阿里云-零基础入门推荐系统 【排序模型+模型融合】
学习过程
20年当时自身功底是比较零基础(会写些基础的Python[三个科学计算包]数据分析),一开始看这块其实挺懵的,不会就去问百度或其他人,当时遇见困难挺害怕的,但22后面开始力扣题【目前已刷好几轮,博客没写力扣文章之前,力扣排名靠前已刷有5遍左右,排名靠后刷3次左右,代码功底也在一步一步提升】不断地刷、遇见代码不懂的代码,也开始去打印print去理解,到后面问其他人的问题越来越少,个人自主学习、自主解决能力也得到了进一步增强。
赛题介绍
该赛题是以新闻APP中的新闻推荐为背景, 目的是要求我们根据用户历史浏览点击新闻文章的数据信息预测用户未来的点击行为, 即用户的最后一次点击的新闻文章。
评价方式理解
最后提交的格式是针对每个用户, 我们都会给出五篇文章的推荐结果,按照点击概率从前往后排序。 而真实的每个用户最后一次点击的文章只会有一篇的真实答案, 所以我们就看我们推荐的这五篇里面是否有命中真实答案的。比如对于user1来说, 我们的提交会是:
user1, article1, article2, article3, article4, article5.
评价指标的公式如下:
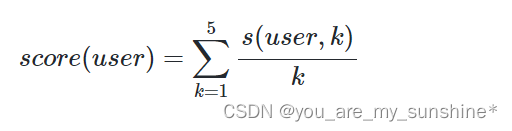
假如article1就是真实的用户点击文章,也就是article1命中, 则s(user1,1)=1, s(user1,2-4)都是0, 如果article2是用户点击的文章, 则s(user,2)=1/2,s(user,1,3,4,5)都是0。也就是score(user)=命中第几条的倒数。如果都没中, 则score(user1)=0。 这个是合理的, 因为我们希望的就是命中的结果尽量靠前, 而此时分数正好比较高。
赛题理解
根据赛题简介,我们首先要明确我们此次比赛的目标: 根据用户历史浏览点击新闻的数据信息预测用户最后一次点击的新闻文章。从这个目标上看, 会发现此次比赛和我们之前遇到的普通的结构化比赛不太一样, 主要有两点:
- 首先是目标上, 要预测最后一次点击的新闻文章,也就是我们给用户推荐的是新闻文章, 并不是像之前那种预测一个数或者预测数据哪一类那样的问题
- 数据上, 通过给出的数据我们会发现, 这种数据也不是我们之前遇到的那种特征+标签的数据,而是基于了真实的业务场景, 拿到的用户的点击日志
所以拿到这个题目,我们的思考方向就是结合我们的目标,把该预测问题转成一个监督学习的问题(特征+标签),然后我们才能进行ML,DL等建模预测。
排序模型
通过召回的操作, 我们已经进行了问题规模的缩减, 对于每个用户, 选择出了N篇文章作为了候选集,并基于召回的候选集构建了与用户历史相关的特征,以及用户本身的属性特征,文章本省的属性特征,以及用户与文章之间的特征,下面就是使用机器学习模型来对构造好的特征进行学习,然后对测试集进行预测,得到测试集中的每个候选集用户点击的概率,返回点击概率最大的topk个文章,作为最终的结果。
排序阶段选择了三个比较有代表性的排序模型,它们分别是:
- LGB的排序模型
- LGB的分类模型
- 深度学习的分类模型DIN
得到了最终的排序模型输出的结果之后,还选择了两种比较经典的模型集成的方法:
- 输出结果加权融合
- Staking(将模型的输出结果再使用一个简单模型进行预测)
import numpy as np
import pandas as pd
import pickle
from tqdm import tqdm
import gc, os
import time
from datetime import datetime
import lightgbm as lgb
from sklearn.preprocessing import MinMaxScaler
import warnings
warnings.filterwarnings('ignore')
读取排序特征
#data_path = './data_raw/'
#save_path = './temp_results/'
data_path = '/data/temp/用户行为预测数据集/' # '/home/admin/jupyter/data/' # 天池平台路径
save_path = 'results/0227/' # '/home/admin/jupyter/temp_results/' # 天池平台路径
offline = False
转化类型
# 重新读取数据的时候,发现click_article_id是一个浮点数,所以将其转换成int类型
trn_user_item_feats_df = pd.read_csv(save_path + 'trn_user_item_feats_df.csv')
trn_user_item_feats_df['click_article_id'] = trn_user_item_feats_df['click_article_id'].astype(int)
if offline:
val_user_item_feats_df = pd.read_csv(save_path + 'val_user_item_feats_df.csv')
val_user_item_feats_df['click_article_id'] = val_user_item_feats_df['click_article_id'].astype(int)
else:
val_user_item_feats_df = None
tst_user_item_feats_df = pd.read_csv(save_path + 'tst_user_item_feats_df.csv')
tst_user_item_feats_df['click_article_id'] = tst_user_item_feats_df['click_article_id'].astype(int)
# 做特征的时候为了方便,给测试集也打上了一个无效的标签,这里直接删掉就行
del tst_user_item_feats_df['label']
返回排序后的结果
def submit(recall_df, topk=5, model_name=None):
recall_df = recall_df.sort_values(by=['user_id', 'pred_score'])
recall_df['rank'] = recall_df.groupby(['user_id'])['pred_score'].rank(ascending=False, method='first')
# 判断是不是每个用户都有5篇文章及以上
tmp = recall_df.groupby('user_id').apply(lambda x: x['rank'].max())
assert tmp.min() >= topk
del recall_df['pred_score']
submit = recall_df[recall_df['rank'] <= topk].set_index(['user_id', 'rank']).unstack(-1).reset_index()
submit.columns = [int(col) if isinstance(col, int) else col for col in submit.columns.droplevel(0)]
# 按照提交格式定义列名
submit = submit.rename(columns={'': 'user_id', 1: 'article_1', 2: 'article_2',
3: 'article_3', 4: 'article_4', 5: 'article_5'})
save_name = save_path + model_name + '_' + datetime.today().strftime('%m-%d') + '.csv'
submit.to_csv(save_name, index=False, header=True)
排序结果归一化
def norm_sim(sim_df, weight=0.0):
# print(sim_df.head())
min_sim = sim_df.min()
max_sim = sim_df.max()
if max_sim == min_sim:
sim_df = sim_df.apply(lambda sim: 1.0)
else:
sim_df = sim_df.apply(lambda sim: 1.0 * (sim - min_sim) / (max_sim - min_sim))
sim_df = sim_df.apply(lambda sim: sim + weight) # plus one
return sim_df
LGB排序模型
# 防止中间出错之后重新读取数据
trn_user_item_feats_df_rank_model = trn_user_item_feats_df.copy()
if offline:
val_user_item_feats_df_rank_model = val_user_item_feats_df.copy()
tst_user_item_feats_df_rank_model = tst_user_item_feats_df.copy()
定义特征列
lgb_cols = ['sim0', 'time_diff0', 'word_diff0','sim_max', 'sim_min', 'sim_sum',
'sim_mean', 'score','click_size', 'time_diff_mean', 'active_level',
'click_environment','click_deviceGroup', 'click_os', 'click_country',
'click_region','click_referrer_type', 'user_time_hob1', 'user_time_hob2',
'words_hbo', 'category_id', 'created_at_ts','words_count']
排序模型分组
trn_user_item_feats_df_rank_model.sort_values(by=['user_id'], inplace=True)
g_train = trn_user_item_feats_df_rank_model.groupby(['user_id'], as_index=False).count()["label"].values
if offline:
val_user_item_feats_df_rank_model.sort_values(by=['user_id'], inplace=True)
g_val = val_user_item_feats_df_rank_model.groupby(['user_id'], as_index=False).count()["label"].values
排序模型定义
lgb_ranker = lgb.LGBMRanker(boosting_type='gbdt', num_leaves=31, reg_alpha=0.0, reg_lambda=1,
max_depth=-1, n_estimators=100, subsample=0.7, colsample_bytree=0.7, subsample_freq=1,
learning_rate=0.01, min_child_weight=50, random_state=2018, n_jobs= 16)
排序模型训练
if offline:
lgb_ranker.fit(trn_user_item_feats_df_rank_model[lgb_cols], trn_user_item_feats_df_rank_model['label'], group=g_train,
eval_set=[(val_user_item_feats_df_rank_model[lgb_cols], val_user_item_feats_df_rank_model['label'])],
eval_group= [g_val], eval_at=[1, 2, 3, 4, 5], eval_metric=['ndcg', ], early_stopping_rounds=50, )
else:
lgb_ranker.fit(trn_user_item_feats_df[lgb_cols], trn_user_item_feats_df['label'], group=g_train)
lgb_ranker模型预测
tst_user_item_feats_df['pred_score'] = lgb_ranker.predict(tst_user_item_feats_df[lgb_cols], num_iteration=lgb_ranker.best_iteration_)
# 将这里的排序结果保存一份,用户后面的模型融合
tst_user_item_feats_df[['user_id', 'click_article_id', 'pred_score']].to_csv(save_path + 'lgb_ranker_score.csv', index=False)
lgb_ranker预测结果重新排序及生成提交结果
rank_results = tst_user_item_feats_df[['user_id', 'click_article_id', 'pred_score']]
rank_results['click_article_id'] = rank_results['click_article_id'].astype(int)
submit(rank_results, topk=5, model_name='lgb_ranker')
lgb_ranker五折交叉验证
# 五折交叉验证,这里的五折交叉是以用户为目标进行五折划分
# 这一部分与前面的单独训练和验证是分开的
def get_kfold_users(trn_df, n=5):
user_ids = trn_df['user_id'].unique()
user_set = [user_ids[i::n] for i in range(n)]
return user_set
k_fold = 5
trn_df = trn_user_item_feats_df_rank_model
user_set = get_kfold_users(trn_df, n=k_fold)
score_list = []
score_df = trn_df[['user_id', 'click_article_id','label']]
sub_preds = np.zeros(tst_user_item_feats_df_rank_model.shape[0])
# 五折交叉验证,并将中间结果保存用于staking
for n_fold, valid_user in enumerate(user_set):
train_idx = trn_df[~trn_df['user_id'].isin(valid_user)] # add slide user
valid_idx = trn_df[trn_df['user_id'].isin(valid_user)]
# 训练集与验证集的用户分组
train_idx.sort_values(by=['user_id'], inplace=True)
g_train = train_idx.groupby(['user_id'], as_index=False).count()["label"].values
valid_idx.sort_values(by=['user_id'], inplace=True)
g_val = valid_idx.groupby(['user_id'], as_index=False).count()["label"].values
# 定义模型
lgb_ranker = lgb.LGBMRanker(boosting_type='gbdt', num_leaves=31, reg_alpha=0.0, reg_lambda=1,
max_depth=-1, n_estimators=100, subsample=0.7, colsample_bytree=0.7, subsample_freq=1,
learning_rate=0.01, min_child_weight=50, random_state=2018, n_jobs= 16)
# 训练模型
lgb_ranker.fit(train_idx[lgb_cols], train_idx['label'], group=g_train,
eval_set=[(valid_idx[lgb_cols], valid_idx['label'])], eval_group= [g_val],
eval_at=[1, 2, 3, 4, 5], eval_metric=['ndcg', ], early_stopping_rounds=50, )
# 预测验证集结果
valid_idx['pred_score'] = lgb_ranker.predict(valid_idx[lgb_cols], num_iteration=lgb_ranker.best_iteration_)
# 对输出结果进行归一化
valid_idx['pred_score'] = valid_idx[['pred_score']].transform(lambda x: norm_sim(x))
valid_idx.sort_values(by=['user_id', 'pred_score'])
valid_idx['pred_rank'] = valid_idx.groupby(['user_id'])['pred_score'].rank(ascending=False, method='first')
# 将验证集的预测结果放到一个列表中,后面进行拼接
score_list.append(valid_idx[['user_id', 'click_article_id', 'pred_score', 'pred_rank']])
# 如果是线上测试,需要计算每次交叉验证的结果相加,最后求平均
if not offline:
sub_preds += lgb_ranker.predict(tst_user_item_feats_df_rank_model[lgb_cols], lgb_ranker.best_iteration_)
score_df_ = pd.concat(score_list, axis=0)
score_df = score_df.merge(score_df_, how='left', on=['user_id', 'click_article_id'])
# 保存训练集交叉验证产生的新特征
score_df[['user_id', 'click_article_id', 'pred_score', 'pred_rank', 'label']].to_csv(save_path + 'trn_lgb_ranker_feats.csv', index=False)
# 测试集的预测结果,多次交叉验证求平均,将预测的score和对应的rank特征保存,可以用于后面的staking,这里还可以构造其他更多的特征
tst_user_item_feats_df_rank_model['pred_score'] = sub_preds / k_fold
tst_user_item_feats_df_rank_model['pred_score'] = tst_user_item_feats_df_rank_model['pred_score'].transform(lambda x: norm_sim(x))
tst_user_item_feats_df_rank_model.sort_values(by=['user_id', 'pred_score'])
tst_user_item_feats_df_rank_model['pred_rank'] = tst_user_item_feats_df_rank_model.groupby(['user_id'])['pred_score'].rank(ascending=False, method='first')
# 保存测试集交叉验证的新特征
tst_user_item_feats_df_rank_model[['user_id', 'click_article_id', 'pred_score', 'pred_rank']].to_csv(save_path + 'tst_lgb_ranker_feats.csv', index=False)
lgb_ranker五折交叉验证预测结果重新排序, 及生成提交结果
# 单模型生成提交结果
rank_results = tst_user_item_feats_df_rank_model[['user_id', 'click_article_id', 'pred_score']]
rank_results['click_article_id'] = rank_results['click_article_id'].astype(int)
submit(rank_results, topk=5, model_name='lgb_ranker_5zhe')
LGB分类模型
# 模型及参数的定义
lgb_Classfication = lgb.LGBMClassifier(boosting_type='gbdt', num_leaves=31, reg_alpha=0.0, reg_lambda=1,
max_depth=-1, n_estimators=500, subsample=0.7, colsample_bytree=0.7, subsample_freq=1,
learning_rate=0.01, min_child_weight=50, random_state=2018, n_jobs= 16, verbose=10)
模型训练
if offline:
lgb_Classfication.fit(trn_user_item_feats_df_rank_model[lgb_cols], trn_user_item_feats_df_rank_model['label'],
eval_set=[(val_user_item_feats_df_rank_model[lgb_cols], val_user_item_feats_df_rank_model['label'])],
eval_metric=['auc', ],early_stopping_rounds=50, )
else:
lgb_Classfication.fit(trn_user_item_feats_df_rank_model[lgb_cols], trn_user_item_feats_df_rank_model['label'])
模型预测
tst_user_item_feats_df['pred_score'] = lgb_Classfication.predict_proba(tst_user_item_feats_df[lgb_cols])[:,1]
# 将这里的排序结果保存一份,用户后面的模型融合
tst_user_item_feats_df[['user_id', 'click_article_id', 'pred_score']].to_csv(save_path + 'lgb_cls_score.csv', index=False)
lgb_cls预测结果重新排序, 及生成提交结果
rank_results = tst_user_item_feats_df[['user_id', 'click_article_id', 'pred_score']]
rank_results['click_article_id'] = rank_results['click_article_id'].astype(int)
submit(rank_results, topk=5, model_name='lgb_cls')
lgb_cls五折交叉验证
# 五折交叉验证,这里的五折交叉是以用户为目标进行五折划分
# 这一部分与前面的单独训练和验证是分开的
def get_kfold_users(trn_df, n=5):
user_ids = trn_df['user_id'].unique()
user_set = [user_ids[i::n] for i in range(n)]
return user_set
k_fold = 5
trn_df = trn_user_item_feats_df_rank_model
user_set = get_kfold_users(trn_df, n=k_fold)
score_list = []
score_df = trn_df[['user_id', 'click_article_id', 'label']]
sub_preds = np.zeros(tst_user_item_feats_df_rank_model.shape[0])
# 五折交叉验证,并将中间结果保存用于staking
for n_fold, valid_user in enumerate(user_set):
train_idx = trn_df[~trn_df['user_id'].isin(valid_user)] # add slide user
valid_idx = trn_df[trn_df['user_id'].isin(valid_user)]
# 模型及参数的定义
lgb_Classfication = lgb.LGBMClassifier(boosting_type='gbdt', num_leaves=31, reg_alpha=0.0, reg_lambda=1,
max_depth=-1, n_estimators=100, subsample=0.7, colsample_bytree=0.7, subsample_freq=1,
learning_rate=0.01, min_child_weight=50, random_state=2018, n_jobs= 16, verbose=10)
# 训练模型
lgb_Classfication.fit(train_idx[lgb_cols], train_idx['label'],eval_set=[(valid_idx[lgb_cols], valid_idx['label'])],
eval_metric=['auc', ],early_stopping_rounds=50, )
# 预测验证集结果
valid_idx['pred_score'] = lgb_Classfication.predict_proba(valid_idx[lgb_cols],
num_iteration=lgb_Classfication.best_iteration_)[:,1]
# 对输出结果进行归一化 分类模型输出的值本身就是一个概率值不需要进行归一化
# valid_idx['pred_score'] = valid_idx[['pred_score']].transform(lambda x: norm_sim(x))
valid_idx.sort_values(by=['user_id', 'pred_score'])
valid_idx['pred_rank'] = valid_idx.groupby(['user_id'])['pred_score'].rank(ascending=False, method='first')
# 将验证集的预测结果放到一个列表中,后面进行拼接
score_list.append(valid_idx[['user_id', 'click_article_id', 'pred_score', 'pred_rank']])
# 如果是线上测试,需要计算每次交叉验证的结果相加,最后求平均
if not offline:
sub_preds += lgb_Classfication.predict_proba(tst_user_item_feats_df_rank_model[lgb_cols],
num_iteration=lgb_Classfication.best_iteration_)[:,1]
score_df_ = pd.concat(score_list, axis=0)
score_df = score_df.merge(score_df_, how='left', on=['user_id', 'click_article_id'])
# 保存训练集交叉验证产生的新特征
score_df[['user_id', 'click_article_id', 'pred_score', 'pred_rank', 'label']].to_csv(save_path + 'trn_lgb_cls_feats.csv', index=False)
# 测试集的预测结果,多次交叉验证求平均,将预测的score和对应的rank特征保存,可以用于后面的staking,这里还可以构造其他更多的特征
tst_user_item_feats_df_rank_model['pred_score'] = sub_preds / k_fold
tst_user_item_feats_df_rank_model['pred_score'] = tst_user_item_feats_df_rank_model['pred_score'].transform(lambda x: norm_sim(x))
tst_user_item_feats_df_rank_model.sort_values(by=['user_id', 'pred_score'])
tst_user_item_feats_df_rank_model['pred_rank'] = tst_user_item_feats_df_rank_model.groupby(['user_id'])['pred_score'].rank(ascending=False, method='first')
# 保存测试集交叉验证的新特征
tst_user_item_feats_df_rank_model[['user_id', 'click_article_id', 'pred_score', 'pred_rank']].to_csv(save_path + 'tst_lgb_cls_feats.csv', index=False)
lgb_cls五折交叉验证预测结果重新排序
# 预测结果重新排序, 及生成提交结果
rank_results = tst_user_item_feats_df_rank_model[['user_id', 'click_article_id', 'pred_score']]
rank_results['click_article_id'] = rank_results['click_article_id'].astype(int)
submit(rank_results, topk=5, model_name='lgb_cls_5zhe')
模型融合
加权融合
# 读取多个模型的排序结果文件
lgb_ranker = pd.read_csv(save_path + 'lgb_ranker_score.csv')
lgb_cls = pd.read_csv(save_path + 'lgb_cls_score.csv')
#din_ranker = pd.read_csv(save_path + 'din_rank_score.csv')
# 这里也可以换成交叉验证输出的测试结果进行加权融合
rank_model = {'lgb_ranker': lgb_ranker,
'lgb_cls': lgb_cls}
#'din_ranker': din_ranker}
def get_ensumble_predict_topk(rank_model, topk=5):
#final_recall = rank_model['lgb_cls'].append(rank_model['din_ranker'])
final_recall = rank_model['lgb_cls'].append(rank_model['lgb_ranker'])
rank_model['lgb_ranker']['pred_score'] = rank_model['lgb_ranker']['pred_score'].transform(lambda x: norm_sim(x))
#final_recall = final_recall.append(rank_model['lgb_ranker'])
final_recall = final_recall.groupby(['user_id', 'click_article_id'])['pred_score'].sum().reset_index()
submit(final_recall, topk=topk, model_name='ensemble_fuse')
get_ensumble_predict_topk(rank_model)
Staking

# 读取多个模型的交叉验证生成的结果文件
# 训练集
trn_lgb_ranker_feats = pd.read_csv(save_path + 'trn_lgb_ranker_feats.csv')
trn_lgb_cls_feats = pd.read_csv(save_path + 'trn_lgb_cls_feats.csv')
#trn_din_cls_feats = pd.read_csv(save_path + 'trn_din_cls_feats.csv')
# 测试集
tst_lgb_ranker_feats = pd.read_csv(save_path + 'tst_lgb_ranker_feats.csv')
tst_lgb_cls_feats = pd.read_csv(save_path + 'tst_lgb_cls_feats.csv')
#tst_din_cls_feats = pd.read_csv(save_path + 'tst_din_cls_feats.csv')
将多个模型输出的特征进行拼接
finall_trn_ranker_feats = trn_lgb_ranker_feats[['user_id', 'click_article_id', 'label']]
finall_tst_ranker_feats = tst_lgb_ranker_feats[['user_id', 'click_article_id']]
for idx, trn_model in enumerate([trn_lgb_ranker_feats, trn_lgb_cls_feats]):
for feat in [ 'pred_score', 'pred_rank']:
col_name = feat + '_' + str(idx)
finall_trn_ranker_feats[col_name] = trn_model[feat]
for idx, tst_model in enumerate([tst_lgb_ranker_feats, tst_lgb_cls_feats]):
for feat in [ 'pred_score', 'pred_rank']:
col_name = feat + '_' + str(idx)
finall_tst_ranker_feats[col_name] = tst_model[feat]
定义一个逻辑回归模型再次拟合交叉验证产生的特征对测试集进行预测
# 这里需要注意的是,在做交叉验证的时候可以构造多一些与输出预测值相关的特征,来丰富这里简单模型的特征
from sklearn.linear_model import LogisticRegression
feat_cols = ['pred_score_0', 'pred_rank_0', 'pred_score_1', 'pred_rank_1']
trn_x = finall_trn_ranker_feats[feat_cols]
trn_y = finall_trn_ranker_feats['label']
tst_x = finall_tst_ranker_feats[feat_cols]
# 定义模型
lr = LogisticRegression()
# 模型训练
lr.fit(trn_x, trn_y)
# 模型预测
finall_tst_ranker_feats['pred_score'] = lr.predict_proba(tst_x)[:, 1]
ensumble_staking预测结果重新排序及生成提交结果
rank_results = finall_tst_ranker_feats[['user_id', 'click_article_id', 'pred_score']]
submit(rank_results, topk=5, model_name='ensumble_staking')
比赛源自:阿里云天池大赛 - 零基础入门推荐系统 - 新闻推荐