数据同步:MySQL到Elasticsearch
目录
背景
随着平台的业务日益增多,基于数据库的全文搜索查询速度较慢,已经无法满足需求。所以,决定基于Elasticsearch 做一个全文搜索平台,支持业务相关的搜索需求。那么第一个问题就是:如何从MySQL同步数据Elasticsearch?
1、基于应用程序多写
直接通过应用程序数据双写到MySQL和ES
**记录删除机制:**直接删除
一致性: 需要自行处理,需要对失败错误做好日志记录,做好异常告警并人工补偿
优点: 直接明了,能够灵活控制数据写入,延迟最低
缺点: 与业务耦合严重,逻辑要写在业务系统中
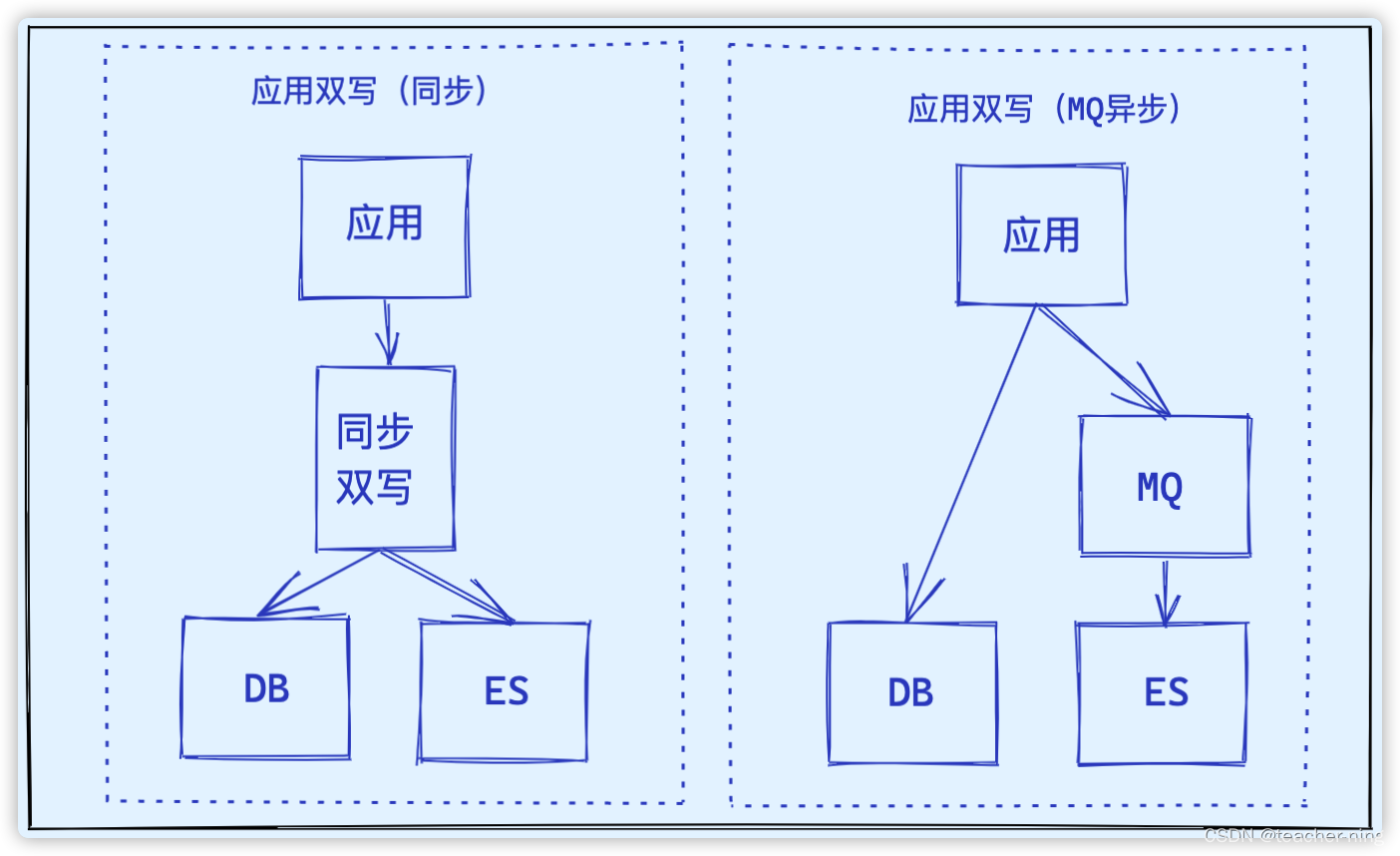
应用双写(同步)
直接通过ES API将数据写入到ES集群中,也就是写入数据库的同时调用ES API写入到ES中,这个过程是同步的
应用双写(MQ异步解耦)
对 应用双写(同步)的改进,引入MQ中间件。
把同步变为异步,做了解耦。
同时引入MQ后双写性能提高,解决数据一致性问题。
缺点是会增加延迟性,业务系统增加mq代码,而且多一个MQ中间件要维护
2、基于binlog订阅
binlog订阅的原理很简单,模拟一个MySQL slave 订阅binlog日志,从而实现CDC(change data capture)
CDC,变更数据获取的简称,使用CDC我们可以从数据库中获取已提交的更改并将这些更改发送到下游,供下游使用。这些变更可以包括INSERT,DELETE,UPDATE等。
**记录删除机制:**直接删除
一致性: 最终一致性
优点: 对业务系统无任何侵入
缺点: 需要维护额外增加的一套数据同步平台;有分钟级的延迟
2.1:canal
https://github.com/alibaba/canal/
阿里巴巴 MySQL binlog 增量订阅&消费组件
简介
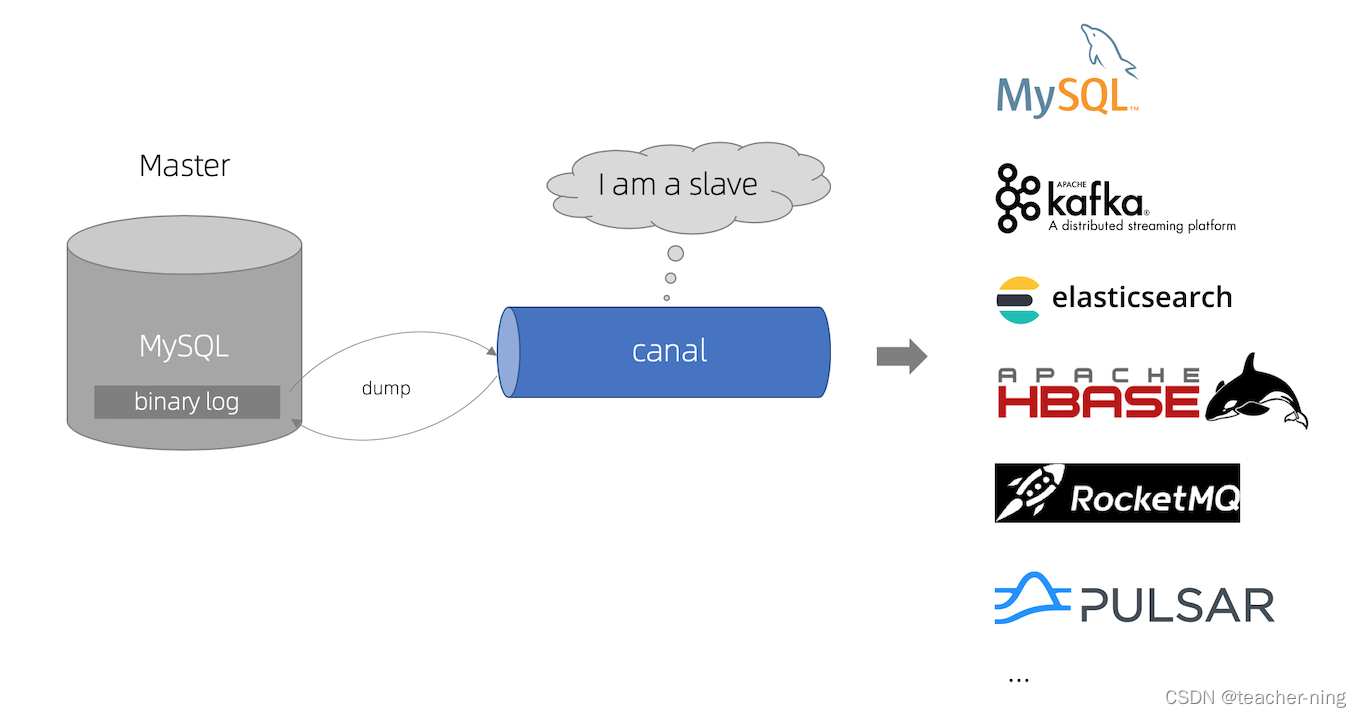
canal [kə’næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
基于日志增量订阅和消费的业务包括:
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护(拆分异构索引、倒排索引等)
- 业务 cache 刷新
- 带业务逻辑的增量数据处理
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
工作原理
MySQL主备复制原理
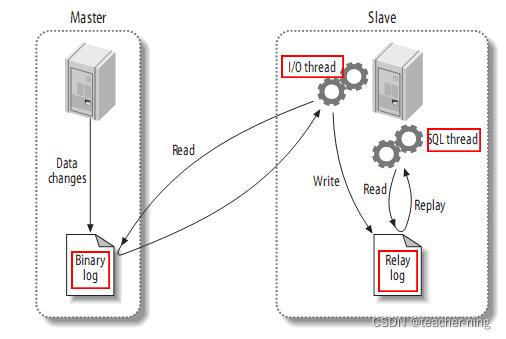
- MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
- MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
canal 工作原理
-
canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
-
MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
-
canal 解析 binary log 对象(原始为 byte 流)
canal同步数据流程图:

优点:
1、canal是同步MySQL的binlog日志,不需要全量更新数据;
2、Kafka是一个高吞吐量的分布式发布订阅消息系统,性能高速度快。
缺点:
1、组件较多,有canal-server、Kafka 和canal-adapter 三个组件;
2、配置相对复杂。
2.2、Databus
https://github.com/linkedin/databus
Linkedin Databus 分布式数据库同步系统
2.3、Maxwell
官网:http://maxwells-daemon.io/
https://github.com/zendesk/maxwell
2.4、Flink CDC
https://github.com/ververica/flink-cdc-connectors
flink-cdc-connectors 中文教程https://github.com/ververica/flink-cdc-connectors/wiki/%E4%B8%AD%E6%96%87%E6%95%99%E7%A8%8B
基于flink数据计算平台实现 MySQL binlog订阅直接写入es
Flink CDC抛弃掉其他中间件,实现 MySQL 》Flink CDC》ES 非常简洁的数据同步架构
该方式比较新2020年开始的项目,目前在一些实时数仓上有应用
2.5、DTS(阿里云)
阿里云的商业产品,具备好的易用性,省运维成本。
2.6、CloudCanal
CloudCanal官网https://www.clougence.com/?utm_source=wwek
CloudCannal数据同步迁移系统,商业产品
3、基于SQL抽取
基于SQL查询的数据抽取同步
这种方式需要满足2个基本条件
1、MySQL的表必须有唯一键字段(和ES中_id对应)
2、MySQL的表必须有一个“修改时间”字段,该记录任何一个字段修改都需要更新“修改时间”
有了唯一键字段就可以知道修改某条记录后同步哪条ES记录,有了修改时间字段就可以知道同步到哪儿了。
满足了这2个基本条件这样就可实现增量实时同步。
记录删除机制:逻辑删除,在MySQL中增加逻辑删除字段,ES搜索时过滤状态
一致性: 依赖修改时间字段;延迟时间等于计划任务多久执行一次
优点: 对业务系统无任何侵入,简单方便;课用JOIN打宽表
缺点: MySQL承受查询压力;需要业务中满足2个基本条件
基于Logstash同步数据
Logstash同步数据流程图:
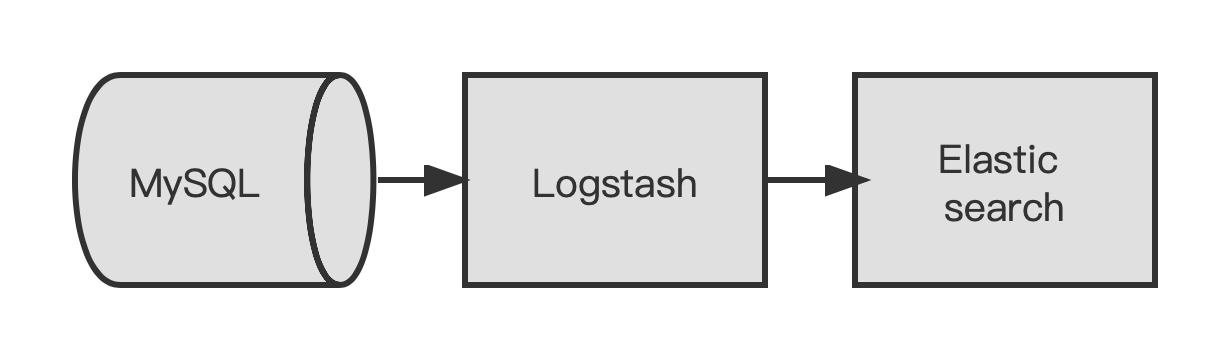
我们使用 Logstash 和 JDBC 输入插件来让 Elasticsearch 与 MySQL 保持同步。从概念上讲,Logstash 的 JDBC 输入插件会运行一个循环来定期对 MySQL 进行轮询,从而找出在此次循环的上次迭代后插入或更改的记录。如要让其正确运行,必须满足下列条件:
- 在将 MySQL 中的文档写入 Elasticsearch 时,Elasticsearch 中的 “_id” 字段必须设置为 MySQL 中的 “id” 字段。这可在 MySQL 记录Elasticsearch 文档之间建立一个直接映射关系。如果在 MySQL中更新了某条记录,那么将会在 Elasticsearch 中覆盖整条相关记录。请注意,在 Elasticsearch中覆盖文档的效率与更新操作的效率一样高,因为从内部原理上来讲,更新便包括删除旧文档以及随后对全新文档进行索引。
- 当在 MySQL 中插入或更新数据时,该条记录必须有一个包含更新或插入时间的字段。通过此字段,便可允许 Logstash仅请求获得在轮询循环的上次迭代后编辑或插入的文档。Logstash 每次对 MySQL 进行轮询时,都会保存其从 MySQL所读取最后一条记录的更新或插入时间。在下一次迭代时,Logstash便知道其仅需请求获得符合下列条件的记录:更新或插入时间晚于在轮询循环中的上一次迭代中所收到的最后一条记录。
input {
jdbc {
jdbc_driver_library => "<path>/mysql-connector-java-8.0.16.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://<MySQL host>:3306/es_db"
jdbc_user => <my username>
jdbc_password => <my password>
jdbc_paging_enabled => true
tracking_column => "unix_ts_in_secs"
use_column_value => true
tracking_column_type => "numeric"
schedule => "*/5 * * * * *"
statement => "SELECT *, UNIX_TIMESTAMP(modification_time) AS unix_ts_in_secs FROM es_table WHERE (UNIX_TIMESTAMP(modification_time) > :sql_last_value AND modification_time < NOW()) ORDER BY modification_time ASC"
}
}
filter {
mutate {
copy => { "id" => "[@metadata][_id]"}
remove_field => ["id", "@version", "unix_ts_in_secs"]
}
}
output {
# stdout { codec => "rubydebug"}
elasticsearch {
index => "rdbms_sync_idx"
document_id => "%{[@metadata][_id]}"
}
}
配置Logstash的计划任务,定时执行
优点:
1、组件少,只需要Logstash就可以实现;
2、配置简单,配置Logstash文件就可以。
缺点:
在数据量很大的情况下,Logstash可能会成为性能瓶颈
4、总结
前期建议采用 基于SQL抽取的方式做同步,后期数据量大了建议采用基于binlog订阅的方式同步。
如果本身有现成的Flink平台可用,推荐使用Flink CDC。
什么是最佳的 MySQL 同步 ElasticSearch 方案?
答案是选择缺点可以接受,又满足需求,拥有成本最低的方案。
“完美”的方案往往拥有成本会比较高,所以需要结合业务环境的上下文去选择。
没有一招鲜的方案,因为每种方案都有利弊,所以选取适合你当下业务环境的方案。那么这样的方案就是最佳方案。