python爬虫爬取糗事百科视频
python爬虫爬取糗事百科视频
注意:
需要提前配置好环境, 不会的话可以自行百度或者看我的另一篇博文, 链接:Windows下的Python安装教程(绝对详细)
1.安装第三方库
requests的安装
打开cmd, 执行命令 pip install requests,如图:
lxml的安装
打开cmd, 执行命令 pip install lxml,如图:
注意, 需要配置环境变量及pip镜像源为国内
2.代码
#!Python
# -*- encoding: utf-8 -*-
'''
1.文件名称 : QiuShiSpider.py
2.创建时间 : 2021/03/07 16:15:08
3.作者名称 : ZAY
4.Python版本 : 3.7.0
'''
import os
import requests
from lxml import etree
from multiprocessing import Pool
class Spider():
def __init__(self):
self.videos_list = []
self.geturl = "https://www.qiushibaike.com/video/page/{}/"
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36"}
self.make_folder()
def make_folder(self):
try:
os.mkdir("D:\\videos")
except FileExistsError:
pass
def get_url(self):
for num in range(1, 14):
url = self.geturl.format(num)
try:
response = requests.get(url, headers=self.headers)
response.encoding = "utf-8"
pyhtml = etree.HTML(response.text)
for video_url in pyhtml.xpath("//video//@src"):
self.videos_list.append(video_url)
print("正在获取{}的视频链接...".format(url))
except:
print("获取{}的视频链接失败!!!".format(url))
def download_videos(self, url):
filelist = os.listdir("D:\\videos")
try:
url = "https:" + url
filename = url.replace("https://qiubai-video.qiushibaike.com/", "")
if filename in filelist:
print("%s已存在!!!" % filename)
else:
video = requests.get(url, headers=self.headers).content
os.chdir("D:\\Videos")
with open("%s" % filename, 'wb') as file:
file.write(video)
print("%s下载成功!!!" % filename)
except:
print("%s下载失败!!!" % filename)
def run(self):
self.get_url()
pool = Pool()
pool.map(self.download_videos, self.videos_list)
if __name__ == "__main__":
spider = Spider()
spider.run()
3.运行效果
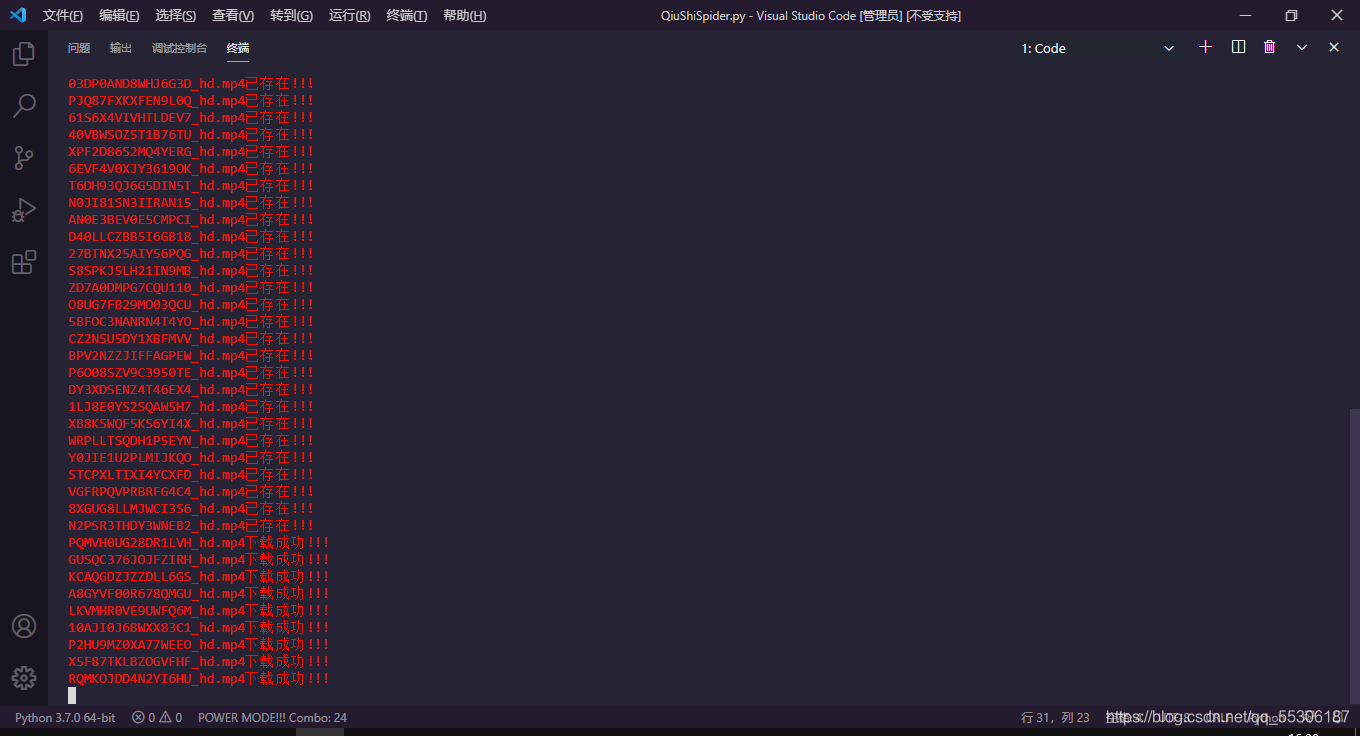
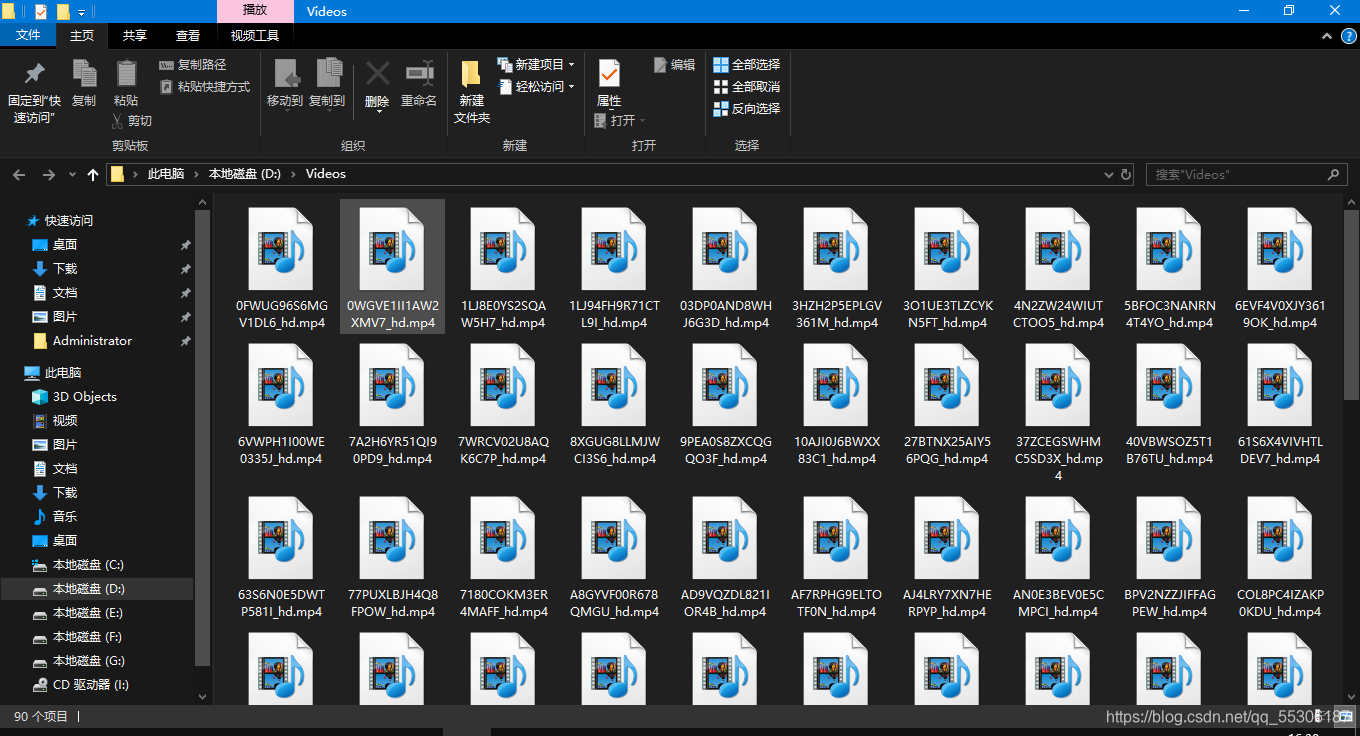
运行时, 将会多线程下载视频, 最终视频会保存在电脑的D:\videos下,如图:
若有疑问, 欢迎在评论区提问