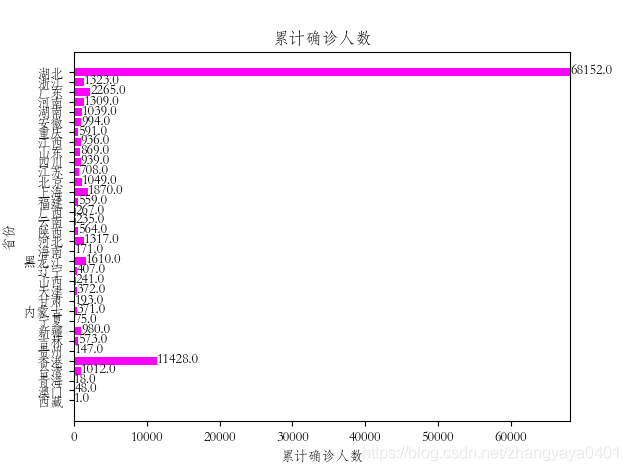
疫情数据处理与可视化
去年的这个时候是疫情的高发期,相信大家每天都会查阅疫情的发展情况。
下面这个网址是百度提供的疫情实时大数据报告
https://voice.baidu.com/act/newpneumonia/newpneumonia/?from=osari_pc_3
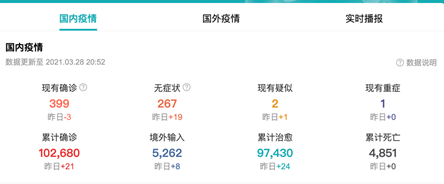
这节课,通过疫情数据案例,带大家体验一下数据可视化的过程。
1.获取数据
回忆一下获取数据步骤:
- 确定爬虫网址
- 用requests.get()方法获取网页全部信息
- 解析数据获取我们想要的信息
- 输出保存数据
以下代码为爬取疫情数据的代码,将疫情数据生成json文件。
需要注意的是这里使用了html.xpath()方法解析数据,也就是根据数据的路径来定位具体数据的位置。
import requests
from lxml import etree
import json
#爬虫
url="https://voice.baidu.com/act/newpneumonia/newpneumonia/?from=osari_aladin_banner"
res=requests.get(url)
html=etree.HTML(res.text)
result=html.xpath('//script[@type="application/json"]/text()')
result=result[0]
result=json.loads(result)
result_in=result['component'][0]['caseList']
result_in=json.dumps(result_in)
#生成json数据
with open('china_data.json','w') as file:
file.write(result_in)
用记事本打开json文件,复制全部,用json解析器解析数据。
https://www.json.cn/
任务1:
解析json数据,对比原网页,了解字典中的键代表着什么意思。
我们尝试着用Python读取json数据,代码如下所示:
import json
filename='china_data.json'
with open(filename) as f:
result_in=json.load(f)
这段代码将json数据读取到result_in变量中,该变量为列表类型。
任务2:
尝试着用循环语句输出result_in列表中的每个元素,也就是国内疫情的数据。
任务3:
通过观察发现,result_in列表中包含着大量的字典元素,每一个字典元素代表着一个省、自治区直辖市的疫情信息。请输出每个省市的已确诊人数
2.写入excel
现在我们要将json数据中的信息写入excel表中。这里使用了openpyxl第三方库。请同学们安装一下这个库。
步骤为:键盘win+R——输入cmd——在管理员界面输入:pip install openpyxl
下面是创建excel表的过程:
wb=openpyxl.Workbook() #新建一个excel文件
ws=wb.active #新建一个sheet文件
ws.title="国内疫情" #sheet名字为“国内疫情”
ws.append(['省份','累计确诊','死亡','治愈','现有确诊']) #导航栏名称
wb.save('./data_test.xlsx') #保存
接下来我们需要将json数据导入。用到的是ws.append()方法。意思是将数据依次写入到单元格中。
需要注意的是数据需要与列表头对应。
for i in result_in:
ws.append([i['area'],i['confirmed'])
任务4:
请补充上段代码,生成完整的国内疫情数据excel表格。
3.读取Excel数据
读取Excel数据和写入Excel数据刚好相反,步骤为:打开表格文件,获取具体工作表,新建字典变量储存数据,将数据写入字典。前三步比较好操作,对应的代码是:
#打开工作表
wb = openpyxl.load_workbook('data.xlsx')
#选中具体表格
ws = wb['国内疫情']
#创建字典
times = {}
#将数据添加到字典中
for row in ws.values:
if row[0] == '省份':
pass
else:
times[____] = float(_____)
任务5:
请同学们复制上段代码吗,完成填空,将Excel表中的数据写入字典。
4.制作词云
制作词云我们使用Wordcloud第三方库,步骤很简单,只需要三步:
1.新建一个词云对象,规定词云的一些属性
2.选择合适的方法生成词云
3.保存图片
wordcloud = WordCloud(font_path="C:/windows/Fonts/simfang.ttf",
background_color='white', width=1920, height=1080)
wordcloud.generate_from_frequencies(times)
wordcloud.to_file('wordcloud.png')
关于Wordcloud的一些方法:

任务6:
结合任务5中的代码,结合Wordcloud代码,尝试着根据新增人数的多少生成词云图。
5.制作条形图
Matplotlib是一个第三方库,内置了很多画图的函数。我们可以在它的官网上找到我们想要的图形及对应的代码,然后修改我们的数据就可以得到我们想要的图形了。网址为:https://matplotlib.org/stable/gallery/index.html
更多关于Matplotlib的内容,在下面这份文件中有简要介绍
Matplotlib简介
接下来我们要借用matplotlib中的画图函数来画一个条形图,下面代码为示例内容:
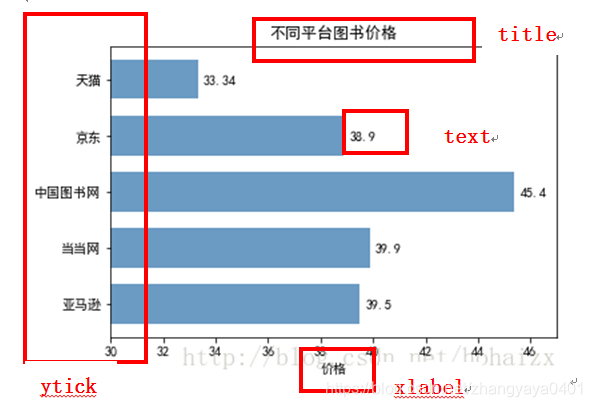
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
price = [39.5, 39.9, 45.4, 38.9, 33.34]
plt.barh(range(5), price, height=0.7, color='steelblue', alpha=0.8) # 从下往上画
plt.yticks(range(5), ['亚马逊', '当当网', '中国图书网', '京东', '天猫'])
plt.xlim(30, 47)
plt.xlabel("价格")
plt.title("不同平台图书价格")
for x, y in enumerate(price):
plt.text(y + 0.2, x - 0.1, '%s' % y)
plt.show()
得到的图形为:
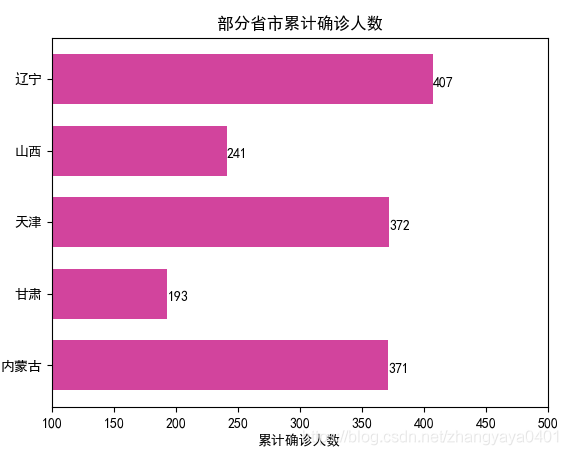
任务6:
修改上段代码的参数,绘制累计确诊人数与省份的条形图(取excel表中前5个省份数据即可)
任务6我们通过手动输入相应的数据,只有5个数据输入相对简单。如果数据较多呢,如何批量的输入数据?
通过观察发现如果我们把34个省的数据全部输入的话,我们需要更改哪几个参数?
x轴y轴坐标、横条的个数、以及x轴的取值范围。
X轴y轴坐标对应的是excel表的第一列和第二列,我们可以参照上节课制作词云的代码,主要思路是通过openpyxl读取excel表中的所有内容;新建两个空列表储存x轴和y轴的数据,遍历excel表,将数据append到对应的列表中。
wb = openpyxl.load_workbook('data.xlsx')
#获取工作表
ws = wb['国内疫情']
data=[]
place=[]
for row in ws.values:
if row[0] == '省份':
pass
else:
data.append(float(row[1]))
place.append(row[0])
生成的横条的个数,应该就是对应数据的个数,虽然我们知道是34,但如果出现数据不全的情况容易出错,最保险的我们用len()函数计算列表中元素的个数作为横条的个数。
plt.barh(range(len(data)), data, height=0.8,
color='fuchsia', alpha=1)
x轴的取值范围其实就是整个列表的最小值和最大值,可以用min()和max()函数来获取。
plt.xlim(min(data), max(data))
任务7:
请修改代码,生成我国各省市累计确诊人数的条形图。