最新HOI综述
人物交互(Human Object Interaction,HOI)也即是人-物体交互检测,主要目的是定位人体、物体、并识别他们之间的交互关系,就是检测图像中的<人体,动词,物体>三元组。HOI检测旨在利用人体、物体以及人物对的特征将人与物体之间的交互进行关联,从而实现对图像或视频中的动作分类。
https://github.com/s-gupta/v-coco
git clone --recursive https://github.com/s-gupta/v-coco.git
HOI检测的方法

1.传统方法
手工提取局部特征,如颜色,HOG,SIFT、使用贝叶斯模型进行HOI分类。
2.深度学习
2.1 两阶段方法
就是把HOI检测任务分为目标检测和交互推理两个子任务。目标检测阶段使用预训练的目标检测模型检测图像中的人和物体,然后将其逐一匹配为成对的建议,而交互推理阶段则是根据人-物体对的特征来推断交互。
2018年提出的基于人-物体区域的卷积神经网络(HO-RCNN)对HOI检测的研究具有十分重要的意义。它是一个多流网络结构,包含三个流:一个人流、一个物体流以及一个成对流。其中人流和物体流分别编码人和物体的外观特征,而成对流的目的则是编码人和物体之间的空间关系。
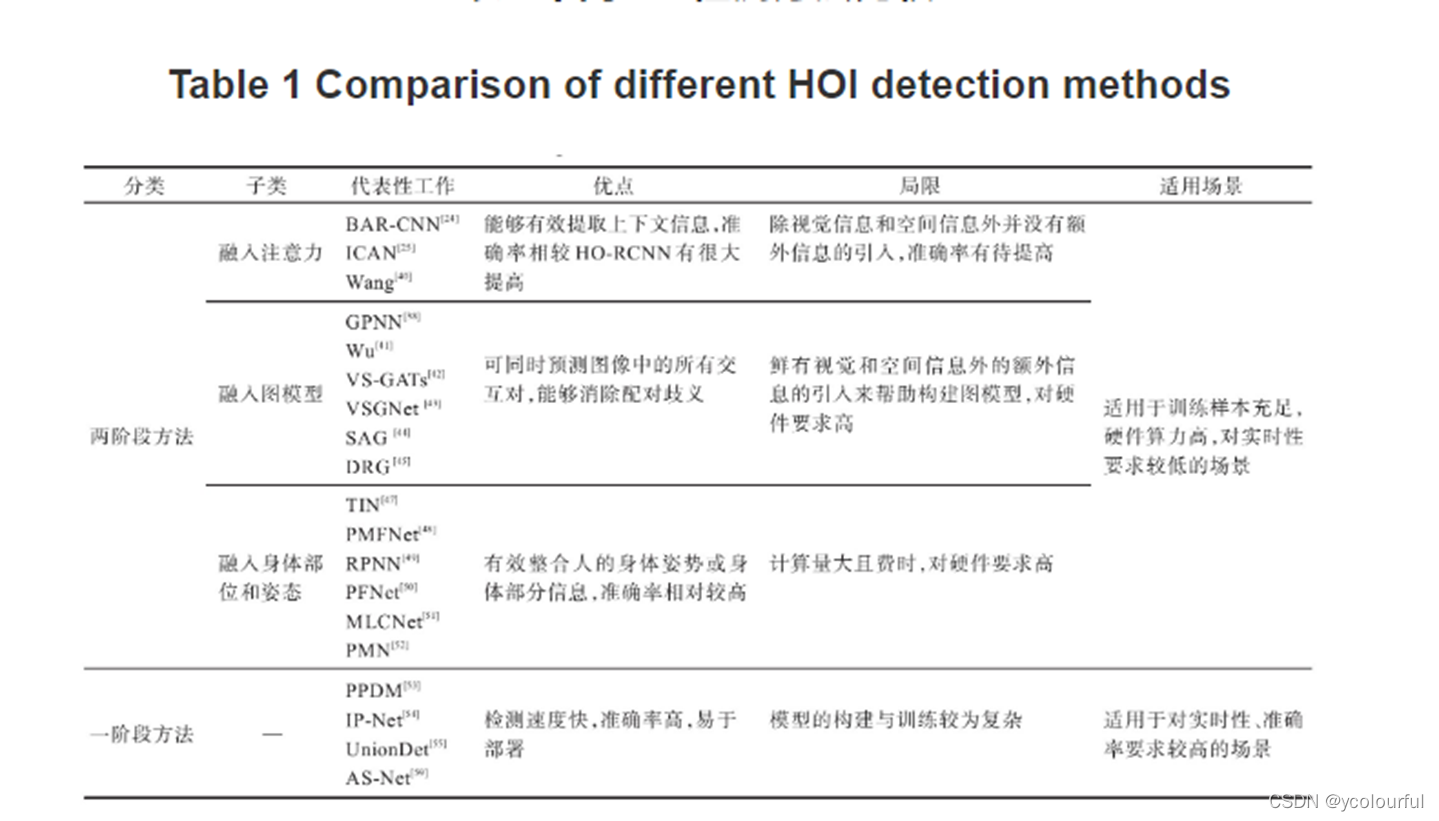
2.1.1融入注意力的HOI检测方法
ICAN:在HO-RCNN的基础上提出,采用以实例为中心的注意力模块来提取与局部区域(人/物框)的外观特征互补的上下文特征,以提高HOI检测效果,ICAN的注意力图是自动学习的,并与网络的其余部分联合训练。
注意力机制的加入有效提高了HOI检测模型提取上下文特征的能力,
由于其分支结构与HO-RCNN相比并没有明显变化,仍然只是利用人与物体的视觉特征以及空间特征来进行推理判断。
2.1.2融入图模型的HOI检测方法
图模型的基本思想是用节点表示人和物体,用边表示人和物体之间的交互,人与物体之间的交互性越大,则边的强度就越高,如:GPNN(图解析神经网络)引入连接函数解决图结构的学习问题,能够以端到端的方式推断邻接矩阵,其中人与物是使用的相同的节点,后来有人提出将人与物用不同的节点表示。
图注意力模型:引入注意力机制的特征处理网络图像上下文信息融入到图节点的特征表示中,如GAT、VS-GATS、如VSGNet(视觉空间网络)、SAG(时空注意力图神经网络)、DRG(双重关系图)
2.1.3融入身体部分和姿态的HOI检测方法
提出了身体部位注意模型,通过学习关注关键部位以及他们之间的相关性,进行HOI识别,使用ROI,提出了TIN:利用交互网络从多个HOI数据集学习一般交互知识,并在推理过程中的HOI分类之前进行非交互抑制。PMFNet(姿态感知多级特征网络)、RPNN(关系解析神经网络)、PFNet(多级成对特征网络)MLCNet(多层次条件网络)、PMN(基于姿态的模块化网络)
2.2 一阶段方法
由于两阶段检测方法需要将检测到的人与物体先配对再进行交互预测,会产生昂贵的计算代价一阶段检测器能够直接从图像中检测HOI三元组,采用一步到位的方法。
PPDM:第一个实时的一阶段HOI检测方法,这一方法使用检测框的中心点表示人和物体点,用人点和物体点间的中点表示交互点。该模型使用两个并行分支分别进行点检测和匹配,其中点检测分支预测人、物体以及交互点,点匹配分支预测从交互点到其对应的人点和物体点的两个位移。源自同一交互点的人点和物体点被视为匹配对
IP-Net:首个将HOI检测作为关键点检测和分组问题,通过将人和物体之间的相互作用定义为相互作用点,将HOI检测视为相互作用点估计问题。
UnionDet:面向实时人机交互检测的联合检测器,使用联合检测框架直接检测相互作用的人类对象对。
AS-Net:将HOI检测表述为一个集合预测问题,具有并行的实例分支和交互分支。
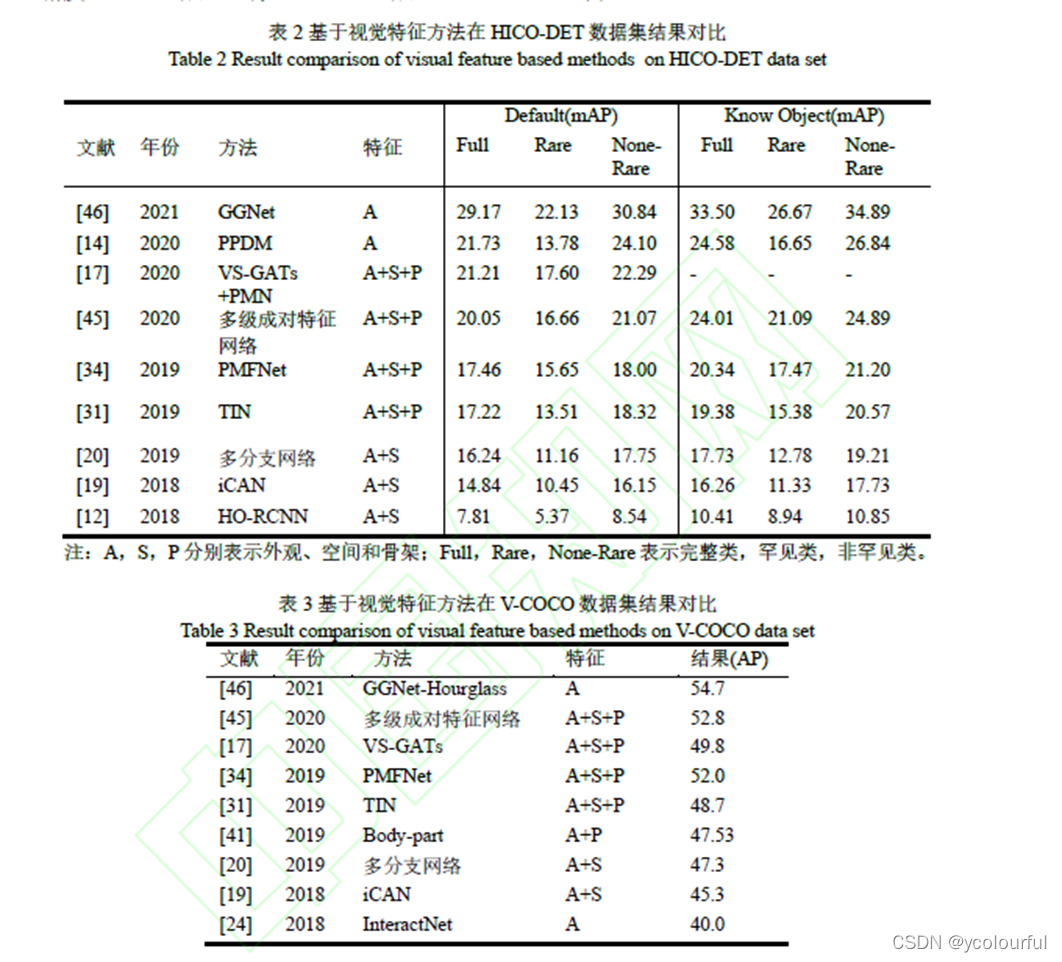
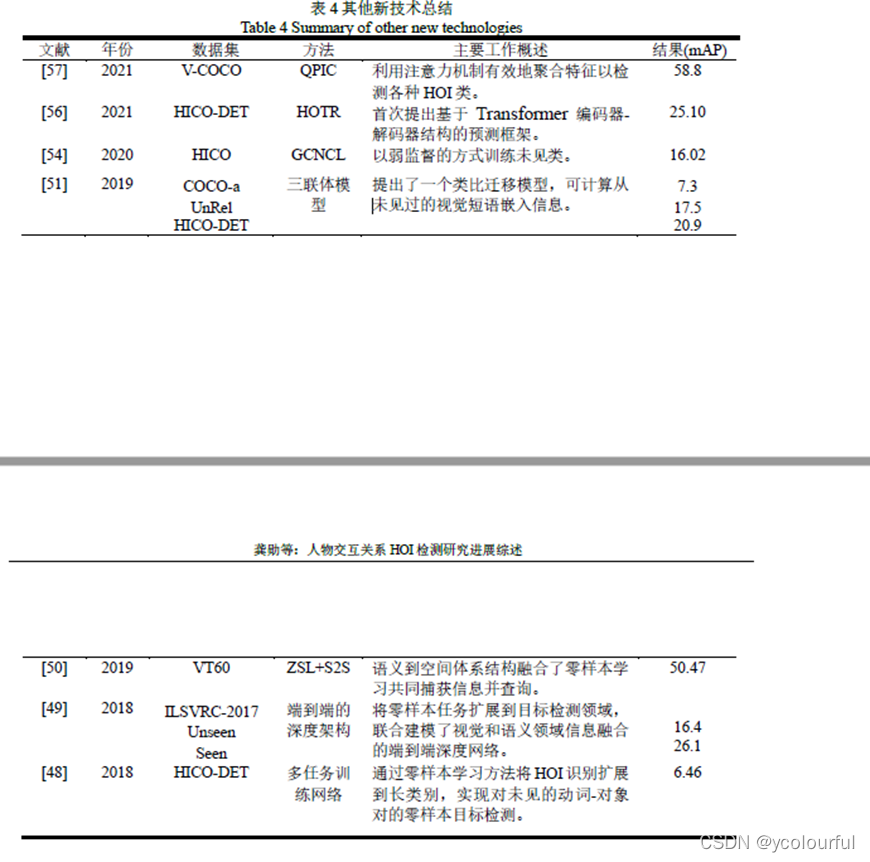
2.3 其他新技术
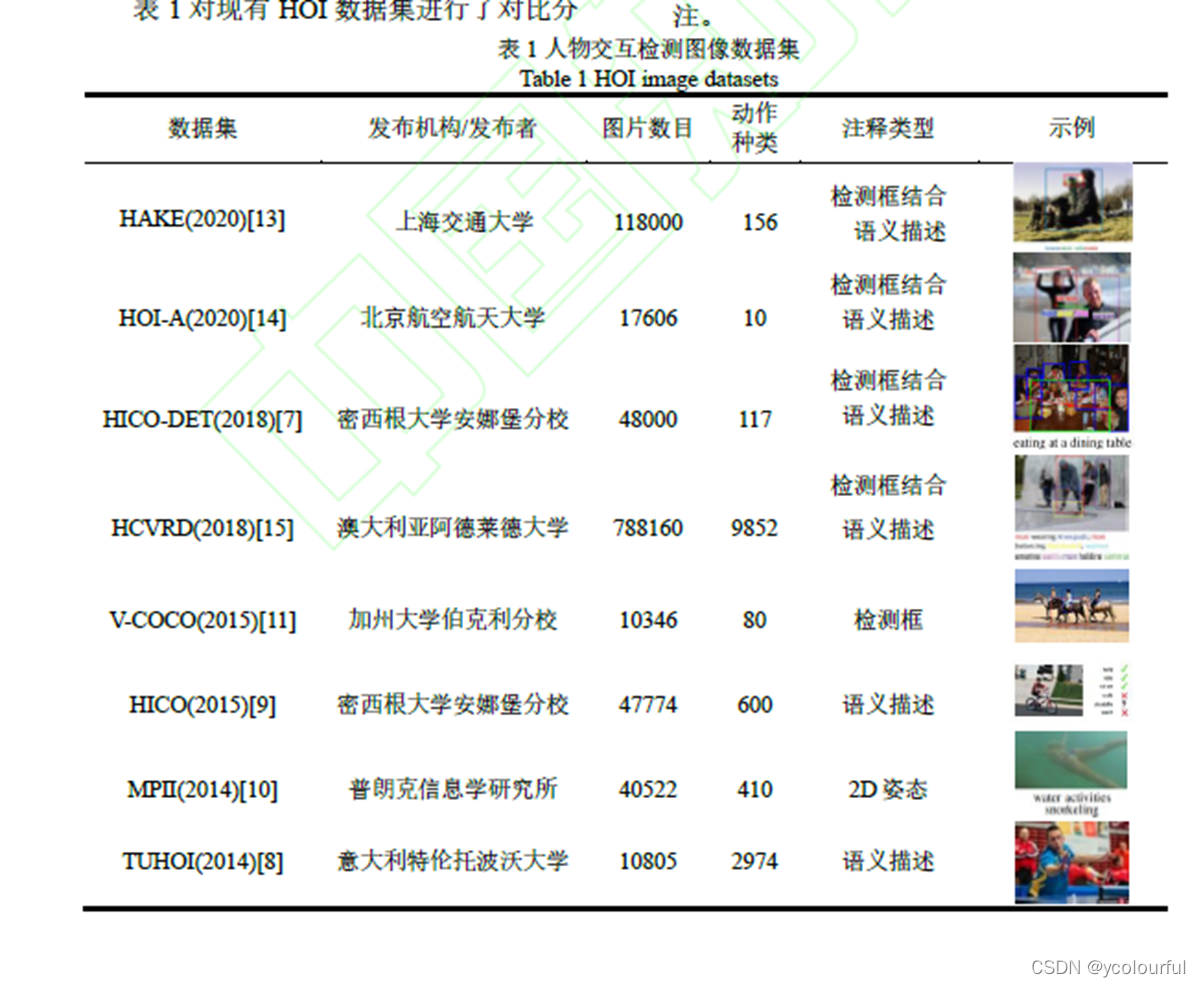
数据集
1.传统数据集
- sports event:博涵8种体育赛事,使用大量语义级标签描述场景和对象。
- TUHOI:人物交互数据集,由于动词的语法师太以及一词多义现象带来映射偏差,导致验证时难以区分语言理解错误和HOI检测错误。
- HICO:收录来自80个对象的117种常见行为,该数据集以物体为中心。
2.实例数据集 - V-COCO数据集:V-COCO针对每一类别的单目标进行实例分割,并为每张图提供了5种文字描述,由Microsoft COCO派生而来,由2533副图像训练集、2867副图像验证集和4946副图像测试集,总共10346副图像,包含16199个人的实例,每个带注释的人含有26个动作标签,80个对象类别。
- HICO-DET:使用无向边作为交互类标签,将人与物体的实例框相连接,专门用于HOI研究任务的基准数据集,来自于HICO的扩种,共有47776副图像,其中38118用于训练,9658用于测试,该数据集与V-COCO 是人物交互检测领域中公认的两大基准数据集。
- HAKE:是人物交互领域最新发布的数据集,
- HOI-A:来自真实场景,包含不同的外观类型,低分辨率,具有严重遮挡的图像,识别难度较大,由38668个带注释的图像 组成,包含11中交互物体和10中交互动作,HOI-A数据集中每种类型的交互分为室内、室外和车内三种场景,包括了黑暗、自然和强烈的三种照明条件,以及各种不同的角度。
评价指标
- 预测的人类边框与其真实边框(ground truth)之间的IoU大于或等于0.5;
- 预测的物体边框与真实的物体边框之间的IoU大于或等于0.5;
- 预测出的人与物体之间的交互动作与标签标注的真实发生的交互动作一致。
被判断为真阳性TP(true positive)表示模型的预测结果与样本的真实类别一致均是正例。FN:模型预测是反例,样本真实是正例FP:预测是正例,样本 真实是反例TN:预测是反例,样本真实是反例使用平均精度mAP来评估HOI检测,是AP的平均值,计算AP需要用到混淆矩阵。
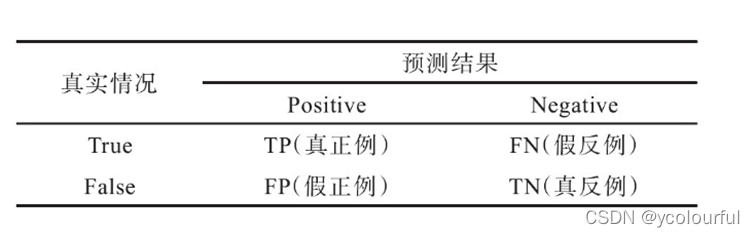
- 准确率表示真正样本占人-物体交互检测模型预测出的全部正样本比例:

- 召回率真实的正样本中,人-物体交互检测模型为正确的正样本所占有的比例

- AP:所有准确率和占该类别的图像数量的比例,评价的是在单个类别上模型判断结果的好坏(p表示准确率,r表示召回率)
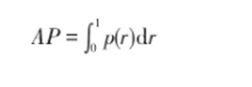
- mAP指的是平均精确率(AP)的平均值,它衡量的是在所有类别上模型判断结果的好坏。(c表示HOI类的总数)
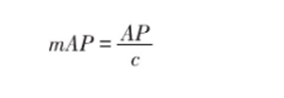
挑战与展望
目前HOI检测网络主要从以下两方面进行改进提升:
- 替换主干网络。主干网络用于提取图像特征,
- 融入额外的信息。例如加入人体姿态与身体部分信息可以提升模型的理解能力
挑战: - 数据集中不同类别间的实例样本数量不平衡,并且交互类别欠全面,目前的HOI检测模型主要基于V-COCO和HICO-DET等少数几个公共基准数据集进行训练和测试,无法训练出特定场景的模型
数据集还有待进一步完善。 - 由于一张图像中往往含有多个人和物体,若是将所有人和物体的组合穷举出来再逐对进行推理判断,则会给计算资源带来巨大的负担
- 两阶段模型不能用于实时性要求较高的场景
- 视觉干扰,如光照变化,拍摄距离,阴影、局部动态背景物体等。
- 运动视角下的人物交互检测。基于图片场景建模的检测方法只适用于固
定拍摄的场景,视频中的交互动作识别对于应用至关重要,如何处理整个时序信息中多个物体产
生的交互,目前还没有很好的方案。
趋势 - 在两阶段方法中,图网络的强大的推理能力非常适用于解决HOI检测任务,但大多数以前的工作未能利用图形中的空间关系信息。因此,如何引入其他信息来完善图模型的构建还有较大的研究空间。
- 一阶段方法更快、更高效,不需要在不同阶段之间切换模型,也不需要保存或加载中间结果,更容易在实际应用中部署,使用它扩展处理一些相关问题,如视觉关系检测和多目标跟踪等也是值得研究的方向。如何简化后期处理以及怎样处理好与交互区域相关的语义歧义是未来研究中亟需解决的问题。
- 由于少样本的HOI检测是为直接解决HOI检测中最重要的两个问题而设计的,是解决HOI检测问题必要深入研究的重要方向。只通过现有的数据进行训练就能够推广到其他未见场景
中,这样才能减少HOI模型对于标记数据的依赖。 - 迫切需要更多像HOI-A这样包含更具针对性动作的或更具实际意义动作的数据集来进一步推动这项技术的发展与应用。
参考文献
[1]阮晨钊,张祥森,刘科,赵增顺.深度学习的人-物体交互检测研究进展[J].计算机科学与探索,2022,16(02):323-336.
[2]龚勋,张志莹,刘璐,马冰,吴昆伦.人物交互关系HOI检测研究进展综述[J/OL].西南交通大学学报:1-13[2022-04-13].