这就是华为速度:2.69分钟完成BERT训练!新发CANN 5.0加持,还公开了背后技术
金磊 萧箫 发自 凹非寺
量子位 报道 | 公众号 QbitAI
快,着实有点快。
现在,经典模型BERT只需2.69分钟、ResNet只需16秒。
啪的一下,就能完成训练!
这是华为全联接2021上,针对异构计算架构CANN 5.0放出的最新性能“预热”:
4K老电影AI修复,原本需要几天时间,现在几小时就能完成;
针对不同模型进行智能优化,300+模型平均可获得30%性能收益;
支持超大参数模型、超大图片计算,几乎无需手动修改原代码……
不同于训练推理框架,异构计算架构在设计时,还需要兼顾硬件和软件的特点。
为的就是尽可能提升AI模型的计算效率,减少在训练和推理上占用的时间。
它的存在,能让开发者在使用AI模型时,最大程度地发挥硬件的性能。
异构计算架构究竟为什么重要,昇腾CANN 5.0又究竟有哪些特性和优势?
我们对华为昇腾计算业务副总裁金颖进行了采访,从CANN 5.0的功能解读中一探究竟。

为什么需要AI异构计算架构?
首先来看看,AI异构计算架构到底是什么。
通常做AI模型分两步,先选用一种框架来搭建AI模型,像常见的Caffe、Tensorflow、PyTorch、MindSpore等;再选用合适的硬件(CPU、GPU等)来训练AI模型。
BUT,在AI训练框架和硬件之间,其实还有一层不可或缺的“中间架构”,用来优化AI模型在处理器上的运行性能,这就是AI异构计算架构。
区别于同构计算(同类硬件分布式计算,像多核CPU),异构计算指将任务高效合理地分配给不同的硬件,例如GPU做浮点运算、NPU做神经网络运算、FPGA做定制化编程计算……

面对各种AI任务,AI异构计算架构会充当“引路员”,针对硬件特点进行分工,用“组合拳”加速训练/推理速度,最大限度地发挥异构计算的优势。
如果不重视它,各类硬件在处理AI任务时,就可能出现“长跑选手被迫举重”的情况,硬件算力和效率不仅达不到最优,甚至可能比只用CPU/GPU更慢。
目前已有越来越多的企业和机构,注意到异构计算架构的重要性,开始着手布局相关技术,不少也会开放给开发者使用。
但开发者在使用这些异构计算架构时,会逐渐发现一个问题:
不少AI异构计算架构,基本只针对一种或几种特定场景来设计,如安防、客服等AI应用较成熟的场景;针对其他场景设计的AI模型,异构计算架构的性能会有所下降。
就像安防公司会针对安防类AI模型进行优化一样,这类异构计算架构往往不具有平台通用性。
这使得开发者在训练不同的AI模型时,需要在搭载不同异构计算架构的各类处理器之间“反复横跳”,找到训练效率最高的方法。
期间不仅要学习各类算子库、张量编译器、调优引擎的特性,还只能选用特定的训练框架,非常复杂。
相比之下,华为从2018年AI战略制定之初,就选择了一条不同的路线。
华为昇腾计算业务副总裁金颖在采访中表示:
我们认为,AI模型会由单一的、场景化的模式,逐渐走向通用化,而昇腾系列,就是针对全场景设计的解决方案。
其中,昇腾CANN作为平台级的异构计算架构,已经经过了3年多的优化,迭代了4个大版本。
现在,最新“预热”的CANN 5.0版本,在各种不同场景的模型和任务上,都表现出了不错的效果。
昇腾CANN 5.0带来哪些新功能?
相比于昇腾CANN 3.0,“跨代”的5.0版本带来三大优势:
性能:AI模型训练/推理性能大幅提升,用时更短;
功能:推理引擎ATC Suite1.0首次发布,AI模型推理性能更高、功能更全面;
便捷性:代码开发和调试进一步简化,包括支持混合编程等,使用门槛更低。
在性能上,无论是训练规模大小、场景类型,还是推理效率,均有较大提升。
其中,在MLPerf提供的大规模集群训练场景中测试,结果如下:
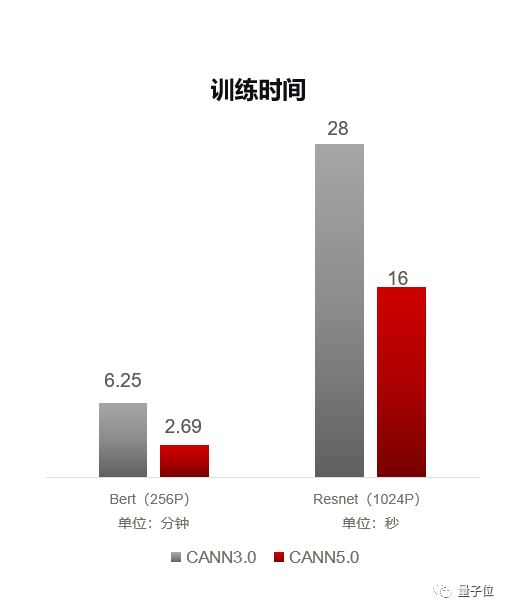
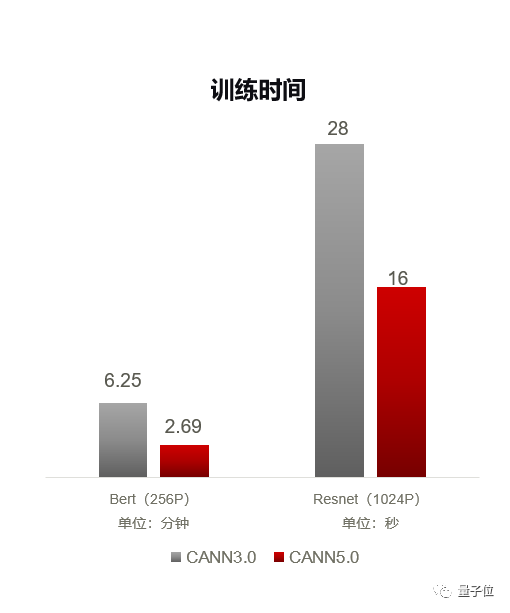
△数据来源:昇腾
从上图可见,原本需要6.25分钟训练的BERT模型,在CANN 5.0的加持下缩短了一倍多,只需2.69分钟就能完成训练;至于在3.0版本上需要28秒训练的ResNet,5.0版本则是“再进化”到了16秒。
至于常用的一些小模型训练场景(分类、检测、语义分割、NLP等),5.0版本的性能提升同样明显:
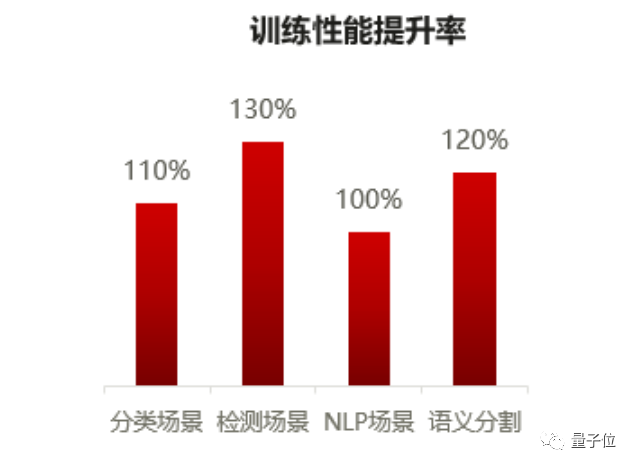
△数据来源:昇腾
训练以外,5.0版本的推理性能,在不同场景(分类、翻译、检测)下提升效果也非常不错:
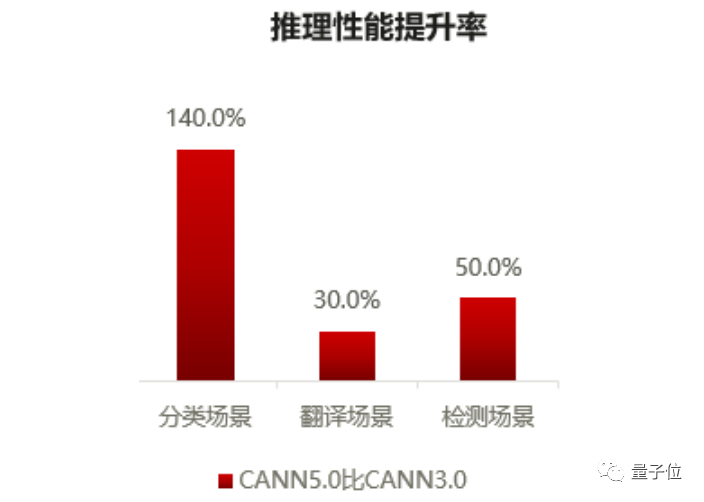
△数据来源:昇腾
显然,无论是训练还是推理,CANN 5.0都实现了更高效的任务调度和更好的性能提升。
在功能上,CANN 5.0首次发布了昇腾推理引擎软件包ATC Suite1.0(ATC,Ascend Tensor Compiler,昇腾张量编译器),包括模型压缩、张量编译、智能优化和媒体预处理硬加速等能力。
模型压缩,包括量化、稀疏、张量分解等工具。像其中的AMCT模型压缩工具,就能对浮点数据进行压缩处理,来降低模型大小,加速推理速度;
智能优化,能为用户提供在线调优能力,包括图解析、子图/算子自动调优、模型编译优化等功能,进一步加速ATC的计算速度。
此外,推理引擎还包括Ascend CL(Ascend Computing Language,昇腾统一编程接口)全栈能力调用,即使是多路复杂的音视频处理等特殊场景也能轻松应对,以及ACE(Ascend Computing Execution,昇腾计算执行引擎)运行管理等功能;至于在线/离线切换的推理模式,也让部署场景更加灵活。
在便捷性上,5.0版本又进一步降低了开发者的使用门槛。
例如,无需开发者手工修改代码,5.0版本支持模型自动迁移。
又例如,进一步支持混合编程。相比于3.0的手动加载模型,5.0版本在APP中可以直接调用算子函数,自动完成编译加载并执行:

△3.0版本

△5.0版本
再例如,相比3.0,5.0版本现在还能自动生成算子测试代码,省去不少步骤:
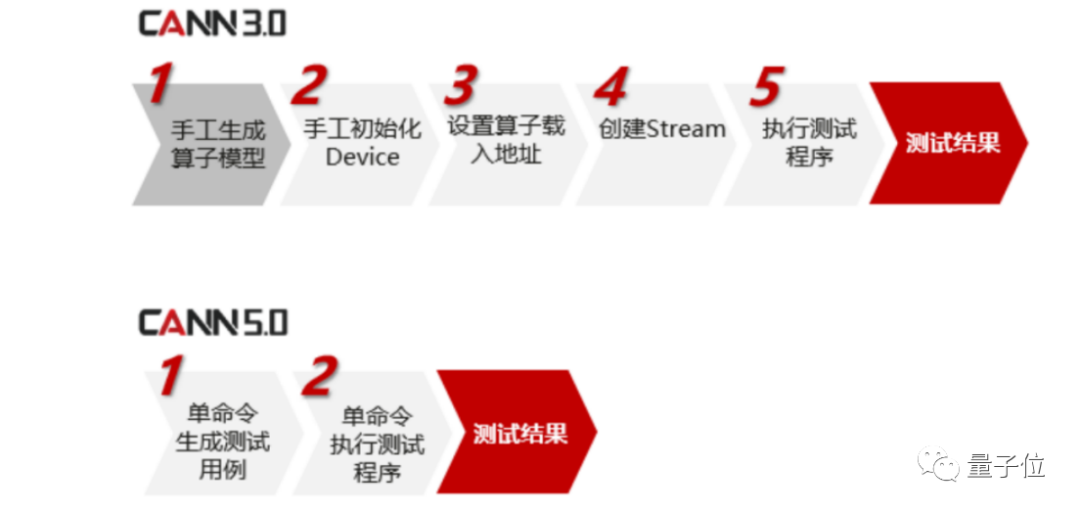
可以说是对开发者新人也很友好了。
然而,相比于表面带来的更高性能、更全面的功能应用,异构计算架构的性能优化,并不如想象中“随便调调参”一般简单,而是需要大量的技术支撑。
性能优化有多难?
将原本需要跑上几天的模型训练时间,缩减到几小时甚至几秒,背后绝不仅仅靠的是硬件的堆叠。
其中CANN 5.0的一个关键技术,就是集群训练(采用大量机器共同训练模型,以加速训练时间)。
据金颖介绍,相对于单机训练,增加训练模型的机器数量,往往并不一定能收获线性的效率提升。
在训练过程中,多台机器虽然整体上拥有更多算力,但这些算力是分散的,彼此在进行数据交互的过程中,实际上又降低了训练效率,这也一直是集群训练的一个瓶颈。

△图源:图虫
昇腾选择用图计算的原理,来分析集群训练的流水线分布、内存分配,针对不同机器的特点进行了架构上的设计,合理分配各个节点中的内存和通讯时间,来提高机器整体的计算效率。
具体来说,CANN 5.0版本在性能优化上,主要自研了4点技术:
其一,任务自动流水。
我们都在打游戏的时候感受过数据加载的痛苦,这是因为硬件需要一定的时间来“反应”,包括加载计算指令等,但在数据量大的情况下,这显然会极大地延缓整体计算时间。
5.0实现了计算指令和数据载入的多流水并行,载入数据满足分段数据量时,不仅启动后续计算逻辑、还保持数据继续载入,进一步“压榨”硬件处理器的并行计算能力,实现任务衔接。
其二,算子深度融合。
算子是支持AI模型训练与推理的基本运算单元及组合,异构计算架构基本都要有自己的算子库。5.0版本重新定制了更灵活的算子融合规则,通过多个算子自动融合提升模型训练效率。
其三,自适应梯度切分。
这项技术,是华为针对集群训练提出的智能梯度切分算法,具体针对模型训练中的迭代计算进行了优化。
CANN 5.0能通过智能梯度切分算法,自动搜索出最优梯度参数切分方式,让计算和通信进一步并行执行,使得通信拖尾时间降至最低、梯度调优时间降低90%。
其四,AutoTune智能计算调优。
不同的AI模型,如果架构只用一种方式进行计算分配的话,势必会造成不适配的情况。
因此,CANN 5.0研究出了智能数据切分技术,提出最优切分策略,确保每个计算单元被充分利用,平均性能提升30%以上。
5.0版本也预置了海量模型优化,能极大地缩短开发者的调优时间。
正是这些技术优势,让华为在AI性能提升上,拥有了更多的底气。
如何评价昇腾CANN 5.0?
一方面,无论是AI模型、还是硬件层面的架构优化,都是AI技术走向更复杂的“通用化”的一个体现。
对于AI模型来说,更加通用的模型,并非仅仅是“参数越堆越多”的结果。
目前的通用AI模型,无论从训练数据、还是架构设计本身来看,技术上都还有许多亟待完善的地方:由数据带来的模型偏见、架构设计的冗余和不可解释性……
显然,AI模型面临的这些问题,不可能单纯通过“模型变大”来彻底得到解决。
对于硬件也是如此,当下AI行业对于算力需求的扩大,同样不可能只通过硬件的堆砌来填补空缺。
如何在单个硬件算力受限的情况下,充分利用每个硬件的性能,达到算力1+1=2甚至是>2的效果,是AI行业的每个参与者都必须思考的问题。
异构计算架构,是高效利用不同硬件算力的解决方案之一,对于它来说,通用化也是同样复杂的一个问题。
相比于单纯为某一场景、或某一功能而设计的专用异构计算架构,适用于全平台、全场景的“通用型”异构计算架构,从实现到优化上都要复杂得多。
这里的难度,不仅仅在于实现功能上的通用性,而是在同样场景下,将对AI模型的性能优化做得和专用架构一样好。
从这个角度来看,不可能存在一个“一劳永逸”的技术解决方案。
无论是AI模型还是异构计算架构,都必须不断推陈出新、打破自己和行业的固有认知,与时俱进,才可能在变幻莫测的时代浪潮中保持身位。

△图源:图虫
另一方面,回过头看历史潮流,仅凭创新,也不足以让技术实现“可持续发展”,究其根本,还是要回归现实、解决实际应用问题。
例如,昇腾CANN 5.0联手武汉大学,解决了遥感领域的超大图片计算瓶颈;同时,也在电影行业中,帮助修复了如《红楼梦》、《开国大典》等高清4K影片。
要守住过去继承下来的技术地位,又要迎头直面实实在在的新问题,对华为已是竞争中的必修课。
正如华为轮值董事长徐直军在全联接大会2021上所言:
数字化将注定是一个长期的过程,不可能一蹴而就。
我们所从事的这些技术领域,有幸处在变化最活跃的环节。