用Selenium爬取网页简单操作
一、工具的安装
首先,我们要先安装selenium库。可以通过指令pip install selenium进行安装。
安装完selenium后,还需要安装浏览器驱动程序。这里以chrome为例。安装步骤如下:
-
查看浏览器的版本号。找到
菜单,在菜单中打开"帮助">"关于Google Chrome命令。里面就有版本号。 -
下载ChromeDriver。官方下载地址:
https://chromedriver.storage.googleapis.com/index.html找到对应的版本号文件夹,打开并下载对应操作系统的zip。 -
将zip中的文件安装在python的安装路径的
Scripts文件夹下。 -
为了验证是否安装成功,可以通过打开命令行窗口输入
chromedriver来检验。
二、通过selenium访问网页
先上代码
from selenium import webdriver
browser = webdriver.Chrome() #声明要模拟的浏览器是Chrome
url = 'https://www.baidu.com/' #要访问的网页链接,这里以baidu为例
browser.get(url) #通过get方式获取网页
text = browser.page_source #获得网页源代码
print(text) #打印出源代码
如果想关闭模拟浏览器窗口,可以在最后加上代码:browser.quit()
如果不想让网页弹出,可以启用无界面浏览模式:
from selenium import webdriver
browser = webdriver.Chrome()
#加上这三句代码
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(options=chrome_options)
url = 'https://www.baidu.com/'
browser.get(url)
ps:通过selenium得到的网页是经过渲染之后的源代码,就不用我们再去抓包找信息了!!
三、使用selenium模拟鼠标跟键盘操作
selenium模块还可以模拟人在浏览器中的鼠标和键盘操作。下面以在百度首页的搜索框中输入python,然后单击百度一下按钮进行搜索为例。
网页是由一个个元素构成的,搜索框和百度一下按钮都是网页上的元素。要对元素进行操作,首先要定位元素。定位元素的方法主要有XPath法跟css_selector两种方法。
1、XPath法
用XPath法定位网页元素的语法格式如下:
browser.find_element_by_xpath('xpath的表达式')
获取网页元素XPath的方法如下(以baidu搜索框为例):
- 找到百度搜索框的位置,将鼠标放在上面
- 点击
鼠标右键>检查>对选中的网页代码再次右键>Copy>Copy XPath
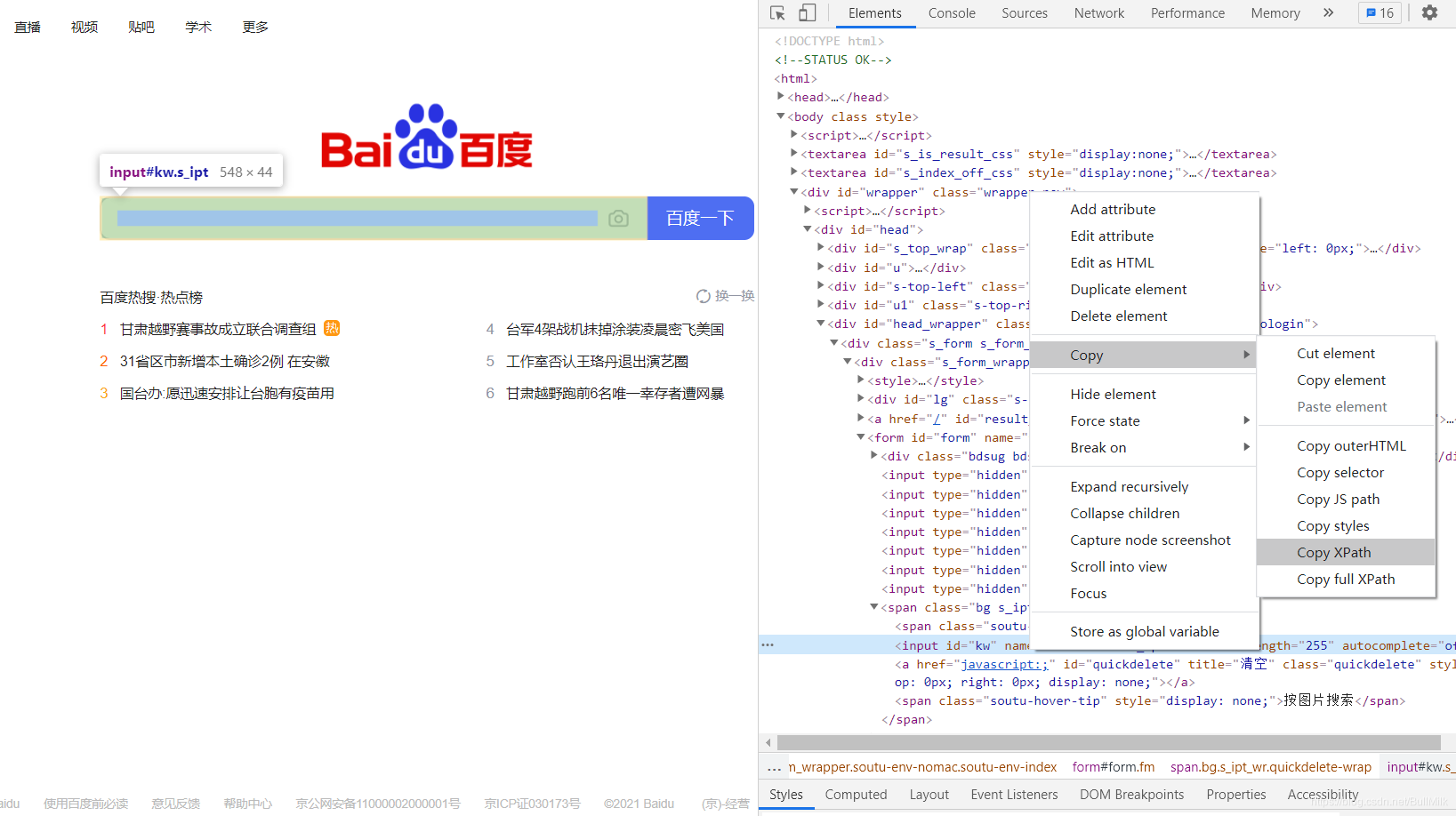
- 粘贴一下发现是
//*[@id="kw"]。这就是搜索框的XPath。
自动在搜索框中输入‘python’的代码如下:
from selenium import webdriver
browser = webdriver.Chrome() #声明要模拟的浏览器是Chrome
url = 'https://www.baidu.com/' #要访问的网页链接,这里以baidu为例
browser.get(url) #通过get方式获取网页
browser.find_element_by_xpath('//*[@id="kw"]').send_keys('python') #输入的代码
其中函数browser.find_element_by_xpath根据XPath表达式定位搜索框,然后使用send_keys在搜索框中输入‘python’。
使用同样的方法获取百度一下按钮的XPath表达式为//*[@id="su"]
输入加搜索的全部代码如下:
from selenium import webdriver
browser = webdriver.Chrome() #声明要模拟的浏览器是Chrome
url = 'https://www.baidu.com/' #要访问的网页链接,这里以baidu为例
browser.get(url) #通过get方式获取网页
browser.find_element_by_xpath('//*[@id="kw"]').send_keys('python') #在搜索框输入
browser.find_element_by_xpath('//*[@id="su"]').click() #通过click()函数来模拟点击
2、css_selector法(跟XPath很像)
css_selector定位网页元素的语法格式如下:
browser.find_element_by_css_selector('css_selector表达式')
css_selector表达式的获取方法跟XPath表达式的获取方式类似。
- 找到百度搜索框的位置,将鼠标放在上面
- 点击
鼠标右键>检查>对选中的网页代码再次右键>Copy>Copy selector
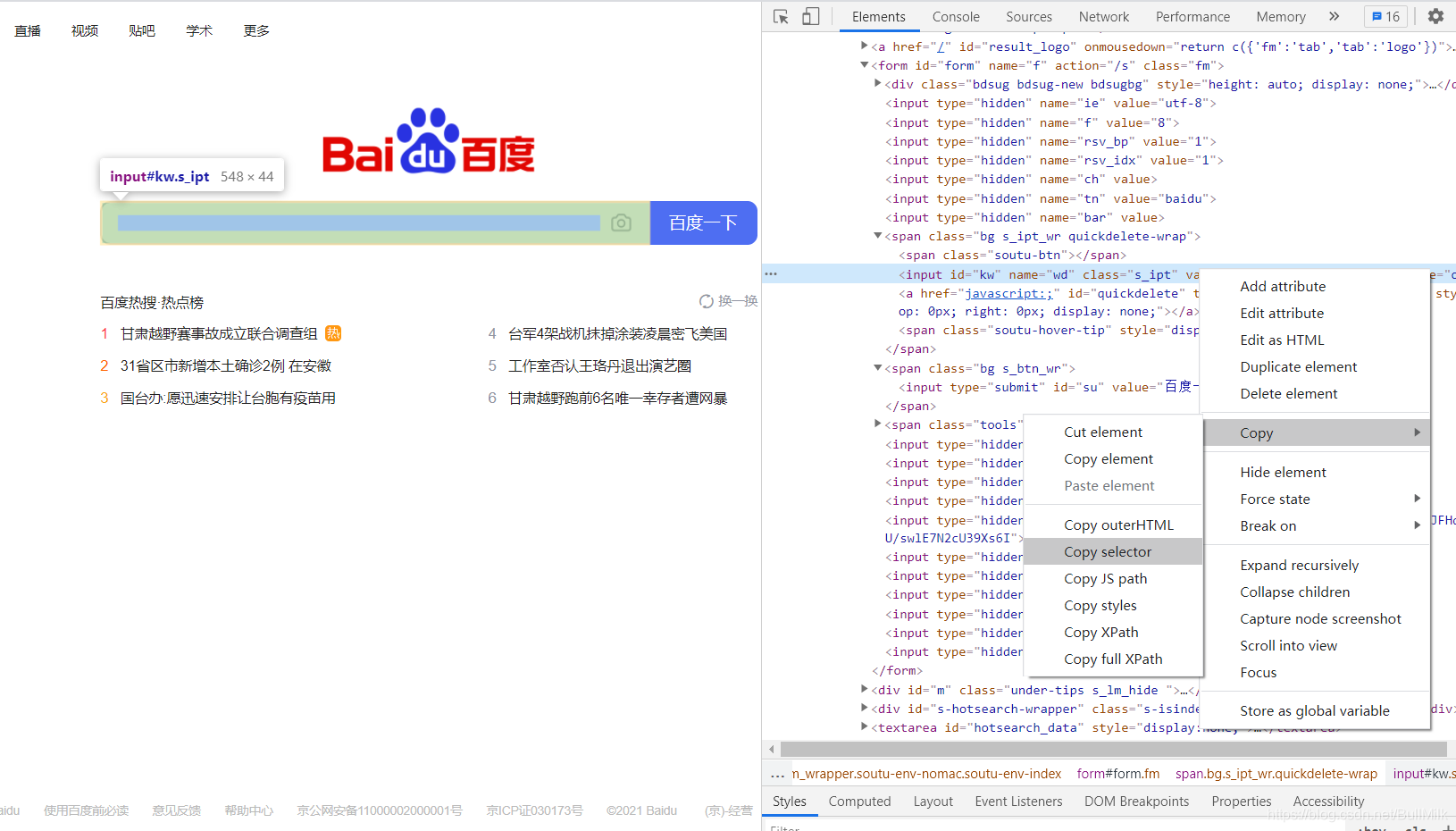
- 粘贴一下发现是
#kw。这就是搜索框的css_selector表达式。
使用css_selector进行操作的全部代码如下:
from selenium import webdriver
browser = webdriver.Chrome() #声明要模拟的浏览器是Chrome
url = 'https://www.baidu.com/' #要访问的网页链接,这里以baidu为例
browser.get(url) #通过get方式获取网页
browser.find_element_by_css_selector('#kw').send_keys('python') #在搜索框输入
browser.find_element_by_css_selector('#su').click() #通过click()函数来模拟点击
四、小提示
XPath跟css_selector本质上是一样的,但有时使用其中一种方法会失败,换成另外一种就有效,所以建议两种方法都要掌握。