TensorFlow入门讲解
TensorFlow 是由 Google Brain 团队为深度神经网络(DNN)开发的功能强大的开源软件库,其允许将深度神经网络的计算部署到任意数量的 CPU 或 GPU 的服务器、PC 或移动设备上,且只利用一个 TensorFlow API。包括 TensorFlow 在内的大多数深度学习库能够自动求导、开源、支持多种 CPU/GPU、拥有预训练模型,并支持常用的NN架构,如递归神经网络(RNN)、卷积神经网络(CNN)和深度置信网络(DBN)。TensorFlow 则还有更多的特点,如下:
- 支持所有流行语言,如 Python、C++、Java、R和Go。
- 可以在多种平台上工作,甚至是移动平台和分布式平台。
- 它受到所有云服务(AWS、Google和Azure)的支持。
- Keras——高级神经网络 API,已经与 TensorFlow 整合。
- 与 Torch/Theano 比较,TensorFlow 拥有更好的计算图表可视化。
- 允许模型部署到工业生产中,并且容易使用。
- 有非常好的社区支持。
- TensorFlow 在后端使用 C/C++,这使得计算速度更快
- TensorFlow 不仅仅是一个软件库,它是一套包括 TensorFlow,TensorBoard 和 TensorServing 的软件。
GPU 和 TensorFlow 等工具,可以通过几行代码轻松访问 GPU 并构建复杂的神经网络,而不需要深入复杂的数学细节,大数据集的可用性为 DNN 提供了必要的数据来源。
一.TensorFlow程序结构
通过将程序分为两个独立的部分,构建任何拟创建神经网络的蓝图,包括计算图的定义及其执行。图定义和执行的分开设计让 TensorFlow 能够多平台工作以及并行执行,TensorFlow 也因此更加强大。
计算图:是包含节点和边的网络。本节定义所有要使用的数据,也就是张量(tensor)对象(常量、变量和占位符),同时定义要执行的所有计算,即运算操作对象(Operation Object,简称 OP)
计算图的执行:使用会话对象来实现计算图的执行。会话对象封装了评估张量和操作对象的环境。这里真正实现了运算操作并将信息从网络的一层传递到另外一层。不同张量对象的值仅在会话对象中被初始化、访问和保存。在此之前张量对象只被抽象定义,在会话中才被赋予实际的意义。请记住,每个会话都需要使用 close() 来明确关闭,而 with 格式可以在运行结束时隐式关闭会话。
举例:需要使用 tf.Session() 定义一个会话对象 sess。然后使用 Session 类中定义的 run 方法运行它run(fetches,feed_dict=None,options=None,run_metadata)运算结果的值在 fetches 中提取
养成显式定义所有张量和操作对象的习惯,不仅可使代码更具可读性,还可以帮助你以更清晰的方式可视化计算图
v_1=tf.constant([1,2,3,4])
v_2=tf.constant([2,1,5,3])
v_add=tf.add(v_1,v_2)
//Session提供了Operation执行和Tensor求值的环境:
with tf.Session() as sess:
print(sess.run(v_add))1.构建图:
添加变量和操作,并按照逐层建立神经网络的顺序传递它们(让张量流动)。TensorFlow 还允许使用 with tf.device() 命令来使用具有不同计算图形对象的特定设备(CPU/GPU)
(1).常量、变量和占位符
最基本的 TensorFlow 提供了一个库来定义和执行对张量的各种数学运算。张量,可理解为一个 n 维矩阵
TensorFlow 支持以下三种类型的张量:
- 常量:常量是其值不能改变的张量。
t_2 = tf.constant([4,3,2])
//要创建一个所有元素为零的张量,可以使用 tf.zeros() 函数
tf.zeros([2,3],tf.int32)
//创建与现有 Numpy 数组或张量常量具有相同形状的张量常量
tf.zeros_like(t_2)
tf.ones_like(t_2)
//在一定范围内生成一个从初值到终值等差排布的序列:
tf.linspace(start,stop,num)TensorFlow 允许创建具有不同分布的随机张量:
//正态分布
t_random=tf.random_normal([2,3],mean=2.0,stddev=4,seed=12)
//伽马分布
t_random=tf.random_uniform([2,3],maxval=4,seed=12)
//将给定的张量随机裁剪为指定的大小
tf.random_crop(t_random,[2,5],seed=12)很多时候需要以随机的顺序来呈现训练样本,可以使用 tf.random_shuffle() 来沿着它的第一维随机排列张量:
tf.random_shuffle(t_random)
2.变量:当一个量在会话中的值需要更新时,使用变量来表示。例如,在神经网络中,权重需要在训练期间更新,可以通过将权重和偏置声明为变量来实现。变量在使用前需要被显示初始化。另外需要注意的是,常量存储在计算图的定义中,每次加载图时都会加载相关变量。换句话说,它们是占用内存的。另一方面,变量又是分开存储的。它们可以存储在参数服务器上。
rand_t=tf.random_uniform([50,50],0,10,seed=0)
t_a=tf.Variable(rand_t)
t_b=tf.Variable(rand_t)weights=tf.Variable(tf.random_normal([100,100],stddev=2))
bias=tf.Variable(tf.zeros[100],name='biases')
//利用前面定义的权重来初始化 weight2:
weight2=tf.Variable(weights.initialized_value(),name='w2')
//声明初始化操作对象:
initial_op=tf.global_variables_initializer()每个变量也可以在运行图中单独使用 tf.Variable.initializer 来初始化:
bias=tf.Variable(tf.zeros([100,100]))
with tf.Session() as sess:
sess.run(bias.initializer)保存变量:使用 Saver 类来保存变量,定义一个 Saver 操作对象:
saver = tf.train.Saver()3.占位符:用于将值输入 TensorFlow 图中。它们可以和 feed_dict 一起使用来输入数据。在训练神经网络时,它们通常用于提供新的训练样本。在会话中运行计算图时,可以为占位符赋值。这样在构建一个计算图时不需要真正地输入数据。需要注意的是,占位符不包含任何数据,因此不需要初始化它们。
可以使用以下方法定义一个占位符:
tf.placeholder(dtype,shape=None,name=None)dtype 定占位符的数据类型,并且必须在声明占位符时指定。在这里,为 x 定义一个占位符并计算 y=2*x,使用 feed_dict 输入一个随机的 4×5 矩阵:
x=tf.placeholder("float")
y=2*x
data=tf.random_uniform([4,5],10)
with tf.Session() as sess:
x_data=sess.run(data)
print(sess.run(y,fedd_dict={x:x_data}))(2).数学运算操作
矩阵运算,例如执行乘法、加法和减法,是任何神经网络中信号传播的重要操作。通常在计算中需要随机矩阵、零矩阵、一矩阵或者单位矩阵。
import tensorflow as tf
#start an interactive session
sess=tf.InteractiveSession()
I_matrix=tf.eye(5)
X=tf.Variable(tf.eye(10))
X.initializer.run()
A=tf.Variable(tf.random_normal([5,10]))
A.initializer.run()
//multiply two matrix
product=tf.matmul(A,X)
b=tf.Variable(tf.random_uniform([5,10],0,2,dtype=tf.int32))
b.initilizer.run()
b_new=tf.cast(b,dtype=tf.float32) #cast to float32 data type
t_sum=tf.add(product,b_new)
t_sub=product-b_new
2.TensorBoard可视化数据流图
使用 TensorBoard 来提供计算图形的图形图像。这使得理解、调试和优化复杂的神经网络程序变得很方便。TensorBoard 也可以提供有关网络执行的量化指标。它读取 TensorFlow 事件文件,其中包含运行 TensorFlow 会话期间生成的摘要数据。
使用 TensorBoard 的第一步是确定想要的 OP 摘要。以 DNN 为例,通常需要知道损失项(目标函数)如何随时间变化。在自适应学习率的优化中,学习率本身会随时间变化。可以在 tf.summary.scalar OP 的帮助下得到需要的术语摘要。假设损失变量定义了误差项,我们想知道它是如何随时间变化的
loss=tf.summary.scalar('loss',loss)还可以使用 tf.summary.histogram 可视化梯度、权重或特定层的输出分布:
output_tensor=tf.matmul(input_tensor,weights)+biases
tf.summary.histogram('output',output_tensor)摘要将在会话操作中生成。可以在计算图中定义 tf.merge_all_summaries OP 来通过一步操作得到摘要,而不需要单独执行每个摘要操作,生成的摘要需要用事件文件写入:
tf.summary,Filewriter:
writer=tf.sammary.Filewriter('summary_dir',sess.graph)这会将所有摘要和图形写入 summary_dir 目录中。现在,为了可视化摘要,需要从命令行中调用 TensorBoard:
tensorboard --logdir=summary_dir
接下来,打开浏览器并输入地址 http://localhost:6006/(或运行 TensorBoard 命令后收到的链接)
二.tensorflow与深度学习
任何深度学习网络都由四个重要部分组成:数据集、定义模型(网络结构)、训练/学习和预测/评估。可以在 TensorFlow 中实现所有这些。
1.数据集
DNN 依赖于大量的数据。可以收集或生成数据,也可以使用可用的标准数据集。TensorFlow 支持三种主要的读取数据的方法,可以在不同的数据集中使用,三种方式分别为:
通过feed_dict传递数据
在这种情况下,运行每个步骤时都会使用 run() 或 eval() 函数调用中的 feed_dict 参数来提供数据。这是在占位符的帮助下完成的,这个方法允许传递 Numpy 数组数据。
y=tf.placeholder(tf.float32)
x=tf.placeholder(tf.float32)
with tf.Session as sess:
X_Array=some Numpy Array
Y_Array=other Numpy Arrray
loss=...
sess.run(loss,feed_dict={x:X_Array,y:Y_Array})
从文件中读取
当数据集非常大时,使用此方法可以确保不是所有数据都立即占用内存,从文件读取的过程可以通过以下步骤完成:
- 使用字符串张量 ["file0","file1"] 或者 [("file%d"i)for i in range(2)] 的方式创建文件命名列表,或者使用
files=tf.train.match_filenames_once('*.JPG')函数创建。 - 文件名队列:创建一个队列来保存文件名,此时需要使用 tf.train.string_input_producer 函数这个函数还提供了一个选项来排列和设置批次的最大数量。整个文件名列表被添加到每个批次的队列中。如果选择了 shuffle=True,则在每个批次中都要重新排列文件名。
- Reader用于从文件名队列中读取文件。根据输入文件格式选择相应的阅读器。read方法是标识文件和记录(调试时有用)以及标量字符串值的关键字。例如,文件格式为.csv 时:
reader=tf.TextLineReader()
key,value=reder.read(filename_queue)- Decoder:使用一个或多个解码器和转换操作来将值字符串解码为构成训练样本的张量:
record_defaults=[[1],[1],[1]]
col1,col2,col3=tf.decode_csv(value,record_defaults=record_defaults)预加载的数据
当数据集很小时可以使用,可以在内存中完全加载。因此,可以将数据存储在常量或变量中。在使用变量时,需要将可训练标志设置为 False,以便训练时数据不会改变。
//preloaded data as constant
training_data=...
traning_labels=...
with tf.Session as sess:
x_data=tf.Constant(training_data)
y_data=tf.Constant(training_labels)
//preloaded data as Variables
training_data=...
traning_labels=...
with tf.Session as sess:
data_x=tf.placeholder(dtype=training_data.dtype,shape=traning_data.shape)
data_y=tf.placeholder(dtype=training_data.dtype,shape=traning_data.shape)
x_data=tf.Variable(data_x,trainable=False,collections[])
y_data=tf.Variable(data_y,trainable=False,collections[])一般来说,数据被分为三部分:训练数据、验证数据和测试数据。
2.定义模型
建立描述网络结构的计算图。它涉及指定信息从一组神经元到另一组神经元的超参数、变量和占位符序列以及损失/错误函数
3.训练/学习
4.评估模型
一旦网络被训练,通过 predict() 函数使用验证数据和测试数据来评估网络。这可以评价模型是否适合相应数据集,可以避免过拟合或欠拟合的问题。一旦模型取得让人满意的精度,就可以部署在生产环境中了。
三.TensorFlow常用激活函数
每个神经元都必须有激活函数。它们为神经元提供了模拟复杂非线性数据集所必需的非线性特性。该函数取所有输入的加权和,进而生成一个输出信号。你可以把它看作输入和输出之间的转换。使用适当的激活函数,可以将输出值限定在一个定义的范围内。
1.阈值激活函数:这是最简单的激活函数。在这里,如果神经元的激活值大于零,那么神经元就会被激活;否则,它还是处于抑制状态。下面绘制阈值激活函数的图,随着神经元的激活值的改变在 TensorFlow 中实现阈值激活函数:
def threshold(x):
cond=tf.less(x,tf.zeros(tf.shape(x),dtype=x.dtype))
out=tf.where(cond,tf.zeros(tf.shape(x)),tf.ones(tf.shape(x)))
return out
h=np.linspace(-1,1,50)
out=threshold(h)
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
y=sess.run(out)
plt.xlabel('Activity of Neyron')
plt.ylabel('Output of Neuron')
plt.title('Threshole Activation Function')
plt.plot(h,y)
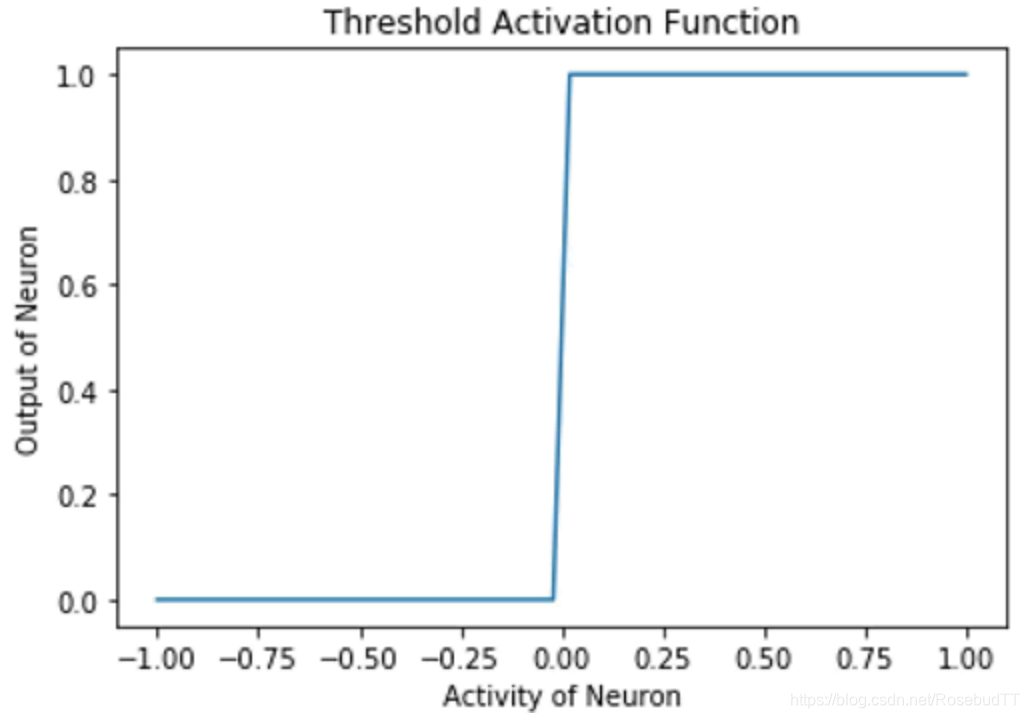
阈值激活函数用于 McCulloch Pitts 神经元和原始的感知机。这是不可微的,在 x=0 时是不连续的。因此,使用这个激活函数来进行基于梯度下降或其变体的训练是不可能的
(2)Sigmoid 激活函数:在这种情况下,神经元的输出由函数 g(x)=1/(1+exp(-x)) 确定。在 TensorFlow 中,方法是 tf.sigmoid,它提供了 Sigmoid 激活函数。这个函数的范围在 0 到 1 之间:
h=np.linspace(-10,10,50)
out=tf.sigmoid(h)
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
y=sess.run(out)
plt.xlabel('Activity of Neyron')
plt.ylabel('Output of Neuron')
plt.title('Sigmiod Activation Function')
plt.plot(h,y)
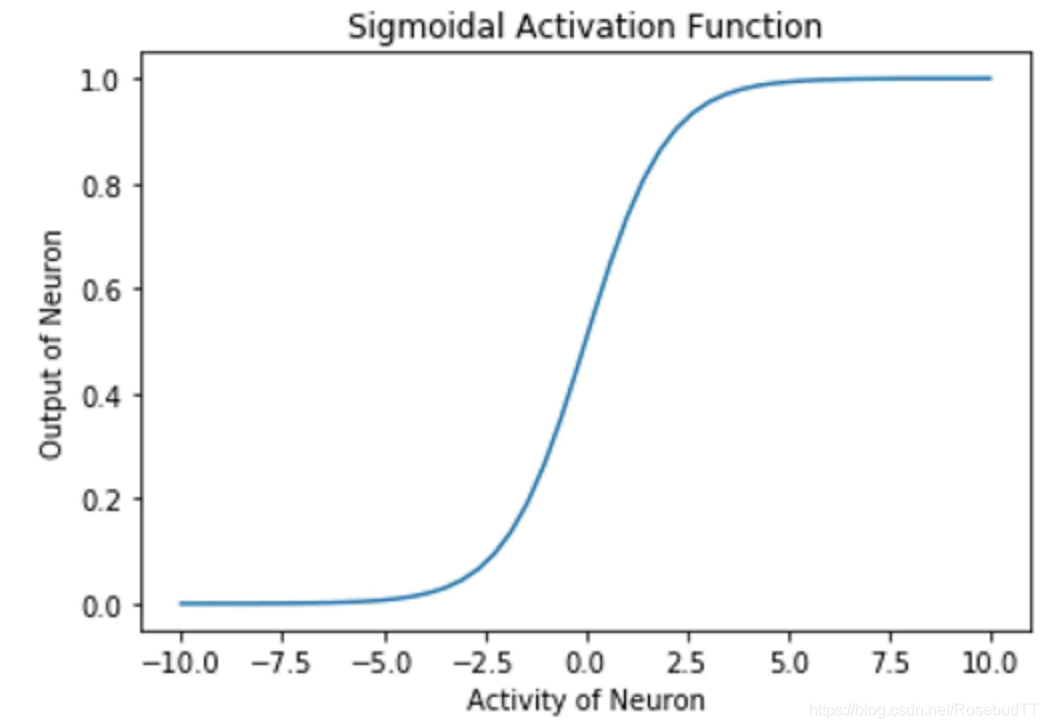
函数的梯度在两个边缘附近变为零,受到梯度消失问题的影响。
(3)双曲正切激活函数:在数学上,它表示为 (1-exp(-2x)/(1+exp(-2x)))。在形状上,它类似于 Sigmoid 函数,但是它的中心位置是 0,其范围是从 -1 到 1。TensorFlow 有一个内置函数 tf.tanh,用来实现双曲正切激活函数
h=np.linspace(-10,10,50)
out=tf.tanh(h)
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
y=sess.run(out)
plt.xlabel('Activity of Neyron')
plt.ylabel('Output of Neuron')
plt.title('Hyperbolic Activation Function')
plt.plot(h,y)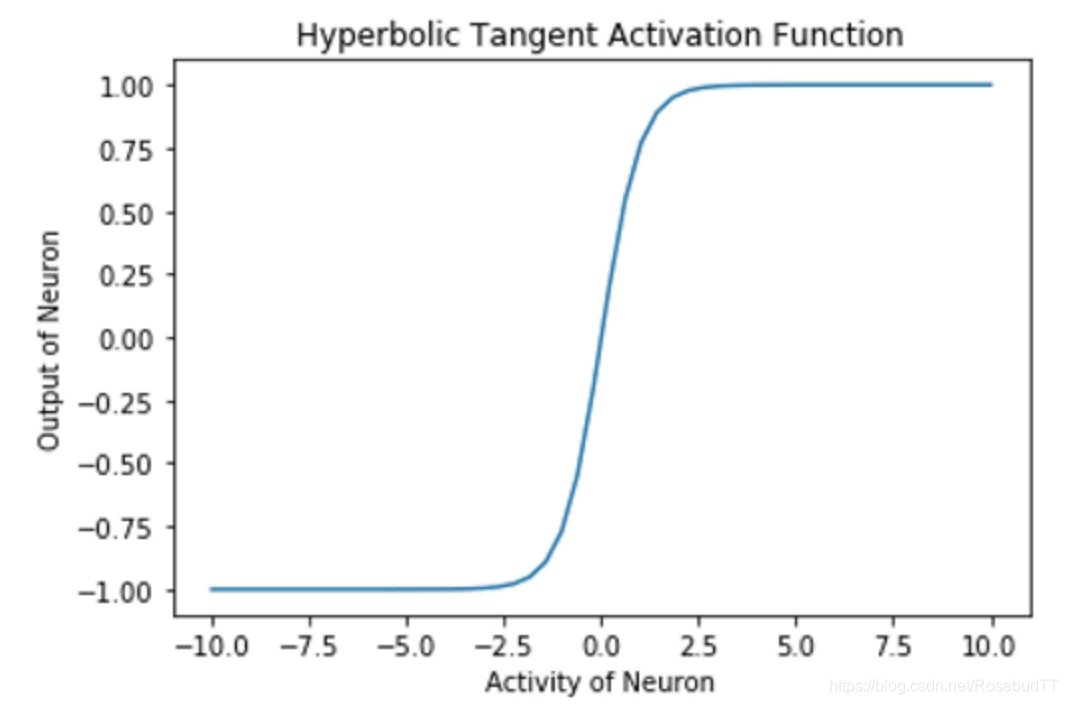
(4)线性激活函数:在这种情况下,神经元的输出与神经元的输入值相同。这个函数的任何一边都不受限制.使用这个函数,不能表示复杂数据集中存在的非线性。
(5)整流线性单元(ReLU)激活函数也被内置在 TensorFlow 库中。这个激活函数类似于线性激活函数,但有一个大的改变:对于负的输入值,神经元不会激活(输出为零),对于正的输入值,神经元的输出与输入值相同:
h=np.linspace(-10,10,50)
out=tf.nn.relu(h)
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
y=sess.run(out)
plt.xlabel('Activity of Neyron')
plt.ylabel('Output of Neuron')
plt.title('Hyperbolic Activation Function')
plt.plot(h,y)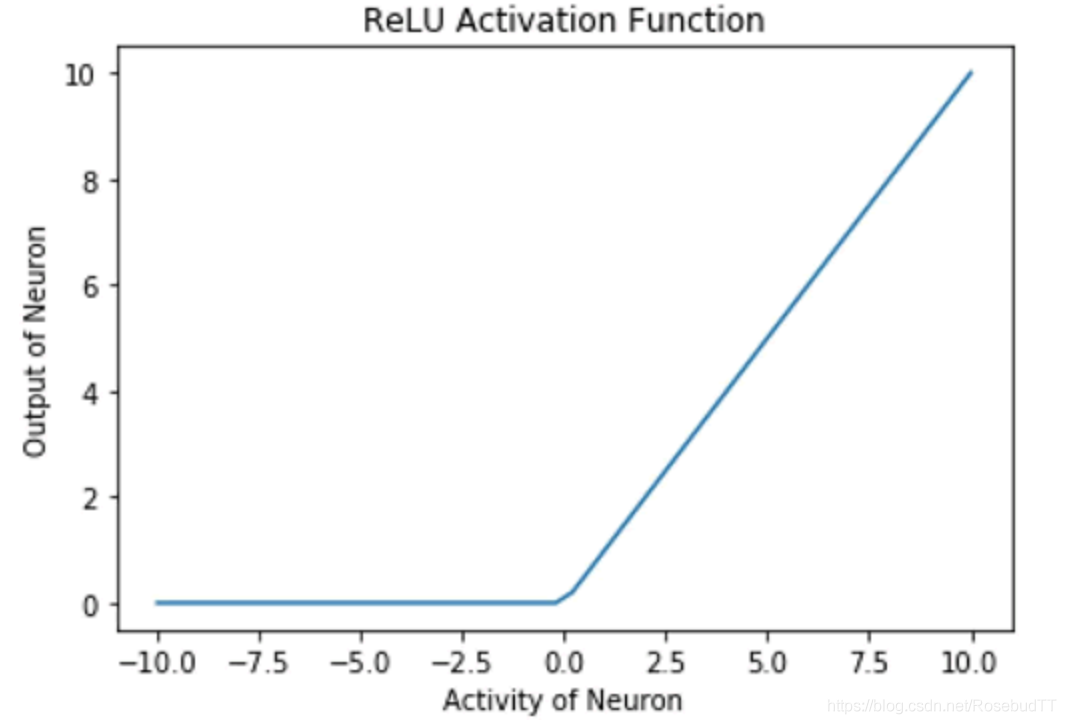
这种整流功能允许其用于多层时捕获非线性。 使用 ReLU 的主要优点之一是导致稀疏激活。在任何时刻,所有神经元的负的输入值都不会激活神经元。就计算量来说,这使得网络在计算方面更轻便。
(6)Softmax 激活函数是一个归一化的指数函数。一个神经元的输出不仅取决于其自身的输入值,还取决于该层中存在的所有其他神经元的输入的总和。这样做的一个优点是使得神经元的输出小,因此梯度不会过大。数学表达式为 yi =exp(xi)/Σjexp(xj):
h=np.linspace(-10,10,50)
out=tf.nn.softmax(h)
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
y=sess.run(out)
plt.xlabel('Activity of Neyron')
plt.ylabel('Output of Neuron')
plt.title('Softmax Activation Function')
plt.plot(h,y)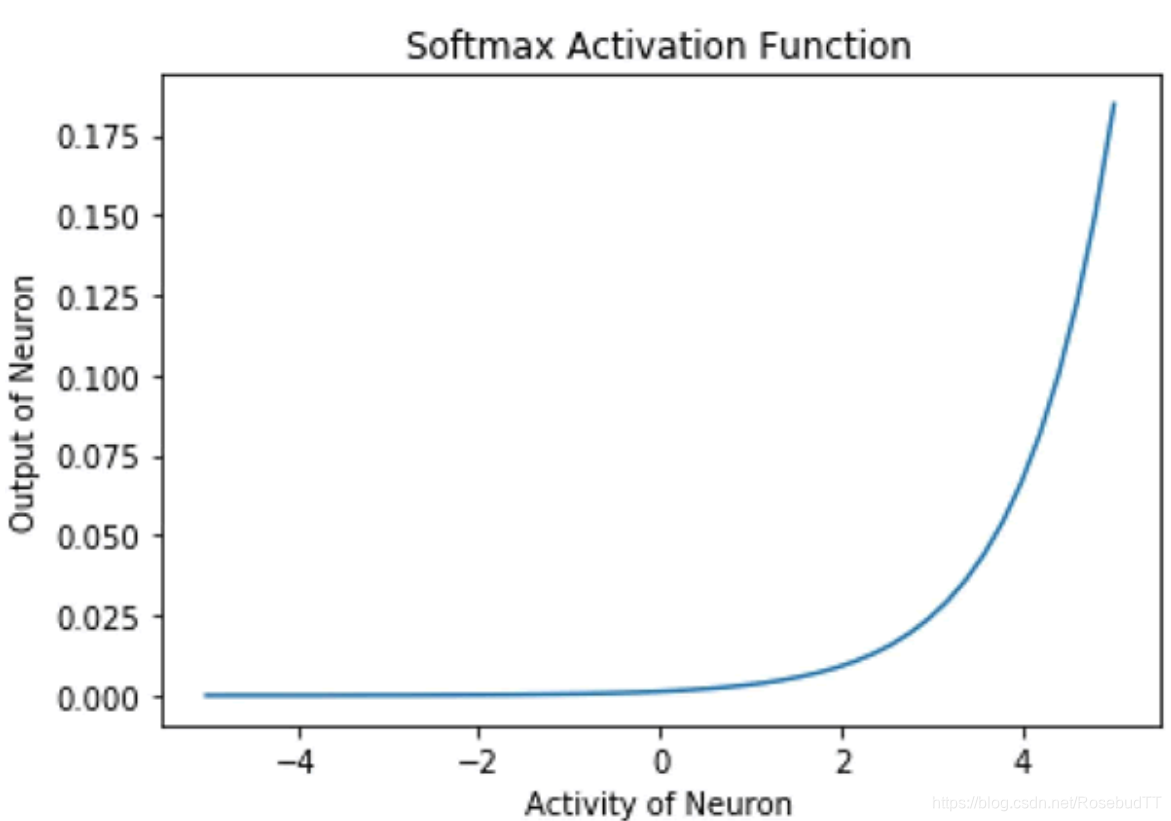
Softmax 激活函数被广泛用作输出层的激活函数,该函数的范围是 [0,1]。在多类分类问题中,它被用来表示一个类的概率。所有单位输出和总是 1.
一般来说,隐藏层最好使用 ReLU 神经元。对于分类任务,Softmax 通常是更好的选择;对于回归问题,最好使用 Sigmoid 函数或双曲正切函数。