haspMap源码分析之-链表拆分问题
Jdk1.8 hashmap在扩容的时候,为什么当将一个链接拆分成两个链表的时候,key的hash值和oldCap与为0时,放在原来下标j位置,不为0时,放在下标j+oldCap位置?
一、源码:
/**
* Initializes or doubles table size. If null, allocates in
* accord with initial capacity target held in field threshold.
* Otherwise, because we are using power-of-two expansion, the
* elements from each bin must either stay at same index, or move
* with a power of two offset in the new table.
*
* @return the table
*/
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
//loHead为什么放在扩容后的下标j位置?
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
//hiHead为什么放在扩容后的下标j+oldCap位置?
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
二、分析:
为了简单起见,设oldCap=4,扩容后newCap=8
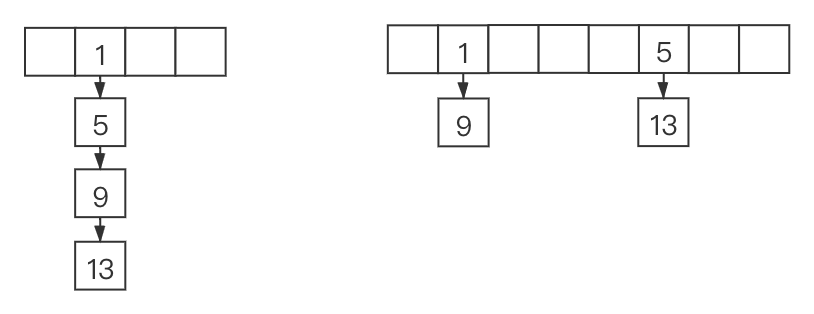
左图为扩容前,右图为扩容后的结果
| key | hash | 二进制 | 和oldCap-1=3的&结果 | 和newCap-1=7的&结果 |
|---|---|---|---|---|
| 1 | 1 | 0000 0001 | 1 | 1 |
| 5 | 5 | 0000 0101 | 1 | 5 |
| 9 | 9 | 0000 1001 | 1 | 1 |
| 13 | 13 | 0000 1101 | 1 | 5 |
上图中key对应的hash值是假设值,那hash值分别和3、7与的结果如上表,那么扩容后,重新通过hash值计算对应的桶下标1和9还在原来的下标1位置,5和13已经移到扩容的下标5位置。
而hashMap扩容的时候,并没有这样重新计算key对应的下标,而是hash值和oldCap与,如果结果为0,放在原来下标位置,如果结果非0,那么放在原来下标+oldCap的下标位置,那么通过hashmap中的这个方式计算,看看结果
| key | hash | 二进制 | 和oldCap=4的&结果 |
|---|---|---|---|
| 1 | 1 | 0000 0001 | 0000 0000 |
| 5 | 5 | 0000 0101 | 0000 0100 |
| 9 | 9 | 0000 1001 | 0000 0000 |
| 13 | 13 | 0000 1101 | 0000 0100 |
1、9和4与的结果为0,会放在原来的下标位置,5、13和4与的结果为非0,会放到原来下标+oldCap=5的位置,这个结果和newCap-1=7的计算下标完全一致,说明用这种方式代替上面那种方式重新计算下标是完全正确的,那么用下面更一般的方式来证明这种代替方法的正确性。
假设一个数的hash值为xxxx,那么和oldCap-1=3与,
0011
&xxxx
=00xx
如果和oldCap=4与
0100
&xxxx
=0x00
如果和oldCap=4与结果为0,那么hash值xxxx中的第二位为0,即x0xx
那么和扩容之后newCap-1=7与,
0111
&x0xx
=00xx
此时正好和扩容前计算的下标相同
如果和oldCap=4与结果为非0,那么hash值xxxx中的第二位为1,即x1xx
那么和扩容之后newCap-1=7与
0111
&x1xx
=01xx
01xx 正好比00xx大oldCap的值,所以此结果是正确的