多模态机器翻译 | (1) 简介
摘录自 机器翻译 基础与模型 东北大学
1. 背景
基于上下文的翻译是机器翻译的一个重要分支。传统方法中,机器翻译通常被 定义为对一个句子进行翻译的任务。但是,现实中每句话往往不是独立出现的。比 如,人们会使用语音进行表达,或者通过图片来传递信息,这些语音和图片内容都 可以伴随着文字一起出现在翻译场景中。此外,句子往往存在于段落或者篇章之中, 如果要理解这个句子,也需要整个段落或者篇章的信息,而这些上下文信息都是机 器翻译可以利用的。
本节在句子级翻译的基础上将问题扩展为更大的上下文中的翻译,具体包括语音翻译、图像翻译、篇章翻译三个主题。这些问题均为机器翻译应用中的真实需求。 同时,使用多模态等信息也是当下自然语言处理的热点研究方向之一。(本博客重点关注图像翻译,语音翻译和篇章翻译请参见原书。)
2. 机器翻译需要更多的上下文
长期以来,机器翻译都是指句子级翻译。主要原因在于,句子级的翻译建模可 以大大简化问题,使得机器翻译方法更容易被实践和验证。但是人类使用语言的过 程并不是孤立地在一个个句子上进行的。这个问题可以类比于人类学习语言的过程: 小孩成长过程中会接受视觉、听觉、触觉等多种信号,这些信号的共同作用使得他 们产生对客观世界的“认识”,同时促使他们使用“语言”进行表达。从这个角度说, 语言能力并不是由单一因素形成的,它往往伴随着其他信息的相互作用,比如,当 人们翻译一句话的时候,会用到看到的画面、听到的语调、甚至前面说过的句子中 的信息。
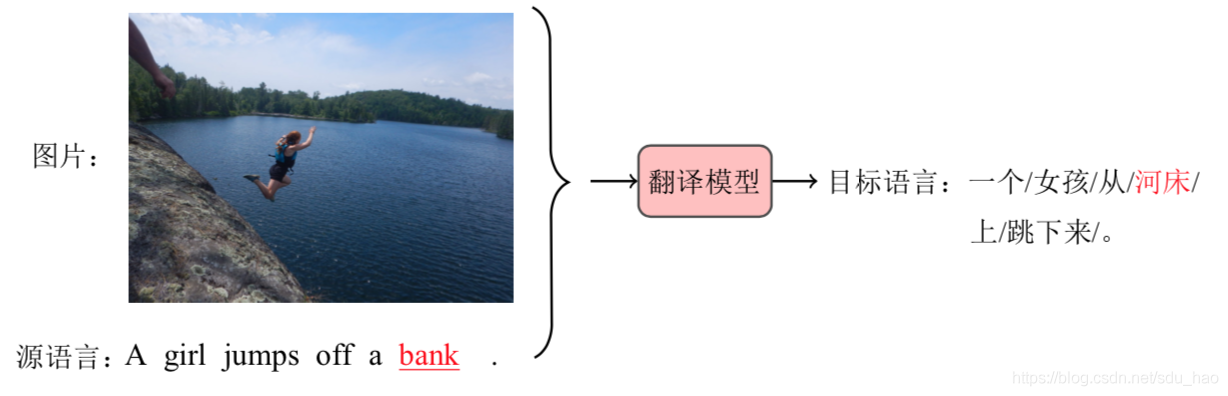
广义上,当前句子以外的信息都可以被看作一种上下文。比如,下图中,需要 把英语句子“A girl jumps off a bank .”翻译为汉语。但是,其中的“bank”有多个含 义,因此仅仅使用英语句子本身的信息可能会将其翻译为“银行”,而非正确的译文“河床”。但是,图17.1中也提供了这个英语句子所对应的图片,显然图片中直接展示 了河床,这时“bank”是没有歧义的。通常也会把这种使用图片和文字一起进行机器翻译的任务称作多模态机器翻译(Multi-Modal Machine Translation)。
模态(Modality)是指某一种信息来源。例如,视觉、听觉、嗅觉、味觉都可以被 看作是不同的模态。因此视频、语音、文字等都可以被看作是承载这些模态的媒介。 在机器翻译中使用多模态这个概念,是为了区分某些不同于文字的信息。除了图像 等视觉模态信息,机器翻译也可以利用听觉模态信息。比如,直接对语音进行翻译, 甚至直接用语音表达出翻译结果。
除了不同信息源所引入的上下文,机器翻译也可以利用文字本身的上下文。比 如,翻译一篇文章中的某个句子时,可以根据整个篇章的内容进行翻译。显然这种 篇章的语境是有助于机器翻译的。在本章接下来的内容中,会对机器翻译中使用不同上下文(多模态和篇章信息)的方法展开讨论。
3. 图像翻译
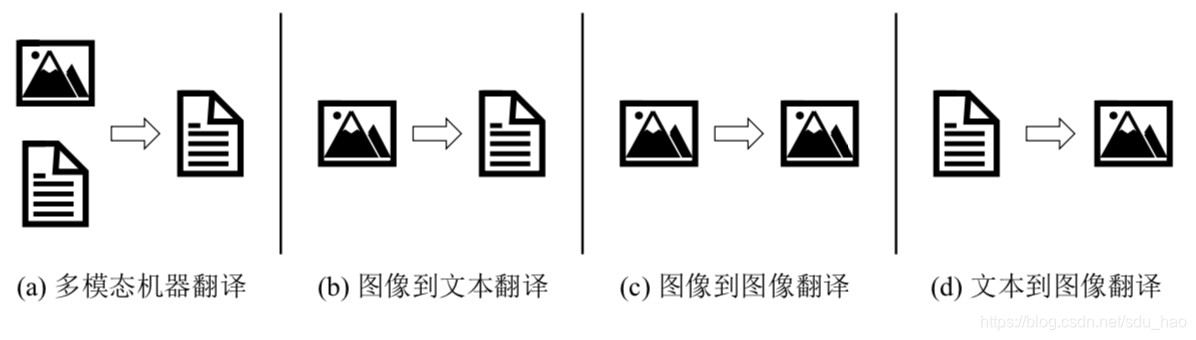
在人类所接受的信息中,视觉信息的比重往往不亚于语音和文本信息,甚至更 多。视觉信息通常以图像的形式存在,近几年,结合图像的多模态机器翻译受到了 广泛的关注。多模态机器翻译(下图 (a))简单来说就是结合源语言和其他模态(例如图像等)的信息生成目标语言的过程。这种结合图像的机器翻译还是一种狭义上的“翻译”,它本质上还是从源语言到目标语言或者说从文本到文本的翻译。事实上从图像到文本(下图(b))的转换,即给定图像,生成与图像内容相关的描述, 也可以被称为广义上的“翻译”。例如,图片描述生成(Image Captioning)就是一种 典型的图像到文本的翻译。当然,这种广义上的翻译形式不仅仅包括图像到文本的转换,还可以包括从图像到图像的转换(图©),甚至是从文本到图像的转换(下图(d))等等。这里将这些与图像相关的翻译任务统称为图像翻译。
本博客重点关注多模态机器翻译,即基于图像增强的文本翻译,其他有关图像翻译的内容参见原书。
4. 基于图像增强的文本翻译
在文本翻译中引入图像信息是最典型的多模态机器翻译任务。虽然多模态机器 翻译还是一种从源语言文本到目标语言文本的转换,但是在转换的过程中,融入了 其他模态的信息减少了歧义的产生。例如前文提到的通过与源语言相关的图像信息, 将“A girl jumps off a bank .”中“bank”翻译为“河岸”而不是“银行”,因为图像 中出现了河岸,因此“bank”的歧义大大降低。换句话说,对于同一图像或者视觉场 景的描述,源语言和目标语言描述的信息是一致的,只不过,体现在不同语言上会 有表达方法上的差异。那么,图像就会存在一些源语言和目标语言的隐含对齐“约 束”,而这种“约束”可以捕捉语言中不易表达的隐含信息。
如何融入视觉信息,更好的理解多模态上下文语义是多模态机器翻译研究的重点[1-3], 主要方向包括基于特征融合的方法[4-6] 和基于联合模型的方法[7,8]。
4.1 基于特征融合的方法
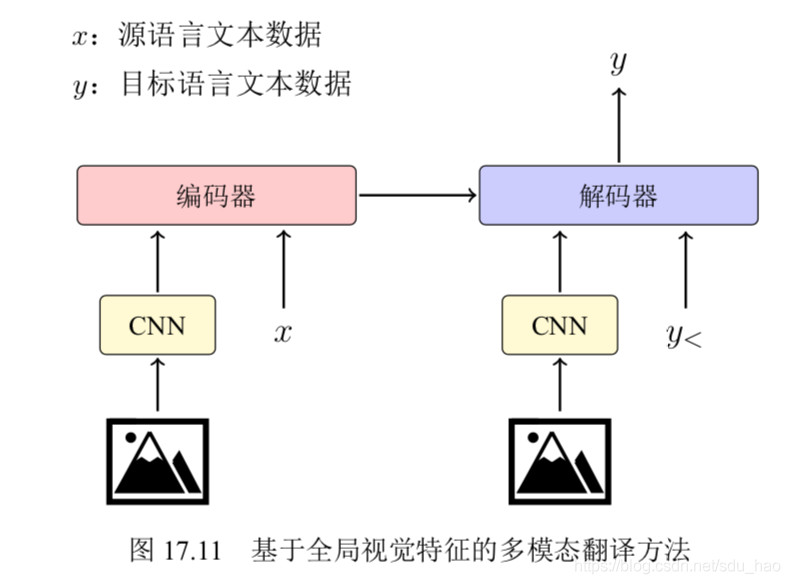
早期,通常将图像信息作为输入句子的一部分[4,9], 或者用其对编码器、解码器的状态进行初始化[4,10,11]. 如下图所示,图中 y< 表示当前时刻之前的单词 序列,对图像特征的提取通常是基于卷积神经网络。通过卷积神经网络得到全局图像特征,在进行维度变换后,将其作为源语言输入的一部分或者初始化状态引入到模型当中。但是,这种图像信息的引入方式有以下两个缺点:
1)图像信息不全都是有用的,往往存在一些与源语言或目标语言无关的信息,作 为全局特征会引入噪音。
2)图像信息作为源语言的一部分或者初始化状态,间接地参与了译文的生成,在神经网络的计算过程中,图像信息会有一定的损失。
说到噪音问题就不得不提到注意力机制的引入,前面章节中提到过这样的一个例子:
中午/没/吃饭/,/又/刚/打/了/ 一/下午/篮球/,/我/现在/很/饿/ ,/我/想 ___ 。
想在横线处填写“吃饭”,“吃东西”的原因是在读句子的过程中,关注到了 “没/吃饭”,“很/饿”等关键息。这是在语言生成中注意力机制所解决的问题,即对 于要生成的目标语言单词,相关性更高的语言片段应该更加“重要”,而不是将所有 单词一视同仁。同样的,注意力机制也应用在多模态机器翻译中,即在生成目标单 词时,更应该关注与目标单词相关的图像部分,而弱化对其他部分的关注。另外,注意力机制的引入,也使图像信息更加直接地参与目标语言的生成,解决了在不使用注意力机制的方法中图像信息传递损失的问题。

那么,多模态机器翻译是如何计算上下文向量的呢? 假设编码器输出的状态序列为 {
h
1
,
.
.
.
,
h
m
h_1,...,h_m
h1,...,hm},需要注意的是,这里的状态序列不是源语言句子的状态序列,而是通过基于卷积等操作提取到的图像的状态序列。 假设图像的特征维度是 16 × 16 × 512,其中前两个维度分别表示图像的高和宽,这里会将图像映射为 256 × 512 的状态序列,其中 512 为每个状态的维度。对于目标语言位置 j,上下文向量
C
j
C_j
Cj被定义为对序列的编码器输出进行加权求和,如下:
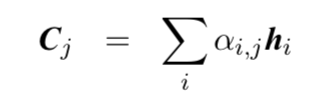
其中,
α
i
,
j
\alpha_{i,j}
αi,j是注意力权重,它表示目标语言第 j 个位置与图片编码状态序列第 i 个位置(状态)的相关性大小。
这里,将 h i h_i hi看作图像表示序列位置 i 上的表示结果。上图给出了模型在生成目标词"bank"时,图像经过注意力机制对图像区域关注度的可视化效果。可以看到,经过注意力机制后,模型更关注与目标词相关的图像部分。当然,多模态机器翻译的输入还包括源语言文字序列。通常,源语言文字对于翻译的作用比图像更大[12] 。从这个角度说,在当下的多模态翻译任务中,图像信息更多的是作为文字信息的补充,而不是替代。除此之外,注意力机制在多模态机器翻译中也有很多研究,比如,在编码器端将源语言文本与图像信息进行注意力建模,得到更好的源语言的表示结果[5, 12]。
4.2 基于联合模型的方法
基于联合模型的方法通常是把翻译任务与其他视觉任务结合,进行联合训练。这 种方法也可以被看做是一种多任务学习,只不过这里仅关注翻译和视觉任务。一种 常见的方法是共享模型的部分参数来学习不同任务之间相似的部分,并通过特定的 模块来学习每个任务特有的部分。
如下图所示,图中 y< 表示当前时刻之前的单词序列,可以将多模态机器翻译任务分解为两个子任务:机器翻译和图片生成[7] 。其中机器翻译作为主任务,图片生成作为子任务。这里的图片生成指的是从一个图片描述生成对应图片,对于图片生成任务原书有详细描述。通过单个编码器对源语言数据进行建模,然后通过两个解码器(翻译解码器和图像解码器)来分别学习翻译任务和图像生成任务。顶层学习每个任务的独立特征,底层共享参数能够学习到更丰富的文本表示。
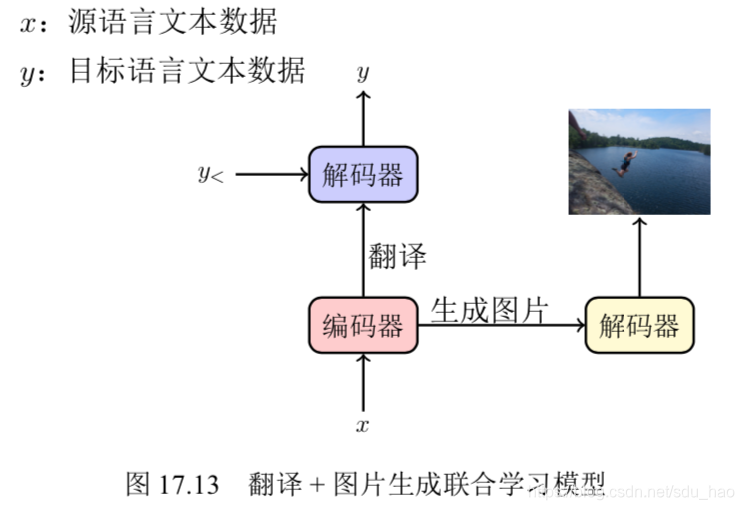
另外在视觉问答领域有研究表明,在多模态任务中,不宜引入过多层的注意力机制,因为过深的模型会导致多模态模型的过拟合[13] 。这一方面是由于深层模型本身对数据的拟合能力较强,另一方面也是由于多模态任务的数据普遍较少,容易造成复杂模型的过拟合。从另一角度来说,利用多任务学习的方式,提高模型的泛化能力,也是一种有效防止过拟合现象的方式。类似的思想,也大量使用在多模态自然语言处理任务中,例如图像描述生成、视觉问答等[14] 。
5. 参考文献
[1] Lucia Specia, Stella Frank, Khalil Sima’an, and Desmond Elliott. “A Shared Task on Multimodal Machine Translation and Crosslingual Image Description”. In: Annual Meeting of the Association for Computational Linguistics, 2016, pages 543– 553 (cited on page 563).
[2] Ozan Caglayan, Walid Aransa, Adrien Bardet, Mercedes Garcı́a-Martı́nez, Fethi Bougares, Loı̈c Barrault, Marc Masana, Luis Herranz, and Joost van de Weijer. “LIUM-CVC Submissions for WMT17 Multimodal Translation Task”. In: Annual Meeting of the Association for Computational Linguistics, 2017, pages 432–439 (cited on page 563).
[3] Jindrich Libovický, Jindrich Helcl, Marek Tlustý, Ondrej Bojar, and Pavel Pecina. “CUNI System for WMT16 Automatic Post-Editing and Multimodal Translation Tasks”. In: Annual Meeting of the Association for Computational Linguistics, 2016, pages 646–654 (cited on page 563).
[4] Iacer Calixto and Qun Liu. “Incorporating Global Visual Features into Attention- based Neural Machine Translation”. In: Conference on Empirical Methods in Natural Language Processing, 2017, pages 992–1003 (cited on page 563).
[5] Jean-Benoit Delbrouck and Stéphane Dupont. “Modulating and attending the source image during encoding improves Multimodal Translation”. In: Conference and Workshop on Neural Information Processing Systems, 2017 (cited on pages 563, 565).
[6] Jindrich Helcl, Jindrich Libovický, and Dusan Varis. “CUNI System for the WMT18 Multimodal Translation Task”. In: Annual Meeting of the Association for Computational Linguistics, 2018, pages 616–623 (cited on page 563).
[7] Desmond Elliott and Ákos Kádár. “Imagination Improves Multimodal Translation”. In: International Joint Conference on Natural Language Processing, 2017, pages 130–141 (cited on pages 563, 565).
[8] Yongjing Yin, Fandong Meng, Jinsong Su, Chulun Zhou, Zhengyuan Yang, Jie Zhou, and Jiebo Luo. “A Novel Graph-based Multi-modal Fusion Encoder for Neural Machine Translation”. In: Annual Meeting of the Association for Computational Linguistics, 2020, pages 3025–3035 (cited on page 563).
[9] Yuting Zhao, Mamoru Komachi, Tomoyuki Kajiwara, and Chenhui Chu. “Double Attention-based Multimodal Neural Machine Translation with Semantic Image Re- gions”. In: Annual Conference of the European Association for Machine Transla- tion, 2020, pages 105–114 (cited on page 563).
[10] Desmond Elliott, Stella Frank, and Eva Hasler. “Multi-Language Image Descrip- tion with Neural Sequence Models”. In: CoRR abs/1510.04709 (2015) (cited on page 563).
[11] Pranava Swaroop Madhyastha, Josiah Wang, and Lucia Specia. “Sheffield Mul- tiMT: Using Object Posterior Predictions for Multimodal Machine Translation”. In: Annual Meeting of the Association for Computational Linguistics, 2017, pages 470– 476 (cited on page 563).
[12] Shaowei Yao and Xiaojun Wan. “Multimodal Transformer for Multimodal Machine Translation”. In: Annual Meeting of the Association for Computational Lin- guistics, 2020, pages 4346–4350 (cited on page 565).
[13] Jiasen Lu, Jianwei Yang, Dhruv Batra, and Devi Parikh. “Hierarchical Question- Image Co-Attention for Visual Question Answering”. In: Conference on Neural Information Processing Systems, 2016, pages 289–297 (cited on page 565).
[14] Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C.Lawrence Zitnick, and Devi Parikh. “VQA: Visual Question Answering”. In: International Conference on Computer Vision, 2015, pages 2425–2433 (cited on page 565).