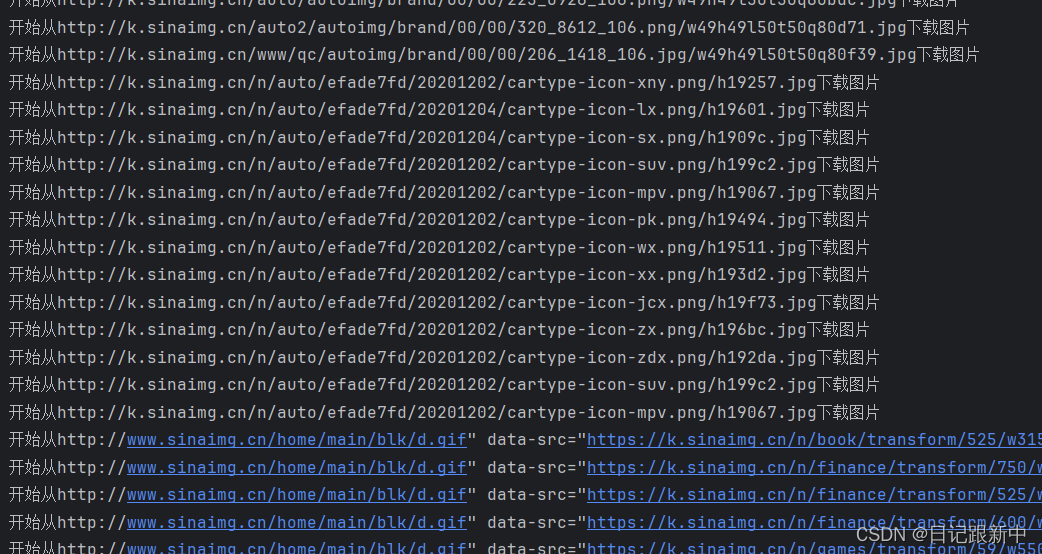
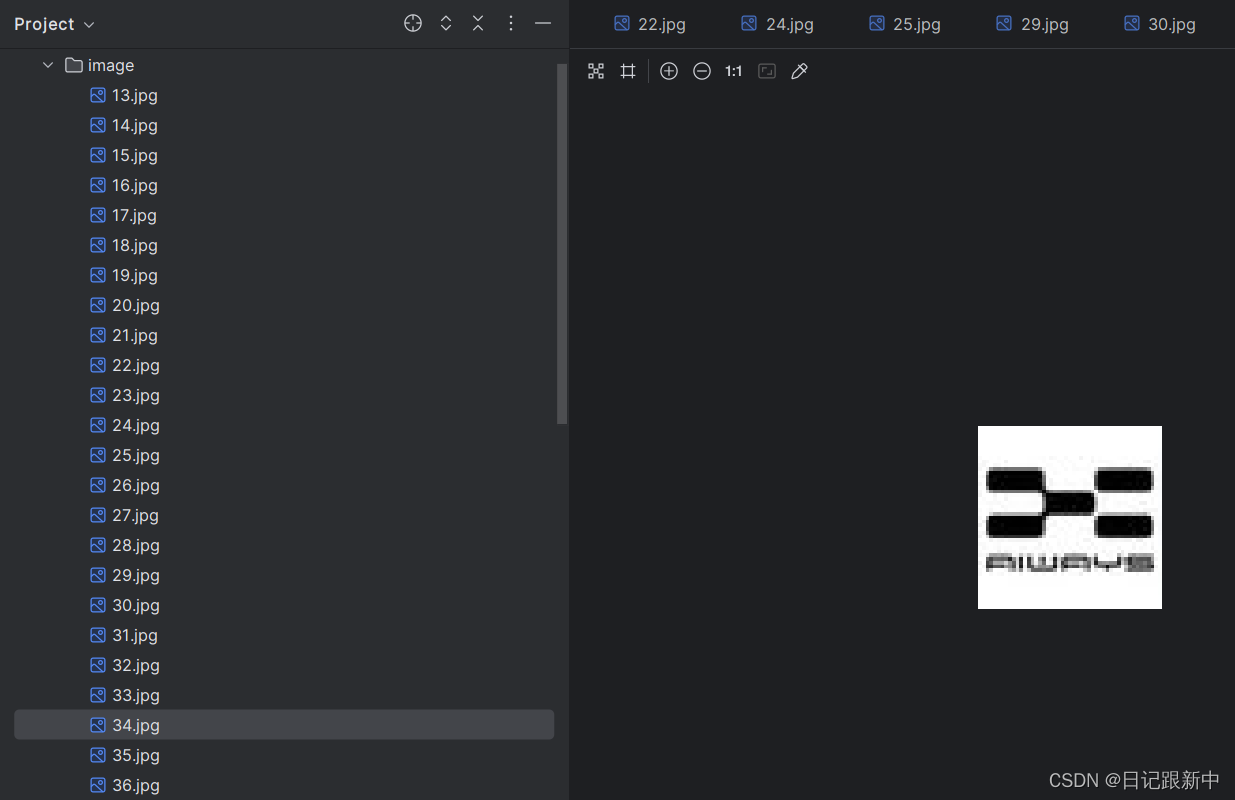
python实现简单的爬取网页图片
先创建一个image文件
代码如下;举例:爬取sina网址的图片
import re
import chardet
import requests
import chardet
url = "https://www.sina.com.cn"
response = requests.get(url=url)
charset = chardet.detect(response.content).get('encoding')
response.encoding = charset
html = response.text
images = re.findall(r"src=\"(.*?jpg|png|jepg)\"", html)
for index,item, in enumerate(images):
if not item.startswith("http"):
real_url = "http:"+item
print("开始从{}下载图片".format(real_url))
resp = requests.get(real_url)
with open("image/"+str(index)+".jpg","wb") as f:
f.write(resp.content)结果如下: