X-AnyLabeling标注工具的使用
前言
项目链接:https://github.com/CVHub520/X-AnyLabeling/tree/main
X-AnyLabeling 是一款全新的交互式自动标注工具,其基于 Labelme 和 Anylabeling 等诸多优秀的标注工具框架进行构建,在此基础上扩展并支持了许多丰富的模型和功能,并借助Segment Anything和 YOLO 系列等目前主流和经典的深度学习模型提供强大的 AI 能力支持。无须任何复杂配置,下载即用,大大降低用户使用成本,同时支持自定义模型和快捷键设置等,极大提升用户标注效率和使用体验!
X-AnyLabeling 具备以下优势:
- 支持中英文一键切换,随心所欲;
- 支持必要的快捷键操作,可自定义设置;
- 支持CPU和GPU一键推理,可按需选取;
- 提供详细的操作手册及交流社区,帮助用户快速解决问题;
- 支持Windows、Linux和MacOS等多个主流的操作系统,同时支持用户自编译;
- 提供多种标注样式,包括多边形、矩形、线段、点、圆形、文本等,以满足用户的多元化的需求.
- 支持多种导出格式,包括 YOLO-txt、COCO-json、VOC-xml 以及图片掩码等,只需一键运行,即可满足日常训练所需标签样式。
- 提供多种模型架构,包括但不仅限于YOLO系列、DETR系列和SAM系列等,可无缝衔接OpenMMLab、PaddlePaddle、timm等多个主流的深度学习框架,同时支持自定义模型导入。
- 支持多种任务模式,包括目标检测、语义分割、姿态估计、人脸关键点回归、文本检测、识别和KIE(关键信息提取)标注等。
此外,为了加速模型推理速度,提供了多个量化版本及LRU缓冲机制,极大提升用户体验。
AI标注功能:
第一: 目标检测 & 语义分割
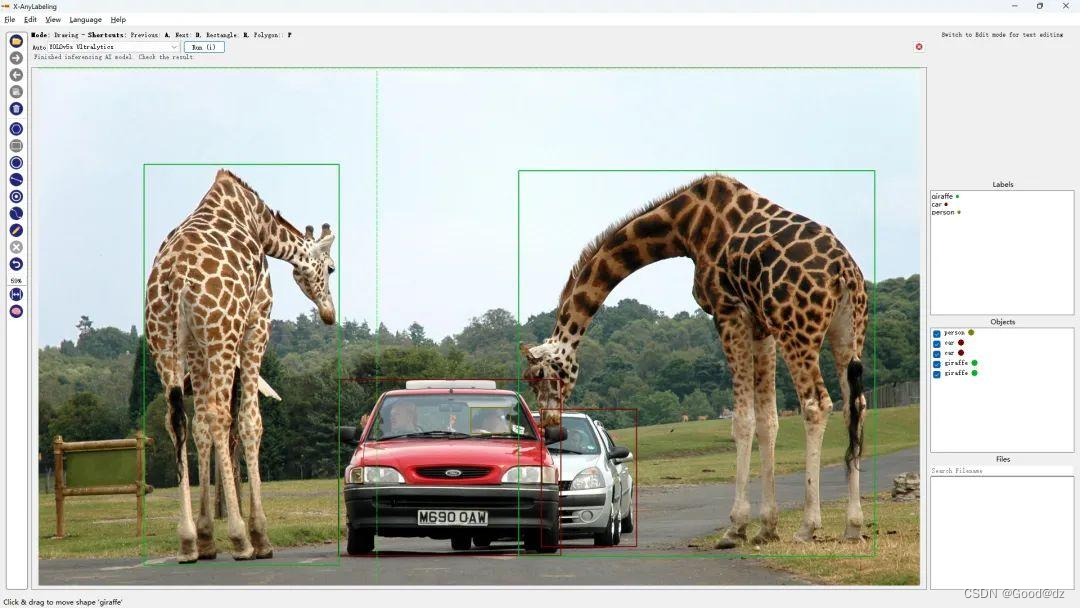 提供了多个yolo的模型
提供了多个yolo的模型
第二:细粒度检测分类
细粒度与粗粒度概念对比
- 粗粒度:类间appearance差异较大,如猫、鸟、鱼、飞机、汽车等
- 细粒度:类间差异较小,如不同品种的犬类之间,不同型号的飞机之间等
例如下面的例子使用YOLOv5s-ResNet50模型进行分类
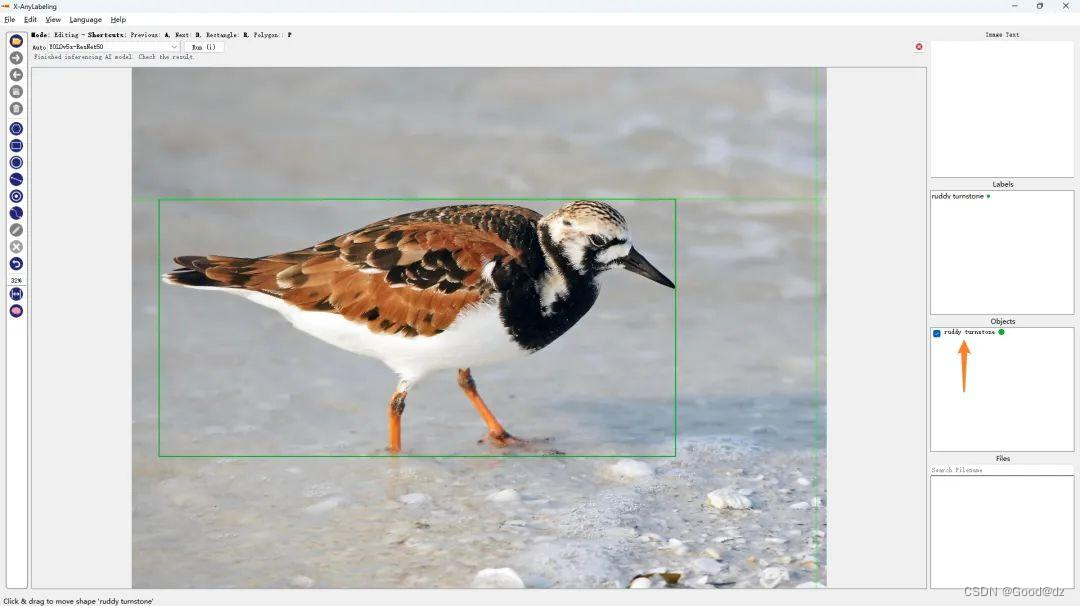
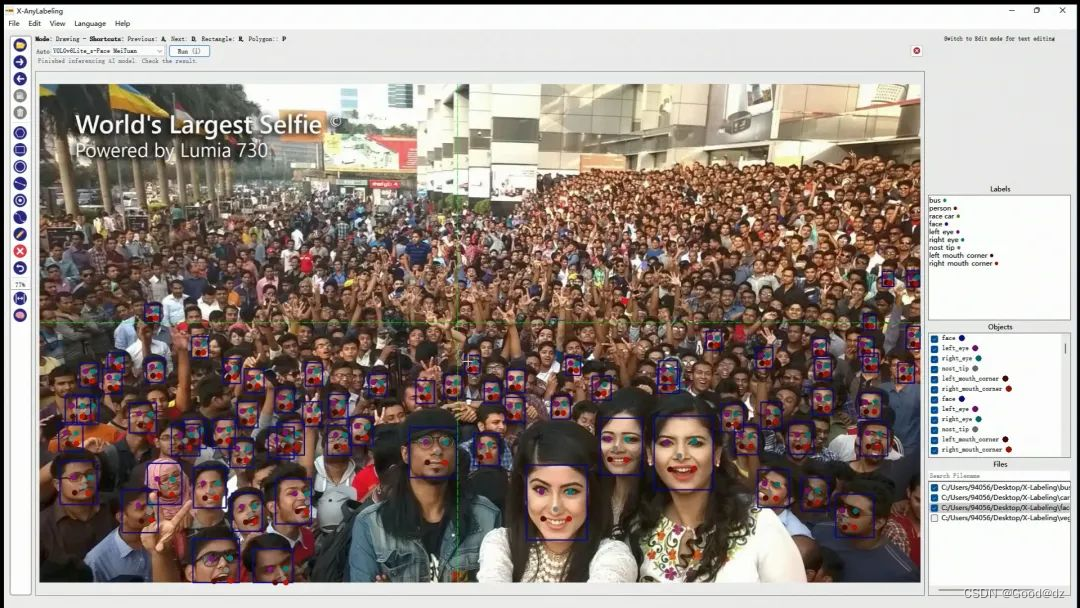
第三:人脸检测+关键点回归
例如下面的例子使用YOLOv6Lite-Face模型进行分类
第四:全身人体姿态估计
例如下面的例子使用YOLOX+DWPose模型进行分类
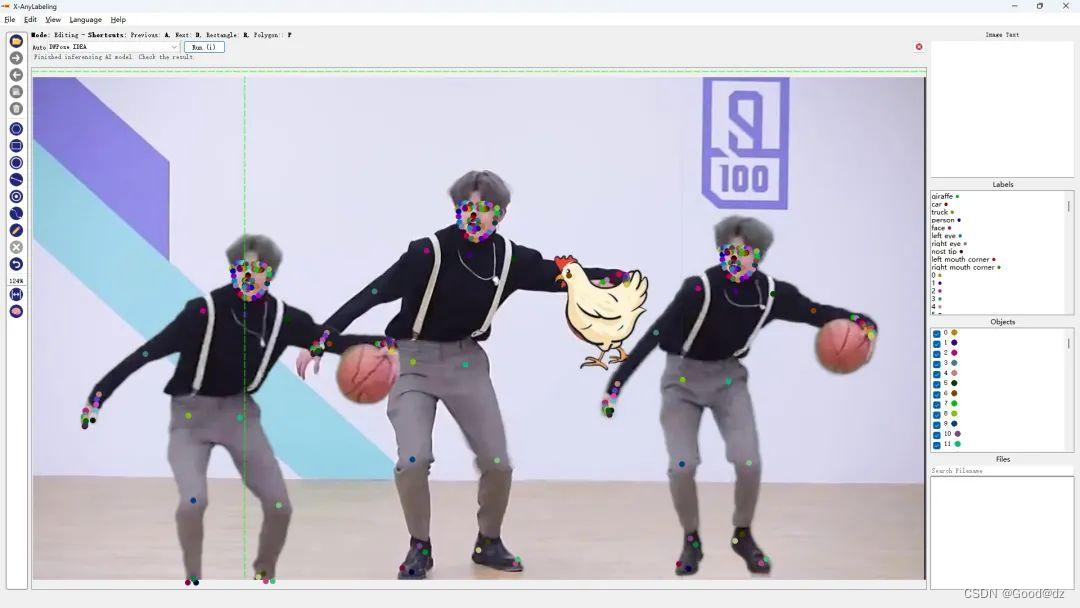
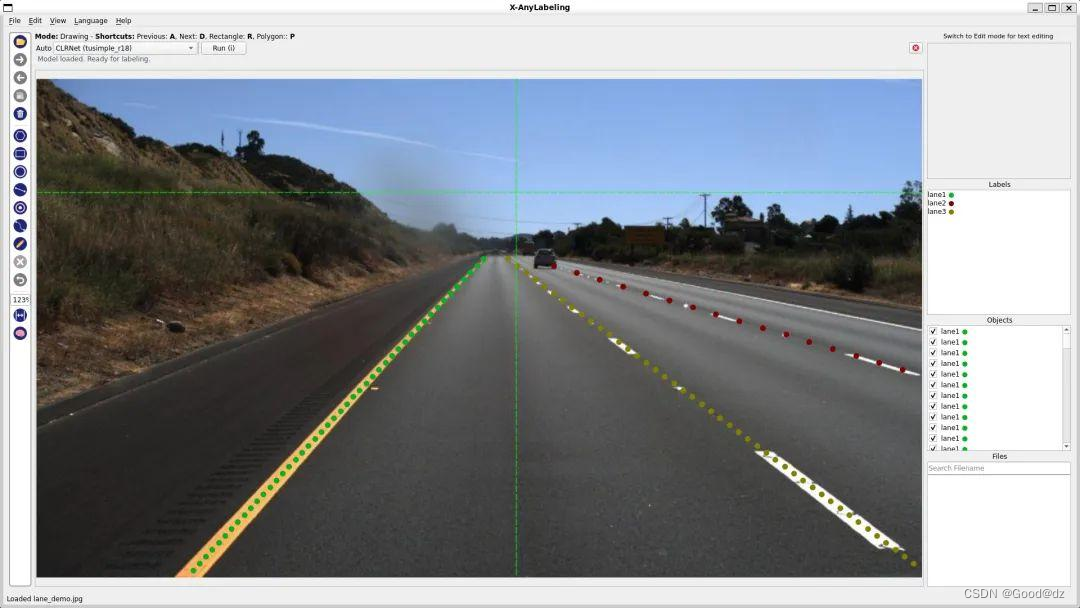
第五:车道线检测
例如下面的例子使用CLRNet-tusimple-r18模型进行分类
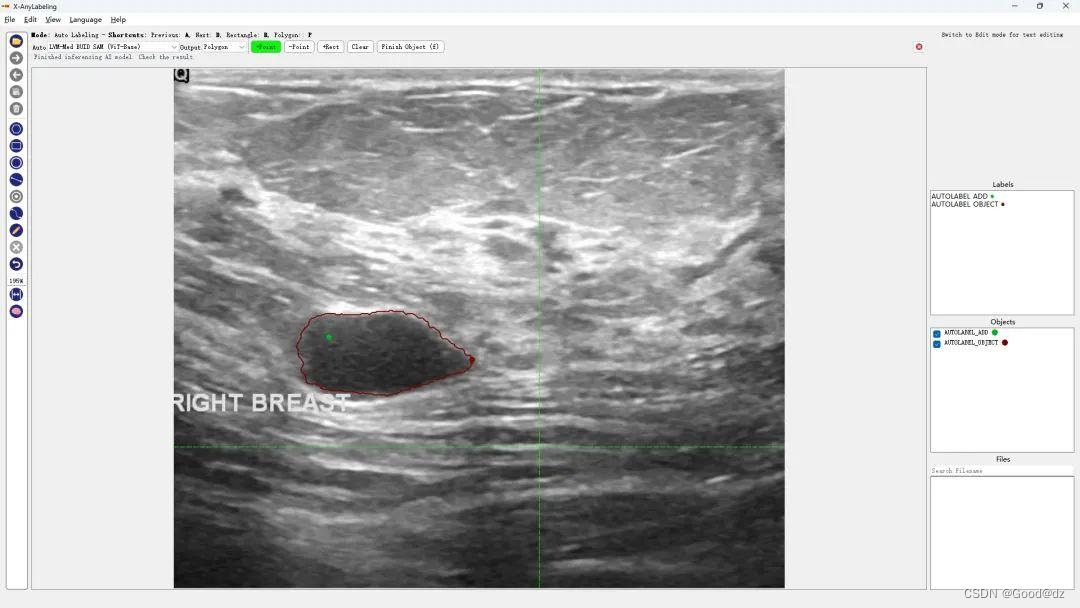
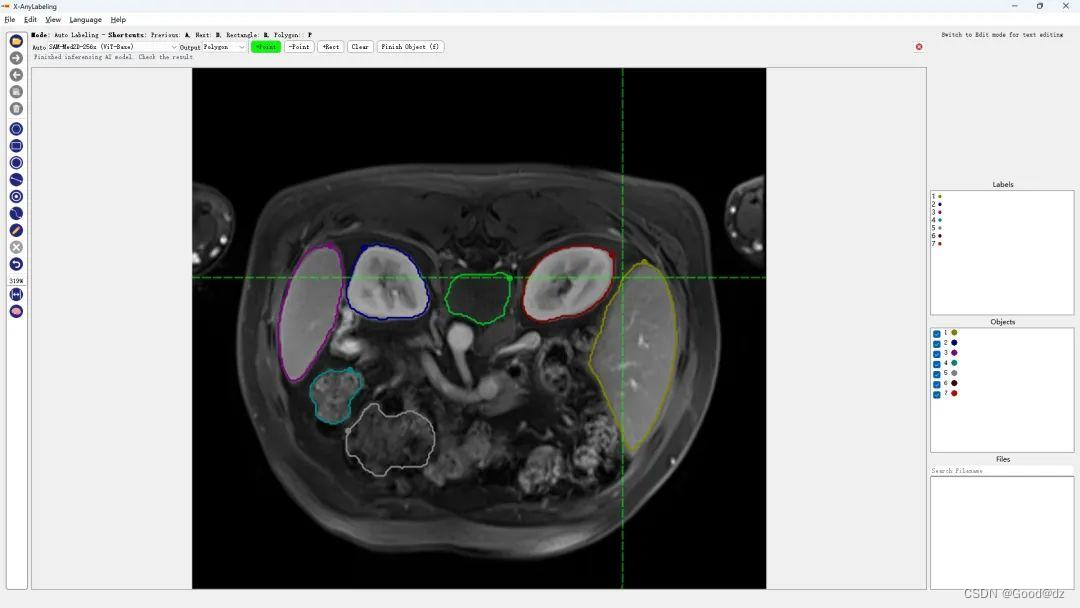
第六:医学图像分割
超声波乳腺癌分割 | 结直肠息肉分割 | 皮肤镜病变分割
第七:自然图像分割
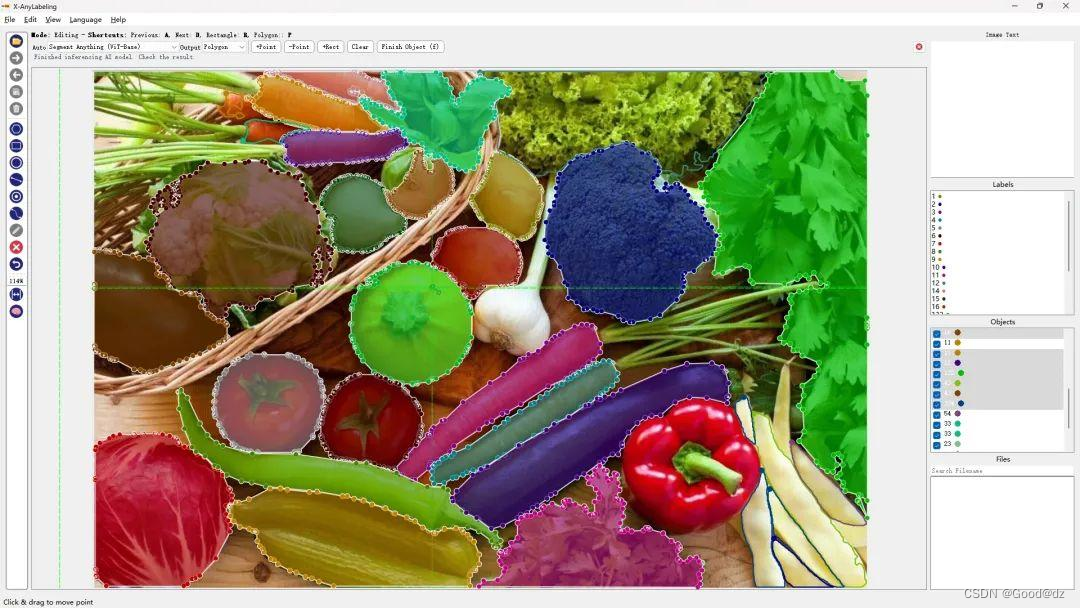 使用SAM-ViT-B、SAM-ViT-L、SAM-ViT-H或者Mobile-SAM模型进行分割。
使用SAM-ViT-B、SAM-ViT-L、SAM-ViT-H或者Mobile-SAM模型进行分割。
第八:OCR
文本标签是许多标注项目中的一项常见任务,但遗憾的是在 Labelme 和 LabelImg 中仍然没有得到很好的支持。X-AnyLabeling 中完美支持了这一项新功能。
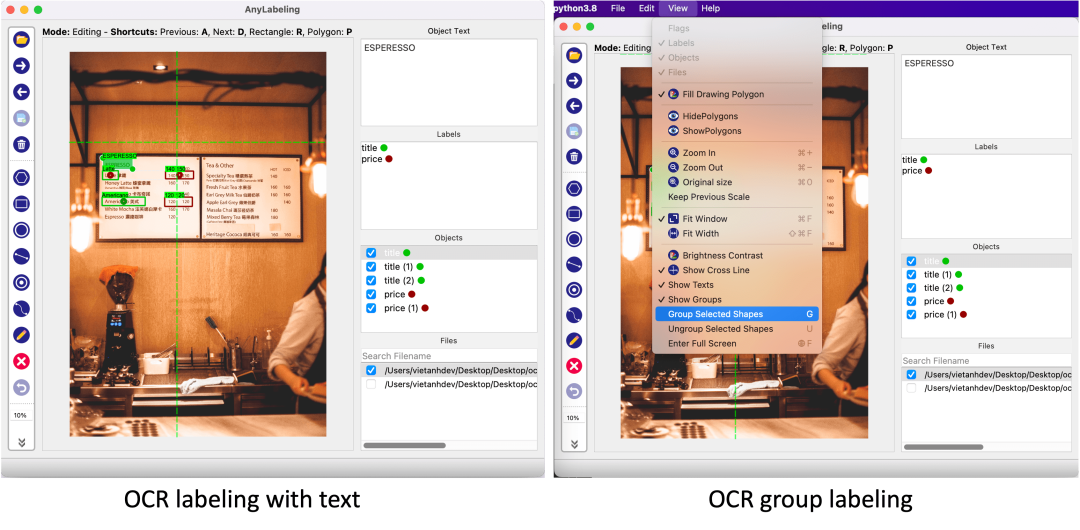 图像文本标签:用户可以切换到编辑模式并更新图像的文本——可以是图像名称或图像描述。
图像文本标签:用户可以切换到编辑模式并更新图像的文本——可以是图像名称或图像描述。
文本检测标签:当用户创建新对象并切换到编辑模式时,可以更新对象的文本。
文本分组:想象一下,当使用 KIE(键信息提取)时,需要将文本分组到不同的字段中,包含标题和值。在这种情况下,你可以使用文本分组功能。当创建一个新对象时,我们同样可以通过选择它们并按G将其与其他对象组合在一起。分组的对象将用相同的颜色标记。当然,也可以按快捷键U取消组合。
参考链接:https://zhuanlan.zhihu.com/p/656703406