时间序列预测方法总结
前言
对时间序列数据预测模型做个简单的分类,方便日后对其进一步研究,理清楚技术更新发展方向。
时间序列预测分析就是利用过去一段时间内某事件时间的特征来预测未来一段时间内该事件的特征。
预测场景
- 单步预测
- 单步单变量预测 :在时间序列预测中的标准做法是使用前一个的观测值,作为输入变量来预测当前的时间的观测值。
- 多步单变量预测 : 前几个观测值,预测下一个观测值
- 多步预测
- 单变量多步预测:前几个观测值数据,预测下几个观测值
- 多变量多步预测:几组不同维度的前几个观测值数据,预测下几个观测值
本文只是列举同方法中的几个模型作为介绍,还有很多的模型可以采用。
一、统计学方法 :
二、 传统时序方法:
2.1 AR
具有如下结构的模型称为p阶自回归模型,简记为AR:
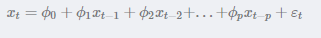
随机变量Xt的取值Xt是前p期xt−1,xt−2,…,xt−pxt−1,xt−2,…,xt−p的多元线性回归,认为xt主 要受过去p期的序列值影响。误差项是当前的随机干扰,为零均值白噪声序列
2.2 ARMA
自回归滑动平均模型(英语:Autoregressive moving average model,简称:ARMA模型)。是研究时间序列的重要方法,由自回归模型(简称AR模型)与移动平均模型(简称MA模型)为基础“混合”构成。
在市场研究中常用于长期追踪资料的研究,如:Panel研究中,用于消费行为模式变迁研究;在零售研究中,用于具有季节变动特征的销售量、市场规模的预测等。
2.3 ARIMA
ARIMA模型(英语:Autoregressive Integrated Moving Average model),差分整合移动平均自回归模型,又称整合移动平均自回归模型(移动也可称作滑动),是时间序列预测分析方法之一。
ARIMA(p,d,q)中,AR是“自回归”,p为自回归项数;MA为“滑动平均”,q为滑动平均项数,d为使之成为平稳序列所做的差分次数(阶数)。“差分”一词虽未出现在ARIMA的英文名称中,却是关键步骤。
总的来说,基于此类方法的建模步骤是,
- 首先需要对观测值序列进行平稳性检测,如果不平稳,则对其进行差分运算直到差分后的数据平稳;
- 在数据平稳后则对其进行白噪声检验,白噪声是指零均值常方差的随机平稳序列;如果是平稳非白噪声序列就计算ACF(自相关系数)、PACF(偏自相关系数),进行ARMA等模型识别,
- 对已识别好的模型,确定模型参数,
- 最后应用预测并进行误差分析。
三 、时间序列分解
时间序列分解法是数年来一直非常有用的方法,一个时间序列往往是一下几类变化形式的叠加或耦合
3.1 常见加法和乘法模型
数据分解为
- 长期趋势
- 季节变动 :显式周期,固定幅度、长度的周期波动
- 循环波动 :隐式周期,周期长不具严格规则的波动
- 不规则波动
分解之后的数据进行加法、乘法或者二者混合的方式进行组合。
3.2 经验模态分解
经验模态分解(Empirical Mode Decomposition,缩写EMD)是由黄锷(N. E. Huang)在美国国家宇航局与其他人于1998年创造性地提出的一种新型自适应信号时频处理方法,特别适用于非线性非平稳信号的分析处理。
实例介绍: 数字信号处理技术(一)经验模态分解(EMD)- Python代码
3.3 变分模态分解
在信号处理中,变分模态分解是一种信号分解估计方法。 该方法在获取分解分量的过程中通过迭代搜寻变分模型最优解来确定每个分量的频率中心和带宽,从而能够自适应地实现信号的频域剖分及各分量的有效分离。
实例介绍 : 数字信号处理技术(二)变分模态分解(VMD)-Python代码
四、 机器学习模型
4.1 XGBoost
XGBoost是陈天奇等人开发的一个开源机器学习项目,高效地实现了GBDT算法并进行了算法和工程上的许多改进,被广泛应用在Kaggle竞赛及其他许多机器学习竞赛中并取得了不错的成绩。
4.2 RF
在机器学习中,随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。 Leo Breiman和Adele Cutler发展出推论出随机森林的算法。 而 “Random Forests” 是他们的商标。
这个术语是1995年由贝尔实验室的Tin Kam Ho所提出的随机决策森林(random decision forests)而来的。这个方法则是结合 Breimans 的 “Bootstrap aggregating” 想法和 Ho 的"random subspace method"以建造决策树的集合。
4.3 SVR
SVR全称是support vector regression,是SVM(支持向量机support vector machine)对回归问题的一种运用
五、 深度学习模型
5.1 LSTM
Long Short Term Memory(LSTM):长短时记忆神经网络,是一种特殊的循环神经网络(RNN),优势在于解决RNN的梯度消失和梯度爆炸的问题,目前广泛应用于序列数据处理和预测,比如文本上下文感情分析,股票预测等;
5.2 Transformer
Transformer是2017年的一篇论文《Attention is All You Need》提出的一种模型架构,这篇论文里只针对机器翻译这一种场景做了实验,全面击败了当时的SOTA,并且由于encoder端是并行计算的,训练的时间被大大缩短了。
它开创性的思想,颠覆了以往序列建模和RNN划等号的思路,现在被广泛应用于NLP的各个领域。目前在NLP各业务全面开花的语言模型如GPT, BERT等,都是基于Transformer模型。
5.3 Bert
BERT是2018年10月由Google AI研究院提出的一种预训练模型。
BERT的全称是Bidirectional Encoder Representation from Transformers。BERT在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩: 全部两个衡量指标上全面超越人类,并且在11种不同NLP测试中创出SOTA表现,包括将GLUE基准推高至80.4% (绝对改进7.6%),MultiNLI准确度达到86.7% (绝对改进5.6%),成为NLP发展史上的里程碑式的模型成就。