[CVPR 2017] Look Closer to See Better: Recurrent Attention Convolutional Neural Network for FGVC
Recurrent Attention Convolutional Neural Network (RA-CNN)
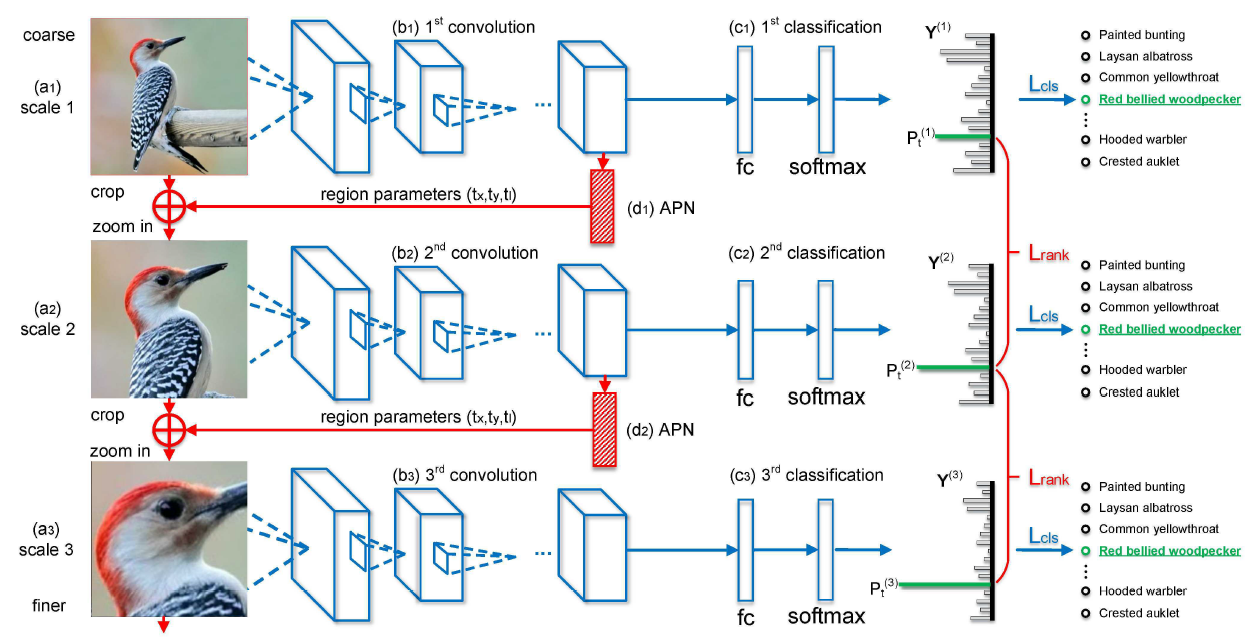
- Multi-task formulation:上图展示了 3 scales 的 RA-CNN 网络,由上到下,网络能逐渐识别出更细粒度的语义特征,并且通过不断堆叠网络结构,可以构造出更细粒度的识别流程。每层网络都由 APN + cls head 组成
- Attention Proposal Network (APN):假设每层的输入图像为
X
X
X,则
X
X
X 先由 CNN 抽取出语义特征
f
X
f_X
fX,APN 由
f
X
f_X
fX 得到 attended region (a square):
[ t x , t y , t l ] = g ( f X ) [t_x,t_y,t_l]=g(f_X) [tx,ty,tl]=g(fX)其中 t x , t y t_x,t_y tx,ty 为中心坐标, t l t_l tl 为边长的一半, g g g 为两个全连接层。之后 APN 就将 attended region 进行双线性插值放大后当作下一层网络的输入来抽取更细粒度的特征。为了确保 crop 操作可导,作者将一个二维窗函数用作 attention mask 来近似 crop 操作。窗函数定义如下:
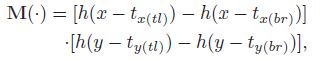 其中,
t
x
(
t
l
)
,
t
x
(
b
r
)
,
t
y
(
t
l
)
,
t
y
(
b
r
)
t_{x(tl)},t_{x(br)},t_{y(tl)},t_{y(br)}
tx(tl),tx(br),ty(tl),ty(br) 为 attended region 的左上和右下点坐标
其中,
t
x
(
t
l
)
,
t
x
(
b
r
)
,
t
y
(
t
l
)
,
t
y
(
b
r
)
t_{x(tl)},t_{x(br)},t_{y(tl)},t_{y(br)}
tx(tl),tx(br),ty(tl),ty(br) 为 attended region 的左上和右下点坐标
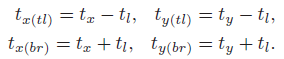 h
h
h 为 logistic function with index
k
k
k:
h
h
h 为 logistic function with index
k
k
k:
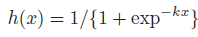 当
k
k
k 很大时,有
x
>
0
,
h
(
x
)
=
1
;
x
<
0
,
h
(
x
)
=
0
;
x
=
0
,
h
(
x
)
=
1
/
2
x>0,h(x)=1; x<0,h(x)=0; x=0,h(x)=1/2
x>0,h(x)=1;x<0,h(x)=0;x=0,h(x)=1/2,也就是说只有当
(
x
,
y
)
(x,y)
(x,y) 处于 attended region 内时,
M
(
x
,
y
)
M(x,y)
M(x,y) 才不为 0.
k
→
∞
⇒
{
h
(
x
)
=
1
x
>
0
h
(
x
)
=
0
x
<
0
h
(
x
)
=
1
/
2
x
=
0
k\rightarrow\infty\Rightarrow\left\{\begin{aligned}h(x)=1\quad x>0\\h(x)=0\quad x<0\\h(x)=1/2\quad x=0\end{aligned}\right.
k→∞⇒⎩
⎨
⎧h(x)=1x>0h(x)=0x<0h(x)=1/2x=0因此 attended region 可由下式得到:
当
k
k
k 很大时,有
x
>
0
,
h
(
x
)
=
1
;
x
<
0
,
h
(
x
)
=
0
;
x
=
0
,
h
(
x
)
=
1
/
2
x>0,h(x)=1; x<0,h(x)=0; x=0,h(x)=1/2
x>0,h(x)=1;x<0,h(x)=0;x=0,h(x)=1/2,也就是说只有当
(
x
,
y
)
(x,y)
(x,y) 处于 attended region 内时,
M
(
x
,
y
)
M(x,y)
M(x,y) 才不为 0.
k
→
∞
⇒
{
h
(
x
)
=
1
x
>
0
h
(
x
)
=
0
x
<
0
h
(
x
)
=
1
/
2
x
=
0
k\rightarrow\infty\Rightarrow\left\{\begin{aligned}h(x)=1\quad x>0\\h(x)=0\quad x<0\\h(x)=1/2\quad x=0\end{aligned}\right.
k→∞⇒⎩
⎨
⎧h(x)=1x>0h(x)=0x<0h(x)=1/2x=0因此 attended region 可由下式得到:
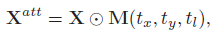 之后再进行双线性插值即可:
之后再进行双线性插值即可:
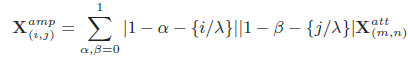 其中,
λ
\lambda
λ 为上采样系数,放大后图像上的点
(
i
,
j
)
(i,j)
(i,j) 在原图上对应的坐标为
(
i
/
λ
,
j
/
λ
)
(i/\lambda,j/\lambda)
(i/λ,j/λ),
m
=
[
i
/
λ
]
+
α
m=[i/\lambda]+\alpha
m=[i/λ]+α 为采样点周围 4 个点的两个
x
x
x 坐标,
n
=
[
j
/
λ
]
+
β
n=[j/\lambda]+\beta
n=[j/λ]+β 为采样点周围 4 个点的两个
y
y
y 坐标,
[
⋅
]
[\cdot]
[⋅] 为整数部分,
{
⋅
}
\{\cdot\}
{⋅} 为小数部分
其中,
λ
\lambda
λ 为上采样系数,放大后图像上的点
(
i
,
j
)
(i,j)
(i,j) 在原图上对应的坐标为
(
i
/
λ
,
j
/
λ
)
(i/\lambda,j/\lambda)
(i/λ,j/λ),
m
=
[
i
/
λ
]
+
α
m=[i/\lambda]+\alpha
m=[i/λ]+α 为采样点周围 4 个点的两个
x
x
x 坐标,
n
=
[
j
/
λ
]
+
β
n=[j/\lambda]+\beta
n=[j/λ]+β 为采样点周围 4 个点的两个
y
y
y 坐标,
[
⋅
]
[\cdot]
[⋅] 为整数部分,
{
⋅
}
\{\cdot\}
{⋅} 为小数部分
与 RPN 不同,APN 并没有使用任何 bbox 标签,而是使用弱监督学习来帮助模型定位特征显著区域
缺陷:图像中往往不止一个显著特征区域,但 APN 每次只能选出一个显著特征区域,无法同时抽取多个显著特征区域的特征,因此更深层的细粒度网络可能会丢失很多有用的语义信息,这一缺陷可以在一定程度上通过作者后面提出的 Multi-scale Joint Representation 进行弥补,但是更好的方法应该是如何抽取出更多的显著特征区域,并且在抽取细粒度信息的同时又不丢失全局信息
- Classification and Ranking:cls head 由
f
X
f_X
fX 经过 FC + softmax 后得到分类概率。损失函数由 intra-scale classification loss 和 inter-scale pairwise ranking loss 组成:
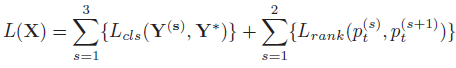 其中,
s
s
s 表示 scale,
Y
(
s
)
Y^{(s)}
Y(s) 表示 predicted label vector,
Y
∗
Y^*
Y∗ 表示 ground truth label vector,
p
t
(
s
)
p_t^{(s)}
pt(s) 表示 GT label
t
t
t 的预测概率。排序损失如下,它可以使得
p
t
(
s
+
1
)
>
p
t
(
s
)
+
m
a
r
g
i
n
p_t^{(s+1)}>p_t^{(s)} + margin
pt(s+1)>pt(s)+margin,这表示深层网络能够凭借细粒度信息更准确地预测出 GT 标签
其中,
s
s
s 表示 scale,
Y
(
s
)
Y^{(s)}
Y(s) 表示 predicted label vector,
Y
∗
Y^*
Y∗ 表示 ground truth label vector,
p
t
(
s
)
p_t^{(s)}
pt(s) 表示 GT label
t
t
t 的预测概率。排序损失如下,它可以使得
p
t
(
s
+
1
)
>
p
t
(
s
)
+
m
a
r
g
i
n
p_t^{(s+1)}>p_t^{(s)} + margin
pt(s+1)>pt(s)+margin,这表示深层网络能够凭借细粒度信息更准确地预测出 GT 标签
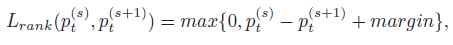
- Multi-scale Joint Representation:由 RA-CNN 最终可以得到对应不同粒度的
N
N
N 个特征 (cls head 的 FC 输出)
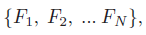 为了充分利用这些多尺度特征,作者分别将
F
i
F_i
Fi 归一化,concat 后由 FC + softmax 得到分类结果
为了充分利用这些多尺度特征,作者分别将
F
i
F_i
Fi 归一化,concat 后由 FC + softmax 得到分类结果
Experiments
- Attention localization


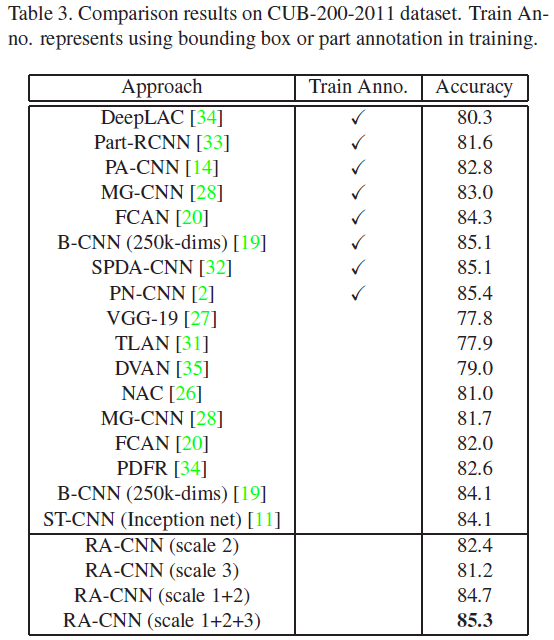
- CUB-200-2011 (下表中的 scale
i
,
j
i,j
i,j 代表使用 scale
i
,
j
i,j
i,j 输出的特征进行融合分类)
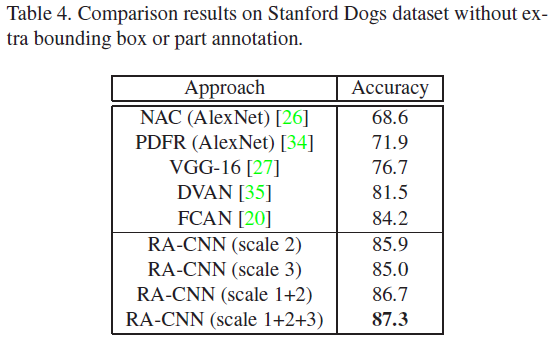
- Stanford Dogs
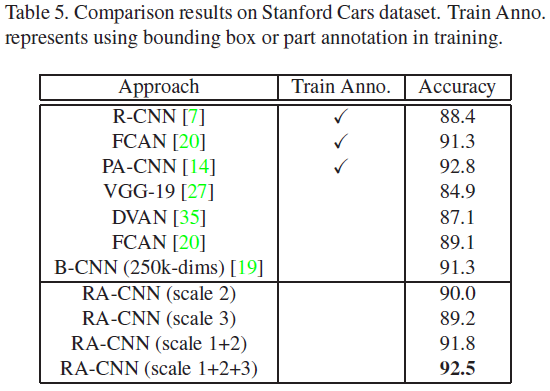
- Stanford Cars
References
- Fu, Jianlong, Heliang Zheng, and Tao Mei. “Look closer to see better: Recurrent attention convolutional neural network for fine-grained image recognition.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
- code: https://github.com/Jianlong-Fu/Recurrent-Attention-CNN