1.贝叶斯的应用
以下举一些实际例子来说明贝叶斯方法被运用的普遍性,这里主要集中在机器学习方面,因为我不是学经济的,否则还可以找到一堆经济学的例子。
1.1 中文分词
贝叶斯是机器学习的核心方法之一。比如中文分词领域就用到了贝叶斯。Google 研究员吴军在《数学之美》系列中就有一篇是介绍中文分词的,这里只介绍一下核心的思想,不做赘述,详细请参考吴军的文章。
分词问题的描述为:给定一个句子(字串),如:南京市长江大桥
如何对这个句子进行分词(词串)才是最靠谱的。例如:
1. 南京市/长江大桥
2. 南京/市长/江大桥
这两个分词,到底哪个更靠谱呢?
我们用贝叶斯公式来形式化地描述这个问题,令 X 为字串(句子),Y 为词串(一种特定的分词假设)。我们就是需要寻找使得 P(Y|X) 最大的 Y ,使用一次贝叶斯可得:
P(Y|X) ∝ P(Y)*P(X|Y)
用自然语言来说就是 这种分词方式(词串)的可能性 乘以这个词串生成我们的句子的可能性。我们进一步容易看到:可以近似地将 P(X|Y) 看作是恒等于 1 的,因为任意假想的一种分词方式之下生成我们的句子总是精准地生成的(只需把分词之间的分界符号扔掉即可)。于是,我们就变成了去最大化 P(Y) ,也就是寻找一种分词使得这个词串(句子)的概率最大化。而如何计算一个词串:
W1, W2, W3, W4 ..
的可能性呢?
我们知道,根据联合概率的公式展开:P(W1, W2, W3, W4 ..) = P(W1) * P(W2|W1) * P(W3|W2, W1) * P(W4|W1,W2,W3) * .. 于是我们可以通过一系列的条件概率(右式)的乘积来求整个联合概率。然而不幸的是随着条件数目的增加(P(Wn|Wn-1,Wn-2,..,W1) 的条件有 n-1 个),数据稀疏问题也会越来越严重,即便语料库再大也无法统计出一个靠谱的 P(Wn|Wn-1,Wn-2,..,W1) 来。
为了缓解这个问题,计算机科学家们一如既往地使用了“天真”假设:我们假设句子中一个词的出现概率只依赖于它前面的有限的 k 个词(k 一般不超过 3,如果只依赖于前面的一个词,就是2元语言模型(2-gram),同理有 3-gram 、 4-gram 等),这个就是所谓的“有限地平线”假设。虽然这个假设很傻很天真,但结果却表明它的结果往往是很好很强大的,后面要提到的朴素贝叶斯方法使用的假设跟这个精神上是完全一致的,我们会解释为什么像这样一个天真的假设能够得到强大的结果。目前我们只要知道,有了这个假设,刚才那个乘积就可以改写成: P(W1) * P(W2|W1) * P(W3|W2) * P(W4|W3) .. (假设每个词只依赖于它前面的一个词)。而统计 P(W2|W1) 就不再受到数据稀疏问题的困扰了。对于我们上面提到的例子“南京市长江大桥”,如果按照自左到右的贪婪方法分词的话,结果就成了“南京市长/江大桥”。但如果按照贝叶斯分词的话(假设使用 3-gram),由于“南京市长”和“江大桥”在语料库中一起出现的频率为 0 ,这个整句的概率便会被判定为 0 。 从而使得“南京市/长江大桥”这一分词方式胜出。
1.2 贝叶斯图像识别
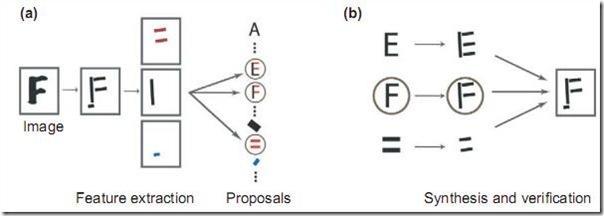
贝叶斯方法是一个非常 general 的推理框架。其核心理念可以描述成:Analysis by Synthesis (通过合成来分析)。06 年的认知科学新进展上有一篇 paper 就是讲用贝叶斯推理来解释视觉识别的,一图胜千言,下图就是摘自这篇 paper :
首先是视觉系统提取图形的边角特征,然后使用这些特征自底向上地激活高层的抽象概念(比如是 E 还是 F 还是等号),然后使用一个自顶向下的验证来比较到底哪个概念最佳地解释了观察到的图像。
1.3 EM 算法与基于模型的聚类
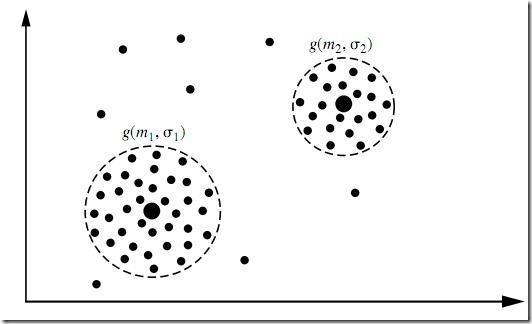
聚类是一种无指导的机器学习问题,问题描述:给你一堆数据点,让你将它们最靠谱地分成一堆一堆的。聚类算法很多,不同的算法适应于不同的问题,这里仅介绍一个基于模型的聚类,该聚类算法对数据点的假设是,这些数据点分别是围绕 K 个核心的 K 个正态分布源所随机生成的,使用 Han JiaWei 的《Data Ming: Concepts and Techniques》中的图:
图中有两个正态分布核心,生成了大致两堆点。我们的聚类算法就是需要根据给出来的那些点,算出这两个正态分布的核心在什么位置,以及分布的参数是多少。这很明显又是一个贝叶斯问题,但这次不同的是,答案是连续的且有无穷多种可能性,更糟的是,只有当我们知道了哪些点属于同一个正态分布圈的时候才能够对这个分布的参数作出靠谱的预测,现在两堆点混在一块我们又不知道哪些点属于第一个正态分布,哪些属于第二个。反过来,只有当我们对分布的参数作出了靠谱的预测时候,才能知道到底哪些点属于第一个分布,那些点属于第二个分布。这就成了一个先有鸡还是先有蛋的问题了。为了解决这个循环依赖,总有一方要先打破僵局,说,不管了,我先随便整一个值出来,看你怎么变,然后我再根据你的变化调整我的变化,然后如此迭代着不断互相推导,最终收敛到一个解。这就是 EM 算法。
EM 的意思是“Expectation-Maximazation”,在这个聚类问题里面,我们是先随便猜一下这两个正态分布的参数:如核心在什么地方,方差是多少。然后计算出每个数据点更可能属于第一个还是第二个正态分布圈,这个是属于 Expectation 一步。有了每个数据点的归属,我们就可以根据属于第一个分布的数据点来重新评估第一个分布的参数(从蛋再回到鸡),这个是 Maximazation 。如此往复,直到参数基本不再发生变化为止。这个迭代收敛过程中的贝叶斯方法在第二步,根据数据点求分布的参数上面。
2.朴素贝叶斯
朴素贝叶斯方法是很特别的方法,所以值得介绍一下。用朴素贝叶斯在垃圾邮件过滤中的应用来举例说明。
2.1 贝叶斯垃圾邮件过滤器
问题是什么?问题是,给定一封邮件,判定它是否属于垃圾邮件。按照先例,我们还是用 D 来表示这封邮件,注意 D 由 N 个单词组成。我们用 h+ 来表示垃圾邮件,h- 表示正常邮件。问题可以形式化地描述为求:
P(h+|D) = P(h+) * P(D|h+) / P(D)
P(h-|D) = P(h-) * P(D|h-) / P(D)
其中 P(h+) 和 P(h-) 这两个先验概率都是很容易求出来的,只需要计算一个邮件库里面垃圾邮件和正常邮件的比例就行了。然而 P(D|h+) 却不容易求,因为 D 里面含有 N 个单词 d1, d2, d3, .. ,所以P(D|h+) = P(d1,d2,..,dn|h+) 。我们又一次遇到了数据稀疏性,为什么这么说呢?P(d1,d2,..,dn|h+) 就是说在垃圾邮件当中出现跟我们目前这封邮件一模一样的一封邮件的概率是多大!开玩笑,每封邮件都是不同的,世界上有无穷多封邮件。瞧,这就是数据稀疏性,因为可以肯定地说,你收集的训练数据库不管里面含了多少封邮件,也不可能找出一封跟目前这封一模一样的。结果呢?我们又该如何来计算 P(d1,d2,..,dn|h+) 呢?
我们将 P(d1,d2,..,dn|h+) 扩展为: P(d1|h+) * P(d2|d1, h+) * P(d3|d2,d1, h+) * .. 。熟悉这个式子吗?这里我们会使用一个更激进的假设,我们假设 di 与 di-1 是完全条件无关的,于是式子就简化为 P(d1|h+) * P(d2|h+) * P(d3|h+) * .. 。这个就是所谓的条件独立假设,也正是朴素贝叶斯方法的朴素之处。而计算 P(d1|h+) * P(d2|h+) * P(d3|h+) * .. 就太简单了,只要统计 di 这个单词在垃圾邮件中出现的频率即可。
2.2 为什么朴素贝叶斯方法令人诧异地好
朴素贝叶斯方法的条件独立假设看上去很傻很天真,为什么结果却很好很强大呢?就拿一个句子来说,我们怎么能鲁莽地声称其中任意一个单词出现的概率只受到它前面的 3 个或 4 个单词的影响呢?别说 3 个,有时候一个单词的概率受到上一句话的影响都是绝对可能的。那么为什么这个假设在实际中的表现却不比决策树差呢?有人对此提出了一个理论解释,并且建立了什么时候朴素贝叶斯的效果能够等价于非朴素贝叶斯的充要条件,这个解释的核心就是:有些独立假设在各个分类之间的分布都是均匀的所以对于似然的相对大小不产生影响;即便不是如此,也有很大的可能性各个独立假设所产生的消极影响或积极影响互相抵消,最终导致结果受到的影响不大。具体的数学公式请参考[1]。
3.层级贝叶斯模型
层级贝叶斯模型是现代贝叶斯方法的标志性建筑之一。前面讲的贝叶斯,都是在同一个事物层次上的各个因素之间进行统计推理,然而层次贝叶斯模型在哲学上更深入了一层,将这些因素背后的因素(原因的原因,原因的原因,以此类推)囊括进来。一个教科书例子是:如果你手头有 N 枚硬币,它们是同一个工厂铸出来的,你把每一枚硬币掷出一个结果,然后基于这 N 个结果对这 N 个硬币的θ(出现正面的比例)进行推理。如果根据最大似然,每个硬币的 θ 不是1就是0 ,然而我们又知道每个硬币的 p(θ) 是有一个先验概率的,也许是一个 beta 分布。也就是说,每个硬币的实际投掷结果 Xi 服从以 θ 为中心的正态分布,而 θ 又服从另一个以 Ψ 为中心的 beta 分布。层层因果关系就体现出来了。进而 Ψ 还可能依赖于因果链上更上层的因素,以此类推。
3.1 隐马可夫模型(HMM)
这个东西我也没学明白,先打个Mark~~
推荐吴军写的数学之美~~因为,只是想了解,专业上没有用到,在这里就不讨论了~~
4.参考文献
[1]Harry Zhang,The Optimality of Naive Bayes.Faculty of Computer Science,University of New Brunswick.
[2]http://mindhacks.cn/2008/09/21/the-magical-bayesian-method/