RedisBloom 插件布隆过滤器,布谷鸟过滤器,Count-Min Sketch,TOPK使用详解
文章目录
前言
RedisBloom 是一款由 RedisLabs 提供的 redis 插件,提供了布隆过滤器、布谷鸟过滤器、Count-Min Sketch、TopK功能实现。通过 BitMap 这样的数据结构,以牺牲部分精度换取更高的内存效率和读写效率,适用于海量数据场景。该博客以下将对 RedisBloom 各个功能以及命令做详解。首先,先简单介绍这些功能的作用:布隆过滤器和布谷鸟过滤器主要用于判断海量元素是否存在的情况,通常可用于防止缓存击穿导致的雪崩问题;Count-Min Sketch 主要用于元素的使用计数,可用于 ip 限流,元素流量查询等场景;TopK 可以帮助我们对元素进行计数,与 Count-Min Sketch 相比,它提供了在O(n)复杂度下查询排名前 n 个元素的命令,可用于海量元素的排名(但在实际测试中,并不能达到预计效果)。以下内容均基于 RedisBloom 2.1.0 版本。一、如何安装
这里仅介绍 docker 下的安装步骤,同样的分享了官网的安装介绍。
docker run -p 6379:6379 --name redis-redisbloom redislabs/rebloom:latest
官网各环节安装介绍:地址
二、布隆过滤器
1. 使用介绍
该模块主要用于判断某个元素是否存在,利用 BitMap 这样的数据结构,在牺牲可接受范围的精度下极大提高了内存使用率和性能,查询复杂度约为 O(hash fun number),和 redis 原有的 set 结构(非 zip set int)相比,内存仅占用其 1/10 甚至不到。以下为 redis 中和 set 的测试内存结果对比:
测试元素 100w ,元素大小 32 个字节
# 布隆过滤器
# Memory
used_memory:4714576
used_memory_human:4.50M
# set
# Memory
used_memory:73434368
used_memory_human:70.03M
根据以上结果,似乎布隆过滤器十分优秀,但由于原理的限制,布隆过滤器无法进行元素删除。
布隆过滤器原理:引用文章地址
2. 命令详解
BF.RESERVE {key} {error_rate} {capacity} [EXPANSION {expansion}] [NONSCALING]
命令用于创建自定义布隆过滤器,时间复杂度:O(1)。其中参数介绍如下:
- key:布隆过滤器的键。
- error_rate:错误率,例如:0.01,则代表在 100 个数据中允许存在 1 个误判。
- capacity:容量,该参数和 EXPANSION 、NONSCALING 参数相关联。
- EXPANSION:当容量不足时,扩容的倍率(这里的扩容用词不准,实际上是建立了子过滤器进行实现,根据这个原理,需要注意的是当子过滤器过多时,会成倍数的影响性能),不填默认为 1。例如:1,则当容量 100 满时,自动扩容为 100 + 100。
- NONSCALING:当容量不足时,返回一个异常,禁止写入。
BF.ADD {key} {item}
命令用于向布隆过滤器中添加元素。时间复杂度:O(hash fun number)。其中参数介绍如下:
- key:布隆过滤器的键,当键不存在时创建一个容量为 100 的默认过滤器。
- item:写入的元素。
BF.MADD {key} {item ...}
命令用于向布隆过滤器中批量添加元素。时间复杂度:O(n * hash fun number)。其中参数介绍如下:
- key:布隆过滤器的键,当键不存在时创建一个容量为 100 的默认过滤器。
- item:写入的元素集合。
BF.INSERT {key} [CAPACITY {cap}] [ERROR {error}] [EXPANSION {expansion}] [NOCREATE]
[NONSCALING] ITEMS {item ...}
命令为 BF.RESERVE 和 BF.MADD 的混合命令,时间复杂度:O(n * hash fun number)。其中参数介绍如下:
- key:布隆过滤器的键。
- ERROR:错误率,例如:0.01,则代表在 100 个数据中允许存在 1 个误判。
- CAPACITY:容量,该参数和 EXPANSION 、NONSCALING 参数相关联。
- EXPANSION:当容量不足时,扩容的倍率(这里的扩容用词不准,实际上是建立了子过滤器进行实现,根据这个原理,需要注意的是当子过滤器过多时,会成倍数的影响性能),不填默认为 1。例如:1,则当容量 100 满时,自动扩容为 100 + 100。
- NONSCALING:当容量不足时,返回一个异常,禁止写入。
- NOCREATE:当容器不存在时不进行创建,返回一个异常,禁止插入。
- item:写入的元素集合。
BF.EXISTS {key} {item}
命令用于判断某个元素是否存在于过滤器中,时间复杂度:O(hash fun number * 子过滤器数),其中参数介绍如下:
- key:布隆过滤器的键。
- item:判断是否存在的元素。
BF.MEXISTS {key} {item ...}
命令用于批量判断某个元素是否存在于过滤器中,时间复杂度:O(n * hash fun number * 子过滤器数),其中参数介绍如下:
- key:布隆过滤器的键。
- item:判断是否存在的元素集合。
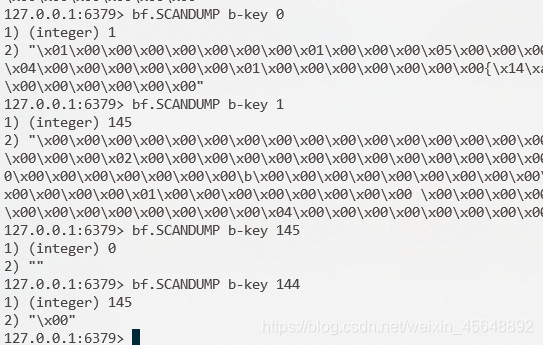
BF.SCANDUMP {key} {iter}
命令用于将一个布隆过滤器以分片的方式读出,返回两个子段分别为分片总数和分片字节,当返回分配总数为 0,且字节为空时代表读取结束,时间复杂度:O(n),其中参数介绍如下:
- key:布隆过滤的键。
- iter:返回的分片下标,首个下标从 0 开始。
BF.LOADCHUNK {key} {iter} {data}
命令用于将一个布隆过滤器以分片的方式写入,存在则覆盖。时间复杂度:O(n),其中参数介绍如下:
- key:布隆过滤器的键。
- iter:返回的分片下标,首个下标从 0 开始。
- data:写入的字节。
BF.INFO {key}
命令用于查看布隆过滤器详情,时间复杂度:O(1),其中参数介绍如下:
- key:布隆过滤器的键。
三、布谷鸟过滤器
1. 使用介绍
该模块主要用于判断某个元素是否存在,相比于布隆过滤器,布谷鸟过滤器支持数据删除,同时由于布谷鸟算法,其占用内存在理论情况下比布隆过滤器更小,查询复杂度约为 O(2),以下为 redis 中和 set 的测试内存结果对比:
测试元素 100w ,元素大小 32 个字节
# 布谷鸟过滤器
# Memory
used_memory:2114792
used_memory_human:2.02M
# set
# Memory
used_memory:73434368
used_memory_human:70.03M
根据以上结果,看上去似乎布谷鸟过滤器在查询和内存的使用效率上会高于布隆过滤器,但在实际情况中为了减少互踢问题,需要扩容,实际使用内存甚至会高于布隆过滤器,同样,由于互踢问题的存在,在实际的写入效率上也比布隆过滤器要差一些。但在实际使用场景中,常常存在需要进行数据擦除的情况,相比于布隆过滤器,布谷鸟过滤器在不是极端的使用场景则更为灵活。
布谷鸟过滤原理:引用文章地址
2. 命令详解
CF.RESERVE {key} {capacity} [BUCKETSIZE {bucketsize}] [MAXITERATIONS {maxiterations}]
[EXPANSION {expansion}]
命令用于创建布谷鸟过滤器,时间复杂度:O(1),其中参数介绍如下:
- key:布谷鸟过滤器的键。
- capacity:布谷鸟过滤器的容量。根据布谷鸟过滤器原理,写入时则可能未满,但由于互踢而被判定为满,需要扩容,故设置时,如果不考虑子过滤器扩容,则需要预设多于实际使用容量的 30%。
- bucketsize:存储桶中的元素数,相比于原始的布谷鸟算法,redisbloom 中引入了存储桶的改进方式,以降低互踢次数,提高内存使用效率,但同时也会导致误判提高和写入性能的下降的问题(由于桶的存在,互踢需要将数组桶的内容交换,故性能下降),默认值为 2。
- maxiterations:最大互踢次数。
- EXPANSION:当容量不足时,扩容的倍率(这里的扩容用词不准,实际上是建立了子过滤器进行实现,根据这个原理,需要注意的是当子过滤器过多时,会成倍数的影响性能),不填默认为 1。例如:1,则当容量 100 满时,自动扩容为 100 + 100。
CF.ADD {key} {item}
命令用于布谷鸟过滤器中添加元素。时间复杂度:O(sub filter number + maxiterations)。其中参数介绍如下:
- key:布谷鸟过滤器的键,当键不存在时创建一个容量为 1080 的默认过滤器。
- item:写入的元素。
CF.ADDNX {key} {item}
命令用于布谷鸟过滤器中添加元素,当元素不存在时则插入,之所以需要提供这样的命令,源于布谷鸟的占位踢出算法,如果连续的插入相同的元素,则会导致内存使用率降低,同时会导致删除后数据依然存在,故写入前应当判断元素是否存在。时间复杂度:O(sub filter number + maxiterations)。其中参数介绍如下:
- key:布谷鸟过滤器的键,当键不存在时创建一个容量为 1080 的默认过滤器。
- item:写入的元素。
CF.INSERT {key} [CAPACITY {capacity}] [NOCREATE] ITEMS {item ...}
CF.INSERTNX {key} [CAPACITY {capacity}] [NOCREATE] ITEMS {item ...}
这两个命令为 CF.RESERVE 和 CF.ADD,CF.ADDNX 的复合体,这里不在重复介绍。
CF.EXISTS {key} {item}
命令用于布谷鸟过滤器中判断元素是否存在,时间复杂度:O(sub filter number)。其中参数介绍如下:
- key:布谷鸟过滤器的键。
- item:要判断的元素。
CF.DEL {key} {item}
命令用于布谷鸟过滤器中删除元素,这里需要注意的是,如果同一个元素添加多次,则同样需要删除多次,时间复杂度:O(sub filter number)。其中参数介绍如下:
- key:布谷鸟过滤器的键。
- item:移除的元素。
CF.COUNT {key} {item}
命令用于布谷鸟过滤器中查询元素存在的数量,这里需要注意的是返回的不是一个准确值,时间复杂度:O(sub filter number)。其中参数介绍如下:
- key:布谷鸟过滤器的键。
- item:查询数量元素。
CF.SCANDUMP {key} {iter}
命令用于将一个布谷鸟过滤器以分片的方式读出,返回两个子段分别为分片总数和分片字节,当返回分配总数为 0,且字节为空时代表读取结束,时间复杂度:O(n),其中参数介绍如下:
- key:布谷鸟的键。
- iter:返回的分片下标,首个下标从 0 开始。
CF.LOADCHUNK {key} {iter} {data}
命令用于将一个布谷鸟过滤器以分片的方式写入,存在则覆盖。时间复杂度:O(n),其中参数介绍如下:
- key:布谷鸟过滤器的键。
- iter:返回的分片下标,首个下标从 0 开始。
- data:写入的字节。
CF.INFO {key}
命令用于查看布谷鸟过滤器详情,时间复杂度:O(1),其中参数介绍如下:
- key:布谷鸟过滤器的键。
三、Count-Min Sketch
1. 使用介绍
该模块主要用于元素的计数统计,属于布隆过滤器的变种,利用 int 数组桶这样的数据结构降低内存使用,提高查询效率。但同样的,由于移除了 key 的存储并限制了哈希冲突数量,当超出哈希冲突限制数时,则会导致误判,但误判的值只会偏大而不会偏小,也就是牺牲了精度。查询复杂度为 O(1)。以下为 redis 中和 hashtable 的测试内存结果对比:
测试元素 100w ,元素大小 32 个字节
# Count-Min Sketch
# Memory
used_memory:9525832
used_memory_human:9.08M
# hashtable
# Memory
used_memory:81505704
used_memory_human:77.73M
Count-Min Sketch 算法如果已经理解了布隆过滤器则较为简单,这里不做过多解释,详见引用文档。
2. 命令详解
CMS.INITBYDIM {key} {width} {depth}
该命令用于创建一个计数器,时间复杂度:O(1)。其中参数介绍如下:
- key:计数器的键。
- width :数组长度,可以简单认为是容量,但实际上正真的容量应为 width * depth,然而由于哈希冲突将使用数组桶,建议 width 作为容量,从而降低误判。
- depth :计数器数组的数量。
CMS.INITBYPROB {key} {error} {probability}
该命令用于以错误率的形式创建一个计数器,时间复杂度:O(1)。其中参数介绍如下:
- key:计数器的键。
- error :元素错误率,影响数组长度。
- probability :元素虚增概率,影响数组的深度。
CMS.INCRBY {key} {item} {increment} [{item} {increment} ...]
该命令用于计数器元素加法运算,支持批量操作,允许加上负整数,但运算结果如果小于0则换算为最大数,时间复杂度:O(1)。其中参数介绍如下:
- key:计数器的键。
- item :元素。
- increment :加上的整数。
CMS.QUERY {key} {item ...}
该命令用于计数器元素运算结果查询,时间复杂度:O(1)。其中参数介绍如下:
- key:计数器的键。
- item :要查询的元素。
CMS.MERGE {dest} {numKeys} {src ...} [WEIGHTS {weight ...}]
该命令用于多个计数器的运算结果相加,但需要注意的是计数器必须拥有相同的创建参数配置(宽度和深度),时间复杂度:O(n)。其中参数介绍如下:
- dest:运算结果写入的目标计数器,该计数器必须存在。
- numKeys:合并的计数器数量。
- src:要合并的计数器 key 集合。
- WEIGHTS:运算权重(乘积),默认为 1。
CMS.INFO {key}
命令用于查看计数器详情,时间复杂度:O(1),其中参数介绍如下:
- key:计数器的键。
四、TopK
1. 使用介绍
该模块相比于 Count-Min Sketch 增加了存储前 k 个的元素,通过 HeavyKeeper 算法进行了实现,但目前 2.1.0 插件版本其表现并不理想。以下为 redis 中和 zset 的测试内存结果对比:
测试元素 100w ,元素大小 32 个字节
# 布隆过滤器
# Memory
used_memory:68275112
used_memory_human:65.11M
# zset
# Memory
used_memory:119351264
used_memory_human:113.82M
根据以上对比,似乎 TopK 在内存表现上,和 Count-Min Sketch 相比并不理想。这里使用 Count-Min Sketch 配和 zset 进行实现也许是一个更好的选择。
HeavyKeeper 算法论文引用地址
2. 命令详解
TOPK.RESERVE {key} {topk} [{width} {depth} {decay}]
命令用于创建计数器,时间复杂度:O(1),其中参数介绍如下:
- key:计数器的键。
- topk:要保留的前 n 个元素。
- width:数组宽度。
- depth:数组桶深度。
- decay:计数器结果降低率。
TOPK.ADD {key} {item ...}
命令用于计数器中添加元素,时间复杂度:O(k + depth),其中参数介绍如下:
- key:计数器的键。
- item:添加的元素。
TOPK.INCRBY {key} {item} {increment} [{item} {increment} ...]
命令用于计数器中的元素加上一个整数,时间复杂度:O(k + n * depth),其中参数介绍如下:
- key:计数器的键。
- item:要计算的元素。
- increment:加上的整数值。
TOPK.QUERY {key} {item ...}
命令用于计数器中的元素查询是否处于前 n 个,时间复杂度:O(n),其中参数介绍如下:
- key:计数器的键。
- item:查询的元素。
TOPK.COUNT {key} {item ...}
命令用于计数器中的元素的运算结果,时间复杂度:O(k * depth),其中参数介绍如下:
- key:计数器的键。
- item:查询的元素。
TOPK.LIST {key}
命令用于计数器中的前 n 个元素,不足则补充为 nil,时间复杂度:O(n),其中参数介绍如下:
- key:计数器的键。
TOPK.INFO {key}
命令用于查看计数器详情,时间复杂度:O(1),其中参数介绍如下:
- key:计数器的键。