的局部变量,还有常量池中引用的对象,还有方法区中的静态引用的变量。 这些统称为GCRoots。
可达性分析都是周期性进行的,当前某个对象是否是垃圾,是随着代码的执行,会发生改变。(可达性分析比较消耗系统资源,开销比较大)
- 回收垃圾
三种基本思路
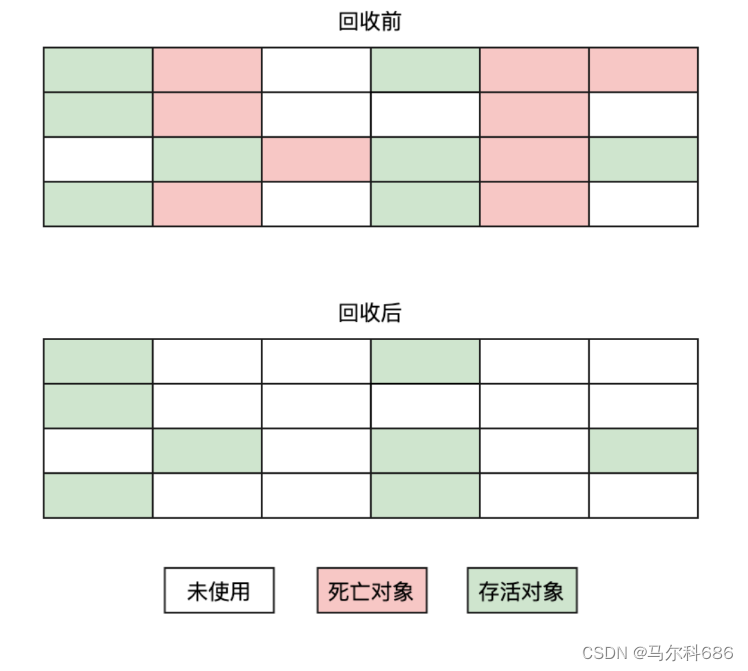
- 标记清除
把对应的对象,直接释放掉,就是标记清楚的方案,这个方案会产生很多的内存碎片,释放内存是为了让别的代码能够申请,申请内存,都是申请到“连续”的内存空间。
优点:实现简单。
缺点:产生不连续的内存碎片,如果程序需要分配一个连续内存的大对象时,就需要提前触发一次垃圾回收。
- 复制算法
通过复制的方式把有效的对象,归类到一起,再统一释放剩下的空间。
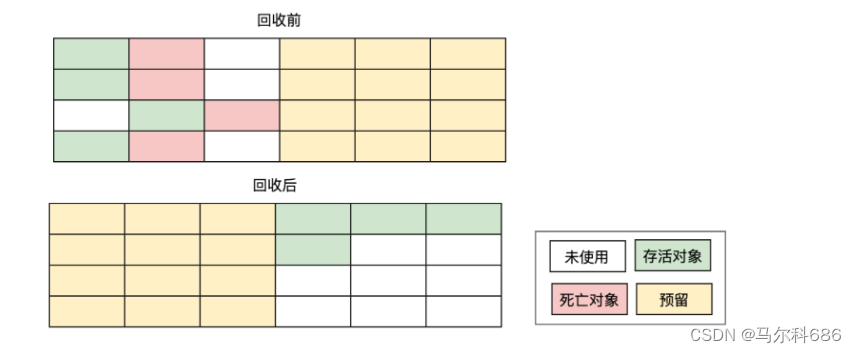
优点:执行效率高,没有内存碎片的问题。
缺点:空间利用率低,因为复制算法每次只能使用一半的内存。
- 标记整理
既能够解决内存碎片化的问题,又能够处理复制算法中利用率低的问题。
类似于顺序表删除元素的搬运操作。搬运的开销仍然很大。
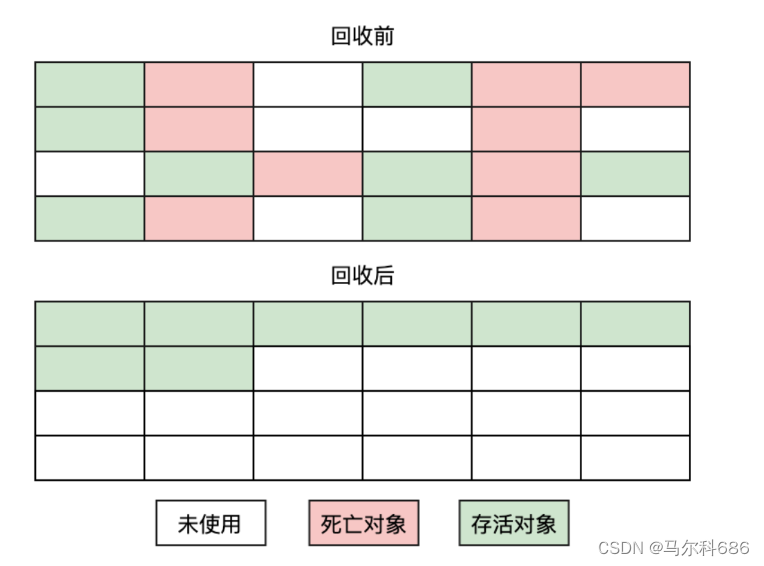
优点:解决了内存碎片问题,比复制算法空间利用率高。
缺点:因为有局部对象移动,所以效率不是很高。
实际上JVM采取的释放思路,是上述基础思路结结合体,让上述方案扬长避短。
分代回收:
