Spark-hadoop集群中8020:Connection refused
一、使用CentOs7虚拟机运行spark案例报出8020端口出现错误
前提条件,使用standalone模式下的Spark,使用spark-shell运行example中的相关测试案例spark-examples_2.12-3.0.0.jar,来计算pi。当spark-shell 停止掉后,集群监控base:4040 页面就看不到历史任务的运行情况,所以需要配置历史服务器记录任务运行情况。
因此,在此基础上需要配置spark的历史服务器来记录任务运行情况,参考网上教程,进行了以下步骤进行配置。
# 1) 修改 spark-defaults.conf.template 文件名为 spark-defaults.conf
mv spark-defaults.conf.template spark-defaults.conf
# 2) 修改 spark-default.conf 文件,配置日志存储路径
spark.eventLog.enabled true
spark.eventLog.dir hdfs://主机名:8020/directory
# 注意:需要启动 hadoop 集群,HDFS 上的 directory 目录需要提前存在。
sbin/start-dfs.sh
hadoop fs -mkdir /directory
# 3) 修改 spark-env.sh 文件, 添加日志配置
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://主机名:8020/directory
-Dspark.history.retainedApplications=30"
# 4) 重新启动集群和历史服务
sbin/start-all.sh
sbin/start-history-server.sh
# 5) 重新执行任务
bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://linux1:7077 ./examples/jars/spark-examples_2.12-3.0.0.jar 10
❗ 在执行第五步的时候出现了报错,部分报错内容如下:
23/07/28 15:19:58 INFO SparkContext: Successfully stopped SparkContext
Exception in thread "main" java.net.ConnectException: Call From base/192.168.10.201 to base:8020 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
二、解决思路
根据报错内容,以及网络搜索查找原因:
- 可能是ip出现异常,导致无法连接。
- 端口号没有开放导致拒接连接。
- 防火墙未关闭,导致无法连接。
三、解决过程
首先根据网络上常用的排查方式,使用telnet指令访问ip或相应端口,查看连接是否正常。
尝试22号端口是否可以连接。
发现使用的ip是可以正常访问的,但是8020端口拒绝连接。

通过netstat查看8020端口,发现该端口不存在,是属于hadoop集群中一个内部通讯的端口。尝试开放该端口,发现开放端口后依旧会导致报错。因此,考虑是Spark配置文件存在错误的问题。
经过查看端口8020的使用情况发现,8020端口一般作为hadoop2.x系列的内部通讯端口使用。常用端口的使用如下:
| 端口名称 | hadoop2.x | hadoop3.x |
|---|---|---|
| Namenode内部通常端口 | 8020/9000 | 8020/9000/9820 |
| Namenode对用户的査询端口 | 50070 | 9870 |
| MapReduce 查看执行任务端口 | 8088 | 8088 |
| 历史服务器通信端口 | 19888 | 19888 |
通过查看namenode端口的使用发现,hadoop3.x默认使用9820端口,因此,发现问题所在是在配置spark文件时端口出现错误。
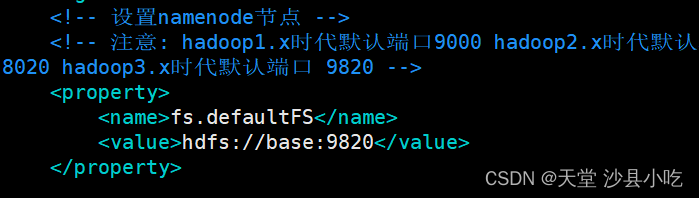
❗ 需要将原本spark-default.conf和spark-env.sh的8020端口改为9820端口,之后再重新启动spark相关服务即可。
相关历史进程可以从http:// ip地址:18080/查看。
四、小结
在使用Spark和Hadoop时,端口问题可能会出现,以下是一些常见的端口问题小结:
- Hadoop端口问题:
- NameNode端口:Hadoop的NameNode组件默认使用端口9820。如果无法访问NameNode,请确保9820端口没有被防火墙或其他应用程序占用。
- Spark端口问题:
- Spark Master端口:Spark的Master节点默认使用端口7077来接收来自Worker节点的连接。如果Worker节点无法连接到Master节点,请检查7077端口是否可用。
- 防火墙设置:
- 确保你的防火墙允许Spark和Hadoop相关的端口通过。你可以配置防火墙规则来放行这些端口,或者完全禁用防火墙。但是,请注意这可能会降低系统的安全性,所以应该谨慎操作。
- 其他问题:
- 端口冲突:在同一台机器上运行多个Spark或Hadoop集群时,可能会发生端口冲突的情况。确保每个集群使用不同的端口范围来避免冲突。
- 网络配置:如果Spark或Hadoop跨多台机器进行通信,确保网络配置正确,允许节点之间的端口通信。
解决端口问题的方法通常是检查端口是否被占用,配置防火墙规则,以及确保网络和集群配置正确。根据具体情况,可能需要查看日志文件获取更多帮助。