强化学习模型研讨班
强化学习的模型:马尔科夫决策过程
1. 强化学习的定义
强化学习(Reinforcement Learning. RL)又称为鼓励学习、评价学习或增强学习,是机器学习的重要组成部分之一,用于描述和解决智能体(Agent)在与环境(Enviroment)交互过程中通过学习策略(Policy)以达到回报(Reward)最大化或实现特定目标的问题。
2、强化学习和其他机器学习领域的区别和联系
强化学习是和监督学习、非监督学习并列的第三种机器学习方法。
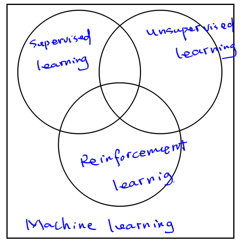
强化学习和监督学习的区别:强化学习不需要事先准备好训练数据,更没有输出作为监督来指导学习过程。强化学习只有奖赏值,但这个奖赏值和监督学习的输出不一样,它并不是事先给出的,而是延后给出的。同时,强化学习的每一步与时间顺序前后关系密切,而监督学习的训练数据一般是相互独立的,相互之间没有依赖关系。
强化学习与非监督学习的区别:非监督学习只有输入数据,没有输出值,也没有奖励值,同时非监督学习的数据之间也是相互独立的,相互之间没有依赖关系。
3. 强化学习建模
-
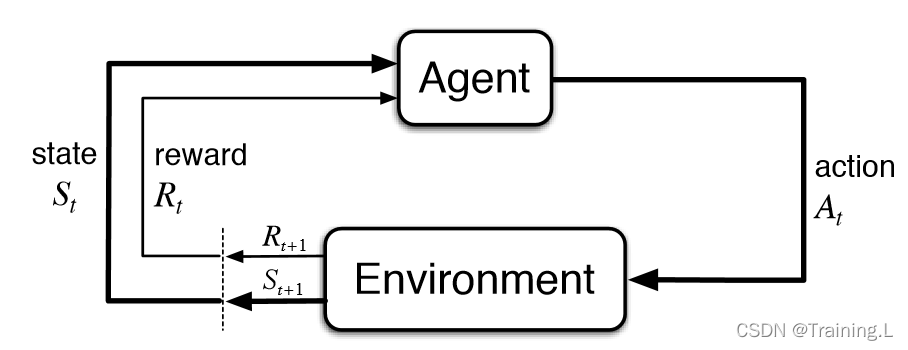
基本模型
-
基本组成元素:
- 智能体(Agent):强化学习的本体,作为学习者或决策者存在;
- 环境(Enviroment):智能体以外的一切,主要指周围的所有状态;
- 状态(State):表示环境的数据,状态集是环境中所有可能状态的集合;
- 动作(Action):智能体可以做出的动作,动作集是智能体可以做出的所有动作的集合;
- 奖励(Rewards):智能体在执行一个动作后,获得的正负奖励信号;
- 策略(Policy):从状态到动作的映射,智能体基于某种状态选择某种动作的过程。
-
学习过程:
Step 1:智能体感知环境状态;
Step 2:智能体根据某种策略做出动作;
Step 3:动作作用于环境导致环境状态改变;
Step 4:同时,环境向智能体发出一个反馈信号(奖励或惩罚);
-
强化学习目标:智能体寻找在连续时间序列里的最优策略。最优策略是指使得长期累计奖励最大化的策略。
4、马尔科夫决策过程(Markov Decition Process, MDP)
马尔科夫性质(无后效性):在时间步
t
+
1
t+1
t+1 时,环境的反馈仅取决于上一时间步
t
t
t 的状态
s
s
s 和动作
a
a
a,与时间步
t
−
1
t-1
t−1 以及
t
−
1
t-1
t−1 步之前的时间步都没有关联性。
P
(
s
t
+
1
∣
a
t
s
t
,
a
t
−
1
s
t
−
1
,
.
.
.
,
a
0
s
0
)
≈
P
(
s
t
+
1
∣
a
t
s
t
)
P(s_{t+1}|a_ts_t,a_{t-1}s_{t-1},...,a_0s_0)≈P(s_{t+1}|a_ts_t)
P(st+1∣atst,at−1st−1,...,a0s0)≈P(st+1∣atst)
马尔科夫是一种为了简化问题而提出的假设。
MDP 的基本组成部分:
-
状态集合: S = { s 1 , s 2 , . . . , s n } S=\left\{s_1,s_2,...,s_n\right\} S={s1,s2,...,sn},其中 s i ( i = 1 , 2 , 3 , . . . , n ) s_i(i=1,2,3,...,n) si(i=1,2,3,...,n) 表示所有可能的状态, s t ( t = 1 , 2 , 3 , . . . , ) s_t(t=1,2,3,...,) st(t=1,2,3,...,) 表示时刻 t t t 的动作,且 s t ∈ S s_t \in S st∈S.
-
动作集合: A = { a 0 , a 1 , a 2 , ⋯ , a n } A=\left\{a_0,a_1,a_2,\cdots,a_n \right\} A={a0,a1,a2,⋯,an}
a i ( i = 0 , 1 , 2 , . . . , m ) a_i(i=0,1,2,...,m) ai(i=0,1,2,...,m) 表示所有可能的动作,而 a t ( t = 0 , 1 , 2 , . . . ) a_t(t=0,1,2,...) at(t=0,1,2,...) 表示时刻 t t t 的状态,且 a t ∈ A a_t \in A at∈A; A ( s i ) A(s_i) A(si) 表示状态 s i s_i si 下的所有合法的动作。
-
状态转移概率: P s a : P s a ( s ′ ) = ( S × A × S ) → [ 0 , 1 ] P_{sa}:P_{sa}(s')=(S \times A \times S) \rightarrow[0,1] Psa:Psa(s′)=(S×A×S)→[0,1]
∑ s ′ ∈ S P s a ( s ′ ) = 1 且 P s a ( s ′ ) ∈ [ 0 , 1 ] , ∀ s ′ ∈ S \sum_{s'\in S}{P_{sa}(s')=1}\ \ 且\ \ P_{sa}(s') \in [0,1], \forall s' \in S s′∈S∑Psa(s′)=1 且 Psa(s′)∈[0,1],∀s′∈S
其中, P s a ( s ′ ) P_{sa}(s') Psa(s′) 表示在状态 s s s 时执行动作 a a a 转移到状态 s ′ s' s′ 的概率。
-
奖励函数:
- R s a : S × A → R ( 实 数 ) R_{sa}:S \times A \rightarrow R(实数) Rsa:S×A→R(实数),将 R s a ( s , a ) R_{sa}(s,a) Rsa(s,a) 记为在状态 s s s 时执行动作 a a a 所得到的奖励;
- R s a s : S × A × S → R ( 实 数 ) R_{sas}:S \times A \times S \rightarrow R(实数) Rsas:S×A×S→R(实数),将 R s a s ( s , a , s ′ ) R_{sas}(s,a, s') Rsas(s,a,s′) 记为在状态 s s s 时执行动作 a a a 转移到状态 s ′ s' s′ 时得到的奖励;
-
策略函数: π : S × A → [ 0 , 1 ] \pi:S \times A \rightarrow [0, 1] π:S×A→[0,1],记为 π ( a ∣ s ) \pi(a|s) π(a∣s),表示在状态 s s s 的前提下,执行动作 a a a 的概率。
f ( x ) = { 0 或 1 , ( π ( s ) = a ) 确 定 性 策 略 [ 0 , 1 ] , 随 机 性 策 略 f(x)= \begin{cases} 0\ 或\ 1,& (\pi(s)=a)\ 确定性策略\\ [0, 1],& 随机性策略 \end{cases} f(x)={0 或 1,[0,1],(π(s)=a) 确定性策略随机性策略
- 折扣因子:
γ
∈
[
0
,
1
]
\gamma \in [0, 1]
γ∈[0,1]
- γ = 0 \gamma = 0 γ=0:贪婪法,价值只由当前延时奖励决定;
- γ = 1 \gamma = 1 γ=1:所有后续状态奖励和当前状态奖励同等重要;
- γ ∈ ( 0 , 1 ) \gamma \in (0, 1) γ∈(0,1):当前延时奖励的权重比后续奖励的权重大。
马尔科夫决策过程可以表示成一个五元组: M D P ( S , A , P s a , R s a , γ ) MDP(S,A,P_{sa},R_{sa},\gamma) MDP(S,A,Psa,Rsa,γ).
MDP 的基本流程:
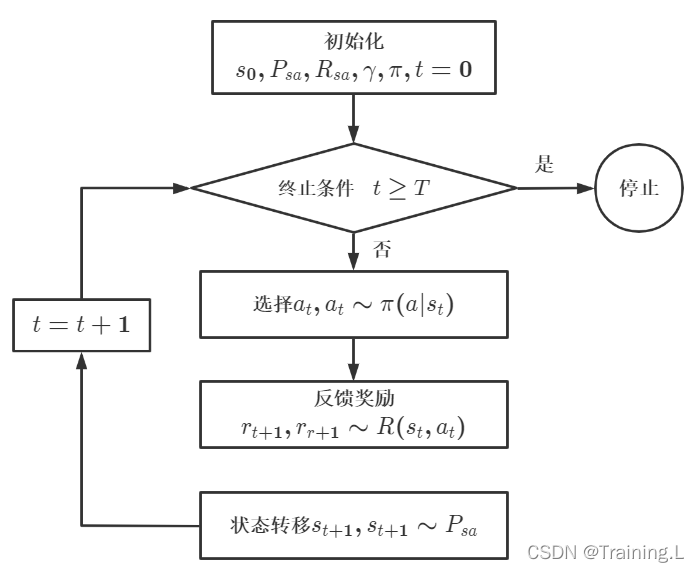
1、产生一个“状态—动作—奖励”序列:
s
0
a
0
r
1
,
s
1
a
1
r
2
,
s
2
a
2
r
3
,
⋯
,
s
t
a
t
r
t
+
1
,
⋯
,
s
T
−
1
a
T
−
1
r
T
s
T
s_0a_0r_1,s_1a_1r_2,s_2a_2r_3,\cdots,s_ta_tr_{t+1},\cdots,s_{T-1}a_{T-1}r_{T}s_T
s0a0r1,s1a1r2,s2a2r3,⋯,statrt+1,⋯,sT−1aT−1rTsT
其中,
r
1
,
r
2
,
⋯
,
r
t
+
1
r_1,r_2,\cdots,r_{t+1}
r1,r2,⋯,rt+1 表示某一个动作的即时奖励,
s
T
s_T
sT 表示最后的终止状态。
2、累积奖励(Total Payoff):
G
t
=
r
t
+
1
+
γ
r
t
+
2
+
γ
2
r
t
+
3
+
⋯
+
γ
T
−
t
−
1
r
T
G_t=r_{t+1}+\gamma r_{t+2} + {\gamma}^2 r_{t+3} + \cdots+ {\gamma}^{T-t-1} r_{T}
Gt=rt+1+γrt+2+γ2rt+3+⋯+γT−t−1rT
这里的折扣因子
γ
∈
[
0
,
1
]
\gamma \in [0, 1]
γ∈[0,1].