Logstash 配置文件中各种组件详解
笔记主要源自#雪山飞胡#
文章目录
Logstash 前言
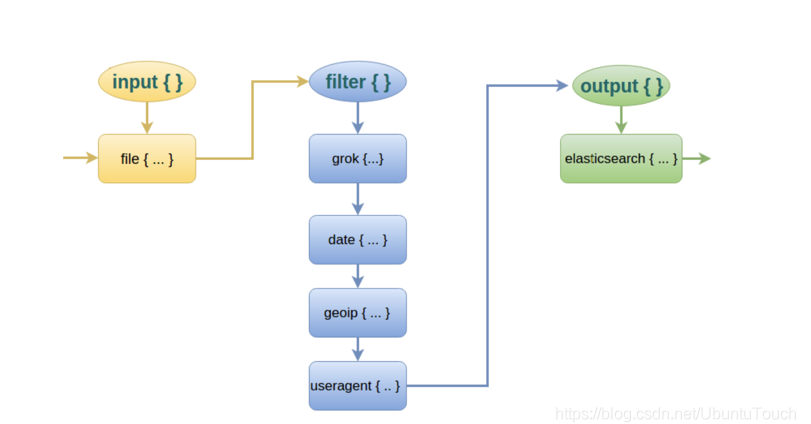
Logstash主要由三部分组成:input、filter、output。而filter就是过滤器插件,这个组件可以不要,但是这样子就不能体现出logtash的强大过滤功能了。
input{
输入插件
}
filter{
过滤器插件
}
outer{
输出插件
}
Input Plugin
Stdin
交互式输入数据
stdin{}从控制台输入 :
input{
stdin{
codec=>"plain"
tags=>["test"]
type=>"std"
add_field=>{"key"=>"value"}
}
}
output{
stdout{
codec=>"rubydebug"
}
}
- codec类型为codec (请看下面Codec Plugin详解)
- type类型为string ,自定义该事件的类型,可用于后续判断
- tags类型为array ,自定义该事件的tag ,可用于后续判断
- add_field类型为hash ,为该事件添加字段
File
例 :
input {
file {
path => ["文件路径"]
start_position => "beginning"
sincedb_path => "/dev/null"
ignore_older => 0
}
}
可选配置:
| 配置项 | 说明 |
|---|---|
| path* | 数组类型,必选,用于知名读取的文件路径,基于glob匹配语法。 |
| exclude | 数组类型,排除不想监听的文件规则,基于glob匹配语法 |
| sincedb_path | 字符串类型,记录sinceddb文件路径,默认路径是当前用户的home文件夹 |
| start_position | 字符串类型,可以配置为beginning/end,是否从头读取文件 |
| stat_interval | 数值类型,单位为秒,定时检查文件是否有更新,默认是1秒 |
| discover_interval | 数值类型,单位为秒,定时检查是否有新文件待读取,默认是15秒 |
| ignore_older | 数值类型,单位为秒,扫描文件列表时,如果该文件上次更改时间超过设定的时长,则不做处理,但依然会监控是否有新内容,默认关闭 |
| close_older | 数值类型,单位为秒,如果监听的文件在超过该设定时间内没有新内容,会被关闭文件句柄,释放资源,但依然会监控是否有新内容,默认3600秒,即1小时 |
参数path模糊匹配 :
-
/var/log/*.log:匹配/var/log目录下以.log结尾的所有文件 -
/var/log/**/*.log:匹配/var/log所有子目录下以.log结尾的文件 -
/var/log/{app1,app2,app3}/*.log:匹配/var/log目录下app1,app2,app3子目录中以.log结尾的文件
参数sincedb_path通过sincedb_path => "/dev/null"可使文件每次都能从头开始读取(linux)
start_position:默认是从文件末尾开始解析(监控)
ignore_older:默认超过24小时的日志不解析,0表示不忽略任何过期日志
HTTP
input {
http {
port => 端口号
}
}
TCP
input {
tcp {
mode => "server"
host => "0.0.0.0"
port => 端口号
codec => json_lines
}
}
Beats
# 配置filebeat
beats {
type => beats
port => 端口号
#把当前不匹配行的数据添加到前面匹配行后面,直到新进的当前行匹配 ^\[ 正则为止。
codec => multiline {
pattern => "^\["
negate => true
what => "previous"
}
}
Codec Plugin
编码插件(codec)可以在logstash输入或输出时处理不同类型的数据,同时,还可以更好更方便的与其他自定义格式的数据产品共存,比如:fluent、netflow、collectd等通用数据格式的其他产品。因此,logstash不只是一个input–>filter–>output的数据流,而且是一个input–>decode–>filter–>encode–>output的数据流。
Codec Plugin作用于Input和Output Plugin,负责将数据在原始与Logstash Event之间转换,常见的codec有:
- plain:读取原始内容,主要用于事件之间没有分隔的纯文本。
- dots:将内容简化为点进行输出
- rubydebug:将Logstash Events按照ruby格式输出,方便调试
- line:处理带有换行符的内容
- json:处理json格式的内容,如果数据为json格式,可直接使用该插件,从而省掉filter/grok的配置,降低过滤器的cpu消耗
- multiline:处理多行数据的内容
Plain
plain是最简单的编码插件,你输入什么信息,就返回什么信息
input {
stdin {
codec => plain
}
}
output {
stdout {
codec => plain
}
}
Json&Json_lines
有时候logstash采集的日志是JSON格式,那我们可以在input字段加入codec => json来进行解析,这样就可以根据具体内容生成字段,方便分析和储存。如果想让logstash输出为json格式,可以在output字段加入codec=>json。
Multiline
当一个Event的message由多行组成时,需要使用multiline,常见的情况是处理日志信息,如下所示:
Exception in thread "main" java.lang.NullPointerException
at com.example.myproject.Book.getTitle(Book.java:16)
at com.example.myproject.Author.getBookTitles(Author.java:25)
at com.example.myproject.Bootstrap.main(Bootstrap.java:14)
| 参数 | 说明 |
|---|---|
| pattern | 设置行匹配的正则表达式,可以使用grok |
| what | 可设置为previous或next。表示当与pattern匹配成功的时候,匹配行是归属上一个事件还是下一个事件 |
| negate | 布尔值,表示是否对pattern的结果取反 |
例 :
input {
file {
path => "/path/to/catalina.out"
start_position => "beginning"
type => "tomcat_log"
codec => multiline {
pattern => "^%{MONTHDAY}[./-]%{MONTH}[./-]%{YEAR}"
negate => true
what => "previous"
auto_flush_interval => 10
}
}
}
- pattern为正则表达式匹配
- negate为布尔类型,true表示否定正则表达式,即不匹配正则表达式。false为匹配正则表达式。默认值为false
- what表示如果正则匹配与否,事件属于上一个或者下一个事件。有两个值可选 - previous(上一个)或者next(下一个)
- auto_flush_interval表示当多长时间没有新的数据,之前积累的多行数据转换为一个事件。这里的10表示10秒
以上的配置可以解释为:不匹配pattern时间戳格式开头的行数据,都归属到上一个事件中,即在下一个匹配的时间戳出现之前的所有行的输出都属于同一个事件,从而达到合并多行的目的,同时等待10秒没有新数据产生,那么最后一个时间戳格式后的所有行数据就是最后一个事件。
Filter Plugin
| 插件名称 | 说明 |
|---|---|
| date | 日期解析 |
| grok | 正则匹配解析 |
| dissect | 分隔符解析 |
| mutate | 对字段作处理,比如重命名、删除、替换 |
| json | 按照json解析字段内容到指定字段中 |
| geoip | 增加地理位置数据 |
| ruby | 利用ruby代码来动态修改Logstash Event |
Date
date插件可以将日期字符串解析为日期类型,然后替换@timestamp字段或者指定其他字段:
filter {
date {
match => ["logdate", "MM dd yyy HH:mm:ss"]
}
}
通过以上配置,我们可以将
{
"logdate": "Jan 01 2018 12:02:2018"
"target": "@timestamp"
}
转换为:
{
"@version" => "1"
"host" => "..."
"logdate" => Jan01 2018 12:02:08
"@timestamp" => "2018-01-01T04:02:08.000Z"
}
Grok
grok语法:
例子:%{SYNTAX:SEMANTIC}
SYNTAX为grok pattern的名称,SEMANTIC为赋值字段名称。%{NUMBER:duration}可以匹配数值类型,但是grok匹配出的内容都是字符串类型,可以通过在最后指定为int或者float来强转类型:%{NUMBER:duration:int}
grok插件用于解析日志内容,例如我们要将下面这一条日志解析成json数组。
83.149.9.216 [17/May/2015:10:05:03 +0000] "GET /presentations/logstash-monitorama-2013/images/kibana-search.png HTTP/1.1" 200 203023 "http://semicomplete.com/presentations/logstash-monitorama-2013/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.77 Safari/537.36"
那么我们就可以这样来配置grok:
%{IPORHOST:clientip} \[%{HTTPDATE:timestamp}\] "%{WORD:verb} %{DATA:request} HTTP/%{NUMBER:httpversion}" %{NUMBER:response:int} (?:-|%{NUMBER:bytes:int}) %{QS:referrer} %{QS:agent}
-
%{IP:clientip} 匹配模式将获得的结果为:clientip: 83.149.9.216
-
%{HTTPDATE:timestamp} 匹配模式将获得的结果为:timestamp: 17/May/2015:10:05:03 +0000
-
%{QS:referrer} 匹配模式将获得的结果为:referrer: “GET /presentations/logstash-monitorama-2013/images/kibana-search.png HTTP/1.1”
自定义grok pattern
一
filter {
grok {
match => {
"message" => "%{SERVICE:service}"
}
pattern_definitions => {
"SERVICE" => "[a-z0-9]{10,11}"
}
}
}
二
格式 : (?<fieldName>pattern)
fieldName : 指定匹配要赋值的名称
pattern : 匹配的正则表达式
例 :
[2018-11-24 08:33:43,253][ERROR][http-nio-8080-exec-4][com.hh.test.logs.LogsApplication][code:200,msg:测试录入错误日志,param:{fdsafdsfdf}]
指定grok表达式 :
(?<date>\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2},\d{3})\]\[(?<type>[A-Z]+)\]\[(?<thread>[A-z0-9-]*)\]\[(?<class>[A-z\.]*)\]\[code:(?<code>[0-9]{0,3}),msg:(?<msg>.*),param:{(?<param>.*)}\]
返回结果
{
"date": "2018-11-24 08:33:43,253",
"msg": "测试录入错误日志",
"code": "200",
"param": "fdsafdsfdf",
"thread": "http-nio-8080-exec-4",
"type": "ERROR",
"class": "com.hh.test.logs.LogsApplication"
}
grok删除不需要的数据 :
filter {
grok {
match => ["message","\s*%{TIMESTAMP_ISO8601}\s+(?<Level>(\S+)).*"]
}
if [Level] == "DEBUG" { drop {} }
if [Level] == "INFO" { drop {} }
}
Level 为grok 解析后字段的属性名称
可在 Input Plugin 指定type值,然后在Filter Plugin根据type值动态保留所要的数据
Dissect
源自shark_西瓜甜
Dissect filter 是一种分割操作。与常规拆分操作不同,其中一个分隔符应用于整个字符串,此操作将一组分隔符应用于字符串值。
Dissect不使用正则表达式,而且速度非常快。但是,如果文本的结构因行而异,那么Grok更适合。
例 :
input { stdin {}}
filter {
dissect {
mapping => {
"message" => "%{ts} %{+ts} %{+ts} %{src} %{} %{prog}[%{pid}]: %{msg}"
}
convert_datatype => {
pid => "int"
}
}
}
output { stdout {}}
测试数据 :
%{ts} %{+ts} %{+ts} %{src} %{} %{prog}[%{pid}]: %{msg}
hello world hello shark 123 logs [456]: hellohello
返回结果 :
{
"host" => "es03",
"@timestamp" => 2021-06-07T14:40:40.010Z,
"message" => "hello world hello shark 123 logs [456]: hellohello",
"src" => "shark",
"pid" => 456,
"@version" => "1",
"prog" => "logs ",
"ts" => "hello world hello",
"msg" => "hellohello"
}
dissect语法简单,因此它能处理的场景比较有限。它只能处理格式相似,且有分隔符的字符串。它的语法如下:
- %{}里面是字段
- 两个%{}之间是分隔符。
- %{+some_field} 表示把匹配到的内容追加到前一个字段中
- %{+some_field/2} 表示带序号的追加,2 表示追加到第二个位置
追加字段 :
- 对于文本
1 2 3 go, 这个%{+a/2} %{+a/1} %{+a/4} %{+a/3}将构建一个a => 2 1 go 3的键值。 - 对于文本
1 2 3 go, 这个%{a} %{b} %{+a}将构建两个键值对:a => 1 3 go, b => 2
跳过字段 :
%{}是一个空的跳过字段。%{?foo}是一个命名的跳过字段,就是把匹配到的内容先存到字段 foo
中,但是不会出现在事件中,这种情况是让后面的某些模式使用其匹配到的值的。
间接字段 :
- 对于字符串:
error: some_error, some_description - 这个表达式
error: %{?err}, %{&err}将会构建一个这样的键值对:some_error => some_description
%{?err} 跳过some_error字段保存但是但是不会出现在事件中,%{&err}又引用%{err}
所以最终 some_error => some_description
Mutate
可以对字段进行各种操作,比如重命名、删除、替换、更新等,主要操作如下:
- convert类型转换
- gsub字符串替换
- split、join、merge字符串切割、数组合并为字符串、数组合并为数组
- rename字段重命名
- update、replace字段内容更新或替换。它们都可以更新字段的内容,区别在于update只在字段存在时生效,而replace在字段不存在时会执行新增字段的操作
- remove_field删除字段
例 :
mutate {
convert => {"age" => "integer"}
gsub => [
"birthday", "-", "/",
"image", "\/", "_"
]
split => {"hobities" => ","}
rename => {"hobities" => "hobityList"}
replace => {"icon" => "%{image}"}
remove_field => ["message"]
}
Json
将字段内容为json格式的数据解析出来。
filter {
json {
source => "message"
target => "msg_json"
}
}
Geoip
根据ip地址提供对应的地域信息,比如经纬度、城市名等,方便进行地理数据分析。
filter {
geoip {
source => "clientIp"
}
}
clientIp : 指定IP的属性名
Output Plugin
Stdout
输出到控制台
output {
stdout {
codec => rubydebug
}
}
File
输出到文件,实现将分散在多地的文件统一到一处的需求,比如将所有web机器的web日志收集到1个文件中,从而方便查阅信息
output {
file {
path => "文件路径"
codec => line {format => %{message}}
}
}
Elasticsearch
输出到elasticsearch
output {
elasticsearch {
hosts => ["http://192.168.3.12:9200"]
index => "logstash-%{+YYYY.MM.dd}"
document_type => "_doc"
user => "用户名"
password => "密码"
}
}
hosts :elasticsearch地址
index : 设置插入的索引
补充
较复杂示例模板 :
input {
beats {
type => beats
port => 5000
}
}
filter {
multiline {
patterns_dir => "/Users/ArpitAggarwal/logstash/patterns"
pattern => "\[%{TOMCAT_DATESTAMP}"
what => "previous"
}
if [type] == "my_log" and "com.test.controller.log.LogController" in [message] {
mutate {
add_tag => [ "MY_LOG" ]
}
if "_grokparsefailure" in [tags] {
drop { }
}
date {
match => [ "timestamp", "UNIX_MS" ]
target => "@timestamp"
}
} else {
drop { }
}
}
output {
stdout {
codec => rubydebug
}
if [type] == "my_log" {
elasticsearch {
manage_template => false
hosts => ["localhost:9201"]
}
}
}
logstash可以使用条件判断来控制filter的执行。官方说明见Accessing Event Data and Fields in the Configuration。支持的运算符包括:
相等: ==, !=, <, >, <=, >=
正则: =~(匹配正则), !~(不匹配正则)
包含: in(包含), not in(不包含)
布尔操作: and(与), or(或), nand(非与), xor(非或)
一元运算: !(取反), ()(复合表达式), !()(对复合表达式结果取反)