【论文解析】从头开始打造Transformer
在谷歌大作Attention is all you need中提出了一种基于seq2seq架构的self-attention特征抽取机制,兼具CNN的并行化优点和RNN的长距离依赖特点,成为后续以MLM为主要任务的Bert、Roberta、albert预训练模型(利用Transformer中的Encode block)以及以AR-ML为主要任务GPT系列模型(利用Transformer中的Decode block)的主要模块,并在各类任务上取得了前所未有的成功。
本博客在Transformer浅析一文中已经简要介绍了该模型的特点和细节,本文参照The Annotated Transformer),进行了代码实现。
为方便代码对照,先po一张Trnasfomer的结构图:
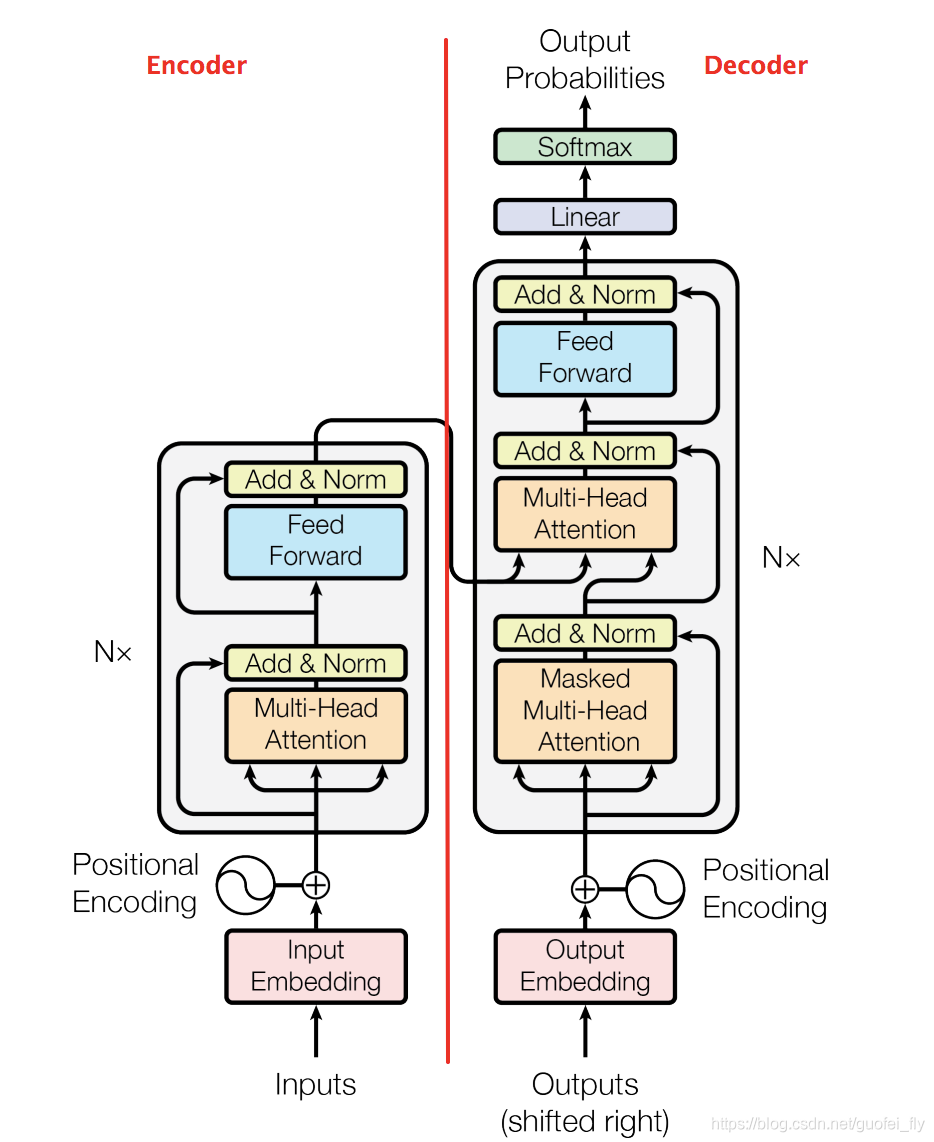
再以树形图的形式,自上而下给出各模块的组织关系:
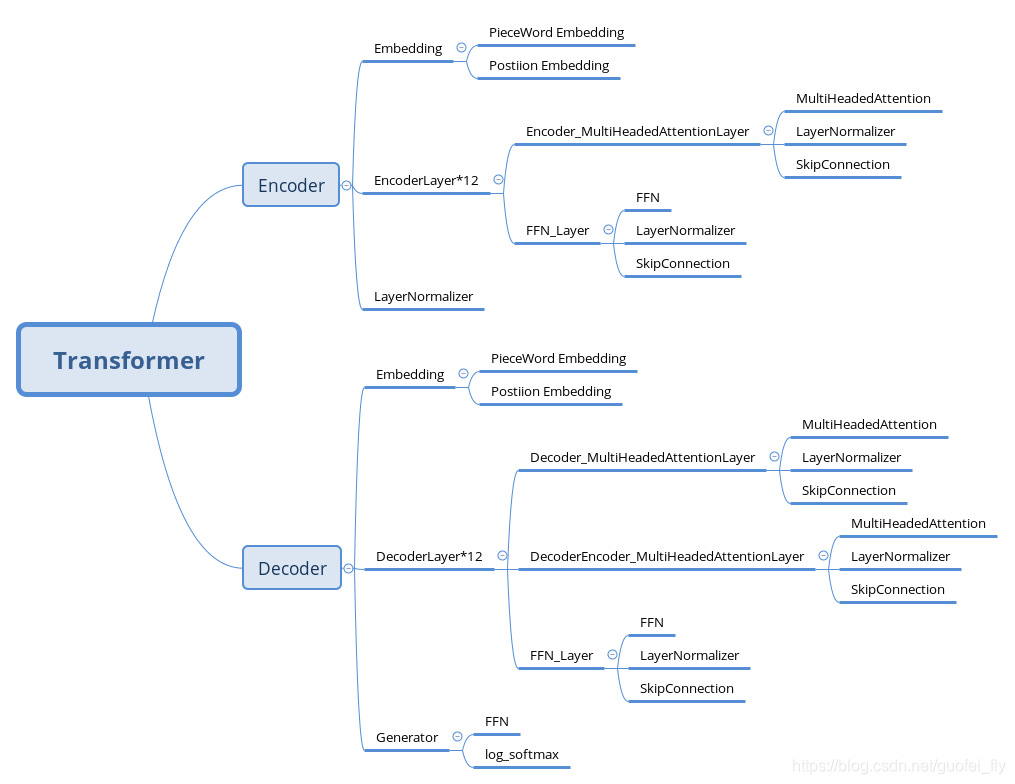
不难发现,其中PieceWord Embedding、Postion Embedding、MultiHeadAttention、FFN、LayNorm、SkipConnection等均是可复用的block,因此按照搭积木的原则,自下往上给出如下的代码实现:
import math
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from copy import deepcopy
def clones(module, N):
"""
重复单元的堆叠
:param module: 模型layer
:param N: 堆叠数
:return:
"""
return nn.ModuleList([deepcopy(module) for _ in range(N)])
class Embedding(nn.Module):
"""
Word-Embedding层
在原始Transformer中,source-embedding、target-embedding,以及decoder-embedding三者是共享的
在获得look-up table中的词向量后,需要乘以sqrt(model_d)
"""
def __init__(self, vocab, d_model):
super(Embedding, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * torch.sqrt(self.d_model)
class PositionalEncoding(nn.Module):
"""
Position Embedding, 这里采用正/余弦定义的方式
PE(pos,2i) = sin(pos/10000^(2i/d_model)), PE(pos,2i+1) = cos(pos/10000^(2i/d_model))
常见的定义方式包括:
(1)static方式,预先定义好,长度有上限
(2)static方式,公式定义,可不限制长度
(3)dynamic方式,可learn的参数
"""
def __init__(self, d_model, dropout, max_length=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_length, d_model, dtype=torch.float32)
position = torch.arange(0, max_length, dtype=torch.float32).unsqueeze(-1)
div_term = torch.exp(-torch.arange(0, d_model, 2, dtype=torch.float32)*(math.log(10000.0)/d_model)) # exp(log(x^y))=exp(y*log(x)), 注意顺序
pe[:, 0::2] = torch.sin(torch.mul(position, div_term))
pe[:, 1::2] = torch.cos(torch.mul(position, div_term))
pe.unsqueeze_(0) # 在batch维度上拓展
self.register_buffer('pe', pe) # static,加入缓存
def forward(self, x):
x = x + nn.Parameter(self.pe[:, :x.size(1)], requires_grad=False)
return self.dropout(x)
class MultiHeadedAttention(nn.Module):
"""
Transformer中的多头注意力机制,用于三个地方:
(1)Encoder中的self-attention
(2)Decoder中的sequence attention
(3) Decoder中的target-source attention
@:param d_model: word-embedding的维度,也是整个Encoder-Decoder内部各元素的维度
@:param h: Head数
@:param dropout: dropout参数
"""
def __init__(self, d_model, h, dropout=0.1):
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0 # d_model必须被h整除
self.h = h
self.d_k = d_model // h # 本质上query和key的维度必须一致,遵循原始Transformer的做法,K、Q、V的维度均取一致
self.linears = clones(nn.Linear(d_model, d_model), 4) # 分别为K、Q、V、O,这里将各Head的K、Q、V进行了维度组合
self.attn = None # attention scores, 可用于可视化
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"""
包括如下流程:
(1)利用FC计算Q、K、V
(2)利用张量运算得到Attention结果
(3)经过O得到最终输出结果
:param query: query tensor (Batch, Sequence, d_model)
:param key: key tensor (Batch, Sequence, d_model)
:param value: value tensor (Batch, Sequence, d_model)
:param mask: mask tensor (Batch, Sequence, Sequence)
:return:
"""
if mask is not None:
mask = mask.unsqueeze(1) # (Batch, 1, Sequence, Sequence), 扩展的维度为Head,以便做张量计算
batch = query.size(0) # Batch维度
# (1) 求Q、K、V张量
# 注意维度转换:(Batch, Sequence, d_model)——> (Batch, Sequence, Head, d_k)——>(Batch, Head, Sequence, d_k)
Q, K, V = [fc(x).view(batch, -1, self.h, self.d_k).transpose(1, 2) for x, fc in zip((query, key, value), self.linears)]
# (2) 求Scaled Dot Product Attention
x, self.attn = self._attention(Q, K, V, mask, self.dropout)
# (3) 输出结果
# 注意维度转换:(Batch, Head, Sequence, d_k)——>(Batch, Sequence, Head, d_k)——>(Batch, Sequence, d_model)
x = x.transpose(1, 2).contiguous().view(batch, -1, self.h*self.d_k)
return self.linears[-1](x) # 乘以O, (Batch, Sequence, d_model)
@staticmethod
def _attention(query, key, value, mask, dropout):
"""
采用矩阵计算的方式计算Scaled Dot Product Attention: Concat<(Q^T*V/sqrt(d_k))V> * O, 其中Q为query,K为key,V为Value,O为Output
@:param query: query tensor(Batch, Head, Sequence, d_k)
@:param key: key tensor(Batch, Head, Sequence, d_k)
@:param value: value tensor(Batch, Head, Sequence, d_k)
@:param mask: mask tensor(Batch, 1, Sequence, Sequence)
@:param dropout: nn.Dropout()
:return:
"""
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-1, -2))/math.sqrt(d_k) # (Batch, Head, Sequence, Sequence)
if mask is not None:
scores = torch.masked_fill(scores, mask==0, -np.inf)
p_attn = F.softmax(scores, dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
class PositionwiseFeedForward(nn.Module):
"""
Encoder和Decoder中的FFN网络
中间通过RELU激活(BERT中改为GELU)
"""
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(p=dropout)
def forward(self, x):
return self.fc2(self.dropout(F.relu(self.fc1(x))))
class LayerNorm(nn.Module):
"""
LayerNorm层,其仅作用于每个sample的最后一个维度
"""
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.gamma = nn.Parameter(torch.ones(features), requires_grad=True)
self.beta = nn.Parameter(torch.ones(features), requires_grad=True)
self.eps = eps
def forward(self, x):
mean = torch.mean(x, dim=-1, keepdim=True)
std = torch.std(x, dim=-1, keepdim=True)
return self.beta * (x - mean)/(std+self.eps) + self.gamma
class SublayerConnection(nn.Module):
"""
网络中SkipConnection,其用于Encoder和Decoder中的各个层次
x = x + Sublayer(LayerNorm(x))
"""
def __init__(self, size, dropout=0.1):
super(SublayerConnection, self).__init__()
self.ln = LayerNorm(size)
self.dropout = nn.Dropout(p=dropout)
def forward(self, sublayer, x):
return x + self.dropout(sublayer(self.ln(x)))
class EncoderLayer(nn.Module):
"""
Encoder中的基本模块,包含:
(1)Self MultiHeadedAttention+SkipConnection
(2) FFN+SkipConnection
size: d_model
self_attn: MultiHeadedAttention()
feed_forward: PositionwiseFeedForward()
"""
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.shortcuts = clones(SublayerConnection(size, dropout), 2)
self.size = size # 在Encoder中调用
def forward(self, x, mask):
x = self.shortcuts[0](lambda x: self.self_attn(x, x, x, mask), x)
return self.shortcuts[1](self.feed_forward, x)
class Encoder(nn.Module):
"""
Encoder模块,包括stack的EncoderLayer以及作用再最后一层之上的LayerNormal
@:param layer: EncoderLayer()
@:param N: layer的层数
"""
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.ln = LayerNorm(layer.size)
def forward(self, x, mask):
for layer in self.layers:
x = layer(x, mask)
return self.ln(x)
class DecoderLayer(nn.Module):
"""
Decoder中的基本模块,包含:
(1)Self MultiHeadedAttention+SkipConnection
(2) Decoder-Encoder MultiHeadedAttention+SkipConnection
(2) FFN+SkipConnection
size: d_model
self_attn: MultiHeadedAttention()
src_attn: MultiHeadedAttention()
feed_forward: PositionwiseFeedForward()
memory: Encoder模块的输出结果
src_mask: Encoder中的mask tensor
tgt_mask: Decoder中的sequence mask tensor
"""
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.shortcuts = clones(SublayerConnection(size, dropout), 3)
self.size = size # 在Encoder中调用
def forward(self, x, memory, src_mask, tgt_mask):
x = self.shortcuts[0](lambda x: self.self_attn(x, x, x, tgt_mask), x)
x = self.shortcuts[1](lambda x: self.src_attn(x, memory, memory, src_mask), x)
return self.shortcuts[2](self.feed_forward, x)
class Decoder(nn.Module):
"""
Decoder模块,包括stack的DecoderLayer以及作用再最后一层之上的LayerNormal
@:param layer: EncoderLayer()
@:param N: layer的层数
"""
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.ln = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.ln(x)
class Generator(nn.Module):
"""
Decoder层后的映射层,将d_model映射为lookupTable
"""
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return F.log_softmax(self.proj(x), dim=-1) # 取log结果,可直接用于KLDivloss
class Transformer(nn.Module):
"""
Encoder和Decoder的完整组合包括:Embedding、Encoder、Decoder、Projection
@:param src_embed Encoder中的Embedding
@:param tgt_embed Decoder中的Embedding
@:param encoder Encoder()
@:param decoder Decoder()
@:param generator Decoder后的投影层
"""
def __init__(self, src_embed, tgt_embed, encoder, decoder, generator):
super(Transformer, self).__init__()
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.encoder = encoder
self.decoder = decoder
self.generator = generator
def forward(self, src, tgt, src_mask, tgt_mask):
return self.generator(self.decode(self.encode(src, src_mask), tgt, src_mask, tgt_mask)) # Encoder层输出结果 (Batch, Sequence, tgt_vocab)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask) # Encoder层输出结果 (Batch, Sequence, Embedding)
def decode(self, memory, tgt, src_mask, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask) # Decoder层输出结果 (Batch, Sequence, Embedding)
def make_model(src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1):
"""
构造Transformer的接口
:return:
"""
attn = MultiHeadedAttention(d_model, h, dropout)
ffn = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
model = Transformer(
nn.Sequential(nn.Embedding(src_vocab, d_model), deepcopy(position)),
nn.Sequential(nn.Embedding(tgt_vocab, d_model), deepcopy(position)),
Encoder(EncoderLayer(d_model, deepcopy(attn), deepcopy(ffn), dropout), N),
Decoder(DecoderLayer(d_model, deepcopy(attn), deepcopy(attn), deepcopy(ffn), dropout), N),
Generator(d_model, tgt_vocab)
)
# 权重的初始化
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_normal_(p)
return model
【Reference】