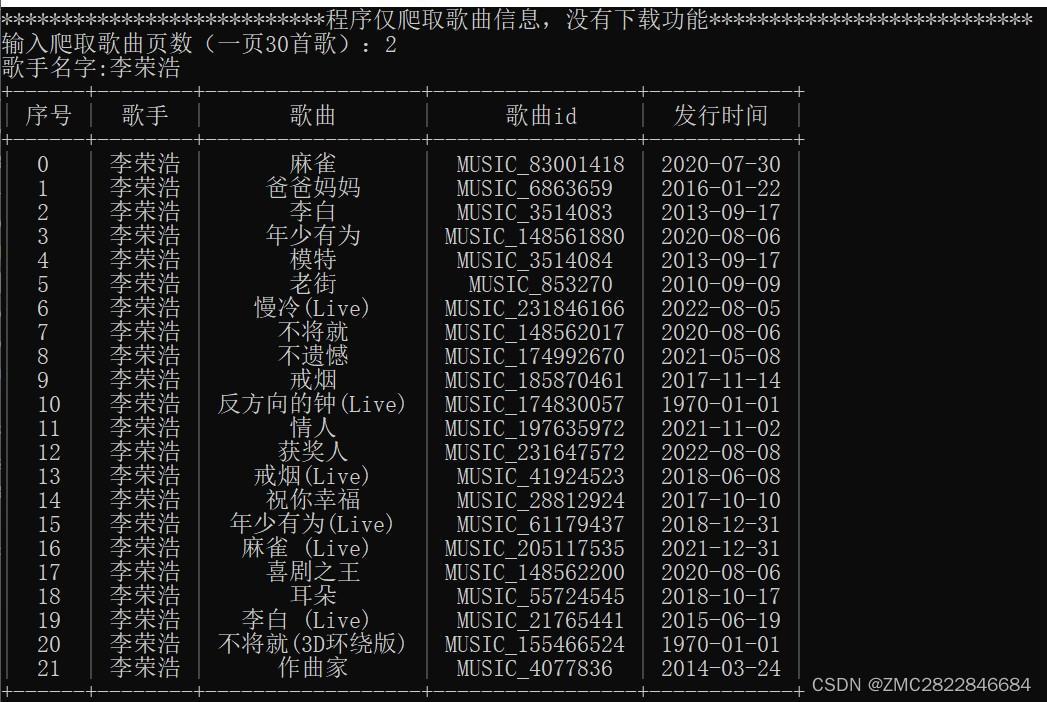
python简单程序爬取酷我音乐歌曲信息
程序自动过滤掉《歌手(artist)》部分字符串长度大于6字节的数据,使后期的表格更美观
{kind=link}
程序--down_music--方法中: header部分得自己加上去
在酷我音乐中按12打开点击network,Ctrl+R刷新一下随便打开一个文件查看
Cookie: csrfHost: Referer: User-Agent: 如需要有30条数据,需要删除第39行条件判断:
'''
歌曲连接:
http://www.kuwo.cn/api/www/search/searchMusicBykeyWord?key=%E6%9D%8E%E8%8D%A3%E6%B5%A9&pn=1&rn=30&httpsStatus=1&reqId=189d5b41-238d-11ed-acf4-4f6bf15618b2
'''
import requests
import prettytable as pt # 制表
import time
class Kuwo_music:
def __init__(self, urls):
self.urls = urls
def get_html(self, url):
header = {
"Cookie": "自己加 ",
"csrf": "自己加",
"Host": "www.kuwo.cn",
"Referer": "http://www.kuwo.cn/search/list?key=%E6%9D%8E%E8%8D%A3%E6%B5%A9",
"User-Agent": "自己加"
}
return requests.get(url, headers=header)
def down_music(self):
json_data = self.get_html(self.urls).json()
json_list = json_data['data']['list']
tb = pt.PrettyTable()
tb.field_names = ["序号", "歌手", "歌曲", "歌曲id", "发行时间"]
count = 0
for data in json_list:
artist = data["artist"]
name = data["name"]
musicrid = data["musicrid"]
releaseDate = data["releaseDate"]
if len(artist) <= 6:
tb.add_row([count, artist, name, musicrid, releaseDate])
else:
continue
count += 1
print(tb)
if __name__ == '__main__':
print("程序仅爬取歌曲信息,没有下载功能".center(70, '*'))
pages = int(input("输入爬取歌曲页数(一页30首歌):"))
name = input("歌手名字:")
for page in range(1, pages + 1):
urls = f"http://www.kuwo.cn/api/www/search/searchMusicBykeyWord?key={name}&pn={page}&rn=30&httpsStatus=1" \
"&reqId=189d5b41-238d-11ed-acf4-4f6bf15618b2 "
wo = Kuwo_music(urls)
wo.down_music()
time.sleep(0.5)
input('Press<Enter')
运行查看结果: