Quantization|A White Paper on Neural Network Quantization (谷歌量化白皮书)
记一下谷歌量化白皮书的理解。
1 Introducation
本文介绍两种主要的category:
- PTQ: post-training quantization: 只需要在正常训练后的参数上调超参数
- QAT: quantization-aware-training: 需要在训练网络的时候量化
2 Quantization fundanmentals
2.1 Hardware background
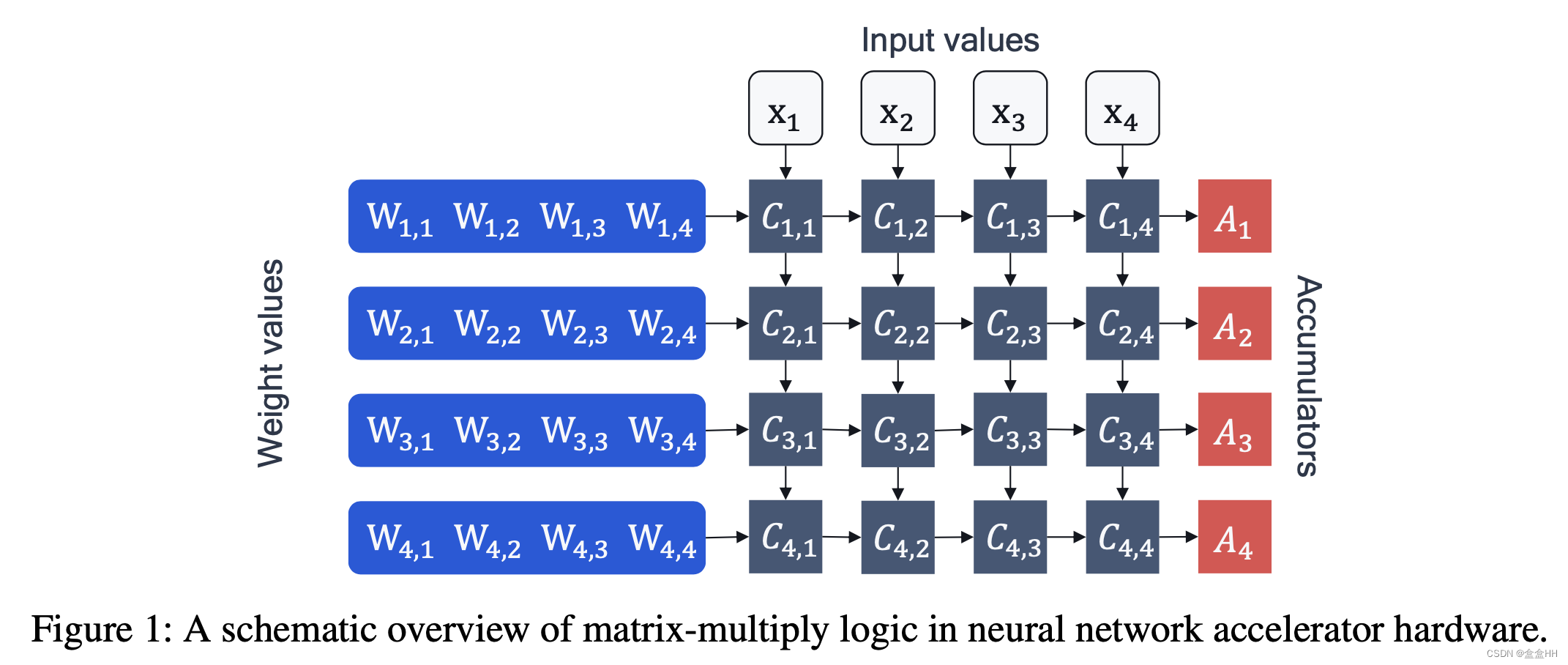
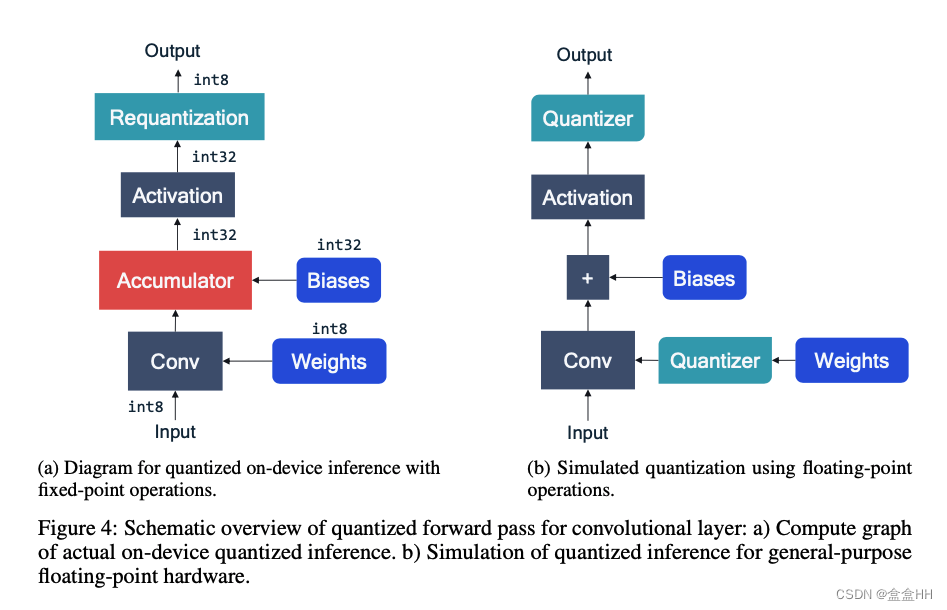
硬件如何计算一个矩阵乘法 y = W x + b y = Wx + b y=Wx+b? 如图,NN 加速器主要需要两组成部分:processing elements C n , m C_{n,m} Cn,m 和accumulators A n A_n An .计算的流程:
-
load bias value b n b_n bn,
-
load weight values W n , m W_{n,m} Wn,m 以及 这层的输入 x m x_m xm, 计算 C n , m = W n , m x m C_{n,m} = W_{n,m}x_m Cn,m=Wn,mxm
-
把计算结果放进accumulator:
A n = b n + ∑ C n , m A_n = b_n+ \sum{C_{n,m}} An=bn+∑Cn,m
上面的步骤就叫 MAC(Multiply-accumulate). 对于较大的矩阵乘法,该步骤重复很多次。在所有cycle结束以后,accumulator里的值被放回memory,供下一层神经网络使用。
一般NN用的都是FP32,MAC操作和数据传输需要能量消耗,因此我们需要量化。一个浮点数可以被表示为:
X ^ = s X ⋅ x i n t ≈ x \hat{X} = s_X·x_{int} \approx x X^=sX⋅xint≈x
其中 s x s_x sx是一个浮点数scale factor, x i n t x_int xint是一个integer vector。我们用 X ^ \hat{X} X^来表示量化后的vector。量化weights和activation之后,我们重写accumulation equation。
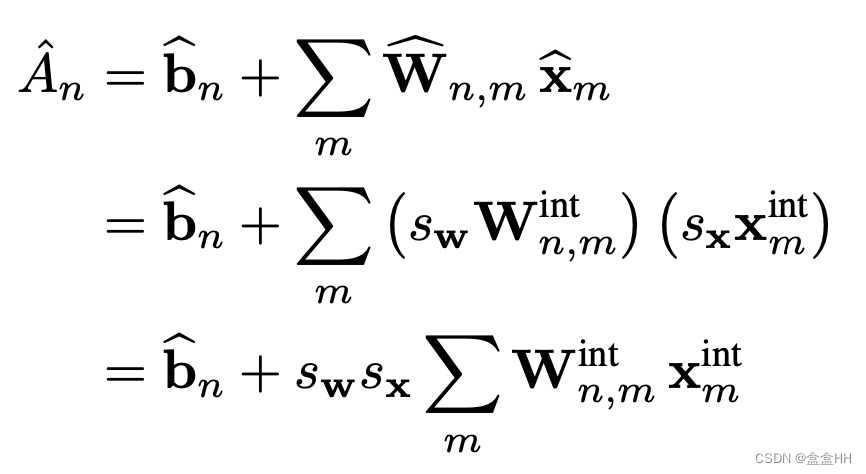
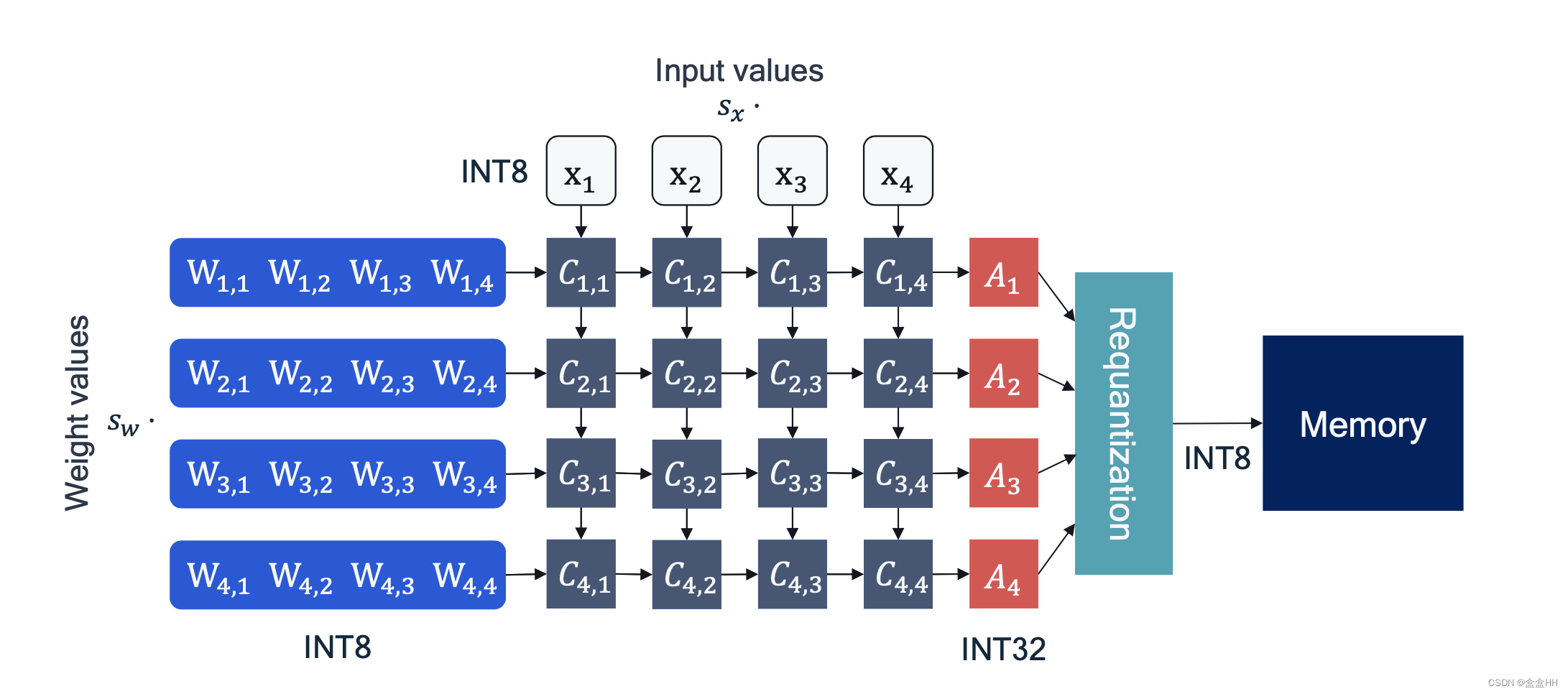
注意这里有两个scale vector, s w s_w sw for weights, s x s_x sx for activations(这里不是activation激活函数,是这层的输入). 这里暂时不量化bias。下图展示了加入量化过后的accumulators。requantization的步骤是为了在把数据写入memory的时候减少传输代价,所以这里重新量化成INT8.
2.2 Uniform affine quantization
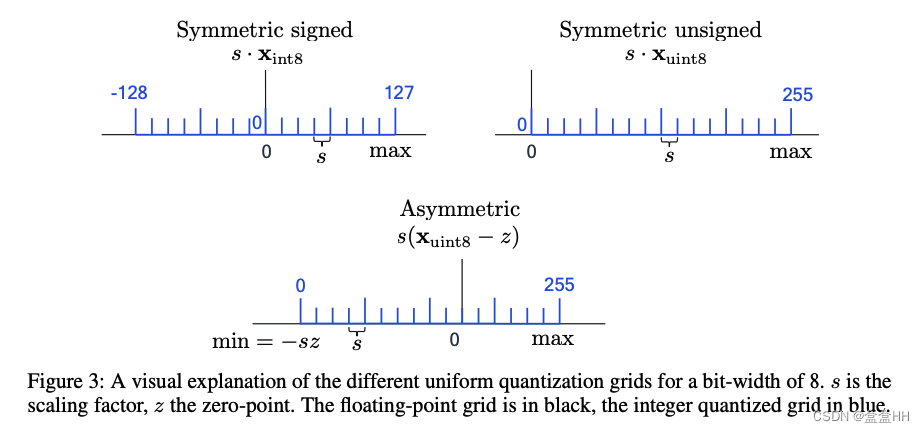
uniform affine quantization(asymmetric quantization)均匀映射量化是最常用的量化方式,因为它能让浮点数运算的实现变得高效。它有三个参数:步长scale factor s s s, 零点zero-point z z z, 位宽bit-width b b b。 s s s 和 z z z 用来把浮点数映射到整数网格,而整数网格的大小由 b b b 决定。步长通常是浮点数。零点通常是整数,用来保证真实的0被正确量化。下面的式子把x映射到整数网格 { 0 , . . . 2 b − 1 } \{0,...2^b-1\} {0,...2b−1}

即先计算 [ s x + z ] [\frac{s}{x}+z] [xs+z],负数全都变成0,溢出的变成最大值。如果要计算近似的真实值,则 x ≈ x ^ = s ( x i n t − z ) x \approx \hat{x} = s(x_{int} -z) x≈x^=s(xint−z)
这种方法有个问题,对于极端的单边分布,可能clip了大部分的数值,产生clipping error。如何减少clipping error?范围( { q m i n , q m a x } \{q_{min},q_{max}\} {qmin,qmax})需要更宽来包含零点,即增加步长 s s s。但是这会导致在[ − s 2 , s 2 -\frac{s}{2},\frac{s}{2} −2s,2s]范围里的rounding error增加,所以这里有个trade-off。
2.2.1 Symmetric uniform quantization
是general asymmetric case的简单版(asymmetric的零点是个整数,symmetric零点就是0)。限制zero-point为0.降低处理zero-point的计算overhead。但是这个时候signed 和unsigned int的情况要分开讨论。
2.2.2 Power-of-two quantizer
是symmetric quantization的特殊情况。即步长 s s s必须是2的次方 s = 2 − k s=2^{-k} s=2−k.原因:hardware efficiency,scale with s s s 可以直接 bit shift
2.2.3 Quantization granularity
目前的量化为per-tensor quantization, 因为我们只定义了两组量化参数,一组给weight用,一组给activation用。我们还能定义更细粒度的量化参数,比如per-channel quantization,细粒度能提升精度但是增加overhead。
2.3 Quantization simulation
量化模拟就是在通用硬件上模拟量化行为。比如卷积,需要在conv之前和activation之后进行量化。
2.3.1 batch normalization folding
原本batch normalization 是在linear layer之后,我们把batch normalization 和 linear layer fuse在一起,则可以得到
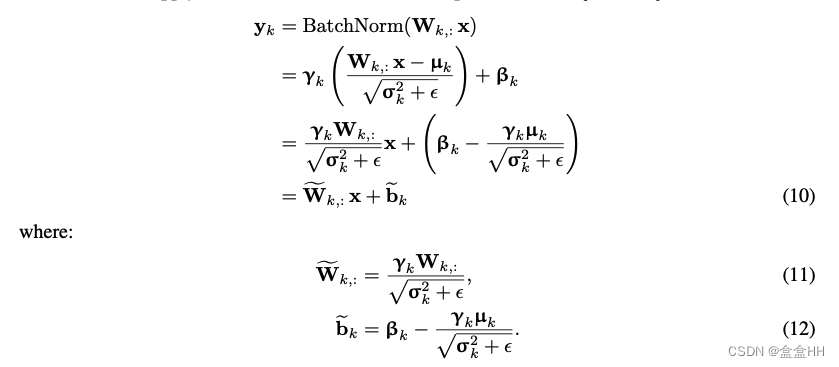
其中 σ \sigma σ 和$ \mu 是 v a r i a n c e 和 m e a n 是 训 练 期 间 计 算 的 均 值 和 方 差 , 是variance 和 mean是训练期间计算的均值和方差, 是variance和mean是训练期间计算的均值和方差,\gamma$ 和 β \beta β是每个通道学习到的affine hyper-parameter 。
2.3.2 Activation function folding
一般linear function后面都有non-linearity, 所以我们可以直接在non-linearity后面应用量化。
2.3.3 Other layers and quantization
maxpooling: 不需要quantization,因为input和output在same integer grid
avgpooling: 因为均值不一定是integer,所以avgpool之后还需要量化。但是input和output的grid基本相同,所以用同一个quantizer。
element-wise addition: 要求两个input的quantization range精准匹配。目前没有可用的solution,但是可以在操作后加一个requantization. 另一种方法是根据input调整量化grids,这种方法不需要requantization,但是需要调参。
**concatenation: ** 一般concatenation的两个input不在同一个quantization grids里,所以一般都需要requantization。和上面一种一样,可能可以让神经网络学习同一组量化参数。
2.4 Practical considerations
注意这一节只考虑homogenous bit-width,这意味着为weights或activation选择的位宽在所有层中保持不变。
2.4.1 Symmetric vs. asymmetric quantization
一般会使用asymmetric activation quantization, 以及symmetric weight quantization.
2.4.2 Per-tensor and per-channel quantization
细粒度的区别,per-channel更细,但是更难implement
3 Post-training quantization
不需要在训练过程中量化,而是把训练好的模型直接量化。一般需要一个小的calibration set(数据集)。
fundamental step:finding good quantization ranges for each quantizer.
3.1 Quantization range setting
key trade-off: clipping error & rounding error (in section2.2)
这里的方法都optimize local cost function, 而不是task loss.
weight quantization不需要calibration,而activation quantization需要calibration data。
Min-max 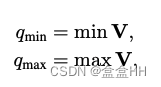
V是input tensor。这种方法没有clipping error,但是sensitive to outliers.
Mean-square error(MSE)
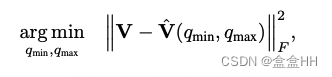
minimize MSE.
Cross-entropy[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uY9hKucn-1655452386971)(quantization.assets/截屏2022-06-06 14.29.22.png)]
BN based range setting
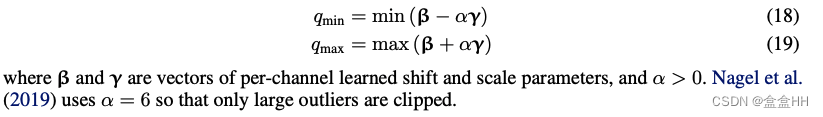
3.2 Cross-layer equalization
Per-tensor quantization会面临问题:当一个tensor里元素差距太大,很难balance clipping error & rounding error. 所以要在不同layer里寻找量化的可能性。一个observation:很多激活函数满足 f ( s x ) = s f ( x ) f(sx) = sf(x) f(sx)=sf(x) . 这叫scaling equivalence。

我们可以找到一个quantization factor s s s, 让rescaled layer里的量化噪声最小。这叫cross-layer equalization(CLE). Optimal 的 s s s :
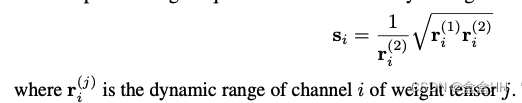
这里的 s s s 只考虑了weight。 同时有人也考虑了activation, 但是没有被证明optimal。
absorbing high bias
Nagel et al. 发现,有的时候CLE会导不同的activation的范围,所以他们提出一种能够让high bias被下一层layer吸收的方法。下面的式子说明,如何把第一层的c吸收到第二层。(第一层后面接了ReLu activation function f f f.
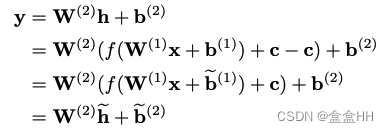
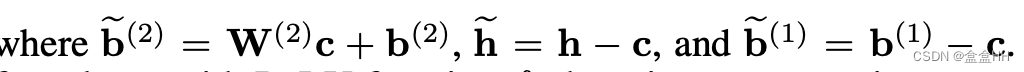
第一行到第二行是因为对于ReLU,存在一个非负vector c c c满足:
r ( W x + b − c ) = r ( W x + b ) − c r(Wx +b-c) = r(Wx+b)-c r(Wx+b−c)=r(Wx+b)−c
什么情况下上面这个式子能成立呢?首先,这是一个正常ReLU:
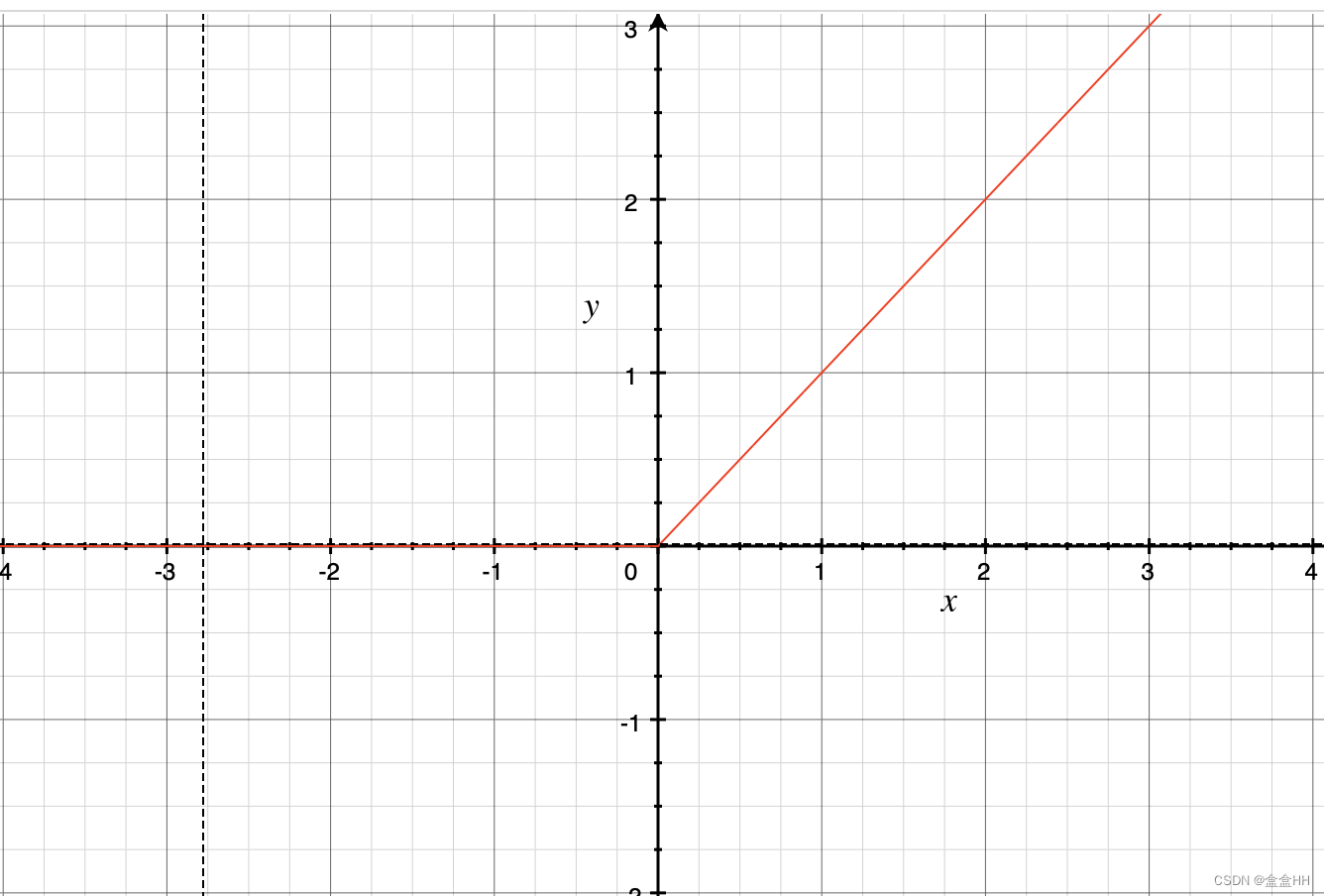
对于等式左边和右边,分别表示为下面两张图。这里我们假设 c = 1 c=1 c=1
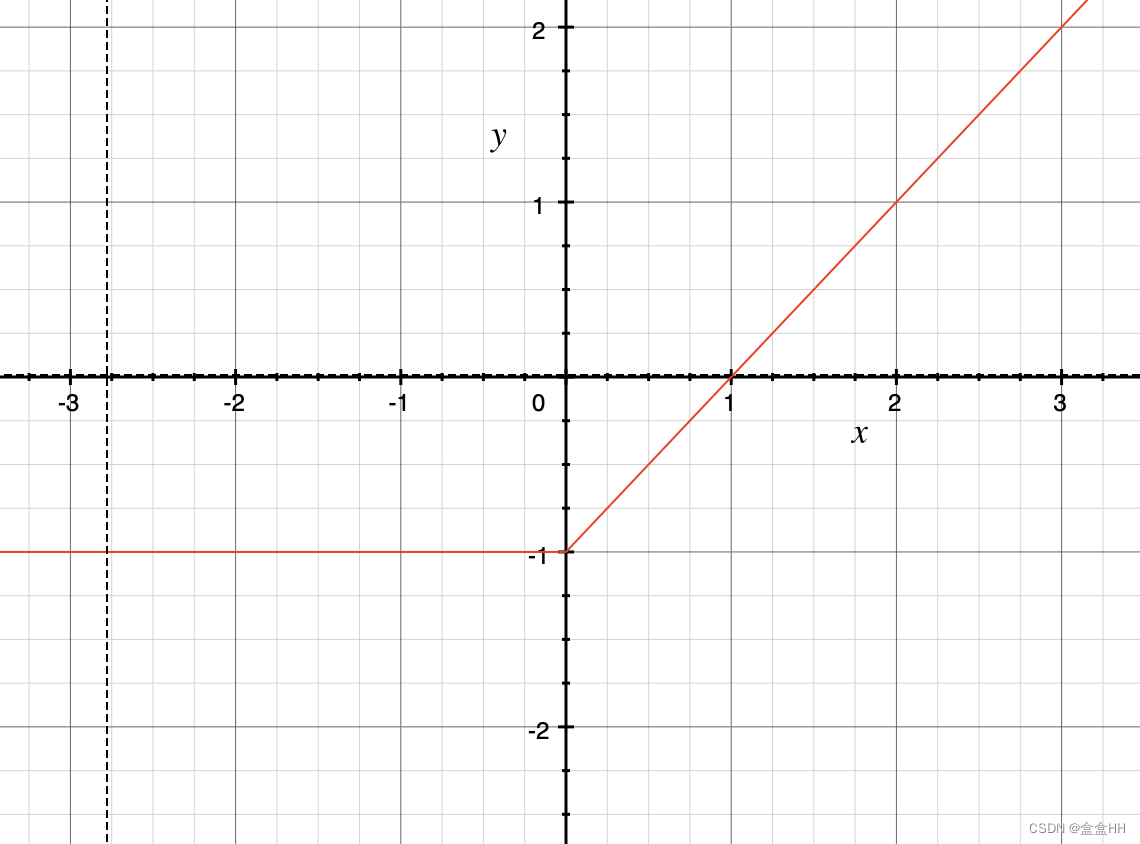
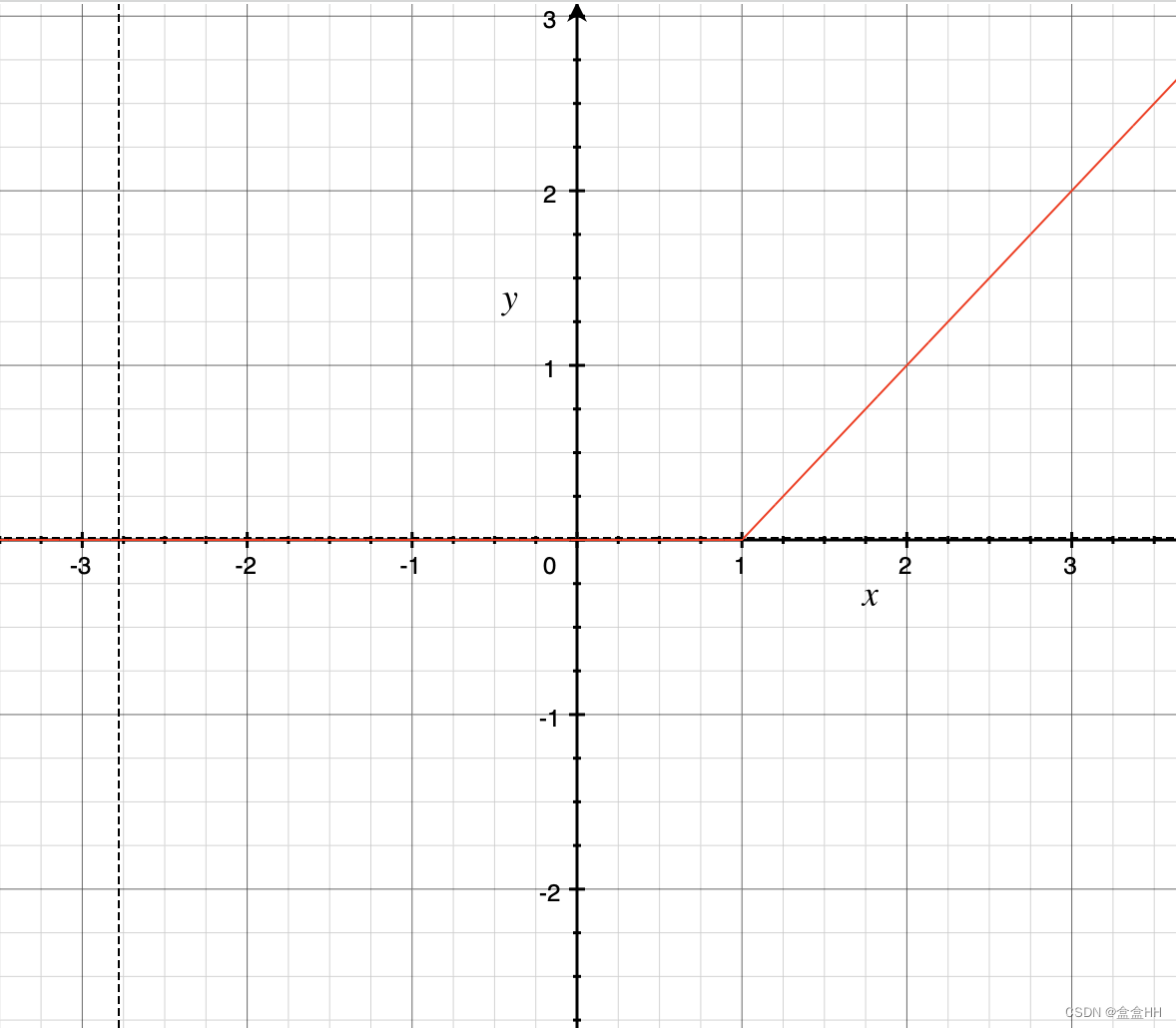
可以看出,当 x > c x>c x>c的时候,等式才完全成立。所以我们想找一个 c c c,尽量让大部分 x > c x>c x>c。所以 c c c是这么来的:
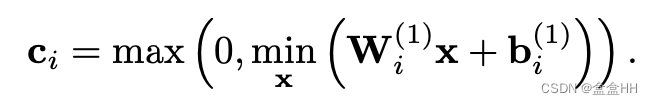
这里的 m i n x min_x minx 是在校准集上算出来的。对于测试集,并不能保证量化后无误差,因此这里还是有量化误差。
3.3 Bias correction
量化误差通常是biased的。比如没有量化的参数是 W W W,量化后是 W ^ \hat{W} W^,则对于 W W W的量化误差是 Δ W = W ^ − W \Delta W = \hat{W}-W ΔW=W^−W, 那么该层的output误差是
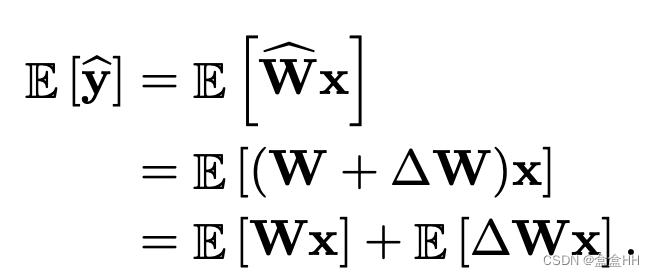
所以biased error是 E [ Δ W x ] E[\Delta Wx] E[ΔWx] . 又因为 Δ W \Delta W ΔW 是常数,所以 E [ Δ W x ] = Δ W E [ x ] E[\Delta Wx] = \Delta WE[x] E[ΔWx]=ΔWE[x]. 即最终我们的biased error是 Δ W E [ x ] \Delta WE[x] ΔWE[x]
所以为了消除误差,我们只需要在output里减掉这一项。
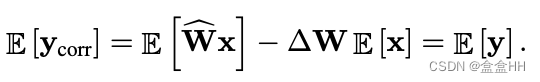
这个correction项和bias的张量大小完全相同,所以在推断的时候我们可以直接把它吸收到bias里,不需要额外的推断开销。
那么怎么计算biased error? 通常有两种方法,分别叫 empirical bias correction 和 analytic bias correction.
Empirical bias correction
如果我们能拿到校准集,就可以直接通过比较全精度和量化后的output:
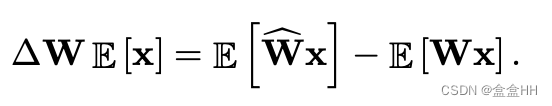
Analytic bias correction
如果没有校准集,可以用analytic bias correction.
3.4 AdaRound
一般把FP32量化为整数,是直接四舍五入到最邻近的整数,这叫rounding-to-nearest. 但这其实不是最optimal的方法。所以我们要用adaptive round. 首先我们用下面的式子定义loss:
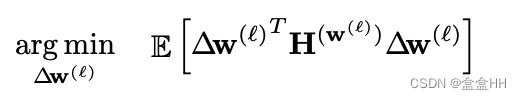
Δ w \Delta w Δw是因为量化引起的扰动,它可以有两个值,一个是round up weight,一个是round down。
。。。。。看不太明白
总之最后转化成了一个优化问题。
3.5 Standard PTQ pipline
cross-layer equalization
add quantizers
weight range setting
AdaRound (这里用于calibration的数据一般500-1000就够了)
Bias correction
Activation range setting
4 Quantization-aware training
4.1 Simulating quantization for backward path
训练的时候量化,问题在于如何进行梯度反向传播, 因为round-to-nearest的梯度通常是0或者undefined。一种方法是STE(straight-through estimator)。这种方法把rounding operation 的gradient设为1,然后我们就可以把gradient equation求出来。我们用 n , p n,p n,p来表示整数grid limits,所以$n=q_{min}/s,p =q_{max}/s $

所以在bp的时候,直接跳过quantizer就行了。
4.2 Batch normalization folding and QAT
如何model BN folding? 一种方法是statistically fold, 在2.3.1节讲过了。
另一种是同时update running statistics并应用batch-statistics.